本文目录:
最近我在思考一个问题为什么大家都在卷多模态,却很少有人想清楚多模态到底是什么?
看起来,多模态就是什么都能处理,包括文本、图像、视频及音频。各大厂商在这个方向上军备竞赛,模型参数越来越大,支持的模态越来越多,但实际应用中却往往事与愿违。一个通用多模态模型虽然什么都能做一点,却往往什么都做不好,让现在的AI识别一张财务报表中的信息,它的准确率可能还不如十年前的专业OCR软件,这背后的原因困惑了我好久。
近期,在PRCV学术会议上,合合信息提出了"多模态文本智能技术"这个概念,背后的思想是对多模态认知的一个根本性的重新定义。
与市面上铺天盖地的多模态大模型不同,合合信息没有追求模态的广度,反而抛出了一个更本质的问题:无论是图像、视频还是自然场景,文本承载的结构化语义信息,始终是AI理解世界的核心枢纽,也就是说文本是通向AGI的必经之路。现如今我们追求的大模型能力越来越强,但信息结构化和语义关联的能力反而在退化。ChatGPT可以写代码作诗,但让它理解一张三表合并的财务报表,它往往还是会"幻觉",这正是多模态文本智能存在的根本价值所在。
一、从"看见"到"读懂"的认知跨越
1.重新定义"文本"的边界
传统认知里,文本等同于文字,但合合信息把这个概念往外扩了一圈:图片里有文本、视频里有文本、合同印章位置也是文本,只要承载结构化语义的,就可以看做文本。
AI要理解世界,最终需要的不是孤立的视觉信号或听觉信号,而是这些信号背后的语义关联。一份文档中,文字、表格、图片的信息从来不是孤立存在的------合同的条款效力与签名位置相关,财报的数据陈述需对照表格验证,医疗报告的诊断结论依赖影像佐证。多模态文本智能技术要做的,就是把这些散落的信息串起来,让机器像人一样理解文档。
2.三层架构支撑全链路智能
多模态文本智能技术构建了"感知-认知-决策"三层架构。感知层负责看清楚,认知层负责读懂,决策层负责去干。三层递进,最后形成闭环。
传统OCR就是个识字工具,看见啥就输出啥,不管对不对。多模态文本智能技术不一样,系统会主动判断:这图片质量不行,得先处理一下;这个信息有问题,得纠个错。扫描全能王的智能高清滤镜就是典型案例:系统根据用户意图,自主分析图像质量下降情形,动态选择最优处理路径和算法,处理光线不足、颜色失真、角度倾斜等十余种问题。
二、底层视觉处理
底层视觉处理听着不起眼,但它就像地基,地基不牢后面全白搭。现实世界中的文档图像往往面临各种质量问题,如果这些问题得不到妥善处理,后续的识别和理解都会大打折扣。
1.文字图像质量提升
现实中拍摄的文档图像往往存在各种问题,一张倾斜的纸质文档,边缘还有手指遮挡。经过处理后,手指被智能去除,页面自动矫正,滤镜让文字变得清晰。看着简单,其实得协调好几个算法:先识别手指在哪儿,抠掉;再把歪的页面摆正;最后加个滤镜让字看得清,哪步没做好都不行。
2.摩尔纹去除
摩尔纹是拍摄电子屏幕时产生的周期性干扰图案,这个问题困扰OCR行业很久了。合合信息的算法通过分析摩尔纹的周期规律与文字特征,精准分离干扰信号,在去除摩尔纹的同时完整保留文字笔画细节。
摩尔纹是周期性的,其频谱集中在特定频率;而文字笔画是随机纹理,频谱分散。通过Fourier Transform或Wavelet Transform 分析图像,可以在频域中识别出摩尔纹的峰值,然后用陷波滤波器精准去除这个频率成分。
除此之外摩尔纹的周期可能随视角变化而变化 。这时候需要用更强的模型来预测摩尔纹掩码,使得去除效果对摩尔纹周期的变化更鲁棒。一般我们都用去除摩尔纹后,文字的清晰度保持率 和笔画完整率 ,去评估效果的好坏,这需要精准分离摩尔纹的周期信号和文字的高频信息,稍有不慎就会把文字笔画也模糊掉。
3.手写擦除
在教育题库整理场景中,试卷往往有学生的手写答案和老师的批改痕迹。如何在不损伤原始题目的前提下清除这些手写内容?合合信息展示的案例挺有说服力。系统用自研的色彩滤镜,专门针对题目图像做处理。处理完一看,手写的全没了,但题目原本的颜色、图表一点没糊。这说明算法能精准分清哪些是印刷的、哪些是手写的,就算笔迹压在字上也能扒开。
三、通用文档解析xParse
xParse是合合信息多模态文本智能技术支持下的核心产品,如果说底层视觉处理是看清楚,那xParse要解决的就是读明白。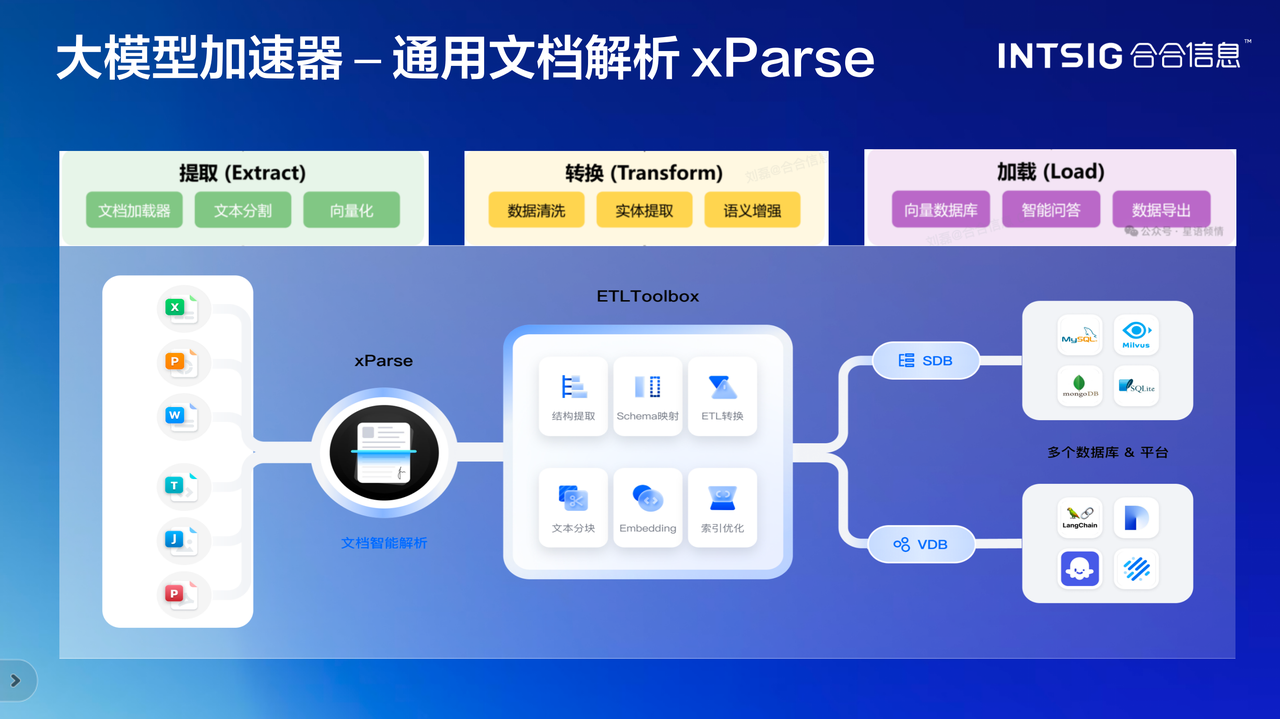
1.行业领先的表格识别能力
分享中重点强调了xParse在表格识别上的突破。跨页表格、合并单元格等这些都是传统OCR的痛点。xParse不仅能识别表格的视觉结构,更能理解表格的语义关系:表格标题与内容的关联,某个数据与其行列标题的对应,甚至表格与上下文段落的逻辑联系。
这些能力直接决定了知识库的质量,合合信息提了三个评价维度:相关性、完整性、可信度。这三个维度直击RAG应用的核心痛点。不少企业上了RAG,用着用着发现答非所问、瞎编答案,根子就在文档解析没做好。xParse通过精准的表格识别、阅读顺序还原、坐标精准定位,确保大模型获得的是准确、完整、可追溯的信息。
2.对大模型更友好的文档解析
xParse可以看做一个大模型加速器,它不是替代大模型,而是让大模型看得更清楚、理解得更准确。通过使用xParse解析的文档构建知识库,检索到的片段相关性、完整性、可信度均得到提升,整个RAG系统的性能都会显著改善。
四、AI内容安全
技术发展的同时,合合信息也没忽视安全问题,AI技术门槛降低,图像篡改、人脸伪造的成本也越来越低,由此引发的鉴伪需求呈爆发式增长。
1.FidOK三大检测能力
FidOK图像智能鉴伪系统覆盖三大场景:文本图像伪造检测、人脸图像伪造检测、AIGC图像伪造检测,
每个场景都有不同的技术难度:
文本图像伪造检测主要是检测PS、删除、移动等篡改操作。工程上需要多维度的特征融合:篡改区域往往在压缩方式、像素统计分布、边界平滑度等方面留下痕迹。比如用PS液化工具修改了身份证号码,原有的笔画笔触会被破坏,周围像素的梯度会出现异常。系统通过对比篡改区域和周围正常区域在这些特征上的差异,来判断是否被修改过。这需要在大量真实案例数据上训练,才能识别出各种篡改手法留下的蛛丝马迹。
人脸图像伪造检测包括换脸、对换等高级伪造手段。这类检测的难点在于,要从一张静态图片中找出极细微的不自然之处。比如眼睛的反光位置、皮肤的毛孔分布、脸部的光影是否符合物理,实际应用中,系统会从多个角度分析人脸的几何结构是否合理、纹理细节是否真实,综合多个信号来做出判断。
AIGC伪造检测 生成模型(如Diffusion模型、GAN)生成的图像质量越来越高,这是当前最大的挑战。生成的图像往往在一些微妙的统计特性上与真实图像不同------比如色彩的分布、纹理的细节规律。系统通过学习真实图像和生成图像在这些特性上的差异,来识别AI生成的假图。生成模型越来越强,检测也要不断升级,这也是为什么FidOK需要持续迭代和优化。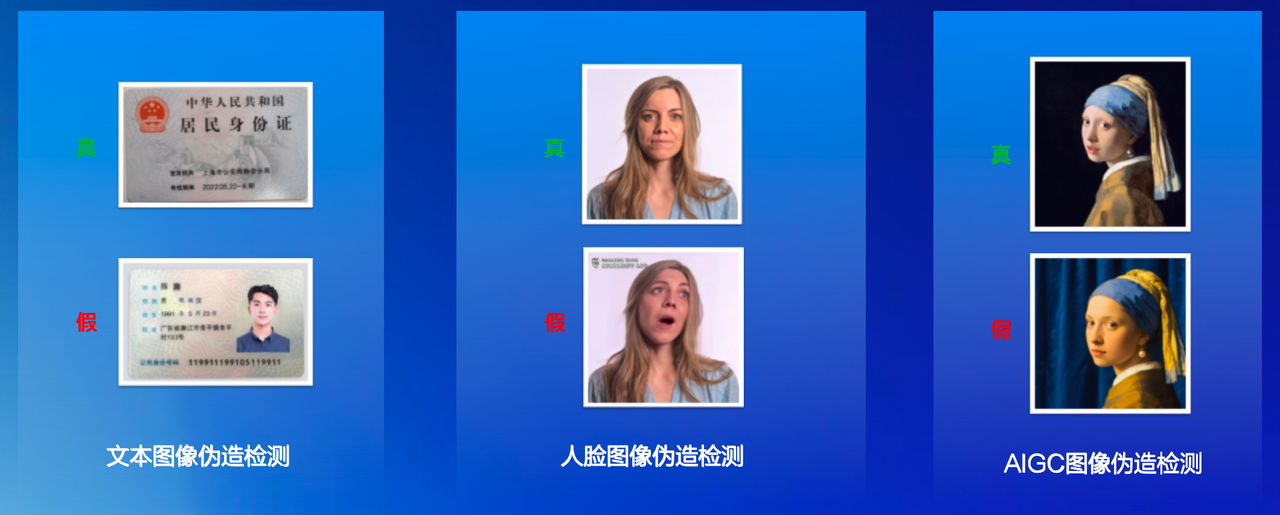
2.技术实力
合合信息技术团队近年来在多项国际顶级赛事中斩获佳绩,包括ICDAR2023"文本图像篡改检测"赛道冠军,2024全球AI攻防对抗挑战赛"AI核身金融凭证篡改检测"赛道冠军,CVPR2024第五届ChaLearn活体检测挑战赛第三名等。
某知名银行的案例显示,前端实时拦截复印翻拍件、不完整身份证图像,后端实时检测PS篡改,伪造样本拦截率超过90%。国有四大行之一的案例中,人脸伪造检测配合相似背景检测,伪造拦截率超过原有系统近8倍。
3.参与标准制定的行业担当
合合信息与中国信通院联合发起,携手中国图象图形学学会、中科大、上海交大等单位,共同编制《文档图像篡改检测标准》。标准制定是技术走向成熟的重要标志,合合信息不仅做产品,还参与行业规范的制定,这体现了技术领先者应有的责任感。
五、三大人工智能底层技术平台
从底层视觉处理到文档解析,再到内容安全防护,合合信息在多模态文本智能技术的各个环节都展现出了扎实的技术积累。但这些单点技术的突破,并非孤立存在的。它们的背后,是合合信息多年来构建的三大人工智能底层技术平台在提供支撑。合合信息技术具有三大创新平台:全球分布式算力与存储平台、文本智能技术平台、AGI技术平台。
三大平台的时间线分别为:2011年、2017年、2021年。合合信息早在移动互联网时代就开始布局算力基础设施,在深度学习兴起时深耕文本智能,在大模型爆发前探索AGI技术。
六、总结与思考
我在看这场分享的时候发现,现在大家都想做大而全的多模态,恨不得一个模型什么都能干,而合合信息反其道而行之,一直专注于文本智能这个细分方向。GPT不是第一个大语言模型,Transformer也不是OpenAI发明的,但OpenAI把这些技术用得最深、想得最透。同样的,合合信息在文本智能上的理解深度,深挖文本在不同模态中的语义关联与提取逻辑。正是这份坚持和专注,让他们在文本智能领域建立起了深厚的技术护城河。这就是合合信息坚信的:文本是通向AGI的必经之路,而这条路需要一步一个脚印地走。
在这个容易被炒作、被浮躁带偏的AI时代,这种务实的技术哲学反而显得格外珍贵。而"多模态文本智能技术"这个概念,本质上代表了一种从数据堆砌到语义理解的思维升级。它不是简单地把我们的图像、文本、表格都识别一遍,而是不断去发现这些看似不同的数据形式背后,究竟在表达什么结构化的知识。正因为这种对问题本质的执着追问,合合信息才能脱颖而出,把技术真正变成了生产力。
当通用大模型的能力开始趋于平缘,真正的差异化会来自于对具体场景的深度理解和优化。合合信息的多模态文本智能技术,正是在为这个未来做准备。未来的AI竞争,可能不会再是谁的模型参数多、谁的训练数据大,而是谁能在特定领域把结构化知识理解得最深、应用得最好。从这个角度看,合合信息今天的选择和积累,可能正在塑造下一个时代的AI基础设施。