机器学习的主要挑战
机器学习虽然取得了显著进展,但在实际应用中仍面临许多挑战,涵盖技术、数据、伦理和实际部署等多个方面。以下是主要的挑战分类及具体问题:
一、数据相关挑战
1、数据质量低
如果训练数据充满错误、异常值和噪声(例如,低质量的测量产生的数据),系统将更难检测到底层模式,也就更不太可能表现良好。花时间清洗训练数据通常是非常值得的。事实上,大多数数据科学家都会花费大量时间做这项工作。例如:·
如果某些实例明显异常,则简单地丢弃它们或尝试手动修复错误可能会有所帮助。·
如果某些实例缺少一些特征(例如,5%的客户没有说明自己的年龄),你必须决定是完全忽略此属性、忽略这些实例、将缺失值补充完整(例如,填写年龄的中位数),还是训练一个具有该特征的模型,再训练一个没有该特征的模型。
2、数据不具备代表性(数据偏差)
为了很好地实现泛化,训练数据必须能代表你想要泛化的新样例,这一点至关重要。无论你使用基于实例的学习还是基于模型的学习,都是如此。例如,训练一个GDP对应幸福指数的线性模型,国家数据集并不完全具有代表性,它不包含任何人均GDP低于23500美元或高于62500美元的国家。
下图展示了添加这些国家信息之后的数据表现。
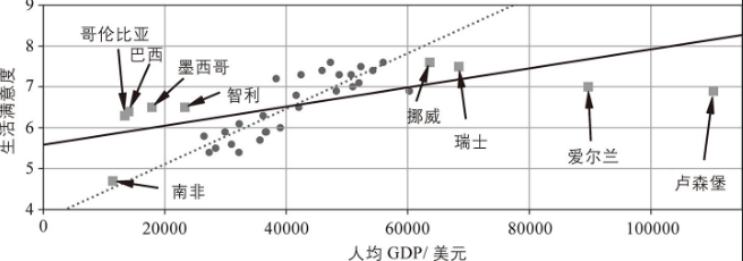
如果你在这个数据上训练一个线性模型,你会得到上图中的实线,旧模型用虚线表示。如你所见,添加了一些缺失的国家信息不仅显著地改变了模型,而且清楚地表明这种简单的线性模型可能永远不会那么准确。似乎非常富裕的国家并不比中等富裕国家更幸福(事实上,似乎稍微有点不幸福!),相反,一些贫穷国家似乎比许多富裕国家更幸福。
通过使用不具代表性的训练集,你训练了一个不太可能做出准确预测的模型,尤其是对于那些非常贫穷和非常富裕的国家。
使用代表你要泛化到的实例的训练集至关重要。不过说起来容易,做起来难:如果样本太小,那么会出现采样噪声(即非代表性数据被选中),但如果采样方法有缺陷,即使是非常大的样本也可能不具有代表性。这称为采样偏差。
3、无关特征
只有当训练数据包含足够多的相关特征并且没有太多的无关特征的时候,系统才能够进行学习。机器学习项目成功的一个关键部分就是提取好的特征集来进行训练,这个过程称为特征工程。
特征工程的主要步骤:特征选择(在现有特征中选择最有用的特征进行训练)→ 特征提取(结合现有特征产生更有用的特征)→ 通过收集新数据创建新特征
二、模型技术挑战
1、过拟合训练数据
假设你正在别的城市旅游,被出租车司机拒载。你可能会说那个城市的所有出租车司机都是地域歧视。以偏概全是我们人类常做的事情。机器也会落入同样的陷阱。在机器学习中,这称为过拟合,也就是指该模型在训练数据上表现良好,但泛化效果不佳。
当模型相对于训练数据的数量和噪声过于复杂时,就会发生过拟合。以下是可能的解决方案:
通过选择参数较少的模型(例如,线性模型而不是高阶多项式模型)、减少训练数据中的属性数量或约束模型来简化模型或者通过正则化来简化模型。
收集更多训练数据。
减少训练数据中的噪声(例如,修复数据错误并移除异常值)。
通过约束模型使它更简单,并降低过拟合的风险,这个过程称为正则化。学习期间应用的正则化程度可以由超参数控制。参数是学习算法(而非模型)的参数。因此,它不受学习算法本身的影响,必须在训练前设置并在训练期间保持不变。如果将正则化超参数设置得非常大,你将得到一个几乎平坦的模型(斜率接近于零)。
学习算法虽然肯定不会过拟合训练数据,但也不太可能找到好的解决方案。调整超参数是构建机器学习系统的重要部分(超参数也会影响学习模型的效率)
2、欠拟合训练数据
欠拟合与过拟合正好相反:当模型太简单而无法学习数据的底层结构时,就会发生欠拟合。例如,生活满意度的线性模型容易出现欠拟合。因为现实情况总是比模型更复杂,所以它的预测必然是不准确的,即使是在训练样例上也是如此。
以下是解决此问题的主要方式:
选择具有更多参数的更强大的模型。
为学习算法提供更好的特征(特征工程:提取更好的特征集进行训练)。
减少对模型的约束(例如通过减少正则化超参数)。
机器学习的测试和验证
了解模型对新实例的泛化能力的唯一方法是在新实例上进行实际尝试。
一种方法是将模型部署到生产环境并监控其性能。这种方法很有效,但如果模型非常糟糕,用户就会投诉/流失,所以这显然不是最好的方法。
更好的选择是将数据分成两组:训练集和测试集。顾名思义,你可以使用训练集训练模型,并使用测试集对其进行测试。新实例的错误率称为泛化误差(或样本外误差),通过在测试集上评估模型,你可以获得误差的估计值。这个值能告诉你模型在处理以前从未见过的实例时的表现。如果训练误差很低(即模型在训练集上犯的错误很少)但是泛化误差很高,这意味着你的模型过拟合了训练数据。
通常使用80%的数据进行训练,保留20%的数据进行测试。然而,这取决于数据集的大小:如果它包含1000万个实例,那么保留1%意味着你的测试集将包含10万个实例,这可能足以很好地估计泛化误差。
一、超参数调整和模型选择
评估模型非常简单:只需使用一个测试集。现在假设你在两种类型的模型(比如线性模型和多项式模型)之间犹豫不决,如何做出判断?一种选择是同时训练这两个模型,并使用测试集比较它们的泛化能力。
现在假设多项式模型拟合得更好,但你想应用一些正则化来避免过拟合。问题是,如何选择正则化超参数的值?一种选择是对于这个超参数,使用100个不同的值来训练100个不同的模型。假设你找到了最佳超参数值,它生成的模型泛化误差最小,比如只有5%的误差。你将此模型部署到生产环境,但遗憾的是它的性能并不如预期,产生了15%的误差。到底发生了什么?
问题是你多次测量了测试集上的泛化误差,并且调整了模型和超参数来生成拟合那个测试集的最佳模型。这意味着该模型不太可能在新数据上表现良好。(对测试集过拟合了,真实环境的数据表现得不好)
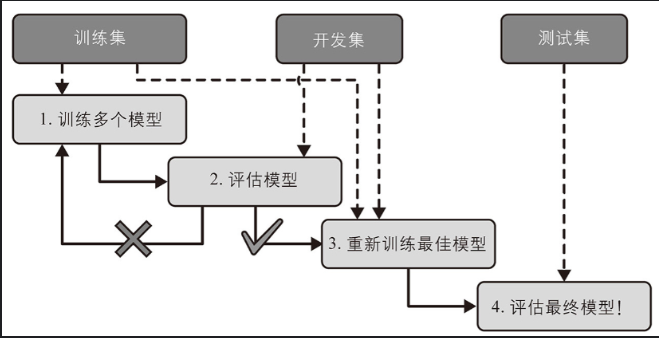
这个问题的一个常见解决方案称为保持验证(见下图):你只需保持训练集的一部分,以评估几个候选模型并选择最佳模型。新的保留集称为验证集(或开发集)。更具体地说,你可以在简化的训练集(即完整训练集减去验证集)上训练具有各种超参数的多个模型,然后选择在验证集上表现最佳的模型。在此保持验证过程之后,你在完整训练集( 包括验证集)上训练最佳模型,这就是你的最终模型。最后,你在测试集上评估这个最终模型以获得泛化误差的估计。
二、数据不匹配
在某些情况下,很容易获得大量数据用于训练,但这些数据可能无法完全代表将在生产环境中使用的数据。
例如,假设你想创建一个移动应用程序来拍摄花朵照片并自动确定它们的种类。你可以轻松地在网络上下载数百万张花卉图片,但它们并不能完全代表在移动设备上使用该应用程序实际拍摄的照片。也许你只有1000张有代表性的照片(即实际使用该应用程序拍摄的)。在这种情况下,要记住的最重要的规则是验证集和测试集都必须尽可能地代表你希望在生产环境中使用的数据,因此它们应该完全由有代表性的图片组成:你可以将它们打乱并将一半放在验证集中,一半放在测试集中(确保两个集中都没有重复或接近重复)。
在网络图片上训练了模型后,如果你观察到模型在验证集上的表现令人失望,那么你将不知道这是因为模型对训练集过拟合了,还是仅仅因为网络图片和移动应用程序图片之间的不匹配。
一种解决方案是将一些训练图片(来自网络)放在train-dev(训练开发)集(见下图)的另一个集合中。模型训练完成后(在训练集上,而不是在train-dev集上),你可以在train-dev集上对其进行评估。如果模型表现不佳,那么它一定是对训练集过拟合了,所以应该尽量简化或正则化该模型、获取更多的训练数据,以及清洗训练数据。
但是如果模型在train-dev集上表现良好,那么你可以在开发集上评估模型。如果模型表现不佳,那么问题一定来自数据不匹配。你可以尝试通过预处理网络图片来解决这个问题,使它们看起来更像移动应用程序拍摄的照片,然后重新训练模型。一旦你拥有在train-dev集和开发集上都表现良好的模型,就可以在测试集上最后一次评估它,以了解它在生产环境中的表现。

当真实数据稀缺时(右),可以使用类似丰富的数据(左)进行训练,并在train-dev集中保留一些数据以评估过拟合。然后使用真实数据评估数据不匹配(开发集)和最终模型的性能(测试集)
****模型是数据的简化表示。****简化旨在丢弃不太可能泛化到新实例的多余细节。当你选择特定类型的模型时,你是在隐含地对数据做出假设。例如,如果你选择线性模型,则隐含地假设数据基本上是线性的,并且实例与直线之间的距离只是噪声,可以安全地忽略它。
如果你完全不对数据做出任何假设,那么就没有理由偏爱某个模型。对于一些数据集,最好的模型是线性模型,而对于其他数据集,最好的模型是神经网络模型。不存在一个先验模型可以保证一定能更好地工作(数学上不能推导出一个模型,这个模型最能代表当前数据)
保证确定哪种模型最好的唯一方法是对所有模型进行评估。由于这是不可能的,因此在实践中你对数据做出了一些合理的假设并仅评估了几个合理的模型。例如,对于简单的任务,你可能只会评估几个具有不同正则化水平的线性模型,而对于复杂的问题,你可能会评估多个神经网络模型。