本文首发于公众号:托尼学长,立个写 1024 篇原创技术面试文章的flag,欢迎过来视察监督~
不得不说,单机模式下的本地缓存是真香,无论是简单直接上手的HashMap集合,还是功能强大的Guava Cache、EhCache和Caffeine等。
这些都比需要额外的服务器进行搭建部署,并引入客户端的Redis性价比高。
尤其是Guava Cache、EhCache和Caffeine,不但在功能上与Redis相差无几,而且节省了硬件成本、提升了研发效率,少了一次网络IO。
不过,一旦从单机模式切换到集群模式下,本地缓存多份数据的更新问题就马上暴露出来了。
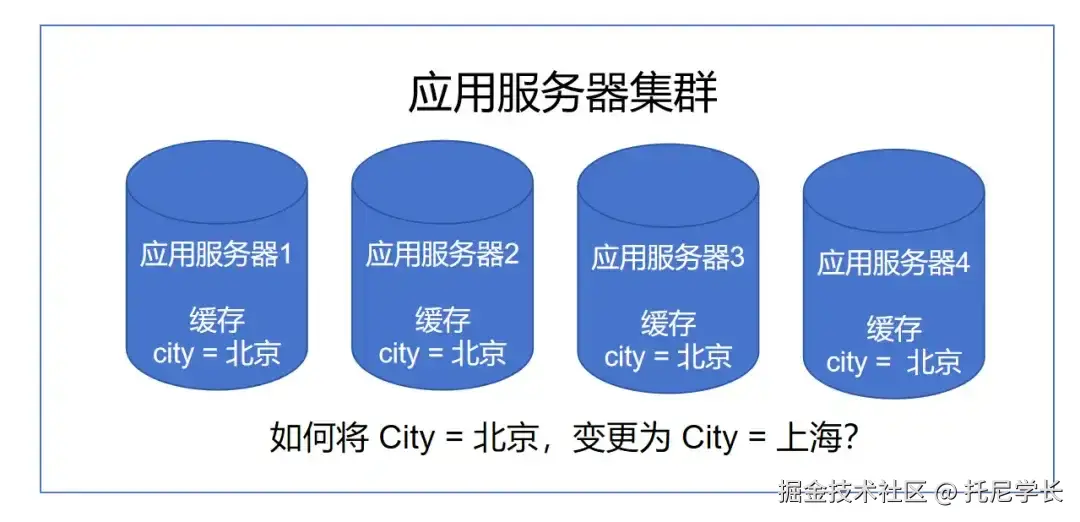
如上图所示,将缓存中的Key City从北京变更到上海,在Redis上只需要一次请求即可。
而在本地缓存上,则需要把集群中的所有应用服务器的缓存数据全部变更才行,这也就大大增加了执行难度。
下面我总结了四种本地缓存数据的变更方案,大家可以根据自己系统的特性选择最适合的那种。

所有服务器API调用
我们都知道,在微服务架构中可以通过Ribbon或Spring Cloud LoadBalancer进行负载均衡的。
而一旦负载均衡了就会面临一个问题,该请求只会打到集群中的一台应用服务器上,在本地缓存更新的场景上,也就只有一台应用服务器的缓存会被更新。
如下图所示:
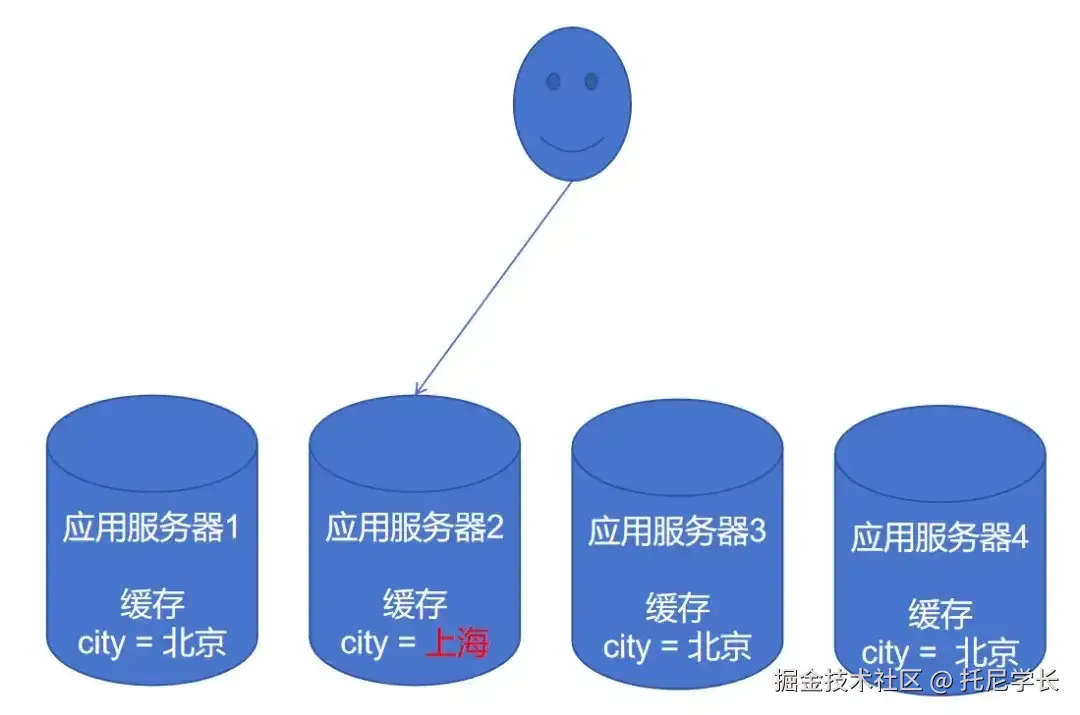
这时,需要我们通过服务发现接口获取所有应用服务器的地址,并全部进行调用访问,才可以更新所有应用服务器的缓存数据。
代码如下所示:
java
@RestController
public class ClusterController {
@Autowired
private DiscoveryClient discoveryClient; // 服务发现客户端
@GetMapping("/cluster/data")
public Mono<Map<String, Object>> getClusterData() {
// 1. 获取所有实例地址(示例:user-service)
List<ServiceInstance> instances = discoveryClient.getInstances("user-service");
List<Mono<Map<String, Object>>> instanceCalls = instances.stream()
.map(instance -> {
String url = "http://" + instance.getHost() + ":" + instance.getPort() + "/data";
return WebClient.create()
.get()
.uri(url)
.retrieve()
.bodyToMono(Map.class);
})
.collect(Collectors.toList());
// 2. 并行调用所有实例并聚合结果
return Flux.merge(instanceCalls)
.collectMap(
result -> (String) result.get("nodeId"), // 使用节点ID作为Key
result -> result
);
}
}这种方案简单容易上手,且不用引入任何外部依赖,数据实时性高,只支持通过程序进行主动更新。
配置中心监听
我们还可以通过配置中心(Nacos、Eureka等)的特性完成本地缓存的数据更新。
当集群中的一台应用服务器收到更新本地缓存的请求,先调用配置中心的API进行配置变更,所有服务器再监听配置变化来更新本地缓存。
如下图所示:
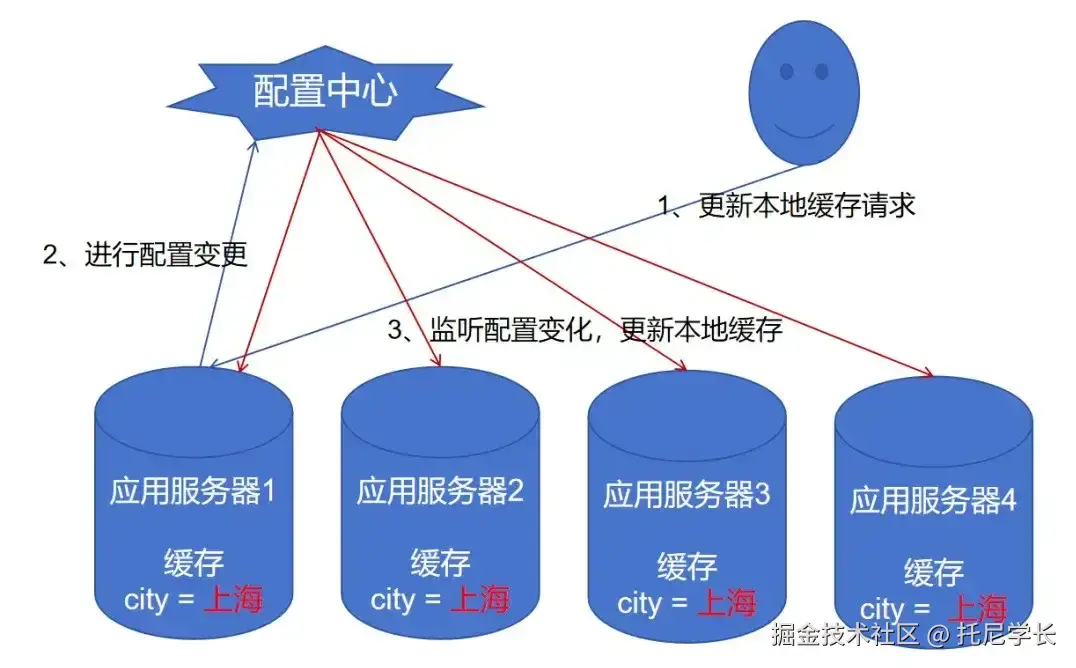
配置变更的代码如下:
(1)添加依赖的SDK
java
<dependency>
<groupId>com.alibaba.nacos</groupId>
<artifactId>nacos-client</artifactId>
<version>2.2.3</version>
</dependency>(2)配置变更代码
java
import com.alibaba.nacos.api.NacosFactory;
import com.alibaba.nacos.api.config.ConfigService;
import com.alibaba.nacos.api.exception.NacosException;
import java.util.Properties;
public class NacosSdkConfigUpdater {
public static void updateConfig(String serverAddr, String dataId, String group,
String namespaceId, String content) throws NacosException {
Properties properties = new Properties();
properties.put("serverAddr", serverAddr);
properties.put("namespace", namespaceId);
ConfigService configService = NacosFactory.createConfigService(properties);
boolean isPublishOk = configService.publishConfig(dataId, group, content);
if (isPublishOk) {
System.out.println("配置更新成功");
} else {
System.err.println("配置更新失败");
}
}
public static void main(String[] args) {
try {
updateConfig(
"127.0.0.1:8848", // Nacos服务器地址
"example-data", // dataId
"DEFAULT_GROUP", // group
"", // namespaceId,默认为空
"newContent=tony" // 新配置内容
);
} catch (NacosException e) {
e.printStackTrace();
}
}
}(3)监听配置变更
java
import com.alibaba.nacos.api.NacosFactory;
import com.alibaba.nacos.api.config.ConfigService;
import com.alibaba.nacos.api.config.listener.Listener;
import com.alibaba.nacos.api.exception.NacosException;
import java.util.Properties;
import java.util.concurrent.Executor;
public class NacosConfigListener {
public static void main(String[] args) throws NacosException {
// Nacos服务器地址
String serverAddr = "127.0.0.1:8848";
// 配置的Data ID
String dataId = "example-data";
// 配置的分组
String group = "DEFAULT_GROUP";
// 命名空间ID(可选)
String namespaceId = "";
// 1. 创建配置服务
Properties properties = new Properties();
properties.put("serverAddr", serverAddr);
if (namespaceId != null && !namespaceId.isEmpty()) {
properties.put("namespace", namespaceId);
}
ConfigService configService = NacosFactory.createConfigService(properties);
// 2. 添加监听器
configService.addListener(dataId, group, new Listener() {
@Override
public void receiveConfigInfo(String configInfo) {
// 当配置变更时,会调用这个方法
System.out.println("配置发生变更,新内容为:");
System.out.println(configInfo);
//更新本地缓存
}
@Override
public Executor getExecutor() {
// 返回执行器,如果返回null,则使用默认的执行器
return null;
}
});
// 保持程序运行,以便持续监听
while (true) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}这种方案实现起来麻烦一些,需要强依赖于配置中心,并存在一定的数据时延性,但可以通过程序进行主动更新,也可以登录配置中心页面进行手动更新。
消息队列广播
这种方案的实现方式与配置中心监听的方式大同小异。
当集群中的一台应用服务器收到更新本地缓存的请求,就往消息队列中发送一条广播模式的消息,所有服务器消费这条消息来更新本地缓存。
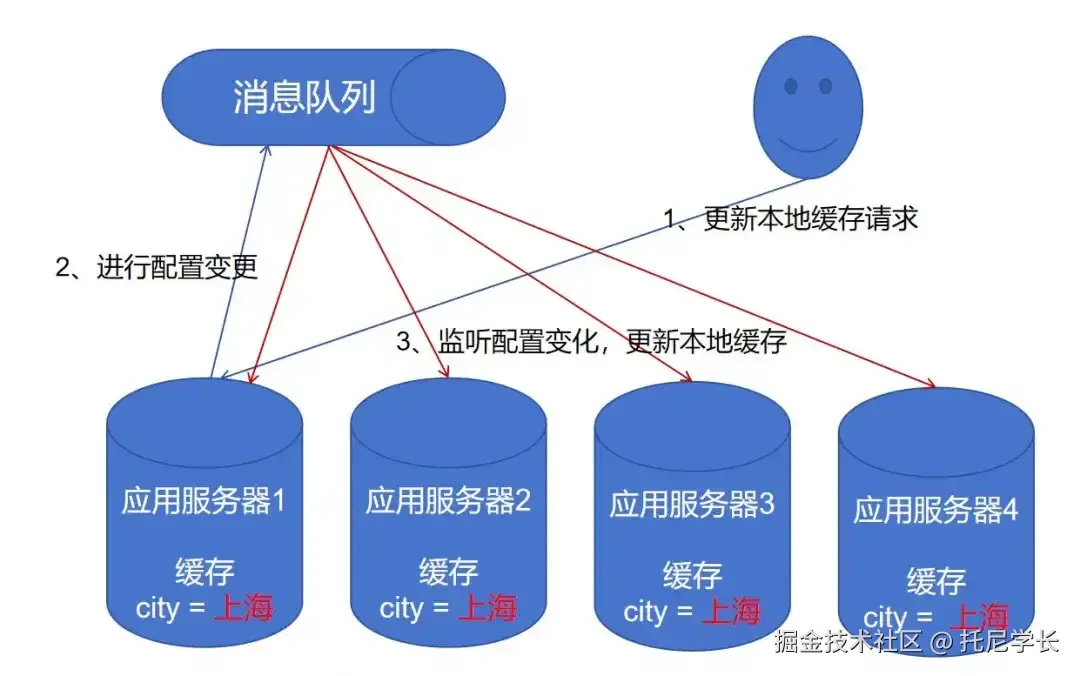
这种方案实现起来麻烦一些,需要强依赖于消息队列,并存在一定的数据时延性,只支持通过程序进行主动更新,并没有明显的优势。
XXL-JOB分片广播
前三种方案都是以用户请求为驱动来触发的,而这种方案则是通过定时任务的方案进行触发的。
XXL-JOB是一个分布式任务调度平台,其分片广播模式的实现机制是,通过调度中心往各个执行器发送请求来执行业务逻辑。
btw:这里所说的调度中心就是集群中的各个应用服务器。
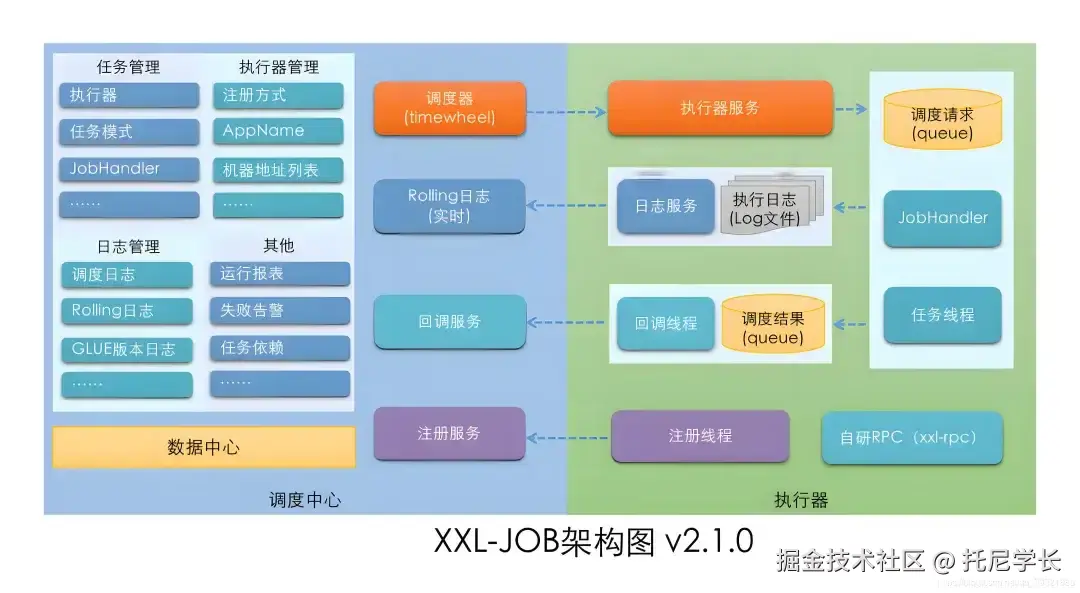
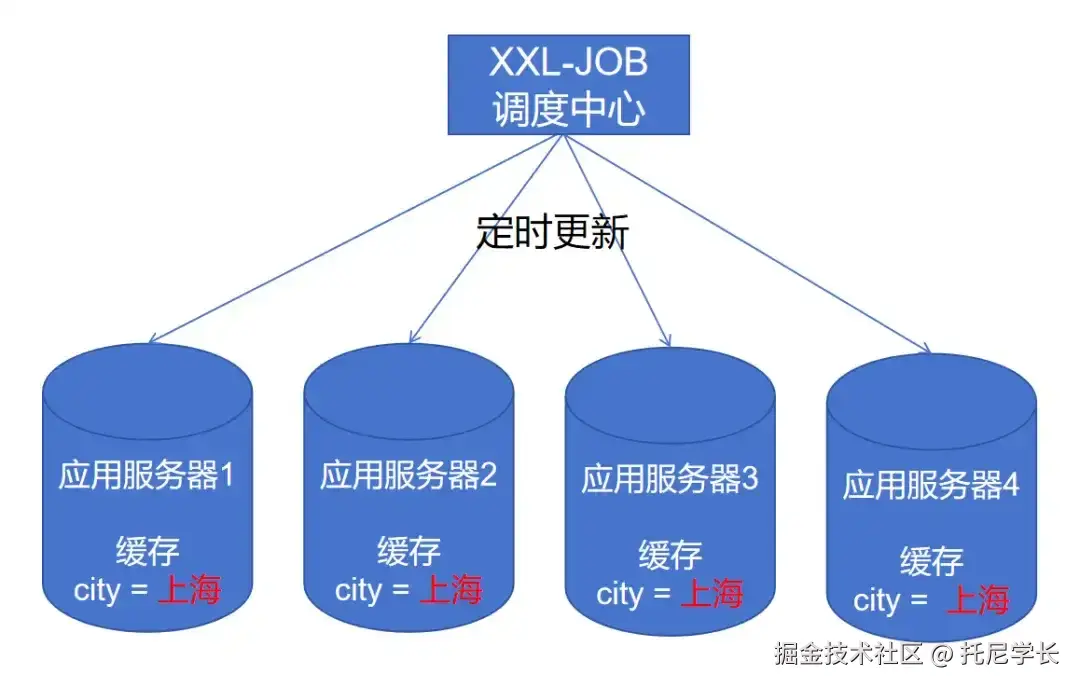
实现代码如下:
java
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.handler.IJobHandler;
import com.xxl.job.core.handler.annotation.JobHandler;
import org.springframework.stereotype.Component;
@JobHandler(value="shardingJobHandler")
@Component
public class ShardingJobHandler extends IJobHandler {
@Override
public ReturnT<String> execute(String param) throws Exception {
// 获取分片参数
int shardIndex = XxlJobHelper.getShardIndex(); // 当前分片序号(从0开始)
int shardTotal = XxlJobHelper.getShardTotal(); // 总分片数
System.out.println("分片参数: 当前分片=" + shardIndex + ", 总分片数=" + shardTotal);
// 更新本地缓存
return ReturnT.SUCCESS;
}
}如果XXL-JOB的调度中心挂了,可以直接向执行器发送请求即可触发任务,或者通过一个操作系统任务定时发送请求。
格式如下:
java
POST http://执行器IP:端口/run
Content-Type: application/json
{
"jobId": 任务ID,
"executorHandler": "任务处理器名称",
"executorParams": "任务参数",
"logId": 日志ID(可随机生成),
"broadcastIndex": 0,
"logDateTime": 当前时间戳
}这种方案适用于对数据一致性要求不高的场景,通过XXL-JOB对本地缓存进行定期更新,方案复杂度适中。