
2025年上半年中文大模型综合性测评
- 2025年上半年大模型评测结果总览
-
- [(一) SuperCLUE全球大模型中文综合能力排行榜](#(一) SuperCLUE全球大模型中文综合能力排行榜)
- [(二) 2025年7月测评总体表现](#(二) 2025年7月测评总体表现)
- [(三) 2025年7月测评结果象限图](#(三) 2025年7月测评结果象限图)
- 一、2025年上半年关键进展及趋势
-
- [(一) 2025年上半年大模型关键进展](#(一) 2025年上半年大模型关键进展)
- [(二) 2025年最值得关注的中文大模型及智能体全景图](#(二) 2025年最值得关注的中文大模型及智能体全景图)
- [(三) 2025年国内外大模型差距](#(三) 2025年国内外大模型差距)
- [(四) 近一年SuperCLUE通用基准测评开闭源模型最好成绩对比](#(四) 近一年SuperCLUE通用基准测评开闭源模型最好成绩对比)
- 二、七月通用测评介绍
-
- [(一) SuperCLUE基准介绍](#(一) SuperCLUE基准介绍)
- [(二) SuperCLUE通用能力测评榜单](#(二) SuperCLUE通用能力测评榜单)
- [(三) SuperCLUE大模型性价比区间分布](#(三) SuperCLUE大模型性价比区间分布)
- [(四) SuperCLUE大模型综合效能区间分布](#(四) SuperCLUE大模型综合效能区间分布)
-
- (1)国外头部模型稳居高效能区,展现强劲应用实力。
- [(2)国内头部模型仅有SenseNova V6 Reasoner趋近高效能区。](#(2)国内头部模型仅有SenseNova V6 Reasoner趋近高效能区。)
- (3)部分国内模型得分反超国外,但耗时差距明显。
- [(五) 代表性模型分析](#(五) 代表性模型分析)
- [(六) 国内大模型成熟度-SC成熟度指数](#(六) 国内大模型成熟度-SC成熟度指数)
- [(七) 评测与人类一致性验证](#(七) 评测与人类一致性验证)
2025年上半年大模型评测结果总览
(一) SuperCLUE全球大模型中文综合能力排行榜
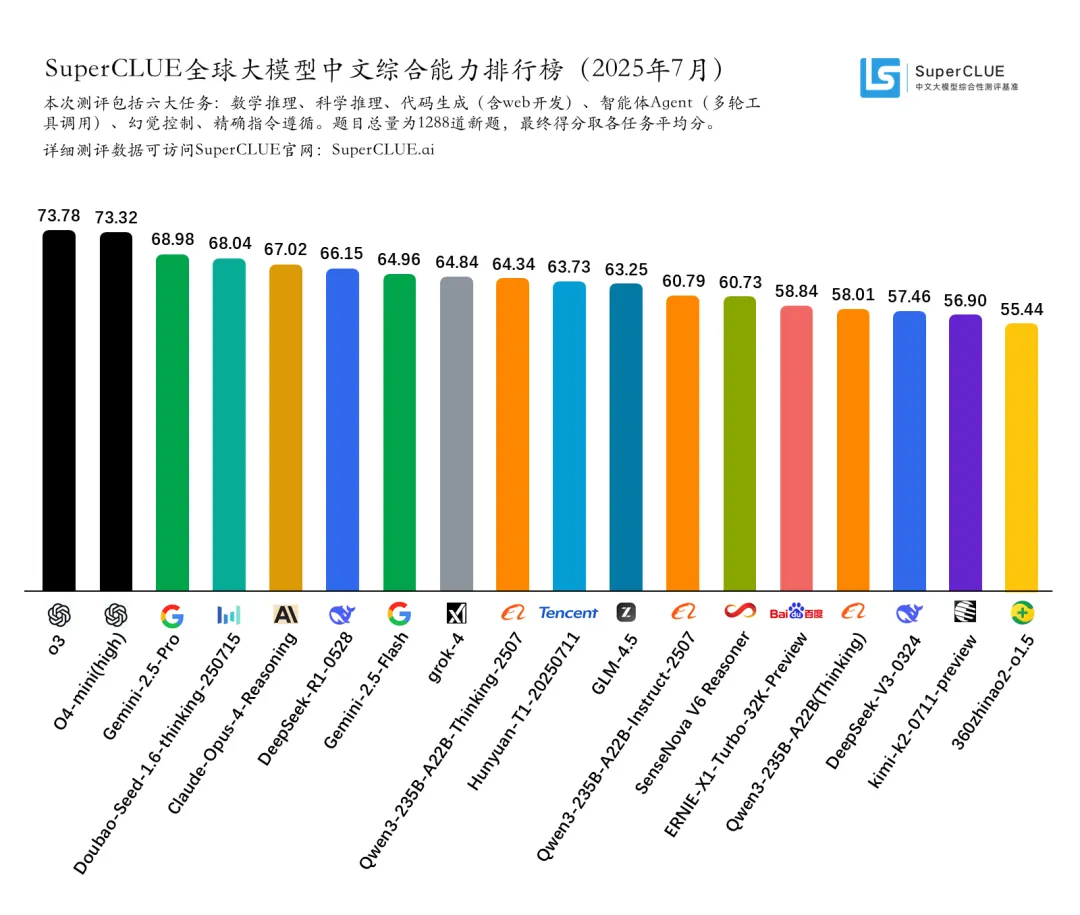
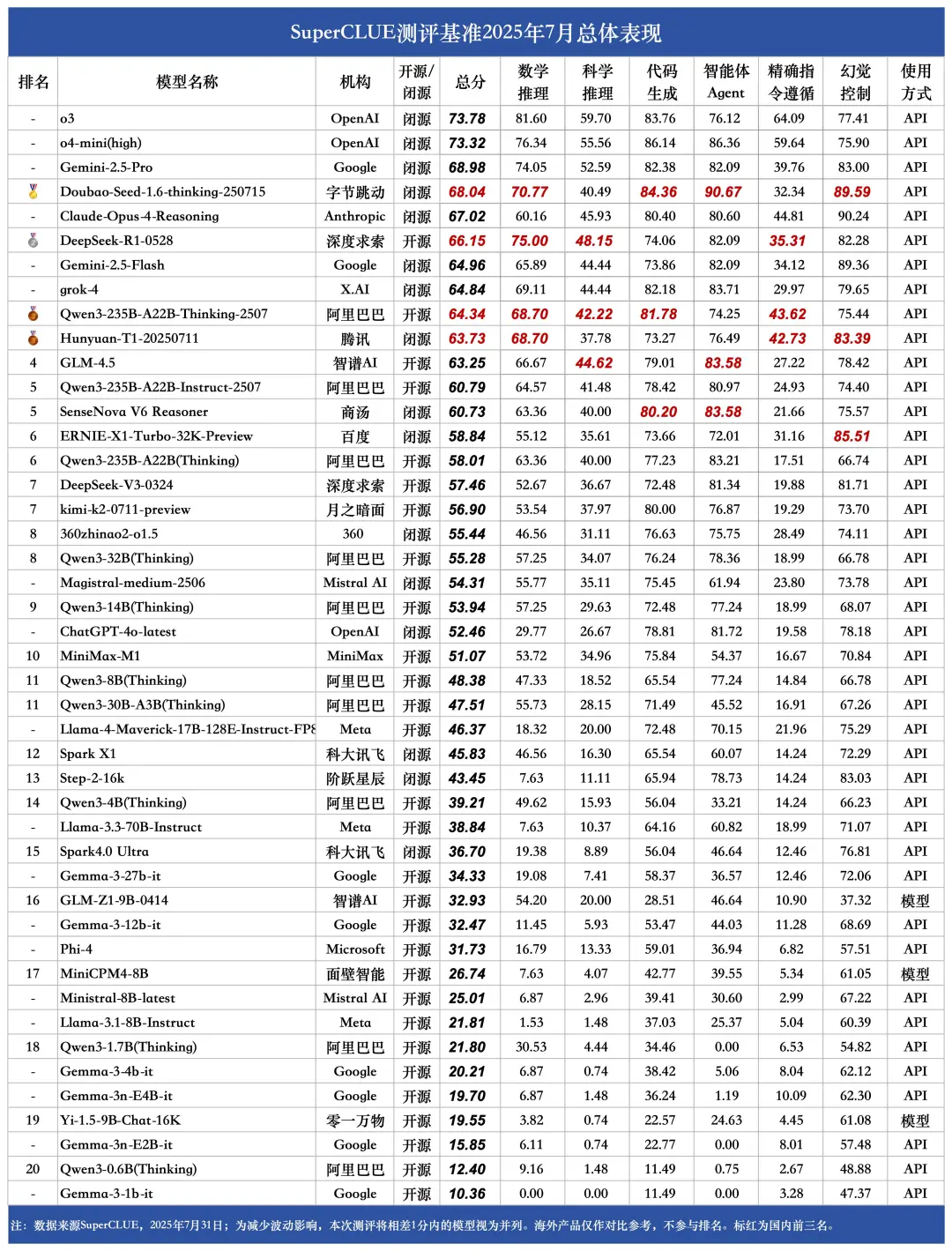
(二) 2025年7月测评总体表现
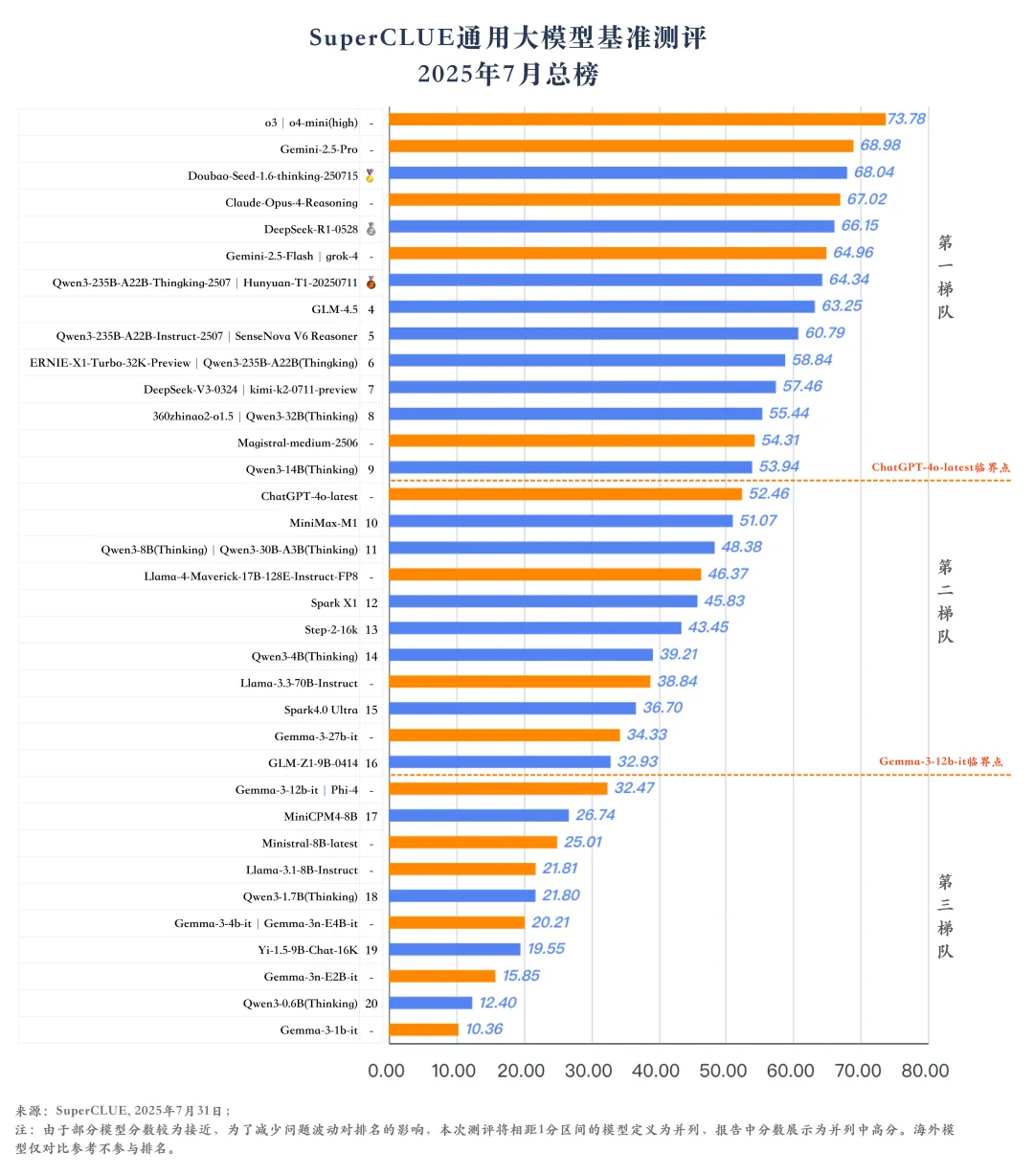
(三) 2025年7月测评结果象限图
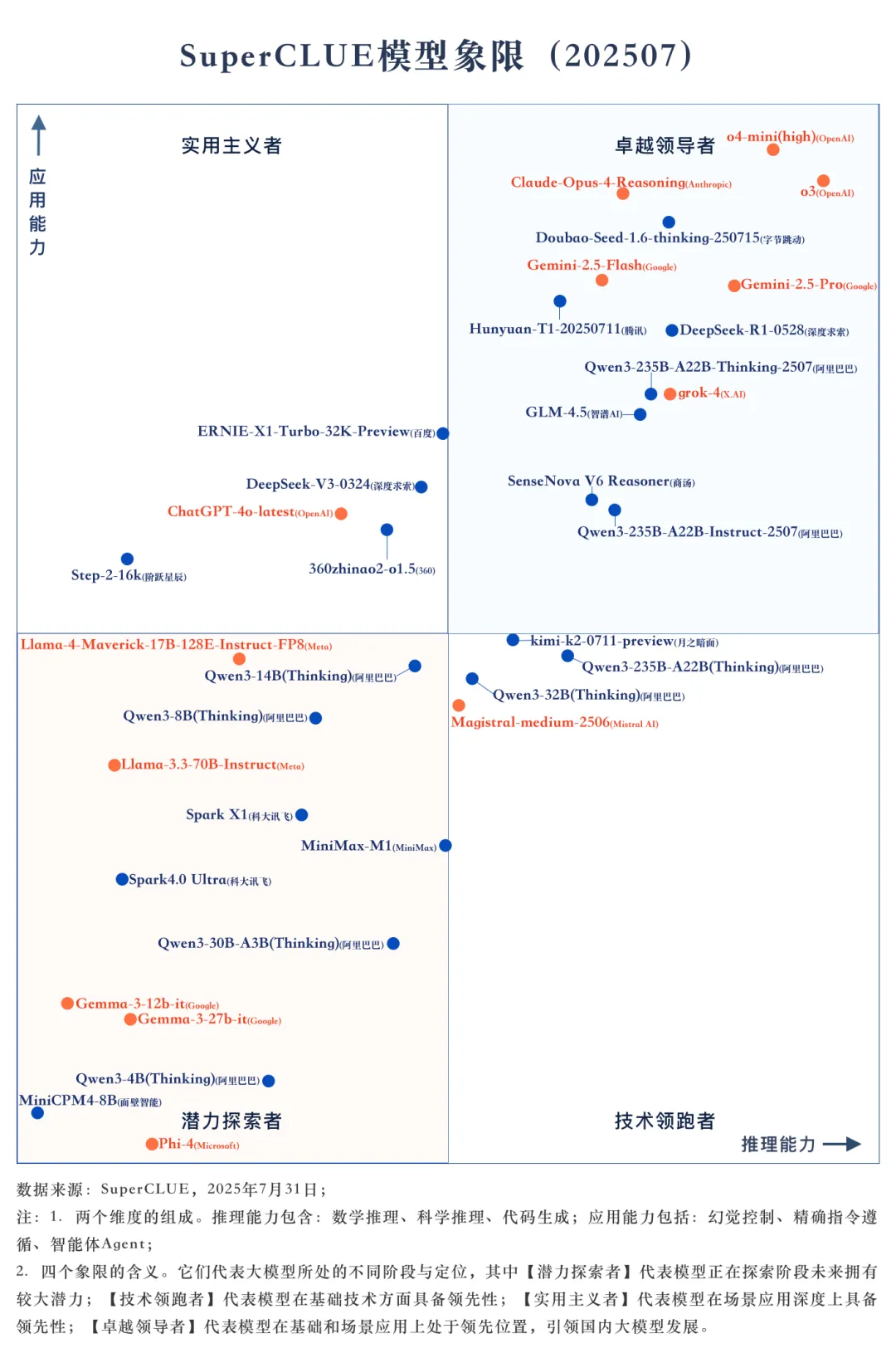
测评摘要
-
测评要点1:o3以73.78的总分取得总榜第一,领跑全球。
海外头部模型o3、o4-mini(high)和Gemini-2.5-Pro在本次七月通用基准测评中取得了73.78分、73.32分和68.98分的总成绩,分别位于榜单前三。Doubao-Seed-1.6-thinking-250715以68.04的总分取得国内第一、全球第四的成绩。 -
测评要点2:国内外头部模型之间的差异较大,海外模型在推理任务上的优势尤其明显。
海外模型在推理任务上的优势尤其显著,o3和o4-mini(high)在推理任务上分别取得了75.02和72.68的分数,领跑推理任务榜单。国内推理任务成绩最好的模型分别是DeepSeek-R1-0528和Doubao-Seed-1.6-thinking-250715,均有超过65分的表现,但与海外头部模型依旧相差近10分。 -
测评要点3:国内开源模型相较于海外开源模型优势显著。
DeepSeek-R1-0528、Qwen3-235B-A22B-Thinking-2507和GLM-4.5分别以66.15分、64.34分和63.25分取得了开源榜单的前三名,海外开源模型最好成绩仅有46.37分,与国内开源模型最好成绩相差近20分,国内开源模型的优势显著。 -
测评要点4:国内大模型在智能体Agent和幻觉控制任务上的表现良好。
在智能体Agent任务上,Doubao-Seed-1.6-thinking-250715以90.67分领跑全球,GLM-4.5和SenseNova V6 Reasoner以83.58分并列国内第二。在幻觉控制任务上,Doubao-Seed-1.6-thinking-250715、ERNIE-X1-Turbo-32K-Preview和Hunyuan-T1-20250711分别位于国内前三。 -
测评要点5:Qwen3系列的开源小参数量模型表现亮眼。
Qwen3系列的多款开源小参数量模型展现出惊人潜力。其中8B、4B和1.7B版本分别在10B级别和端侧5B级别的榜单中遥遥领先。
一、2025年上半年关键进展及趋势
(一) 2025年上半年大模型关键进展
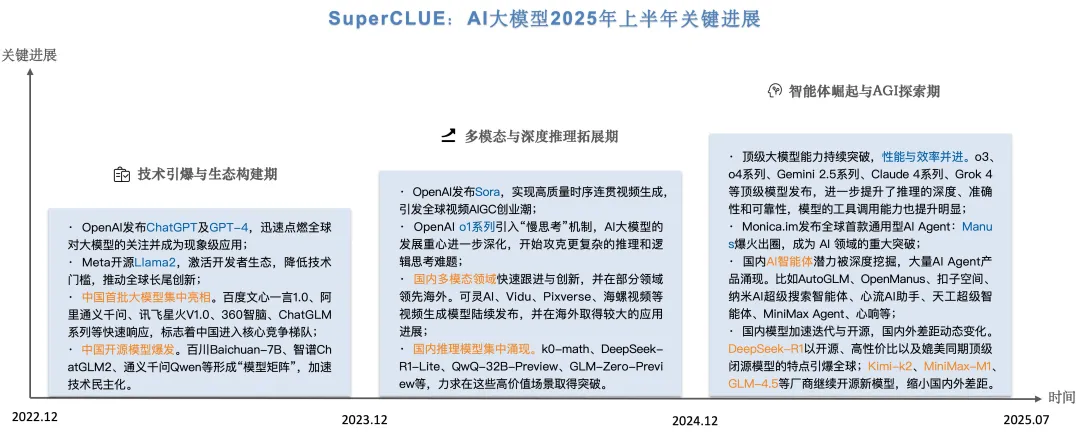
自2022年11月30日ChatGPT发布以来,AI大模型在全球范围内掀起了有史以来规模最大的人工智能浪潮。国内外AI机构在过去2年半有了实质性的突破。具体可分为:技术引爆与生态构建期、多模态与深度推理拓展期、智能体崛起与AGI探索期。
(二) 2025年最值得关注的中文大模型及智能体全景图

(三) 2025年国内外大模型差距
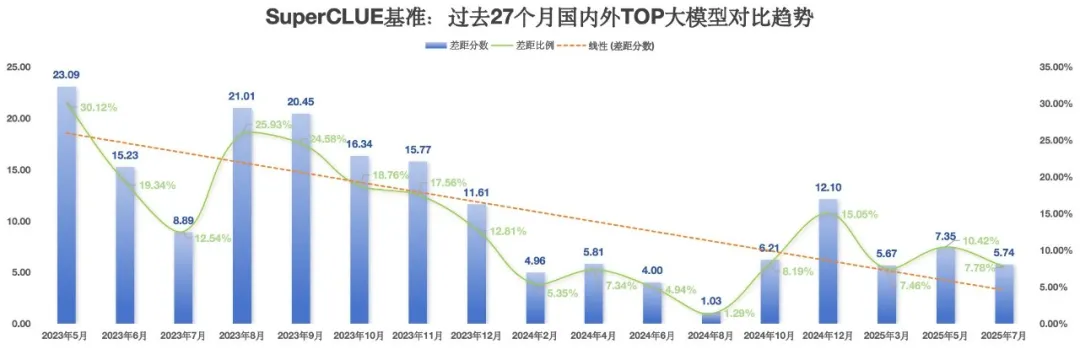
总体趋势上,国内外第一梯队大模型在中文领域的通用能力差距正在缩小。2023年5月至今,国内外大模型能力持续发展。其中GPT系列模型为代表的海外最好模型经过了从GPT3.5、GPT4、GPT4-Turbo、GPT4o到o1系列、o3系列以及o4系列多个版本的迭代升级。国内模型也经历了波澜壮阔的25个月的迭代周期。本次测评我们可以发现国内外第一梯队的大模型从5月通用基准测评10.42%的差距缩小到7.78%。
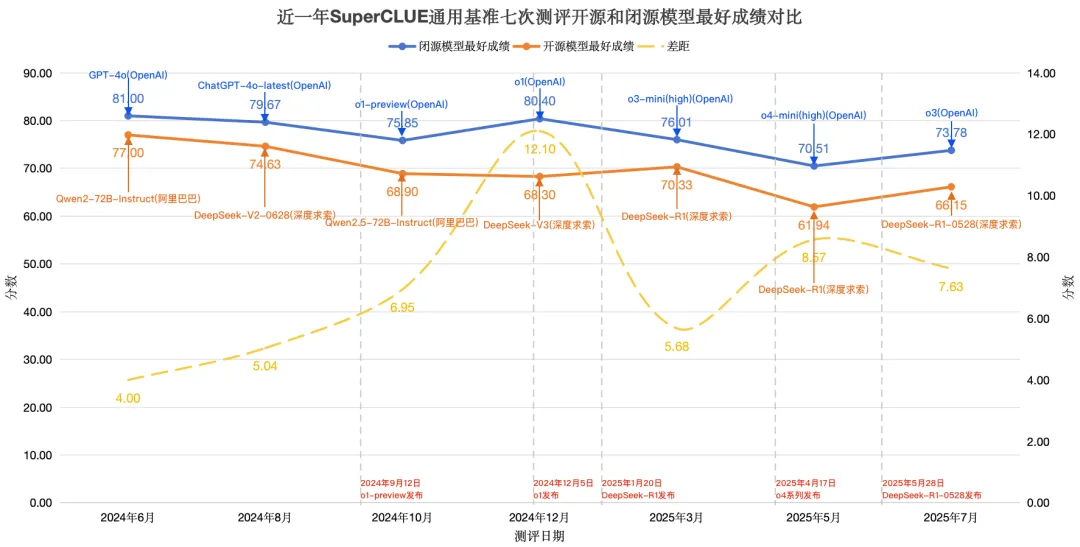
(四) 近一年SuperCLUE通用基准测评开闭源模型最好成绩对比
在近一年的七次SuperCLUE通用基准测评中,闭源模型与开源模型的TOP1性能差距呈现出动态变化趋势。2024年下半年,随着o1系列闭源模型的推出,两者性能差距呈现扩大态势。这一趋势在2025年初迎来转折,DeepSeek-R1开源模型的发布显著缩小了开闭源模型之间的性能差距。接着OpenAI相继推出o3、o4系列闭源模型,将开闭源模型之间的差距再次拉大。DeepSeek-R1-0528的发布又将开闭源模型之间的差距缩小。
二、七月通用测评介绍
(一) SuperCLUE基准介绍
中文通用大模型评测基准------SuperCLUE是大模型时代背景下CLUE(The Chinese Language Understanding Evaluation)基准的发展和延续,是独立、领先的通用大模型的综合性测评基准。中文语言理解测评基准CLUE发起于2019年,陆续推出过CLUE、FewCLUE、ZeroCLUE等广为引用的测评基准。
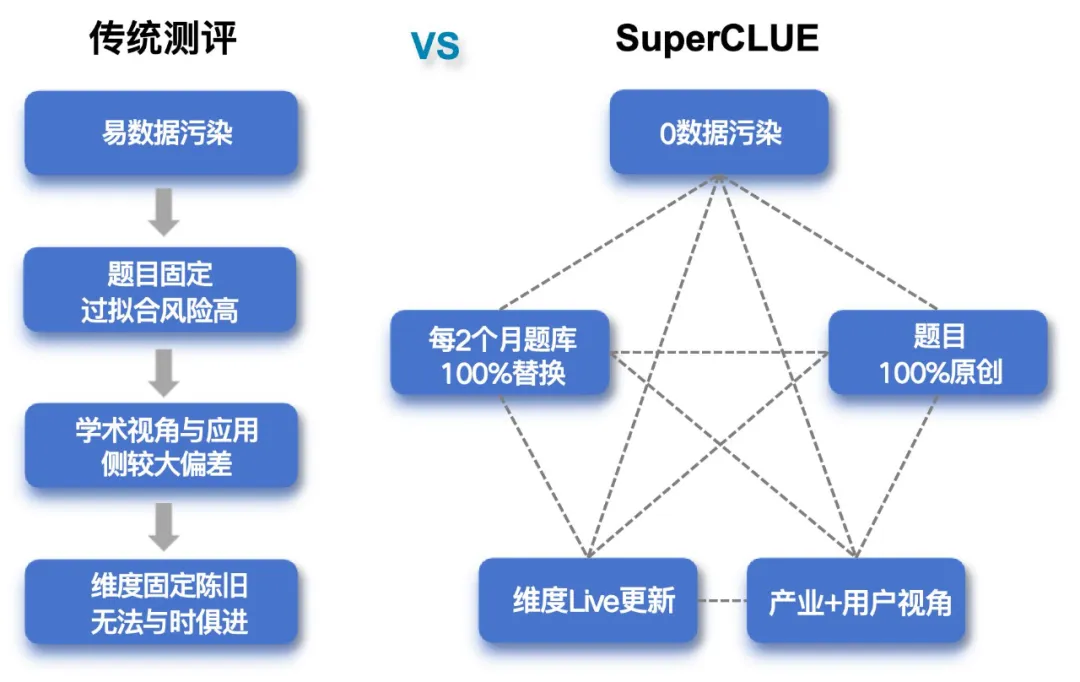
SuperCLUE与传统测评的区别:
SuperCLUE三大特征:
2.SuperCLUE大模型综合测评体系
基于大模型技术和应用发展趋势以及基准测评专业经验,SuperCLUE构建出多领域、多层次的大模型综合性测评基准框架。从基础到应用覆盖:通用基准体系、文本系列基准、多模态系列基准、推理系列基准、Agent系列基准、AI应用系列基准、性能系列基准。为产业、学术和研究机构的大模型研发提供重要参考。

3.SuperCLUE通用测评基准数据集及评价方式
本次2025年上半年报告聚焦通用能力测评,由六大维度构成。题目均为原创新题,总量为1288道简答题。

4.测评模型列表
本次测评数据选取了SuperCLUE-7月测评结果,模型选取了国内外有代表性的45个大模型在7月份的版本。
三、总体测评结果与分析
1.SuperCLUE模型象限
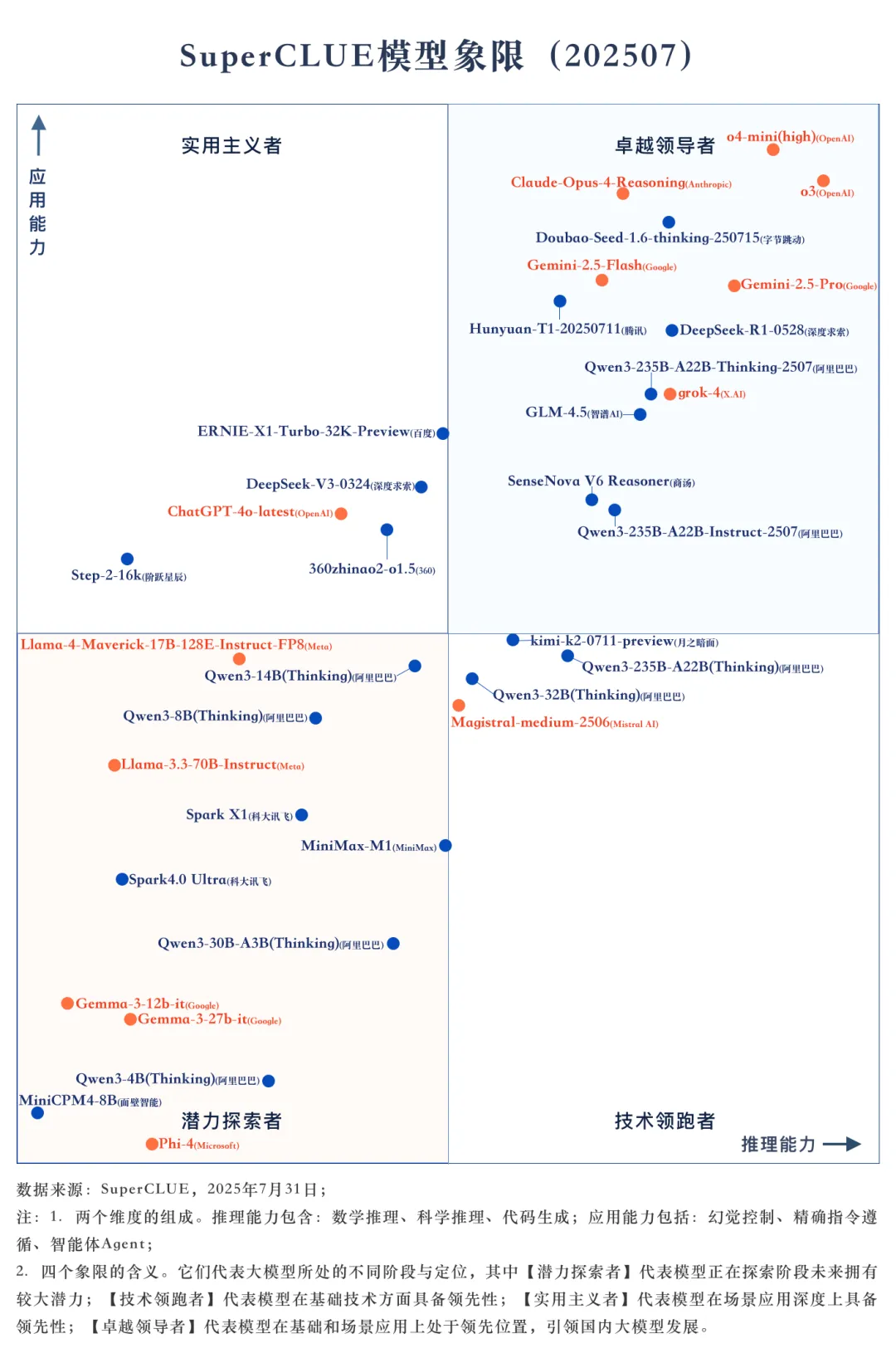
(二) SuperCLUE通用能力测评榜单
(1)总榜单
1.国内外头部模型竞争激烈,海外模型暂时领先。
OpenAI的o3以73.78分位居榜首,o4-mini(high)以73.32分和Google的Gemini-2.5-Pro以68.98分紧随其后。字节跳动的Doubao-Seed-1.6-thinking-250715和深度求索的DeepSeek-R1-0528分别以68.04分和66.15分的总分位列第四和第六,展现出国产大模型的强大实力和快速发展势头。此外,Qwen3-235B-A22B-Thinking-2507、Hunyuan-T1-20250711、GLM-4.5等国产模型也表现不俗,有接近grok-4的趋势。
2.国产开源模型崛起势头强劲。
国产开源模型在本次测评中表现出色,包括DeepSeek-R1-0528、GLM-4.5(63.25分)、多个Qwen3系列模型等。 DeepSeek-R1-0528以66.15分成为开源模型第一,与闭源模型榜首仅差7.63分。在某些细分领域展现出了与顶级闭源模型相媲美的能力,如Qwen3-235B-A22B-Thinking-2507和kimi-k2-0711-preview在代码生成任务分别取得了81.78分和80分,与顶尖模型o4-mini(high)(86.14分)仅相差5-6分左右。
3.国产大模型在智能体Agent和幻觉控制任务上的表现良好,但在推理任务上稍有逊色。
在智能体Agent任务上,Doubao-Seed-1.6-thinking-250715以90.67分领跑全球,GLM-4.5和SenseNova V6 Reasoner以83.58分并列国内第二。在幻觉控制任务上,Doubao-Seed-1.6-thinking-250715、ERNIE-X1-Turbo-32K-Preview和Hunyuan-T1-20250711分别位于国内前三。在推理任务上,海外最好模型为o3,推理任务的分数为75.02分,而国产最好模型DeepSeek-R1-0528仅有65.74分,相差9.28分。
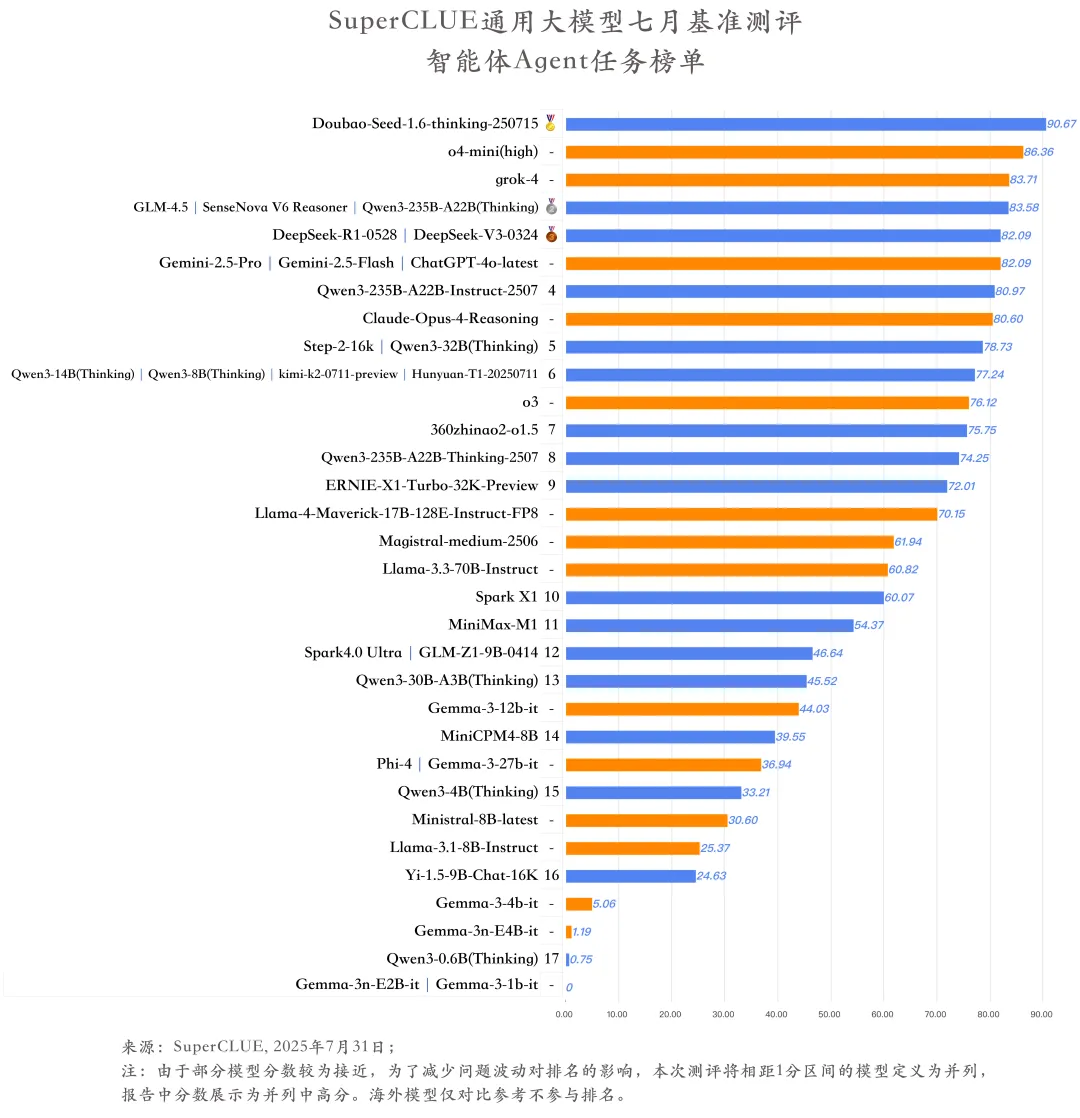
(2)智能体Agent任务榜单
1.国内多款大模型在智能体测评中表现亮眼,赶超国外主流模型。
Doubao-Seed-1.6-thinking-250715在智能体Agent任务中表现尤为突出,以90.67分的成绩高居榜首。国外o4-mini(high)紧随其后,但两者仍存在4分以上的差距。在智能体Agent任务中,国内多款大模型已实现对国外主流模型的赶超,如GLM-4.5、SenseNova V6 Reasoner、Qwen3-235B-A22B(Thinking)的得分均已超越Gemini-2.5-Pro,且接近grok-4。
2.模型得分随任务复杂度上升而降低。
在智能体Agent任务中,随着交互轮次和交互步数的增加,模型的工具调用能力会有所降低。对于轮数为1-3轮的题目,模型在每轮的平均得分均在50分以上,而轮数为4轮时,模型在该轮的平均得分仅有38.97分,下降幅度超过14分。随着交互步数的增加,模型的平均得分也呈现逐渐下降的趋势。
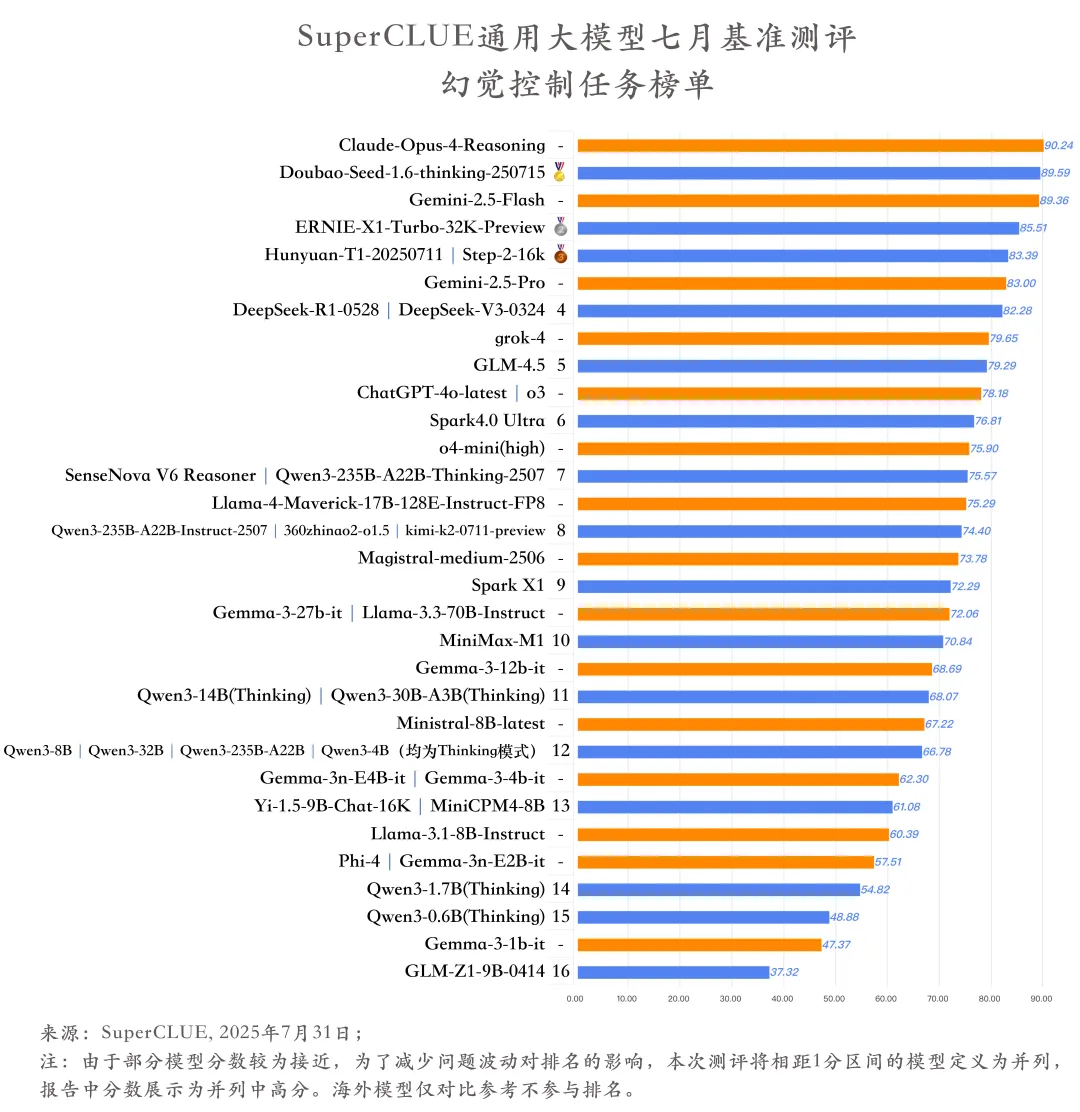
(3)幻觉控制任务榜单
1.国内外头部模型差距在幻觉控制任务上差距较小。
国外头部模型Claude-Opus-4-Reasoning以 90.24 分的高分位居榜首,国内模型Doubao-Seed-1.6-thinking-250715紧随其后,以 89.59 分的成绩与之仅相差 0.65 分。另外,国产模型ERNIE-X1-Turbo-32K-Preview、Hunyuan-T1-20250711和Step-2-16k均有超过海外顶尖模型Gemini-2.5-Pro的表现。
2.任务开放性越高,模型的幻觉越严重。
对于幻觉控制任务中的不同类别,模型的平均得分差异显著:文本摘要(89.82分)、阅读理解(78.31分)、多文本问答(78.49分)因需紧扣原文,相对而言得分较高,幻觉率较低;而对话补全(43.09分)因需推理或自由生成,幻觉风险大幅增加,模型的平均得分相对较低。任务开放性与幻觉率呈现出一定的相关性。
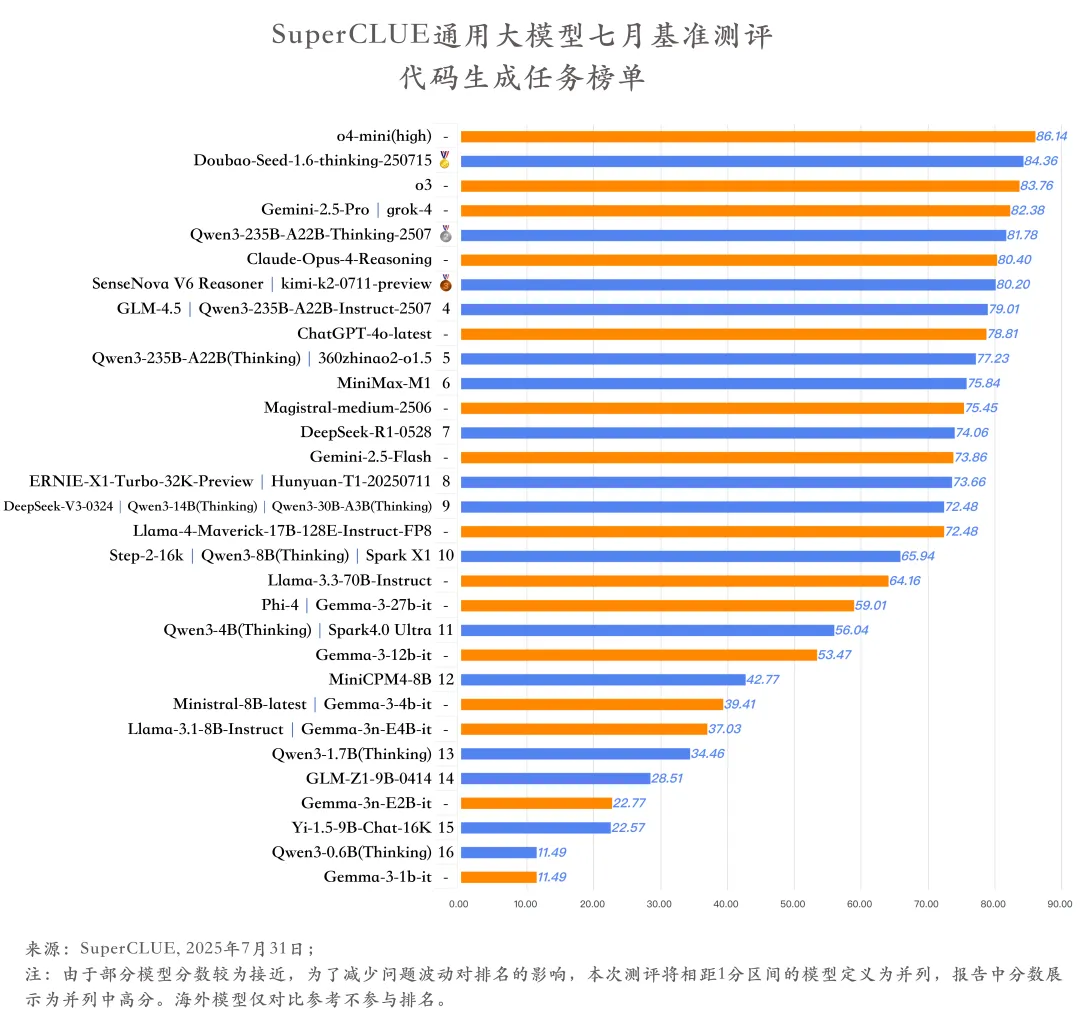
(4)代码生成任务榜单
1.海外头部模型相较国产模型在代码生成任务上有一定的优势。
在代码生成任务榜单中,前五名有4个海外模型,仅有一个国产模型。o4-mini(high)以86.14分位居榜首,国产模型Doubao-Seed-1.6-thinking-250715已以84.36分的成绩位于第二,o3、Gemini-2.5-Pro和grok-4三个海外模型占据代码生成任务榜单的第3-5名。国内外头部模型在该任务上有一定的差距。
2.开源模型与闭源模型差距显著。
从代码生成任务的整体表现来看,所有开源模型的平均分(54.94分)与闭源模型的平均分(76.16分)相差约21分。另外,在该任务上的前5名均为闭源模型,说明当前闭源模型在代码生成能力上仍占据明显的优势,而开源模型在代码生成任务上还有一定的优化空间。
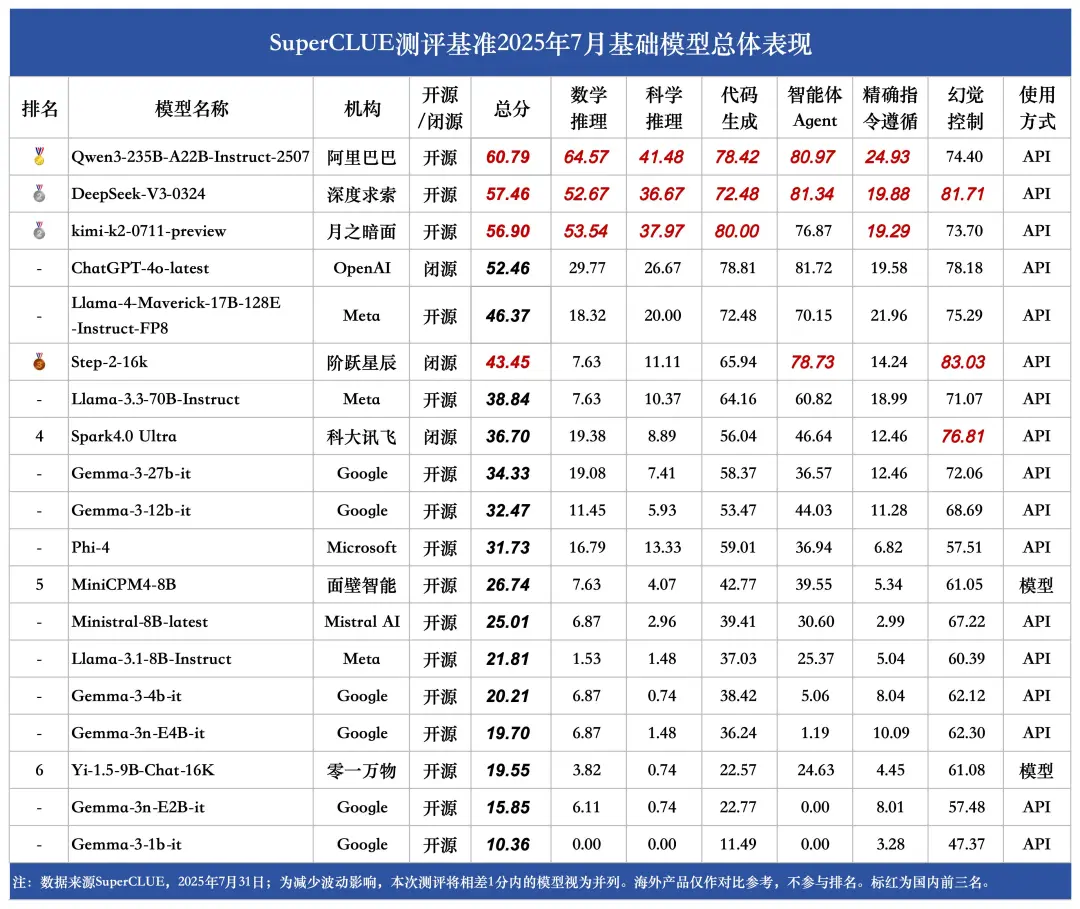
(5)基础模型榜单
1.国内基础模型整体表现优于国外。
国内大模型Qwen3-235B-A22B-Instruct-2507以超60分的成绩位居榜首,与ChatGPT-4o-latest(52.46分)拉开超8分的差距。国内大模型DeepSeek-V3-0324同样表现不俗,在各项任务中均稳居国内前三。
2.关键领域国内模型优势显著。
在数学推理方面,Qwen3-235B-A22B-Instruct-2507(64.57分)更是以压倒性优势领先ChatGPT-4o-latest(29.77分),高出34.8分。
3.国内模型部分任务仍需优化。
虽然国内大模型Qwen3-235B-A22B-Instruct-2507、DeepSeek-V3-0324、kimi-k2-0711-preview、Step-2-16k在总体表现上占据前三,但在代码生成、智能体Agent和幻觉控制任务中,均不同程度落后于国外表现最好的ChatGPT-4o-latest。
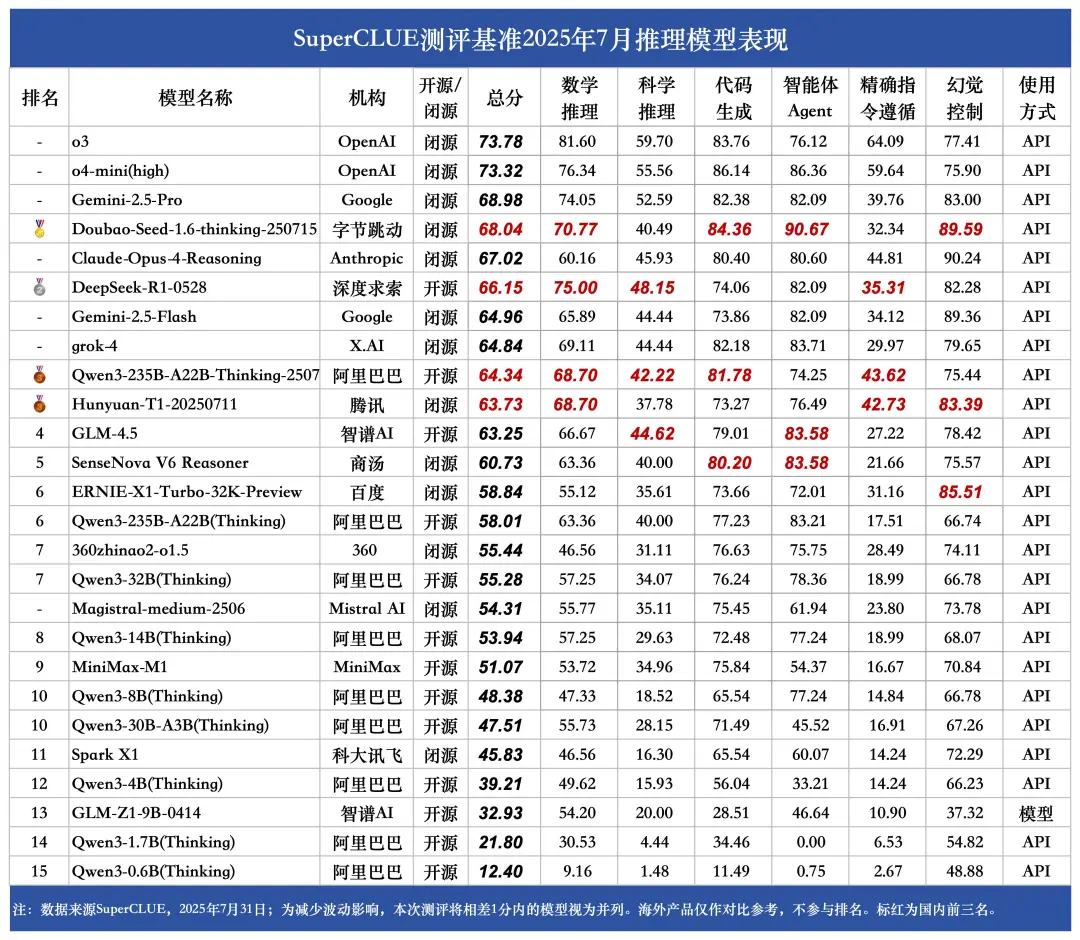
(6)推理模型榜单
1.国际头部模型领跑,国内模型紧追不舍。
OpenAI的o3、o4-mini(high)占据榜单前两位,海外大厂模型在推理总分上优势明显,国内模型如DeepSeek-R1-0528、Doubao-Seed-1.6-thinking-250715等模型虽紧追不舍,但仍存在一定差距,清晰呈现出推理模型领域"国际头部领跑,国内奋力追赶"的梯队格局 。
2.国产模型亮点纷呈,部分领域接近国际顶尖水平。
国内大模型Doubao-Seed-1.6-thinking-250715在代码生成任务中斩获84.36的高分,超越了多数国内外同类模型,与国外表现最佳的o4-mini(high)(86.14分)仅相差1.78分。国内大模型Qwen3-235B-A22B-Thinking-2507则在三项任务中均有不俗表现,且每项成绩均位列国内大模型前三。
3.各维度能力发展不均衡。
从各模型在不同维度的得分来看,能力发展不均衡现象明显。如代码生成维度,DeepSeek-V3-0324得分84.81,而部分模型得分较低,差距巨大。在精确指令遵循维度,模型间分数差异也较为显著。这种不均衡体现了不同模型在能力侧重上的差异,也反映出大模型在追求综合能力提升时,仍面临各维度能力协调发展的挑战。
(7)开源模型榜单
1.国内开源模型主导地位凸显。
在7月SuperCLUE开源模型测评中,深度求索的DeepSeek-R1-0528以66.15分位居榜首;阿里旗下多款Qwen3系列模型表现亮眼,其中Qwen3-235B-A22B-Thinking-2507、Qwen3-235B-A22B-Instruct-2507、Qwen3-235B-A22B(Thinking)分别位列第二、第四、第五,国内模型的领先优势进一步巩固。
2.机构竞争格局呈现多元态势。
阿里在开源模型领域的布局成果显著,多款Qwen3系列模型跻身前列;此外,深度求索、智谱AI、月之暗面、MiniMax等机构也有模型入围,展现出行业内多主体竞逐的态势,头部机构各自拥有优势模型,竞争格局日趋丰富。
3.模型专项能力各有突出侧重。
DeepSeek-R1-0528在数学推理、科学推理和幻觉控制三项任务中均以高分领跑国内外开源模型;Qwen3-235B-A22B-Thinking-2507则在代码生成和精确指令遵循任务中位居第一;智能体Agent任务中,GLM-4.5以83.58分夺冠,超出国内头部模型DeepSeek-R1-0528(82.09分)1.49分 。 整体来看,各模型在专项能力上的差异化竞争特征明显。
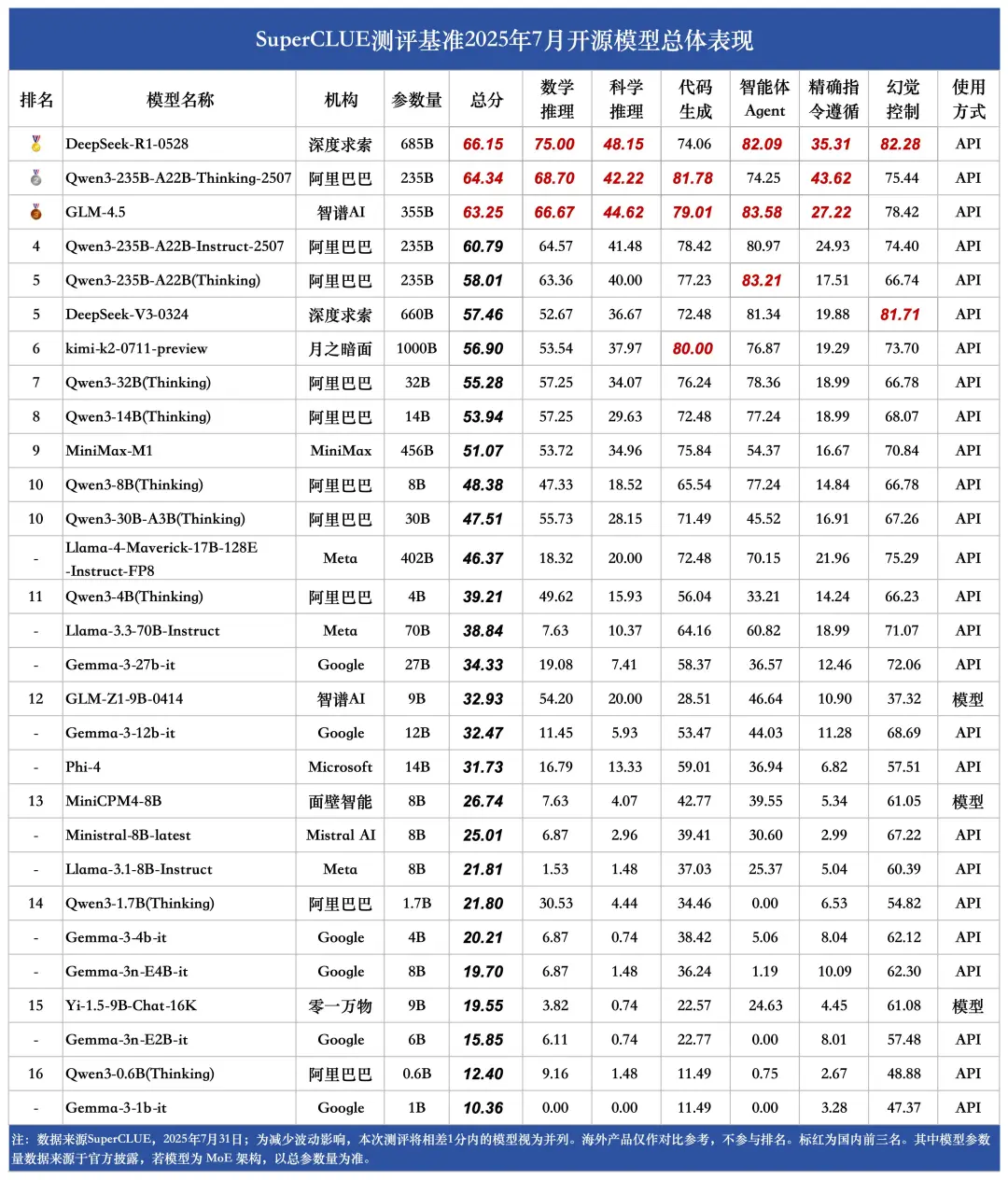
(8)推理任务榜单
1.榜单前三均为海外头部模型,优势显著。
o3、o4-mini(high)和Gemini-2.5-Pro分别以75.02分、72.68分和69.67分获得推理任务榜单的前三。DeepSeek-R1和Doubao-Seed-1.6-thinking-250715分别以65.74分和65.21分获得国内金牌,但与海外头部模型相比,差距还比较显著。
2.国内头部模型在推理任务上竞争激烈,推理能力差距较小。
在推理任务榜单中,DeepSeek-R1和Doubao-Seed-1.6-thinking-250715获得金牌,Qwen3-235B-A22B-Thinking-2507和GLM-4.5获得银牌,Qwen3-235B-A22B-Instruct-2507和SenseNova V6 Reasoner获得铜牌,极差不到5分,国内头部模型的推理能力差距较小。
3.国内开源模型的推理能力显著优于海外开源模型。
国内开源模型有5个推理任务得分在60分以上,但海外开源模型最高分不到37分,领先幅度接近23分,说明国内开源模型的推理能力要显著优于海外开源模型。
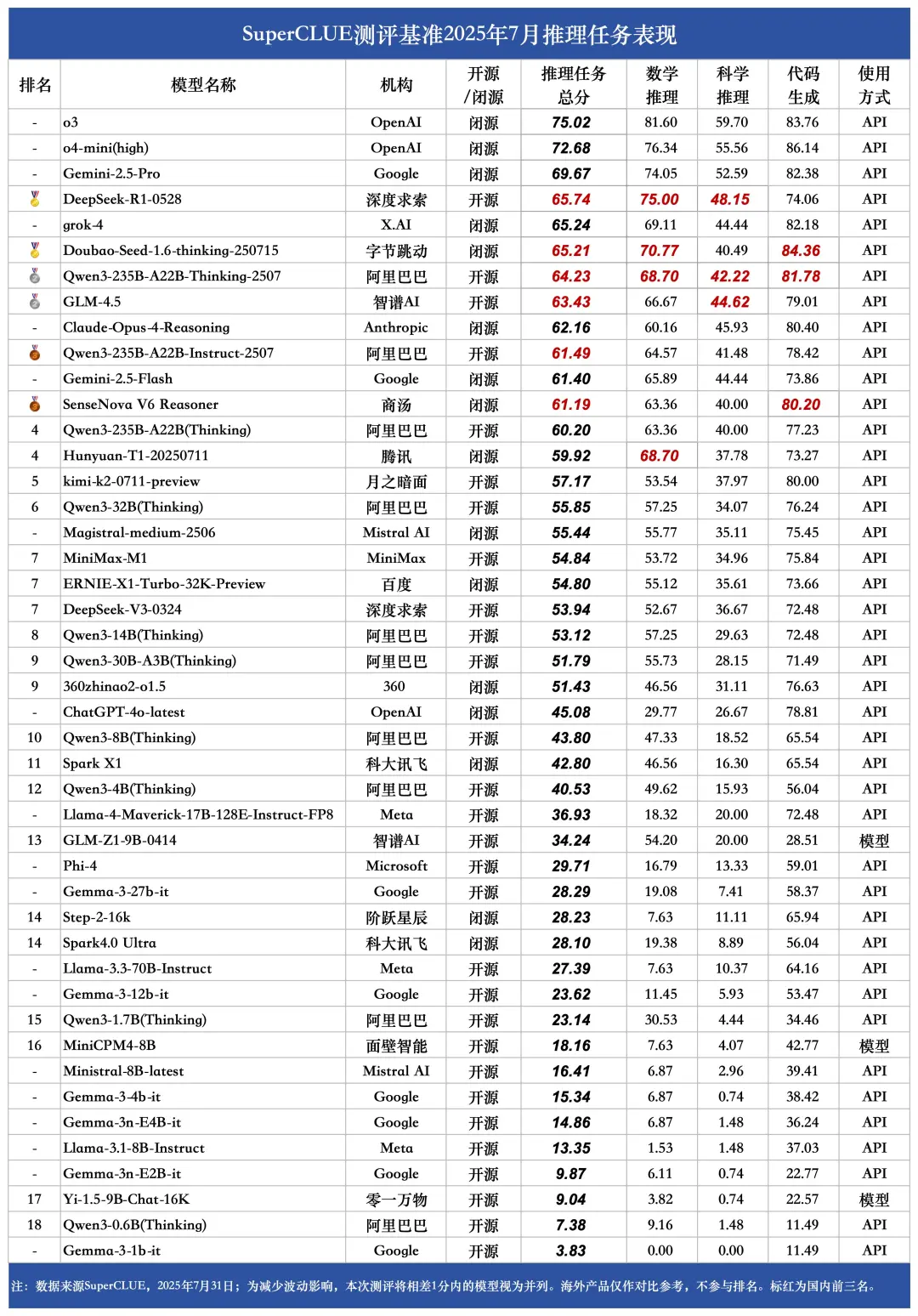
(9)10B级别小模型榜单
1.Qwen3-8B(Thinking)领跑国内10B级小模型。
在10B级别的小模型榜单中,前四均为国内小模型,其中Qwen3 - 8B(Thinking)以48.38分的总分位居榜首。该模型在各项任务中均跻身国内大模型前三甲,有力打破了"参数规模小=性能表现弱"的固有认知。
2.任务表现分化显著,小模型"长短板"特征直观显现。
同一模型在不同任务中的得分呈现显著差异。如Qwen3-4B(Thinking)在幻觉控制任务中能取得66.23分的优异成绩,但在精确指令遵循任务上仅得14.24分,这一鲜明对比,直观展现了小模型在任务适配能力上的"长短板"特征。
3.国内头部小模型大幅领先国外竞品。
国内头部小模型表现抢眼,包揽榜单前四,Qwen3-8B(Thinking)远超国外表现最佳的Ministral-8B-latest(25.01分),领先优势达18.37分,充分彰显了国内小参数模型的强劲实力。
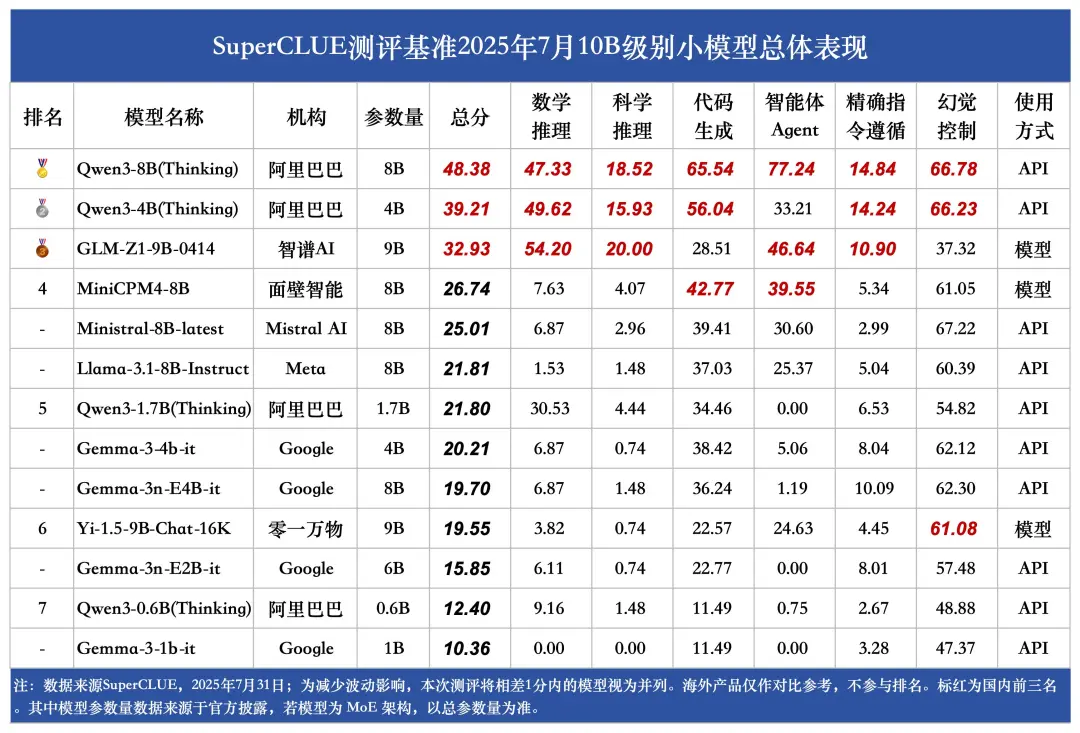
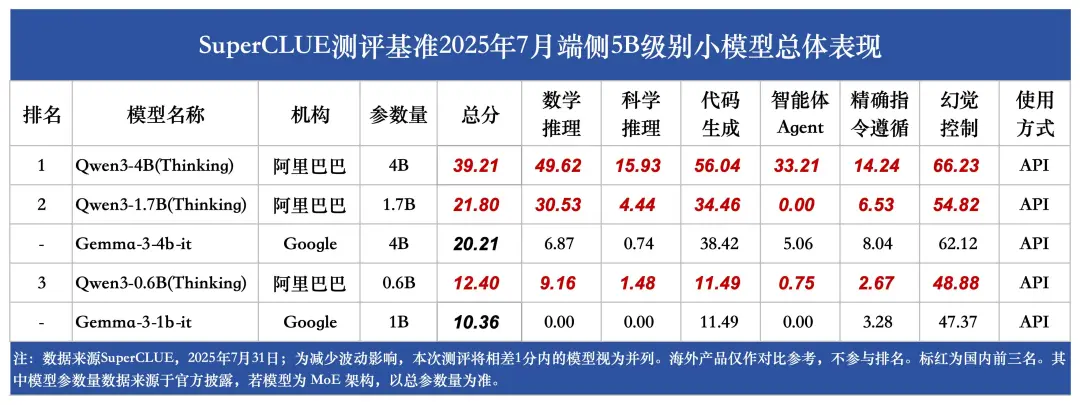
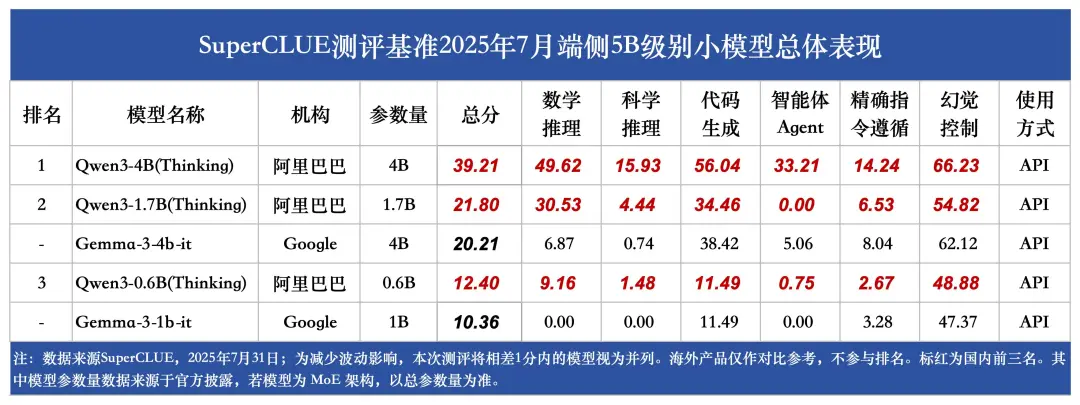
(10)端侧5B级别小模型榜单
2025年端侧小模型快速发展,已在设备端侧(非云)上实现本地运行,其中PC、手机、智能眼镜、机器人等大量场景已展现出极高的落地可行性。国内端侧小模型进展迅速,相比国外小模型,国内小模型在中文场景下展现出更好的性能表现。
1.阿里巴巴等国内机构的小模型占据主流地位。
Qwen3 - 4B(Thinking)在端侧5B级别小模型领域表现抢眼,以39.21分的高分位居榜首,且在各项细分任务中均展现出卓越实力,全部位列第一。尤其在幻觉控制方面,该模型取得了超过60分的优异成绩,充分彰显了小模型的巨大潜力。
2.围绕数学推理、代码生成等关键任务,可清晰看到小模型在"有限参数"约束下的能力边界。
如Qwen3-1.7B(Thinking)在代码生成任务中获得34.46分的不错成绩,但在智能体 Agent 任务中得分却为 0,这一差异直观暴露了端侧小模型在复杂场景适配中存在的难点。
(三) SuperCLUE大模型性价比区间分布
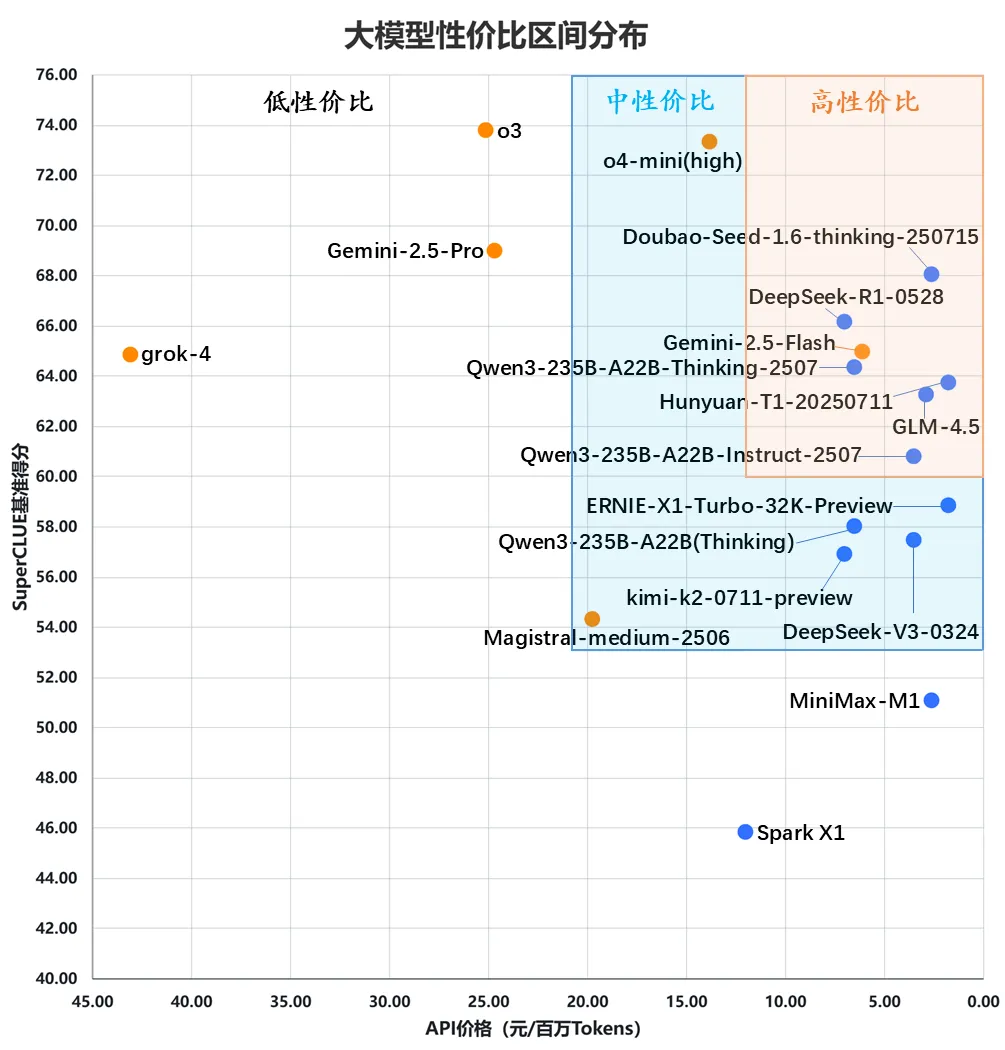
(1)国内头部模型较海外模型呈现出更高的性价比
国内大模型展现出强劲的性价比优势,如Hunyuan-T1-20250711、GLM-4.5、Doubao-Seed-1.6-thinking-250715、Qwen3-235B-A22B-Thinking-2507。海外模型Gemini-2.5-Flash与国内模型Qwen3-235B-A22B-Thinking-2507、DeepSeek-R1-0528在得分和价格上不相上下,共同处于高性价比区间。
(2)国内中性价比模型能力待提升
国内处于中性价比区间的模型,价格普遍控制在9元/百万Tokens以内,部分超低价模型甚至低于3元/百万Tokens,但这类模型的基准得分仅在 56-60 分之间,整体能力还有较大的提升空间。
(3)海外头部模型性价比较低
尽管o3、o4-mini(high)以超 70 分的成绩领跑,但二者价格显著高于其他模型。其中,o3的价格比国内表现最优的Doubao-Seed-1.6-thinking-250715高出了超20元/百万Tokens以上,性价比相对较低。
(四) SuperCLUE大模型综合效能区间分布
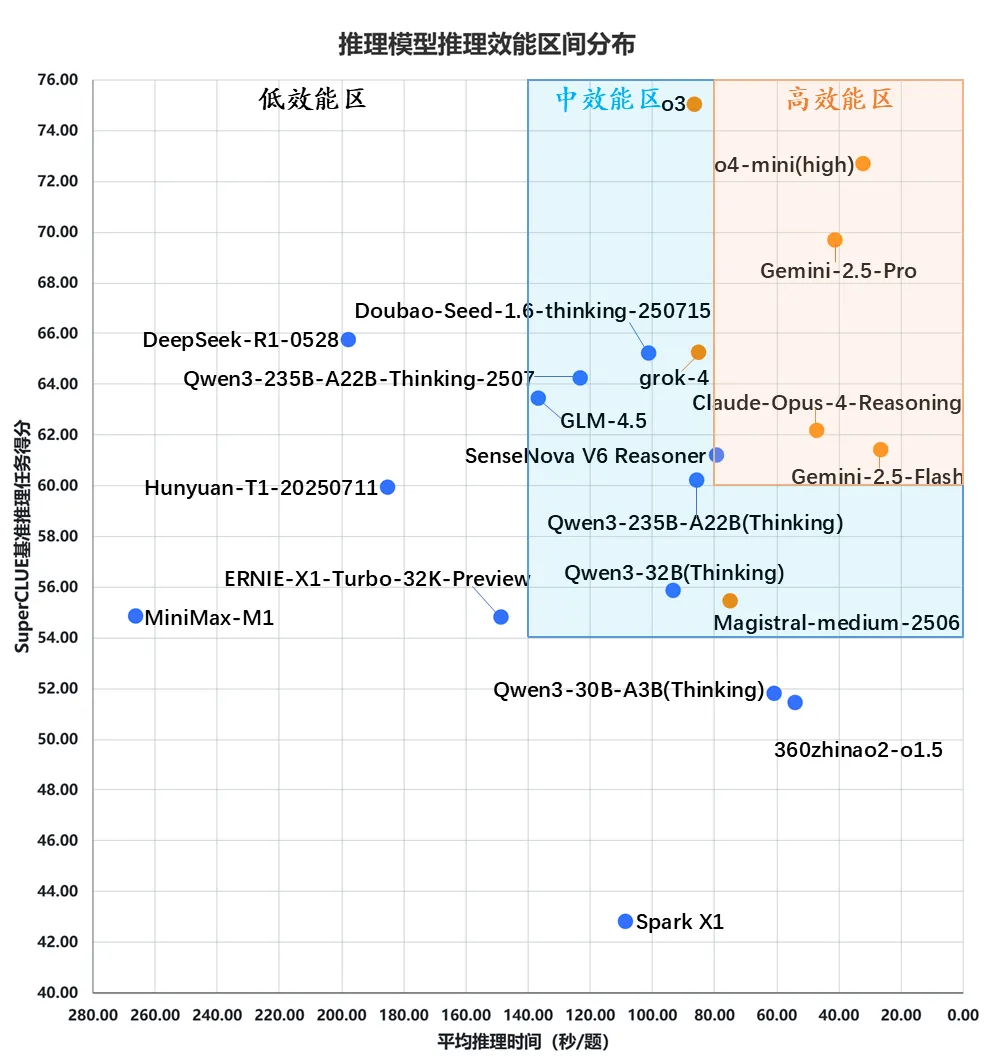
(1)国外头部模型稳居高效能区,展现强劲应用实力。
从推理效能分布图可见,国外头部模型o4-mini(high)、Gemini-2.5-Pro、Gemini-2.5-Flash、Claude-Opus-4-Reasoning的平均推理时间均控制在 60 秒以内,且推理任务得分均突破 60 分,完全符合「高效能区」标准,充分展现出极强的实际应用效能。
(2)国内头部模型仅有SenseNova V6 Reasoner趋近高效能区。
国内头部模型中,SenseNova V6 Reasoner在推理时间与基准得分的综合效能方面表现最为突出,已处于「高效能区」的边界位置,彰显了国内模型的不俗实力。国内大模型Qwen3-235B-A22B(Thinking)同样表现出色,紧随其后。
(3)部分国内模型得分反超国外,但耗时差距明显。
国内大模型如Doubao-Seed-1.6-thinking-250715、Qwen3-235B-A22B-Thinking-2507、GLM-4.5、DeepSeek-R1-0528在推理任务得分上已实现对部分国外头部模型的反超,但在平均推理时间的耗时上却存在着较大差距。
(五) 代表性模型分析
(1)代表模型一:Doubao-Seed-1.6-thinking-250715
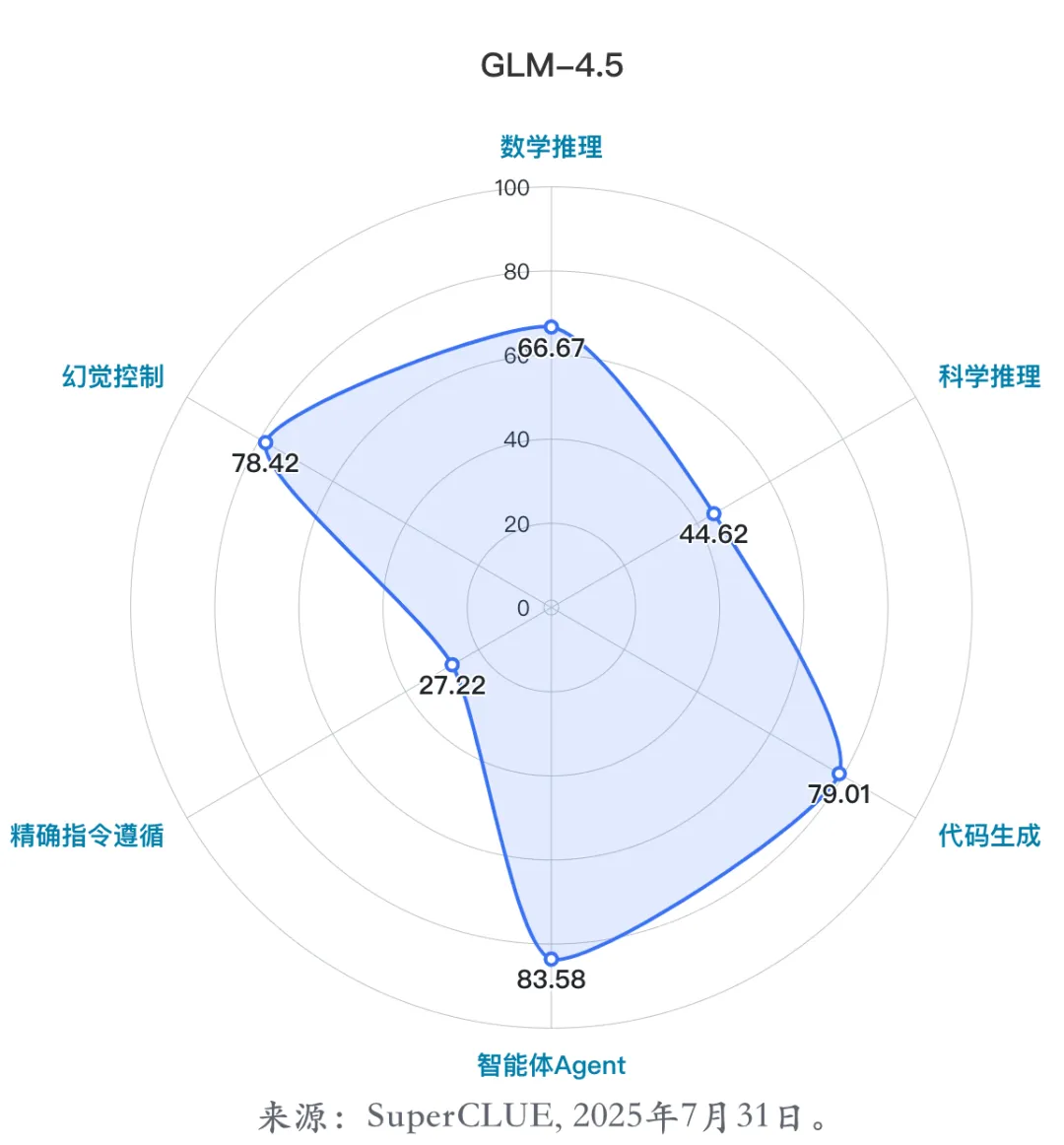
Doubao-Seed-1.6-thinking-250715是由字节跳动在2025年7月推出的最新版本的多模态深度思考模型。
技术亮点:
该模型在思考能力上进行了大幅强化, 对比上一代深度理解模型,在编程、数学、逻辑推理等基础能力上进一步提升, 支持视觉理解。
能力优势:
- 擅长通用 Agent 任务:在SuperCLUE智能体Agent任务排名全球第一;
- 擅长幻觉控制和代码任务:在SuperCLUE幻觉控制、代码生成任务均排名全球第二,国内第一;
- 擅长数学推理:在SuperCLUE数学推理任务排名国内第二。
适配应用场景:
智能体、复杂推理任务、代码编程、科学研究、中文创作
(2)代表模型二:DeepSeek-R1-0528
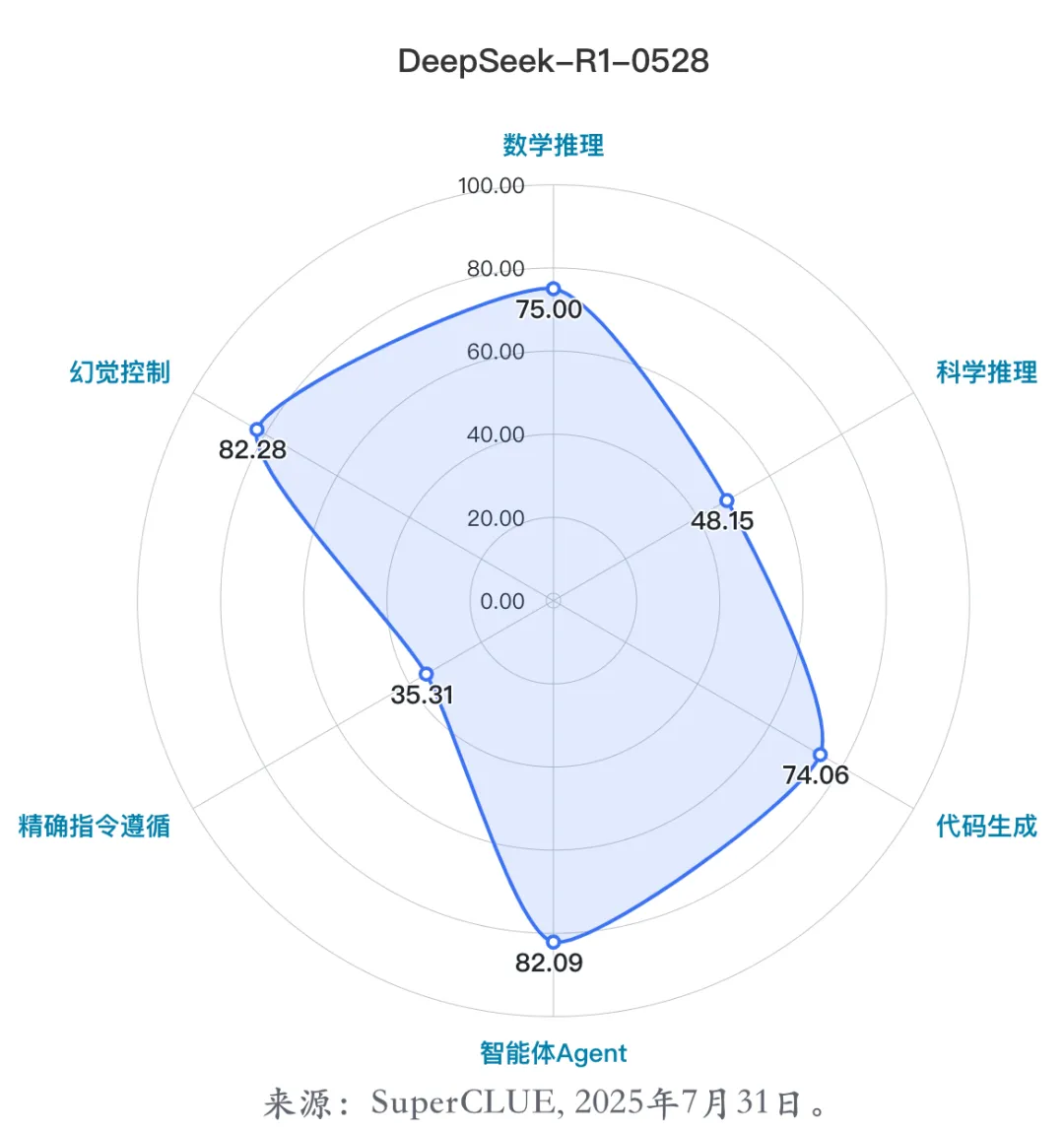
DeepSeek-R1-0528是由深度求索在2025年5月28日发布的DeepSeek-R1小版本升级模型,该模型使用 2024 年 12 月所发布的 DeepSeek V3 Base 模型作为基座,但在后训练过程中投入了更多算力,显著提升了模型的思维深度与推理能力。
技术亮点:
模型参数为 685B(其中 14B 为 MTP 层),采用 MLA、MoE 等架构提升推理效率与长上下文处理能力,通过无监督强化学习等训练方式增强推理性能。
能力优势:
a.擅长复杂推理:在SuperCLUE数学推理、科学推理任务均排名国内第一;
b.擅长精确指令遵循任务:在SuperCLUE精确指令遵循任务均排名国内前三;
c.擅长通用 Agent 任务:在SuperCLUE智能体Agent任务排名国内前三。
适配应用场景:
复杂推理任务、代码编程、智能体、中文创作
(3)代表模型三:GLM-4.5
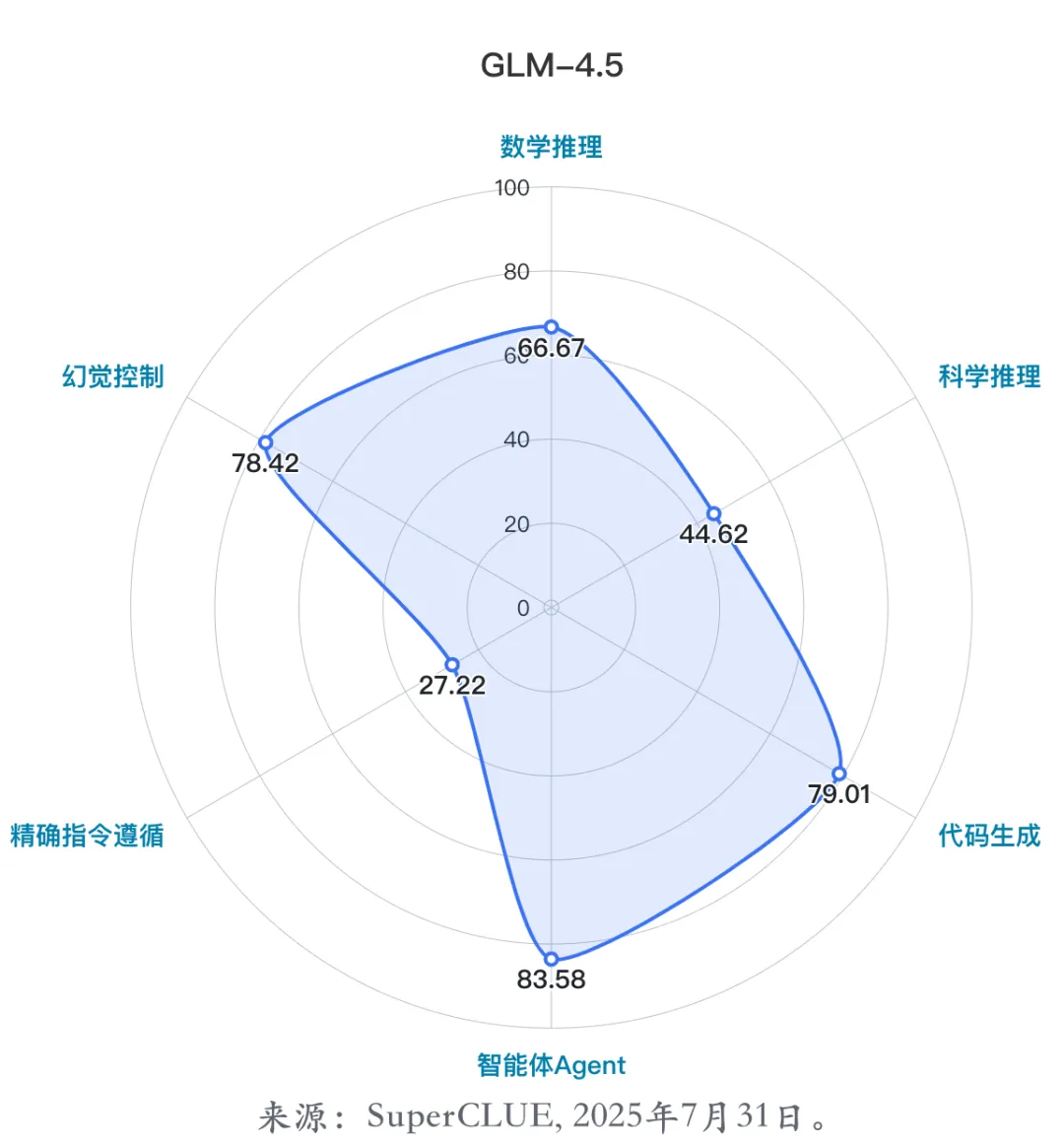
GLM-4.5是由智谱华章在2025年7月28日正式发布并开源的最新旗舰模型,该模型采用MoE架构,该模型拥有3550亿个总参数和320亿个激活参数,将推理、编码和代理功能统一到一个模型中,以满足快速发展的代理应用日益复杂的需求。
技术亮点:
在 MoE 层中使用了无损平衡路由和 S 型门控;使用Muon优化器、QK-Norm技术、分组查询注意力(Grouped-Query Attention)与部分旋转位置编码(partial RoPE),并加入多令牌预测层(MTP),提升训练效率和推理性能。
能力优势:
a.擅长通用 Agent 任务:在SuperCLUE智能体Agent任务排名国内第二;
b.擅长复杂推理任务:在SuperCLUE科学推理任务排名国内第二。
适配应用场景:
智能体、复杂推理任务、代码编程
(4)代表模型四:kimi-k2-0711-preview
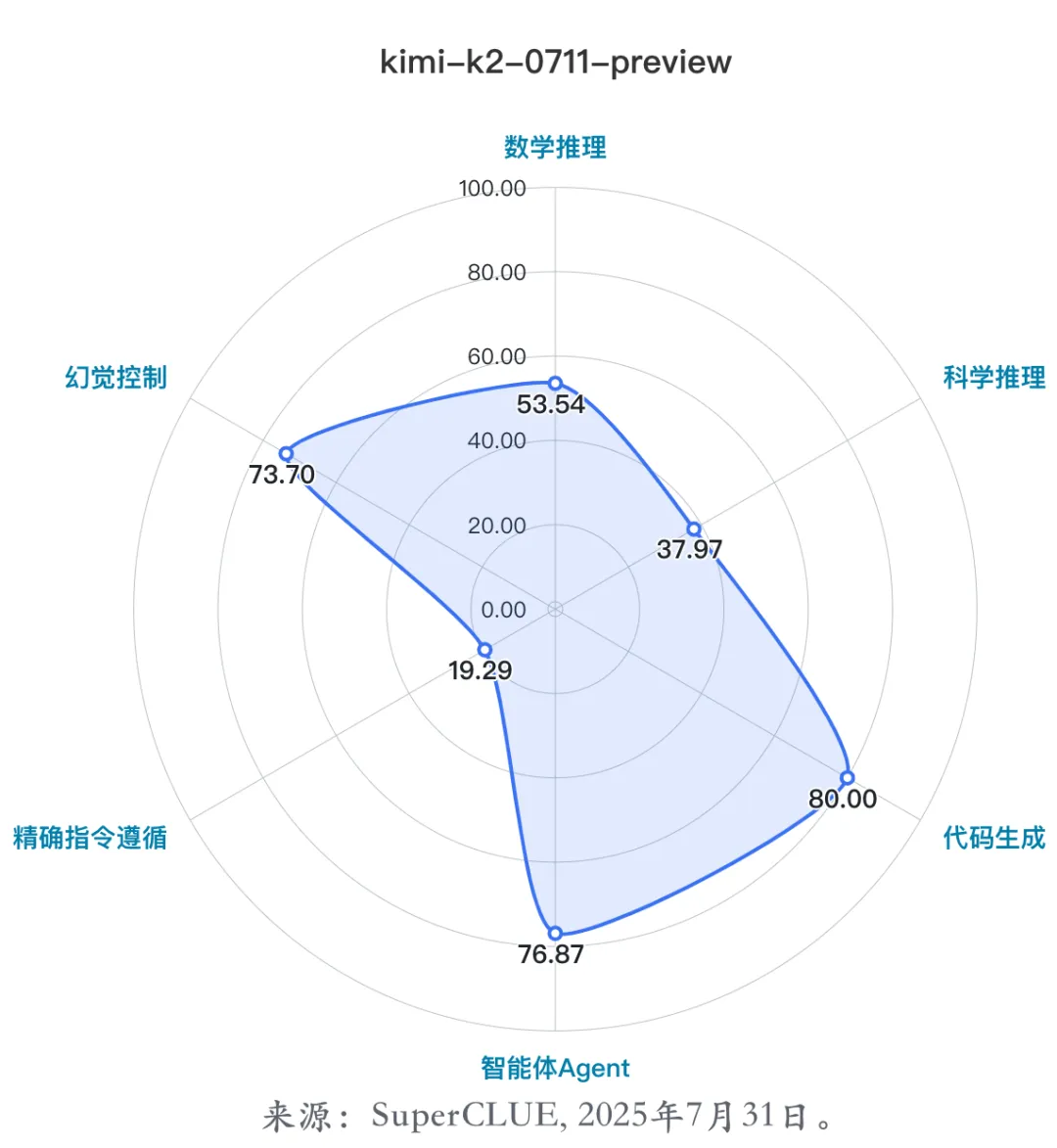
kimi-k2-0711-preview是由月之暗面在2025年7月11日正式发布并开源的最新旗舰模型,该模型采用MoE架构,总参数 1T,激活参数 32B**。**
技术亮点:
a.预训练阶段使用 MuonClip 优化器实现万亿参数模型的稳定高效训练,有效提高 Token 利用效率,找到新的 Scaling 空间;
b.大规模 Agentic Tool Use 数据合成;
c.引入自我评价机制的通用强化学习。
能力优势:
a.擅长代码任务:在SuperCLUE代码生成任务排名国内第三;
b.擅长推理任务:在SuperCLUE数学推理、科学推理任务排名基础模型前三。
适配应用场景:
智能体、复杂推理任务、代码编程
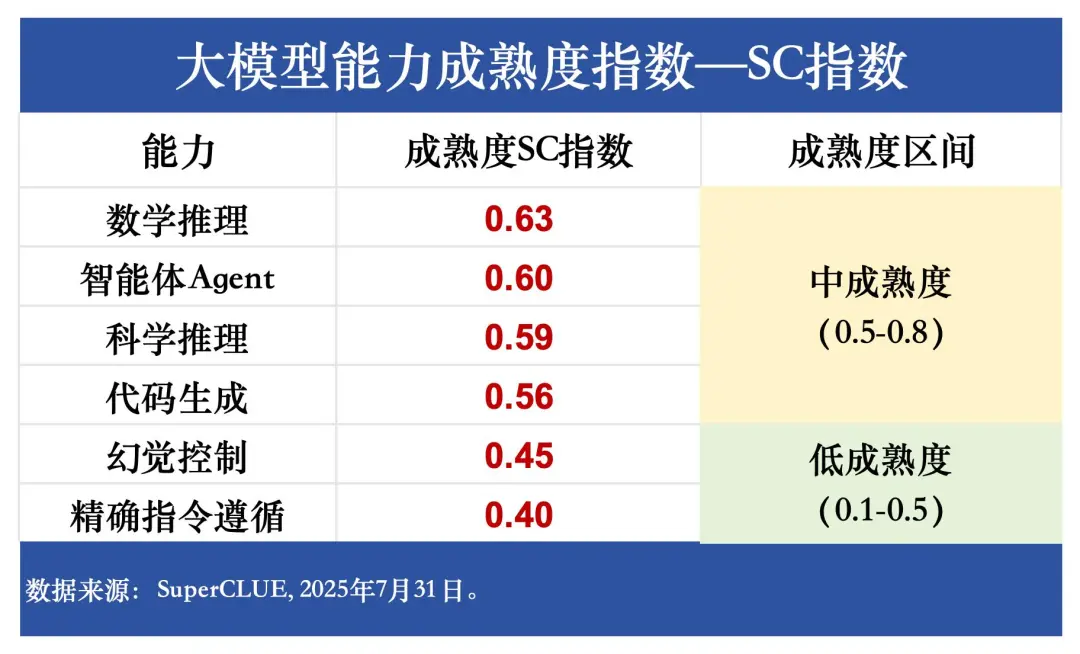
(六) 国内大模型成熟度-SC成熟度指数
(1)高成熟度能力
高成熟度指大部分闭源大模型普遍擅长的能力,SC成熟度指数在0.8至1.0之间。
在本次测评的六大任务中,当前国内闭源大模型成熟度较高的任务暂时没有。
(2)中成熟度能力
中成熟度指的是不同大模型能力上有一定区分度,但不会特别大。SC成熟度指数在0.5至0.8之间。
当前国内大模型表现出中成熟度的能力是【数学推理】、【智能体Agent】、【科学推理】和【代码生成】,还有一定优化空间。
(3)低成熟度能力
低成熟度指的是少量大模型较为擅长,很多模型无法胜任。SC成熟度指数在0.1至0.5之间。
当前国内大模型低成熟度的能力是【幻觉控制】和【精确指令遵循】。
SC成熟度指数计算方法说明:
-
1.计算相对差距 :对于每个任务,首先找出所有国产闭源模型中的最高分。然后,计算每个模型的分数与这个最高分之间的相对差距。这个差距是通过 (最高分 - 模型分数) / 最高分 来计算的。这个值反映了每个模型与顶尖水平的距离。
-
2.计算累积差距 :将一个任务中所有国产闭源模型的相对差距加起来,然后除以模型的数量,得到一个平均的相对差距,称之为"相对差距累积值"。这个值代表了在这个任务上,所有国产闭源模型表现的平均离散程度。
-
3.归一化处理 :为了消除不同任务之间难度和评分标准差异带来的影响,需要对"相对差距累积值"进行归一化处理。这里采用的是最小-最大归一化方法。首先,在所有国产闭源模型的相对差距中,找出最小值和最大值。然后,通过 (相对差距累积值 - 最小相对差距) / (最大相对差距 - 最小相对差距) 这个公式,将累积差距缩放到 0, 1 的区间内。
-
4.计算最终成熟度 :最后,用 1 减去归一化后的差距,即 1 - 归一化差距 ,就得到了最终的任务成熟度。这个值越高,代表该任务的整体发展水平越高,模型间的平均表现越接近顶尖水平。
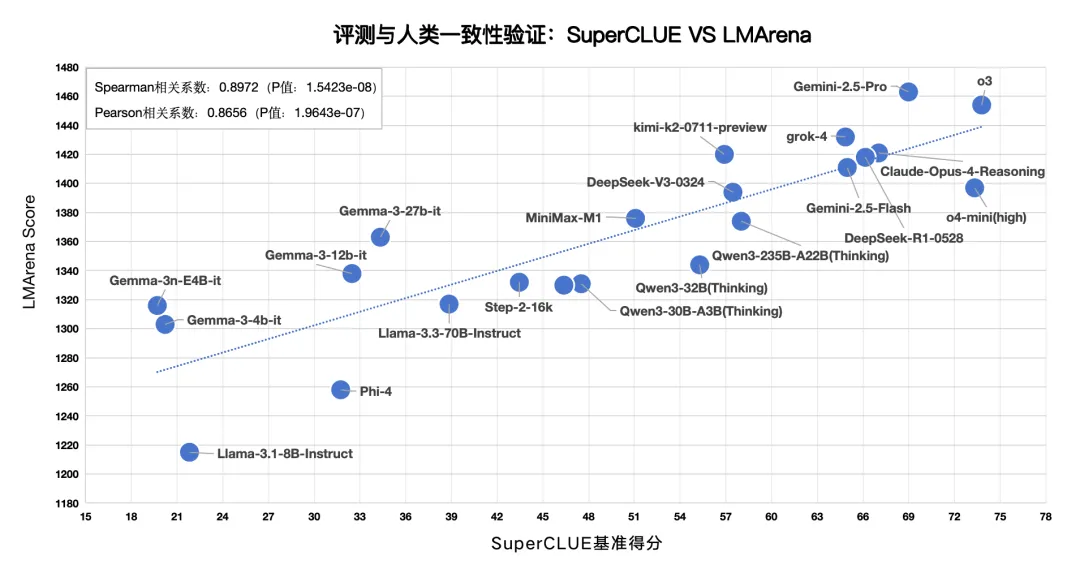
(七) 评测与人类一致性验证
LMArena是当前英文领域较为权威的大模型排行榜,由LMSYS Org开放组织构建,它以公众匿名投票的方式,对各种大型语言模型进行对抗评测。
我们将SuperCLUE得分与LMArena得分进行相关性计算,得到:
斯皮尔曼相关系数:0.8972,P值:1.5423e-08;
皮尔逊相关系数:0.8656,P值:1.9643e-07。
注:
斯皮尔曼相关系数:用于衡量两个变量之间的单调关系,取值为-1,1,该系数的绝对值越接近1表示两个变量之间的相关性越强;
皮尔逊相关系数:用于衡量两个连续变量之间的线性相关程度,取值为-1,1,该系数的绝对值越接近1表示两个变量之间的相关性越强。