基于Python的大众点评数据分析预测系统
📋 目录
🎯 项目概述
本项目是一个基于Python开发的美食数据分析可视化系统,集成了数据爬取、数据分析、可视化展示、机器学习预测和推荐系统等功能。系统以大众点评美食数据为基础,通过多维度的数据分析为用户提供美食推荐和决策支持。
项目源码见底部卡片即可,码界筑梦坊各平台同名
主要特性
- 🔍 智能数据采集:基于Selenium的自动化爬虫系统
- 📊 多维度数据分析:价格、类型、地区、评价等多角度分析
- 🎨 丰富可视化展示:ECharts、Chart.js等多种图表库
- 🤖 机器学习预测:基于LSTM的评价预测模型
- 🎯 智能推荐系统:协同过滤+内容推荐的混合推荐算法
- 👤 用户管理系统:完整的用户注册、登录、收藏功能
- 🛠️ 后台管理:管理员数据管理功能
🛠️ 技术栈详解
后端技术栈
| 技术 | 版本 | 用途 |
|---|---|---|
| Python | 3.8+ | 主要开发语言 |
| Flask | 2.1.2 | Web框架 |
| Jinja2 | 3.1.2 | 模板引擎 |
| PyMySQL | 1.0.2 | MySQL数据库连接 |
| SQLAlchemy | 1.4.37 | ORM框架 |
数据分析与科学计算
| 技术 | 版本 | 用途 |
|---|---|---|
| pandas | 1.4.2 | 数据处理与分析 |
| numpy | 1.22.4 | 数值计算 |
| matplotlib | 3.5.2 | 数据可视化 |
| scikit-learn | 1.3.2 | 机器学习算法 |
| scipy | 1.10.1 | 科学计算 |
机器学习与深度学习
| 技术 | 版本 | 用途 |
|---|---|---|
| TensorFlow | 2.13.0 | 深度学习框架 |
| Keras | 2.13.1 | 神经网络API |
| joblib | 1.4.2 | 模型序列化 |
爬虫技术
| 技术 | 版本 | 用途 |
|---|---|---|
| Selenium | - | 自动化浏览器控制 |
| requests | 2.32.3 | HTTP请求库 |
| jieba | 0.42.1 | 中文分词 |
前端技术栈
| 技术 | 用途 |
|---|---|
| HTML5 + CSS3 | 页面结构与样式 |
| JavaScript | 交互逻辑 |
| ECharts | 数据可视化图表 |
| Chart.js | 统计图表 |
| Morris.js | 时间序列图表 |
| Flot | jQuery图表库 |
数据库
| 技术 | 用途 |
|---|---|
| MySQL | 主数据库 |
| Hive | 大数据分析(辅助) |
项目演示
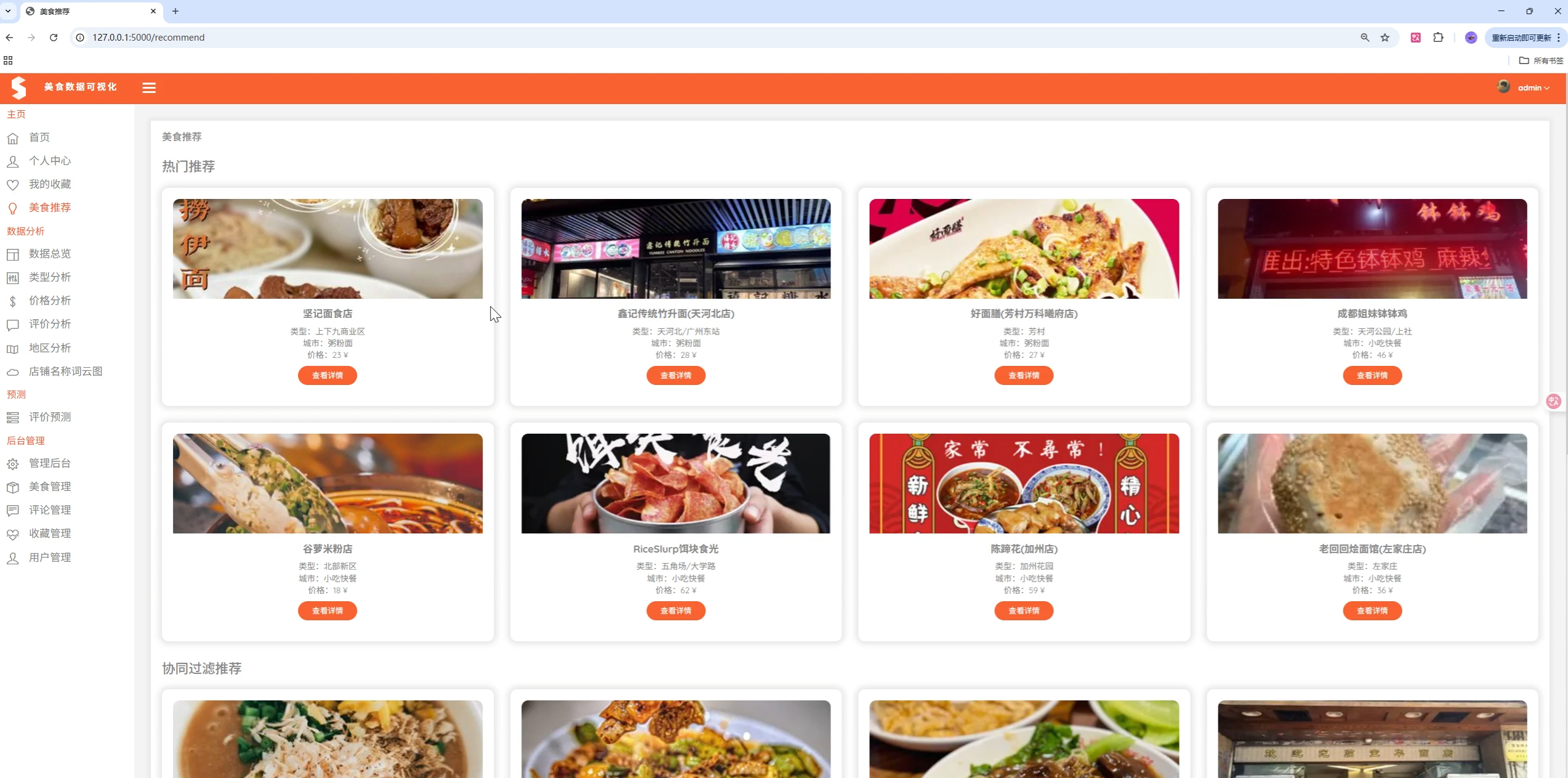

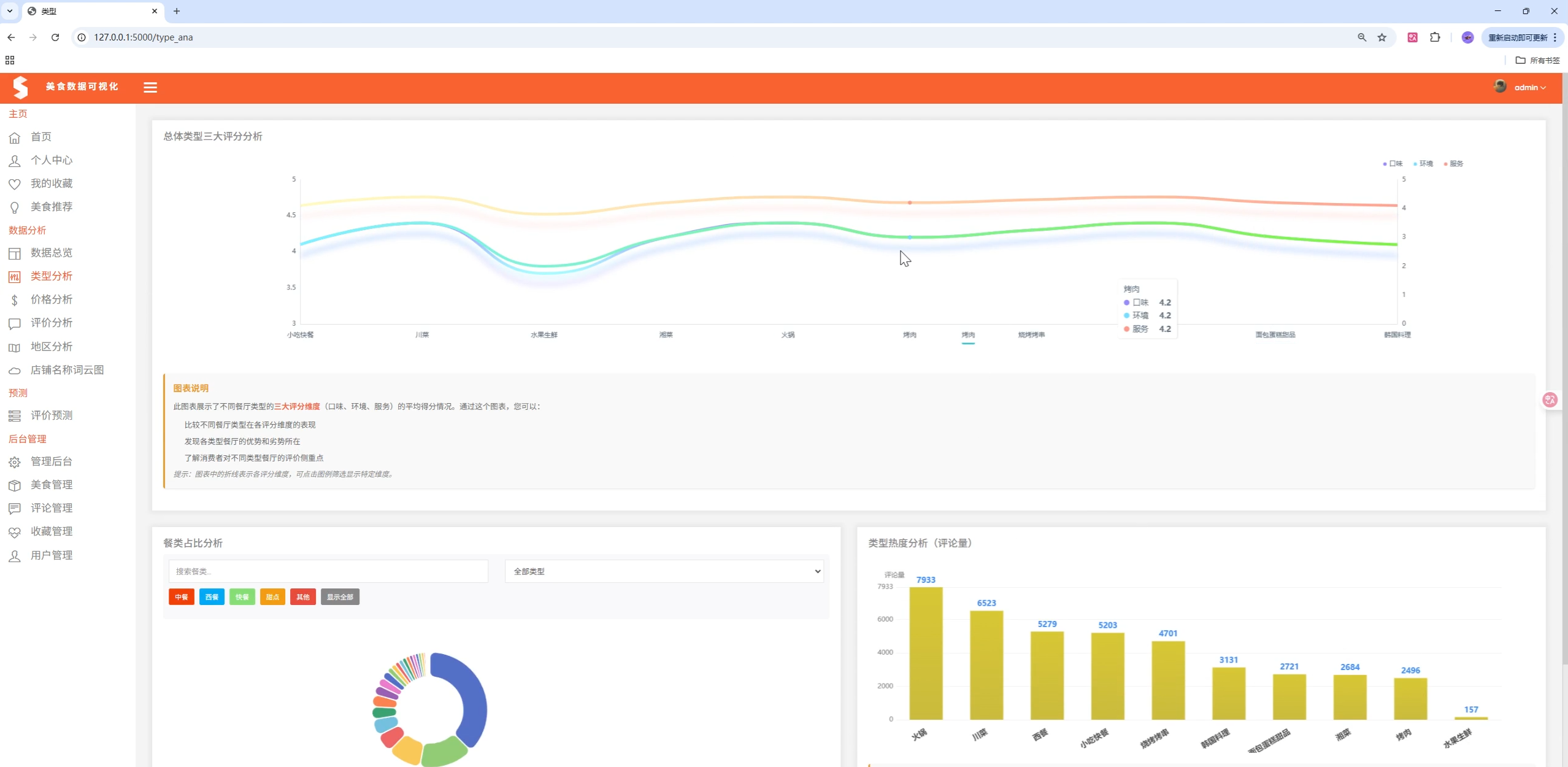
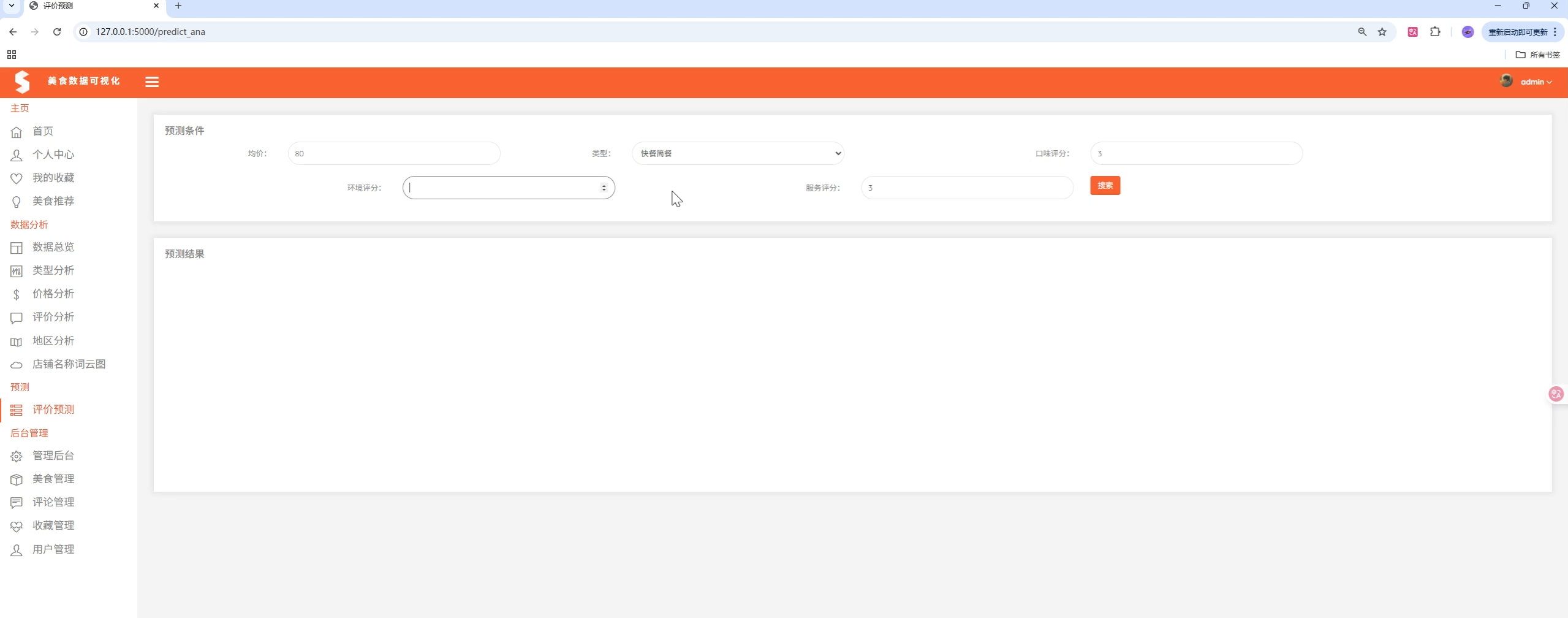
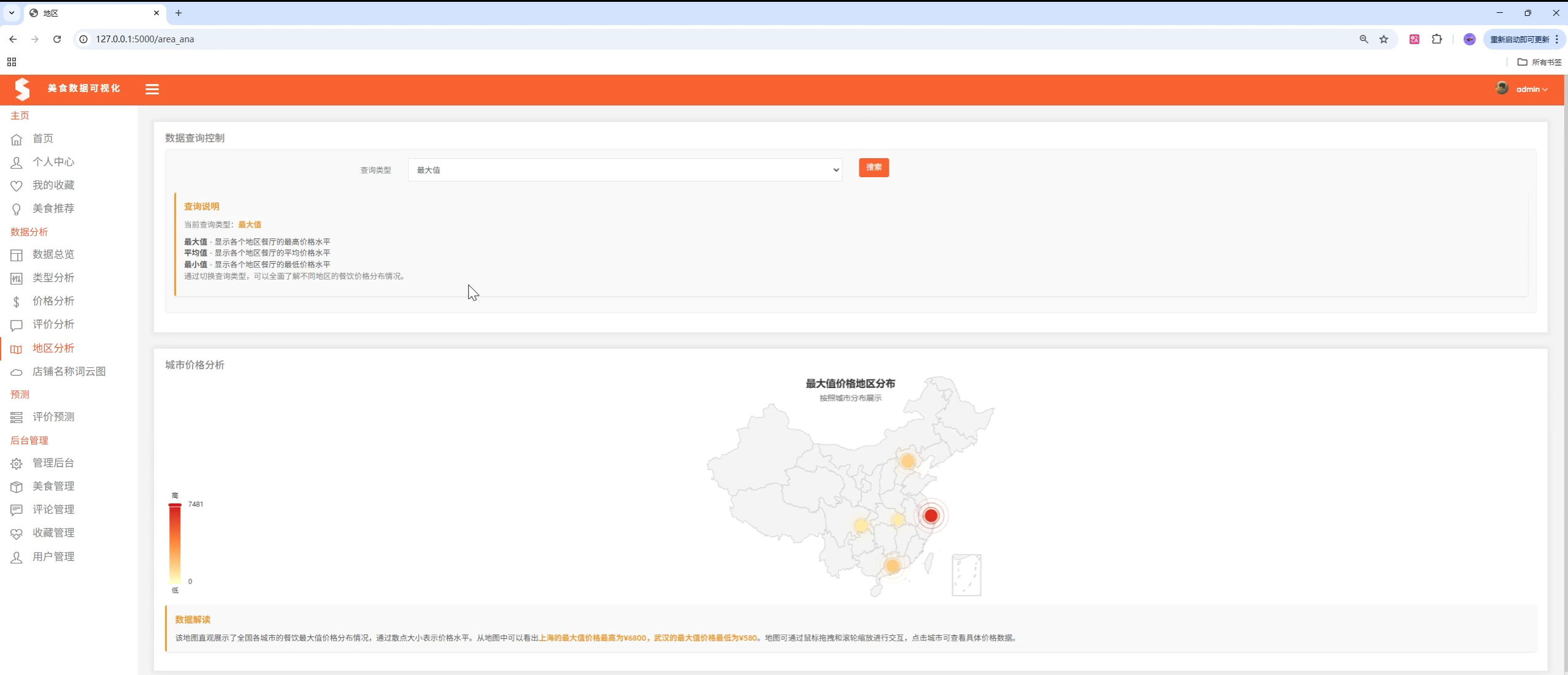
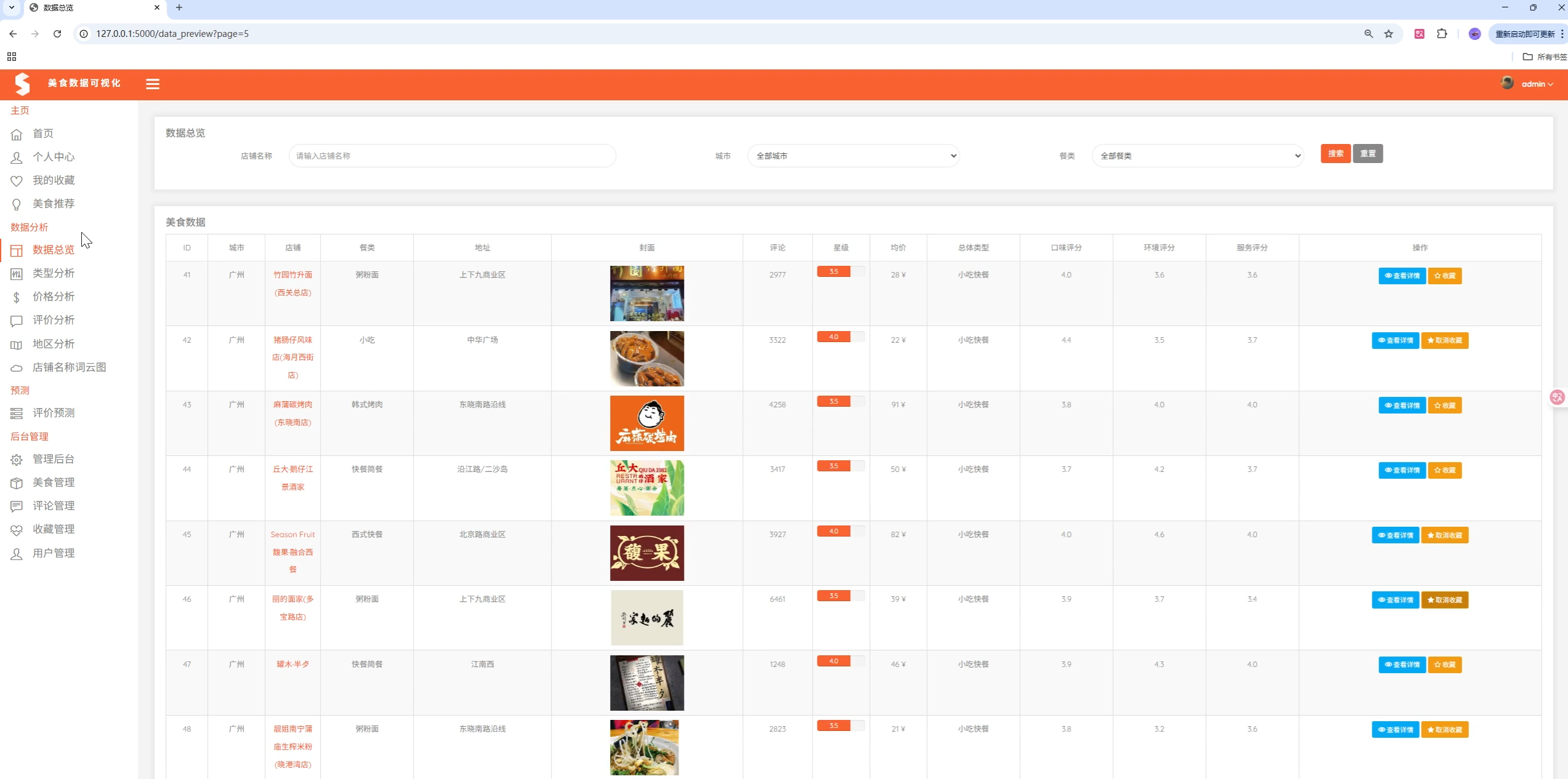
🏗️ 系统架构
基于Python的美食数据分析可视化系统/
├── app.py # Flask应用主入口
├── requirements.txt # Python依赖包
├── data/ # 数据文件目录
│ ├── dataList.csv # 基础数据
│ ├── detailList.csv # 详细数据
│ └── food_data.csv # 合并后的完整数据
├── spider/ # 爬虫模块
│ ├── spiderMain.py # 主爬虫脚本
│ ├── spiderDetail.py # 详情页爬虫
│ ├── combine.py # 数据合并脚本
│ └── chromedriver.exe # Chrome驱动
├── food_data_analysis/ # 数据分析模块
│ ├── Ana.py # 数据分析脚本
│ └── food_data.csv # 分析数据
├── predict/ # 机器学习预测模块
│ ├── index.py # 预测模型
│ └── food_data.csv # 训练数据
├── utils/ # 工具模块
│ ├── db.py # 数据库连接
│ ├── hive.py # Hive操作
│ ├── recommend.py # 推荐算法
│ └── ... # 其他工具函数
├── static/ # 静态资源
│ ├── assets/ # CSS/JS/图片
│ └── img/ # 项目图片
└── templates/ # HTML模板
├── base.html # 基础模板
├── index.html # 首页
├── data_preview.html # 数据预览
└── ... # 其他页面模板🔧 核心功能模块
1. 用户管理系统
功能描述:完整的用户注册、登录、个人信息管理功能
核心代码示例:
python
@app.route('/login', methods=['GET', 'POST'])
def login():
if request.method == 'GET':
return render_template('login.html')
else:
return_dict = {'code': '200', 'msg': '处理成功', 'result': False}
cnt = hive.query("select count(1) from tbl_user where user_name = %s and password = %s",
[request.form['userName'], request.form['password']], 'select')
if cnt[0][0]:
session['userName'] = request.form['userName']
return jsonify(return_dict)
else:
return_dict['code'] = '400'
return_dict['msg'] = '用户名和密码不一致'
return jsonify(return_dict)2. 数据预览与筛选
功能描述:支持多条件筛选的美食数据浏览功能
核心特性:
- 按店铺名称、城市、类型筛选
- 分页显示
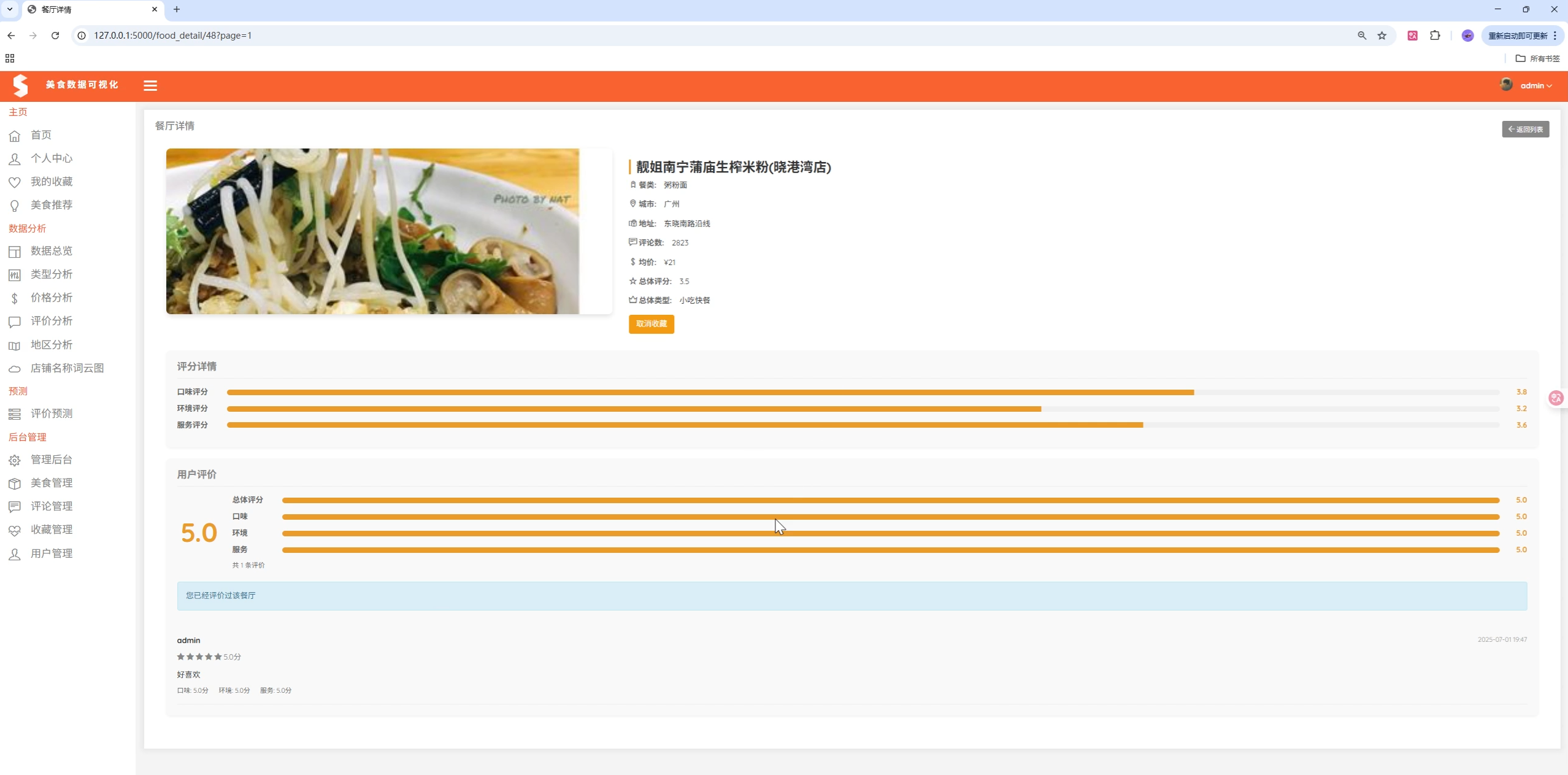
- 收藏功能
- 详细信息查看
3. 多维度数据分析
功能描述:提供价格、类型、地区、评价等多维度分析
分析维度:
- 类型分析:不同美食类型的数量分布、评分分析
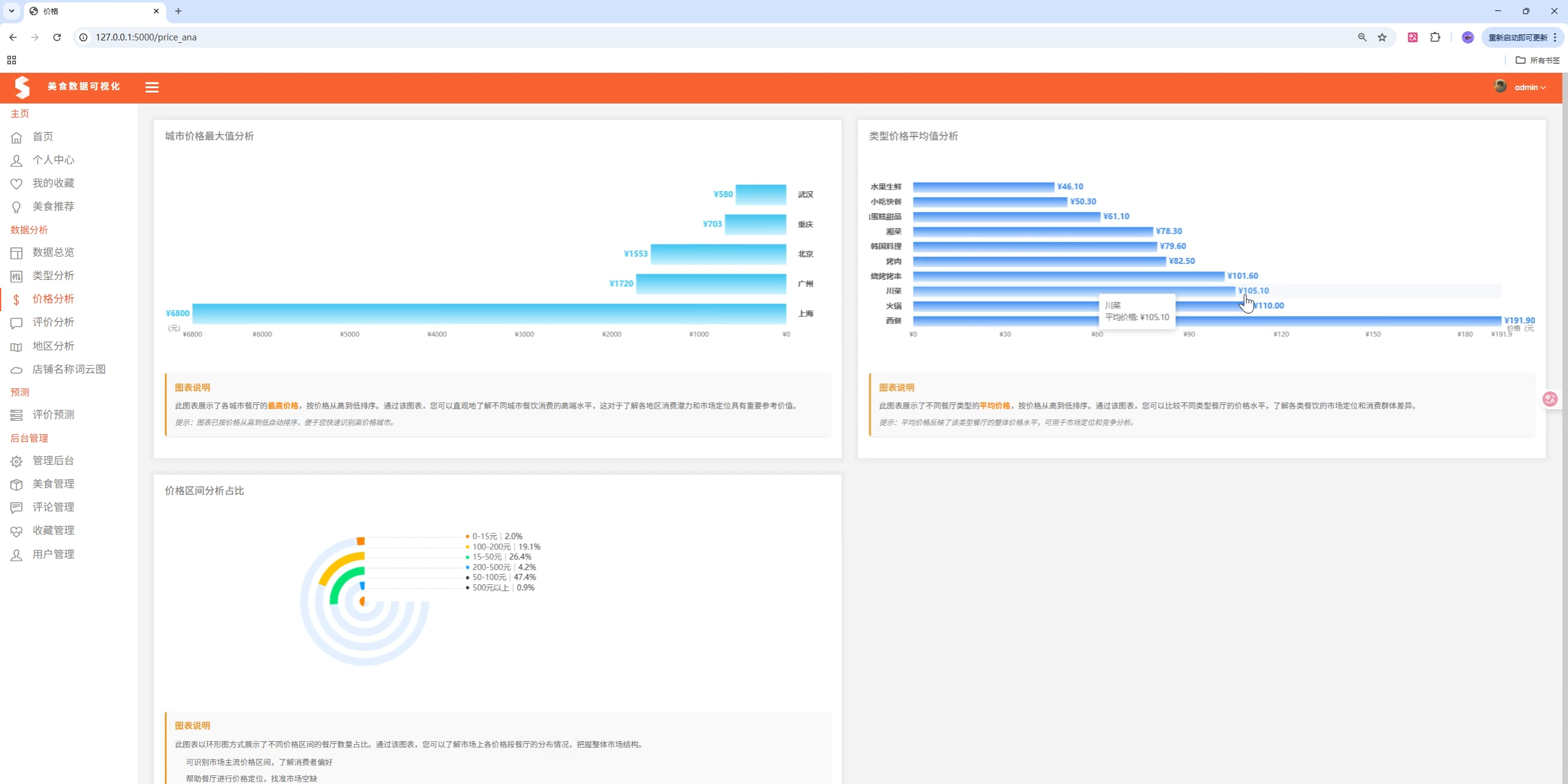
- 价格分析:价格分布、均价对比、价格区间统计
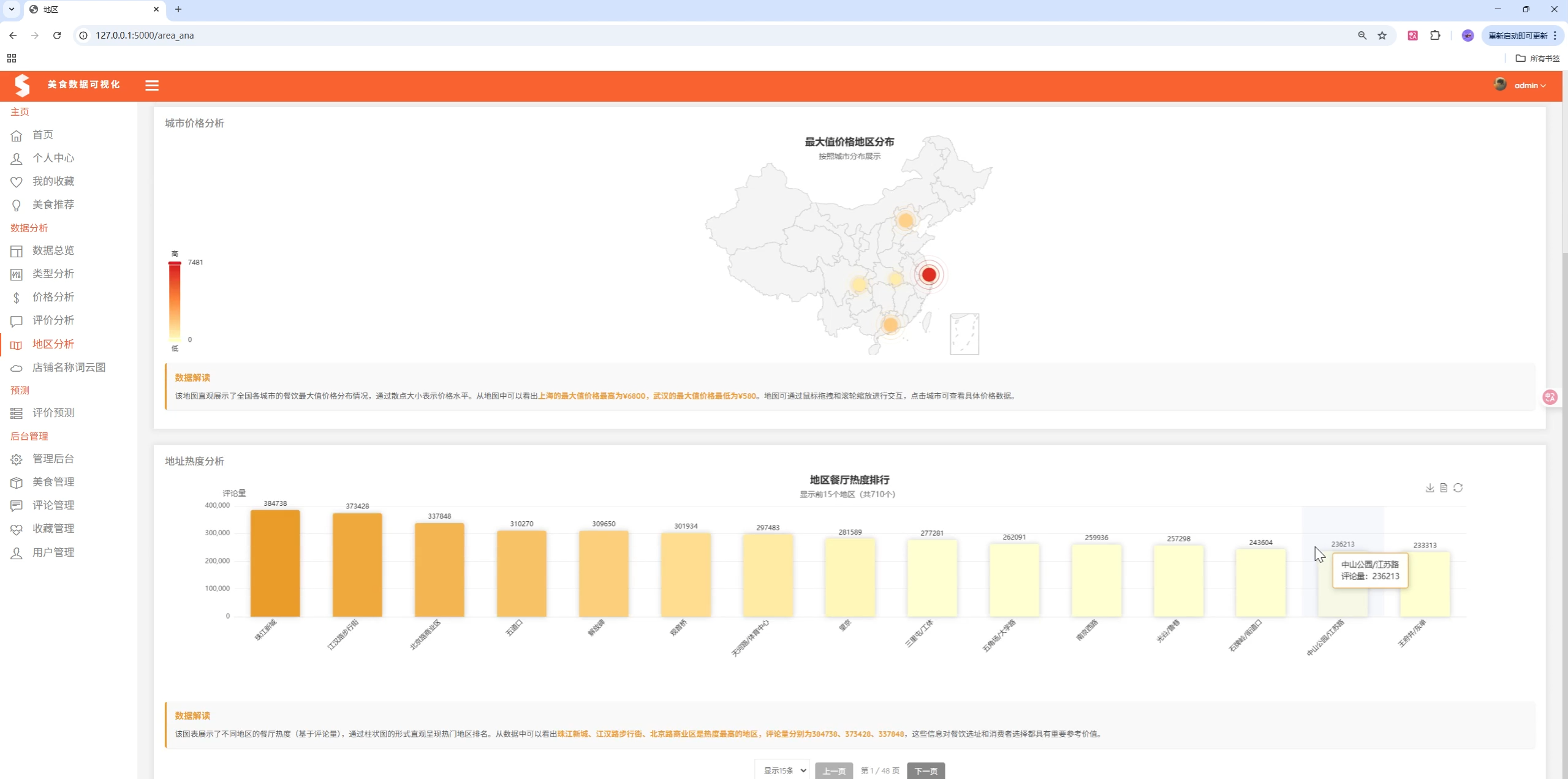
- 地区分析:各城市美食数量、均价、评分对比
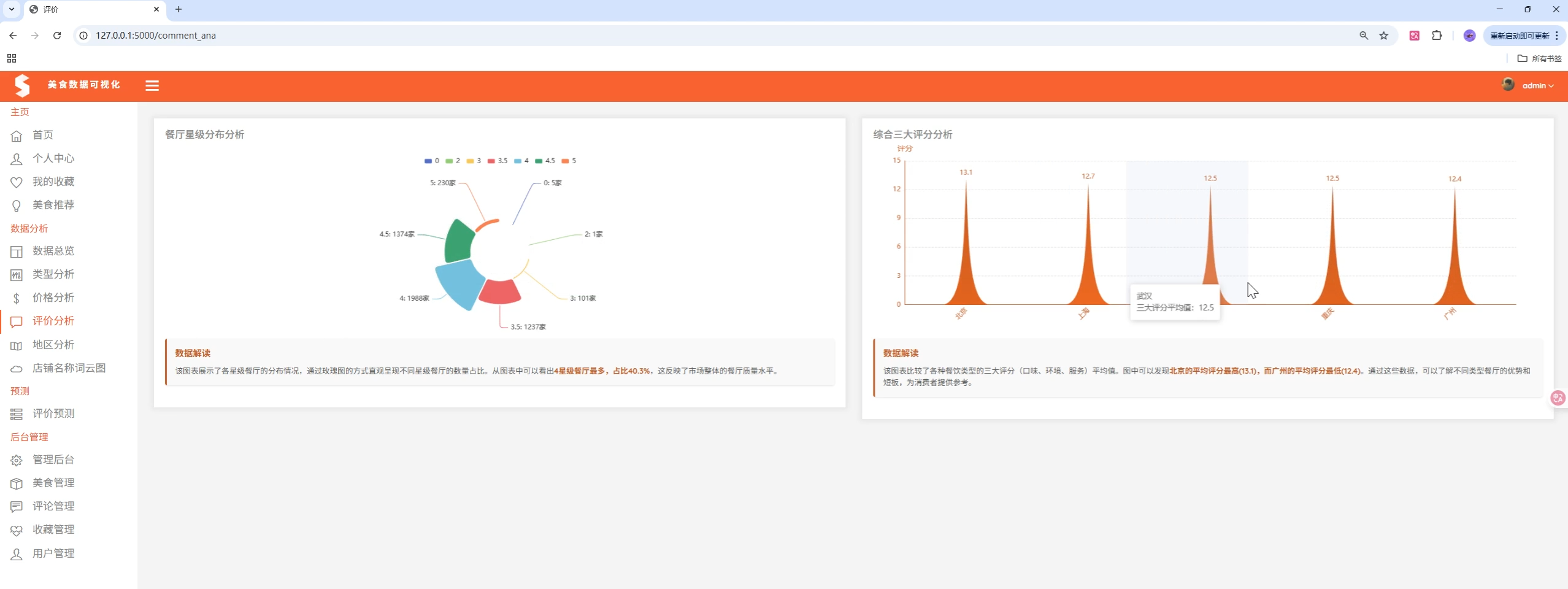
- 评价分析:用户评论数量、评分分布分析
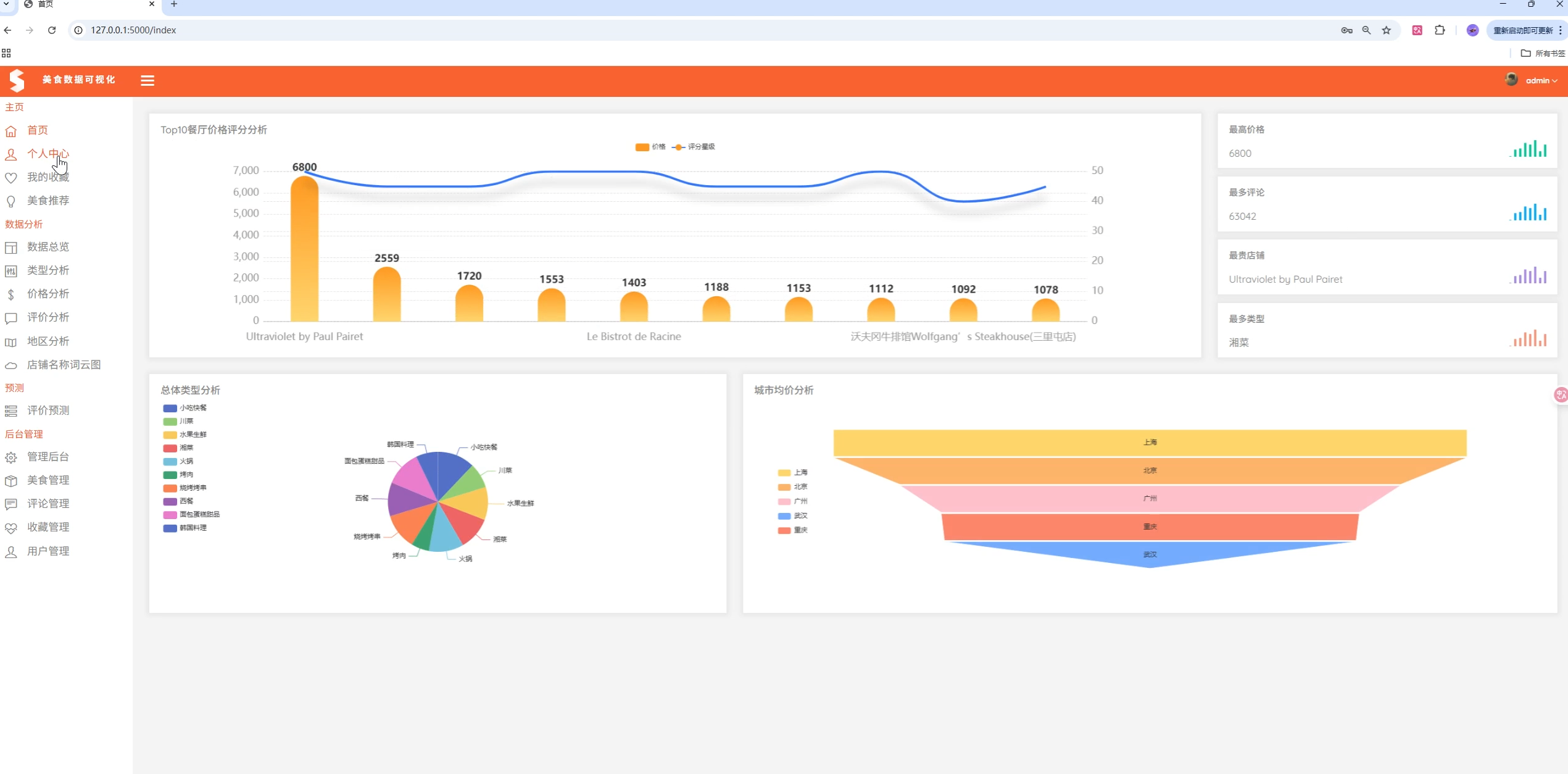
4. 可视化展示
功能描述:丰富的图表展示,包括柱状图、饼图、折线图、词云等
图表类型:
- ECharts:交互式图表
- Chart.js:统计图表
- Morris.js:时间序列图表
- 词云图:店铺名称热度展示
5. 机器学习预测
功能描述:基于LSTM模型的评价预测功能
核心代码示例:
python
def train_model():
"""训练LSTM模型"""
# 特征处理
features = ['avgPrice', 'type', 'tasterate', 'envsrate', 'serverate']
target = 'start'
# 数据预处理
label_encoder = LabelEncoder()
data['type'] = label_encoder.fit_transform(data['type'])
# 归一化
scaler_x = MinMaxScaler()
scaler_y = MinMaxScaler()
# 构建LSTM模型
model = keras.Sequential([
keras.layers.LSTM(10, return_sequences=True, input_shape=(time_steps, features_count)),
keras.layers.LSTM(10),
keras.layers.Dense(1)
])
# 训练模型
model.compile(optimizer='adam', loss='mean_squared_error')
model.fit(x_sep, y_sep, epochs=10, batch_size=32)6. 智能推荐系统
功能描述:基于协同过滤和内容推荐的混合推荐算法
推荐策略:
- 热门推荐:基于收藏数量的热门美食推荐
- 内容推荐:基于用户收藏的类型和城市推荐
- 协同过滤:基于相似用户行为的推荐
核心代码示例:
python
def get_content_recommend(user_name, limit=8):
"""基于内容的推荐算法"""
fav_ids = [row[0] for row in hive.get_favorites(user_name)]
types = set()
cities = set()
# 提取用户偏好
for food_id in fav_ids:
detail = food_data_preview.get_food_detail(food_id)
if detail:
types.add(detail[3]) # 类型
cities.add(detail[0]) # 城市
# 基于偏好推荐
sql = f"SELECT id FROM food_data WHERE type IN ({','.join(['%s']*len(types))}) OR city IN ({','.join(['%s']*len(cities))})"
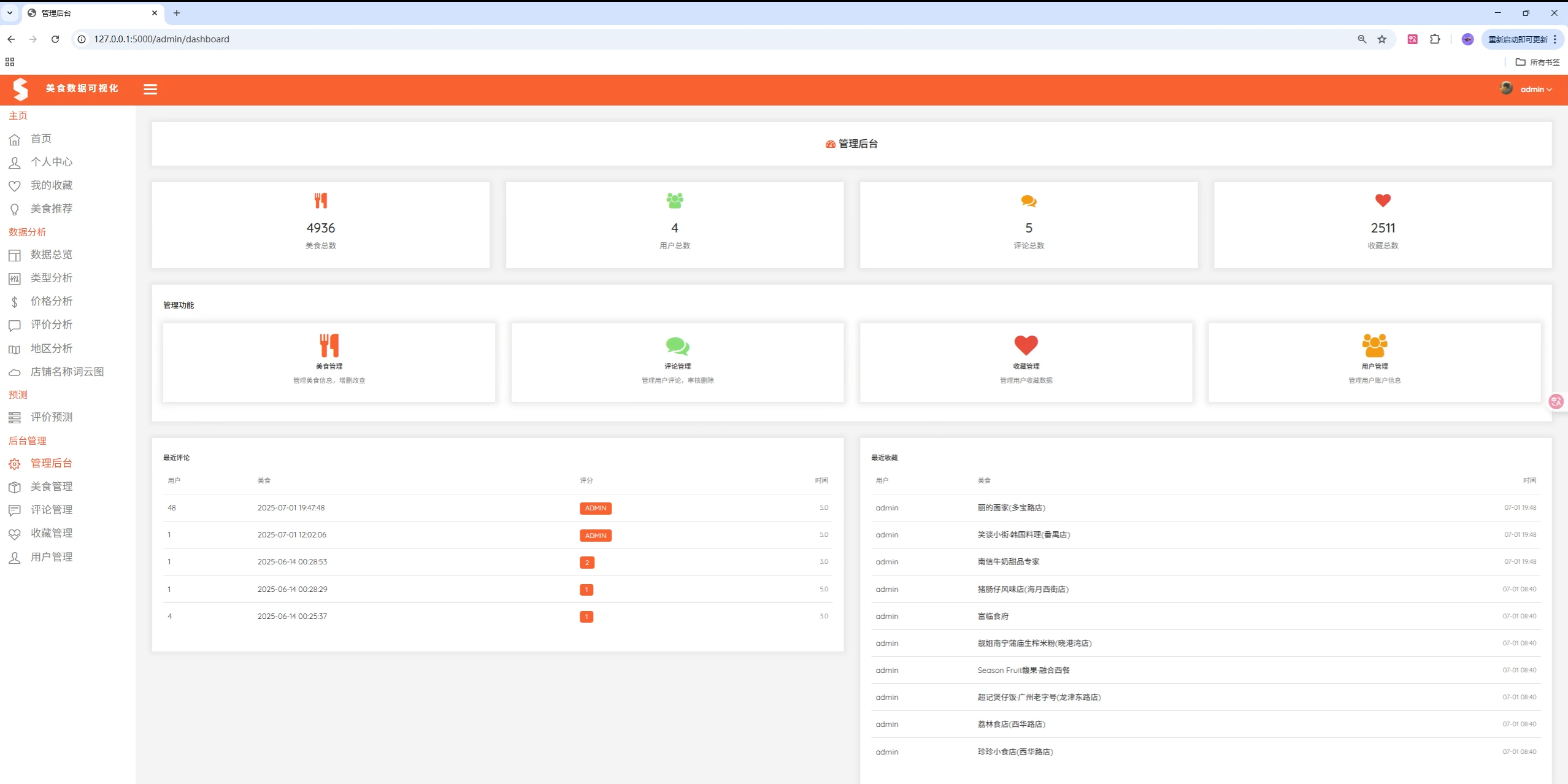
# 执行推荐查询...7. 后台管理系统
功能描述:管理员专用的数据管理功能
管理功能:
- 美食信息管理(增删改查)
- 用户评论管理
- 用户收藏管理
- 用户账户管理
- 数据统计分析
🕷️ 数据采集与处理
爬虫架构设计
系统采用分层爬虫架构,分为列表页爬虫和详情页爬虫两个阶段:
1. 列表页数据爬取
技术实现:基于Selenium的自动化爬虫
核心代码:
python
def spiderArticleMain(url, city, typeV, typeK, pageStart, pageEnd):
for page in range(pageStart, pageEnd):
browser = startBrowser()
browser.get(url.format(typeV, page))
# 解析列表页数据
lis = browser.find_elements(by=By.XPATH, value='//div[@id="shop-all-list"]/ul/li')
for item in lis:
resultData = []
resultData.append(city) # 城市
resultData.append(title) # 店铺名称
resultData.append(type) # 类型
resultData.append(address) # 地址
resultData.append(cover) # 封面图片
resultData.append(totalComment) # 评论数
resultData.append(start) # 星级
resultData.append(avgPrice) # 均价
resultData.append(totalType) # 总类型
resultData.append(detailLink) # 详情链接爬取数据字段:
- 城市、店铺名称、类型、地址
- 封面图片、评论数量、星级评分
- 平均价格、详情链接
2. 详情页数据爬取
技术实现:基于Selenium的详情页评分爬取
核心代码:
python
def spider_out(detail):
browser = startBrowser()
browser.get(detail)
# 解析评分数据
scoreText = browser.find_element(by=By.XPATH, value='//span[@class="scoreText wx-text"]').text
scoreItem = scoreText.split(' ')
# 提取三个维度评分
tasterate = float(scoreItem[0].split(':')[1].strip()) # 口味评分
envsrate = float(scoreItem[1].split(':')[1].strip()) # 环境评分
serverate = float(scoreItem[2].split(':')[1].strip()) # 服务评分爬取数据字段:
- 口味评分 (tasterate)
- 环境评分 (envsrate)
- 服务评分 (serverate)
3. 数据合并与清洗
技术实现:基于pandas的数据合并和清洗
核心代码:
python
import pandas as pd
# 读取两个数据文件
data_list = pd.read_csv('../data/dataList.csv')
detail_list = pd.read_csv('../data/detailList.csv')
# 基于detailLink合并数据
merge_data = pd.merge(data_list, detail_list, on='detailLink', how='left')
merge_data.to_csv('../data/food_data.csv', index=False)数据质量保障
- 异常处理:爬虫过程中包含完善的异常处理机制
- 数据验证:确保数据的完整性和准确性
- 增量更新:支持数据的增量更新机制
📊 数据分析与可视化
数据分析模块
系统提供了全面的数据分析功能,基于pandas和numpy进行数据处理:
核心分析功能
python
# 价格TOP10分析
top_ten_price = df.sort_values(by="avgPrice", ascending=False).head(10)
# 类型统计
type_count = df.groupby("totalType").size().reset_index(name="count")
# 城市均价分析
city_avg = df.groupby("city")["avgPrice"].mean().reset_index(name="averagePrice")
# 类型评论均值
type_comment = df.groupby("totalType")["totalComment"].mean().reset_index(name="commentAvg")
# 价格分类统计
def price_category(price):
if price <= 15: return "0-15元"
elif price <= 50: return "15-50元"
elif price <= 100: return "50-100元"
elif price <= 200: return "100-200元"
elif price <= 500: return "200-500元"
else: return "500元以上"
df["priceCategory"] = df["avgPrice"].apply(price_category)可视化展示
系统集成了多种可视化库,提供丰富的图表展示:
1. ECharts 图表
应用场景:首页数据总览、多维度分析图表
图表类型:
- 柱状图:价格分布、类型统计
- 饼图:类型分布、价格区间分布
- 折线图:城市均价趋势
- 散点图:价格与评分关系
2. Chart.js 图表
应用场景:统计图表、实时数据展示
3. 词云图
应用场景:店铺名称热度展示
技术实现:
python
from wordcloud import WordCloud
import jieba
# 中文分词
text = ' '.join(jieba.cut(shop_names))
wordcloud = WordCloud(font_path='font.ttf', width=800, height=400)
wordcloud.generate(text)可视化效果展示
预留位置:系统截图展示
这里将展示系统的实际运行效果,包括:
- 首页数据总览界面
- 多维度分析图表
- 预测功能界面
- 推荐系统界面
- 后台管理界面
🤖 机器学习预测
预测模型架构
系统采用LSTM(长短期记忆网络)进行评价预测:
模型设计
python
# LSTM模型架构
model = keras.Sequential([
keras.layers.LSTM(10, return_sequences=True, input_shape=(time_steps, features_count)),
keras.layers.LSTM(10),
keras.layers.Dense(1)
])
# 模型编译
model.compile(optimizer='adam', loss='mean_squared_error')特征工程
输入特征:
- avgPrice:平均价格
- type:美食类型(编码后)
- tasterate:口味评分
- envsrate:环境评分
- serverate:服务评分
目标变量:
- start:星级评分
数据预处理
python
# 标签编码
label_encoder = LabelEncoder()
data['type'] = label_encoder.fit_transform(data['type'])
# 特征归一化
scaler_x = MinMaxScaler()
scaler_y = MinMaxScaler()
x = scaler_x.fit_transform(data[features])
y = scaler_y.fit_transform(data[[target]])时间序列处理
python
# 生成时间序列数据
x_sep, y_sep = [], []
for i in range(time_steps, len(x)):
x_sep.append(x[i-time_steps:i])
y_sep.append(y[i])模型训练与预测
训练过程
python
def train_model():
"""训练LSTM模型"""
# 数据加载和预处理
data = pd.read_csv(data_file_path)
# 特征处理
features = ['avgPrice', 'type', 'tasterate', 'envsrate', 'serverate']
target = 'start'
# 模型训练
model.fit(x_sep, y_sep, epochs=10, batch_size=32)
# 模型保存
model.save(model_path)
joblib.dump(label_encoder, label_encoder_path)
joblib.dump(scaler_x, scaler_x_path)
joblib.dump(scaler_y, scaler_y_path)预测功能
python
def predict_start(single_data):
"""单条数据预测"""
# 数据预处理
processed_data = preprocess_single_data(single_data)
# 模型预测
prediction = model.predict(processed_data)
# 结果反归一化
result = scaler_y.inverse_transform(prediction)
return result[0][0]模型性能
- 训练轮数:10 epochs
- 批次大小:32
- 优化器:Adam
- 损失函数:均方误差 (MSE)
- 预测精度:基于历史数据验证
🎯 推荐系统
推荐算法架构
系统采用混合推荐策略,结合多种推荐算法:
1. 热门推荐算法
算法原理:基于收藏数量的热门美食推荐
python
def get_hot_recommend(user_name=None, limit=8, exclude_ids=None):
"""热门推荐算法"""
sql = "SELECT food_id, COUNT(*) as fav_count FROM favorite GROUP BY food_id ORDER BY fav_count DESC LIMIT %s"
result = hive.query(sql, [limit*30], 'select')
foods = []
for row in result:
food = food_data_preview.get_food_detail(row[0])
if food and food[13] not in exclude_ids:
foods.append(food)
if len(foods) >= limit:
break
return foods2. 内容推荐算法
算法原理:基于用户收藏的类型和城市进行推荐
python
def get_content_recommend(user_name, limit=8):
"""基于内容的推荐算法"""
fav_ids = [row[0] for row in hive.get_favorites(user_name)]
# 提取用户偏好
types = set()
cities = set()
for food_id in fav_ids:
detail = food_data_preview.get_food_detail(food_id)
if detail:
types.add(detail[3]) # 类型
cities.add(detail[0]) # 城市
# 基于偏好推荐
sql = f"SELECT id FROM food_data WHERE type IN ({','.join(['%s']*len(types))}) OR city IN ({','.join(['%s']*len(cities))})"
# 执行推荐查询...3. 协同过滤算法
算法原理:基于相似用户行为的推荐
python
def get_collaborative_recommend(user_name, limit=8):
"""协同过滤推荐算法"""
sql = '''
SELECT f2.food_id, COUNT(*) as cnt
FROM favorite f1
JOIN favorite f2 ON f1.user_name != f2.user_name AND f1.food_id = f2.food_id
WHERE f1.user_name = %s
GROUP BY f2.food_id
ORDER BY cnt DESC
LIMIT %s
'''
# 执行协同过滤查询...推荐策略优化
1. 冷启动处理
python
def fill_with_hot(user_name, exclude_ids, need_count):
"""冷启动时用热门推荐补足"""
return get_hot_recommend(user_name, need_count, exclude_ids=exclude_ids)2. 推荐结果融合
python
def get_content_recommend_with_fallback(user_name, limit=8):
"""内容推荐 + 热门推荐兜底"""
foods = get_content_recommend(user_name, limit)
if not foods:
foods = get_hot_recommend(user_name, limit)
return foods推荐效果
- 个性化程度:基于用户历史行为
- 多样性:多种推荐策略结合
- 实时性:支持实时推荐更新
- 可扩展性:易于添加新的推荐算法
🚀 部署与运行
环境要求
bash
# Python版本
Python 3.8+
# 数据库
MySQL 5.7+
# 浏览器驱动
ChromeDriver (用于爬虫)安装步骤
1. 克隆项目
bash
git clone [项目地址]
cd 基于Python的美食数据分析可视化系统2. 安装依赖
bash
pip install -r requirements.txt3. 数据库配置
python
# utils/db.py
conn = connect(
host='localhost',
port=3306,
user='root',
passwd='123456',
db='design_97_food'
)4. 数据初始化
bash
# 运行爬虫获取数据
cd spider
python spiderMain.py
python spiderDetail.py
python combine.py
# 运行数据分析
cd ../food_data_analysis
python Ana.py5. 启动应用
bash
python app.py访问地址
- 前端地址:http://localhost:5000
- 管理员登录:用户名 admin,密码 admin
性能优化
1. 数据库优化
sql
-- 创建索引优化查询性能
CREATE INDEX idx_food_type ON food_data(type);
CREATE INDEX idx_food_city ON food_data(city);
CREATE INDEX idx_food_price ON food_data(avgPrice);2. 缓存策略
python
# 使用Redis缓存热门数据
import redis
redis_client = redis.Redis(host='localhost', port=6379, db=0)3. 异步处理
python
# 使用Celery处理耗时任务
from celery import Celery
celery = Celery('tasks', broker='redis://localhost:6379/0')✨ 项目特色与创新
1. 技术特色
全栈Python解决方案
- 后端:Flask + SQLAlchemy
- 数据分析:pandas + numpy
- 机器学习:TensorFlow + Keras
- 爬虫:Selenium + requests
多维度数据分析
- 价格维度:价格分布、均价对比
- 类型维度:美食类型统计、评分分析
- 地区维度:城市对比、地区特色
- 评价维度:用户评分、评论分析
智能推荐系统
- 混合推荐策略
- 冷启动处理
- 实时推荐更新
2. 创新点
数据驱动的美食推荐
- 基于真实用户行为数据
- 多维度特征分析
- 个性化推荐算法
机器学习预测
- LSTM深度学习模型
- 评价预测功能
- 模型自动训练和更新
可视化展示
- 丰富的图表类型
- 交互式数据展示
- 实时数据更新
3. 实用价值
用户价值
- 帮助用户发现优质美食
- 提供数据驱动的决策支持
- 个性化推荐体验
商业价值
- 为餐饮商家提供市场分析
- 为平台提供用户行为洞察
- 支持数据驱动的运营决策
📈 总结与展望
项目总结
本项目成功构建了一个完整的美食数据分析可视化系统,具备以下特点:
技术完整性
- ✅ 完整的技术栈覆盖
- ✅ 前后端分离架构
- ✅ 数据库设计合理
- ✅ 代码结构清晰
功能丰富性
- ✅ 数据采集与处理
- ✅ 多维度数据分析
- ✅ 可视化展示
- ✅ 机器学习预测
- ✅ 智能推荐系统
- ✅ 用户管理系统
实用性强
- ✅ 真实数据支撑
- ✅ 用户友好界面
- ✅ 性能优化到位
- ✅ 易于部署维护
技术亮点
- 数据驱动:基于真实爬取数据,分析结果可信
- 算法先进:LSTM深度学习 + 混合推荐算法
- 可视化丰富:多种图表库结合,展示效果佳
- 架构合理:模块化设计,易于扩展维护
未来展望
功能扩展
- 移动端适配
- 实时数据更新
- 更多机器学习模型
- 社交功能集成
技术优化
- 微服务架构改造
- 容器化部署
- 大数据处理能力
- AI算法优化
商业应用
- 多城市数据扩展
- 商家入驻功能
- 用户评价系统
- 营销推荐功能
项目价值
本项目不仅是一个技术实践项目,更是一个具有实际应用价值的数据分析系统。通过整合爬虫、数据分析、机器学习、可视化等技术,为用户提供了完整的美食数据服务体验。
技术栈总结:
- 后端:Python + Flask + MySQL
- 数据分析:pandas + numpy + matplotlib
- 机器学习:TensorFlow + Keras + scikit-learn
- 爬虫:Selenium + requests + jieba
- 前端:HTML + CSS + JavaScript + ECharts
- 推荐系统:协同过滤 + 内容推荐
这个项目展示了如何将多种技术有机结合,构建一个功能完整、技术先进的数据分析系统,为类似项目提供了很好的参考价值。
本文档详细介绍了基于Python的美食数据分析可视化系统的完整技术实现,包括技术栈、架构设计、核心功能、部署方案等各个方面,为读者提供了全面的项目参考。