点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年08月04日更新到: Java-94 深入浅出 MySQL EXPLAIN详解:索引分析与查询优化详解 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解

章节内容
上节我们完成了如下的内容,基本都是特性概念相关的:
- 分区相关介绍
- 副本机制
- 同步节点
- 宕机恢复
- Leader选举 基础概念、选举过程、为何不少数服从多数

Kafka 分区(Partition)概念
Kafka 分区是 Kafka 中一个非常核心的概念。每个 Kafka 主题(Topic)都可以被划分成多个分区。分区使得 Kafka 能够横向扩展,并提高数据的处理能力。
什么是分区
-
分区的作用:
- Kafka 通过将消息分发到多个分区中,实现数据的并行处理。每个分区都是一个有序的消息队列,消息在分区内按照写入的顺序存储,并且每条消息都具有唯一的偏移量(Offset)。
- 分区机制使得Kafka能够支持水平扩展,当消息量增加时,可以通过增加分区数量来提高系统的整体吞吐量。
- 例如,一个包含10个分区的主题可以同时被10个消费者并行处理,这比单一分区能处理更多的消息。
-
数据分布:
- 分区可以分布在不同的 Kafka Broker 上,这使得 Kafka 可以通过增加分区数来扩展集群的吞吐量。
- 每个分区会被分配到一个特定的Broker上,这个Broker称为该分区的Leader。同时,分区的副本会被复制到其他Broker上,确保数据的可靠性。
- 例如,在一个3个Broker的集群中,一个有3个分区的主题可能会将每个分区的Leader分布在不同的Broker上,以实现负载均衡。
- 通过增加分区数量,消息可以被更均匀地分散到集群中的各个Broker,从而提高整体吞吐量。但同时需要注意,分区数量过多可能会导致元数据管理开销增加。
分区的优势
1. 并行处理能力提升
通过将数据分散到多个分区,系统可以实现真正的并行处理:
- 生产者端:消息可以并发写入不同分区
- 消费者端:消费者组内的多个消费者可以分别消费不同分区的数据,形成"多个消费者并行处理多个分区"的高效模式
- 吞吐量提升:假设一个主题有10个分区,理论上可以比单分区处理提升近10倍的吞吐量
典型应用场景:
- 电商大促期间的高并发订单处理
- 实时日志收集与分析系统
- 物联网设备数据采集
2. 高可用容错机制
分区的副本机制提供了强大的容错能力:
副本架构:
- 每个分区包含1个Leader副本和多个Follower副本
- 副本分布在不同的Broker上,遵循机架感知策略
故障处理流程:
- 当Leader副本所在Broker宕机时
- 控制器(Controller)会从ISR(In-Sync Replicas)列表中选择新Leader
- 新Leader开始提供服务,整个过程通常在秒级完成
数据安全保障:
- 写入操作需要等待所有ISR副本确认才算成功
- 即使丢失一个Broker,数据仍然可以从其他副本恢复
- 支持配置不同的副本因子(通常3副本)
示例配置:
properties
# 创建主题时指定副本数
bin/kafka-topics.sh --create \
--topic orders \
--partitions 10 \
--replication-factor 3 \
--bootstrap-server localhost:9092这种设计特别适合对数据可靠性要求高的场景,如:
- 金融交易系统
- 医疗数据系统
- 政府关键业务系统
分区重分配
向已经部署好的Kafka集群里添加机器,我们需要从已经部署好的Kafka节点中复制相应的配置文件,然后把里边的 BrokerID 修改为全局唯一的,最后启动这个节点即可让它加入到现有的Kafka集群中。
分区重新分配(Partition Reassignment)
分区重新分配是 Kafka 中用于重新平衡分区在不同 Broker 之间的核心机制。它通过调整分区在不同 Broker 上的分布来优化集群性能和可靠性。以下是其主要应用场景及详细说明:
主要应用场景
1. Broker 扩容或缩容
- 新增 Broker :当集群需要水平扩展时,新加入的 Broker 需要承担部分负载。例如:
- 一个 3 节点的集群扩容到 5 节点
- 需要将现有分区的 30-40% 迁移到新 Broker 上
- 移除 Broker :当节点需要下线维护或退役时:
- 需要将该节点上的所有分区迁移到其他可用节点
- 确保迁移过程中保持副本同步和可用性
2. 负载不均衡调整
- 分区分布不均 :
- 某些 Broker 可能承载了过多分区(如 Broker1 有 50 个分区,而其他只有 20 个)
- 热点 Broker CPU/磁盘/I/O 使用率明显高于其他节点
- 磁盘空间管理 :
- 当某些 Broker 磁盘将满时(如使用率超过 85%)
- 需要将部分分区迁移到磁盘空间充足的 Broker
3. 机架感知优化
- 在跨机架部署中,确保分区的副本分布在不同的机架上:
- 避免单机架故障导致数据不可用
- 通常需要配置
broker.rack参数
实施步骤详解
-
生成重新分配计划:
- 使用
kafka-reassign-partitions.sh工具 - 可以手动指定目标分配,或使用
--generate自动生成
- 使用
-
执行验证:
- 先执行
--verify检查计划可行性 - 确认不会导致副本数不足或违反机架策略
- 先执行
-
分阶段执行:
- 对于大型集群,建议分批迁移(如每次 10% 的分区)
- 监控带宽和性能影响
-
完成确认:
- 最终验证所有分区已正确迁移
- 检查 ISR(In-Sync Replicas)列表是否完整
注意事项
- 网络带宽:大规模迁移可能消耗大量网络带宽
- 性能影响:迁移过程中可能短暂影响生产/消费性能
- 监控指标 :需特别关注以下指标:
- 未同步副本数
- 控制器队列大小
- 网络出入流量
最佳实践
- 在业务低峰期执行重分配
- 提前做好容量规划
- 使用
throttle参数限制迁移速度 - 保留完整的迁移日志和回滚方案
当前问题
新添加的Kafka节点并不会自动的分配数据,无法分担集群的负载,除非我们新建一个Topic。 在重新分布Topic分区之前,我们先来看看现在Topic的各个分区的分布位置。
启动服务
如果你的Kafka服务还未启动,需要先启动,再进行后续的测试实验。 我这里启动:
shell
kafka-server-start.sh /opt/servers/kafka_2.12-2.7.2/config/server.properties启动结果如下图: 
创建主题
shell
kafka-topics.sh --zookeeper h121.wzk.icu:2181 --create --topic wzk_topic_test --partitions 5 --replication-factor 1我们的配置:
- 创建一个5个分区的主题
- Kafka此时的算法会保证所有分区都分配到现有的Kafka代理节点上
创建的结果如下: 
查看主题
shell
kafka-topics.sh --zookeeper h121.wzk.icu:2181 --describe --topic wzk_icu_test创建的结果如下图,可以观察到5个分区。 
新增Kafka
在新的机器上部署Kafka服务,记得修改BrokerID。 刚才我们是单节点的,Kafka在 h121 节点上。
shell
# 配置内容参考 h121 中的配置
# 但是注意要修改 BrokerID
vim config/server.properties- h121 broker 1
- h122 broker 2
- h123 broker 3 (暂时还不配置3节点)
 此时我们来到 h122 用如下的命令启动Kafka,我启动的是临时的,如果你有需要,请用守护方式启动。
此时我们来到 h122 用如下的命令启动Kafka,我启动的是临时的,如果你有需要,请用守护方式启动。
shell
# 环境变量别忘了配置
kafka-server-start.sh /opt/servers/kafka_2.12-2.7.2/config/server.properties启动过程如下图: 
查看集群
shell
# 先进入ZK 在ZK中进行查看
zkCli.sh
get /cluster/id执行的过程是:
shell
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0] get /cluster/id
{"version":"1","id":"DGjwPmfLSk2OKosFFLZJpg"}重新分区
我们使用Kafka自带的:kafka-reassign-partitions.sh 工具来重新发布分区,该工具有三种使用模式:
- generate模式,给定需要重新分配的的Topic,自动生成 reassign plan (不会自动执行)
- execute模式,根据指定的 reassign plan重新分配 Partition
- verify模式,验证重新分配Partition是否成功
生成JSON
shell
vim wzk_icu_test_to_move.json
{
"topics": [
{
"topic": "wzk_icu_test"
}
],
"version": 1
}当前结果如下: 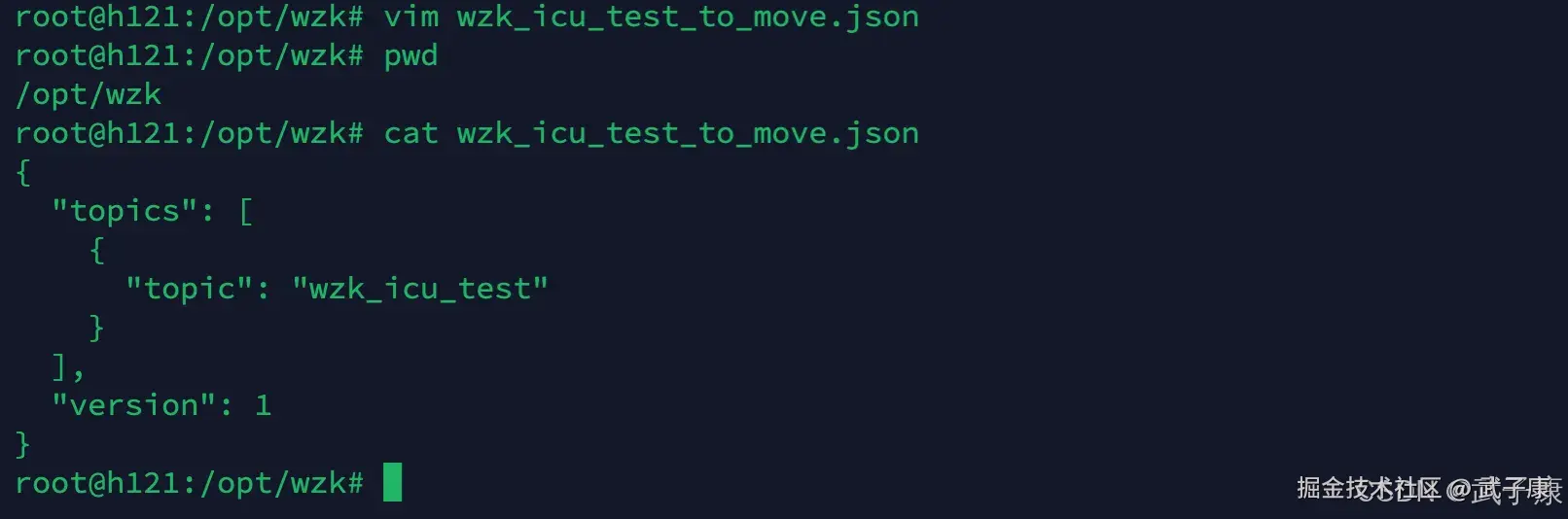 执行如下的脚本,来对分区进行配置:
执行如下的脚本,来对分区进行配置:
shell
kafka-reassign-partitions.sh --zookeeper h121.wzk.icu:2181 --topics-to-move-json-file wzk_icu_test_to_move.json --broker-list "0,1" --generate观察控制台的结果: 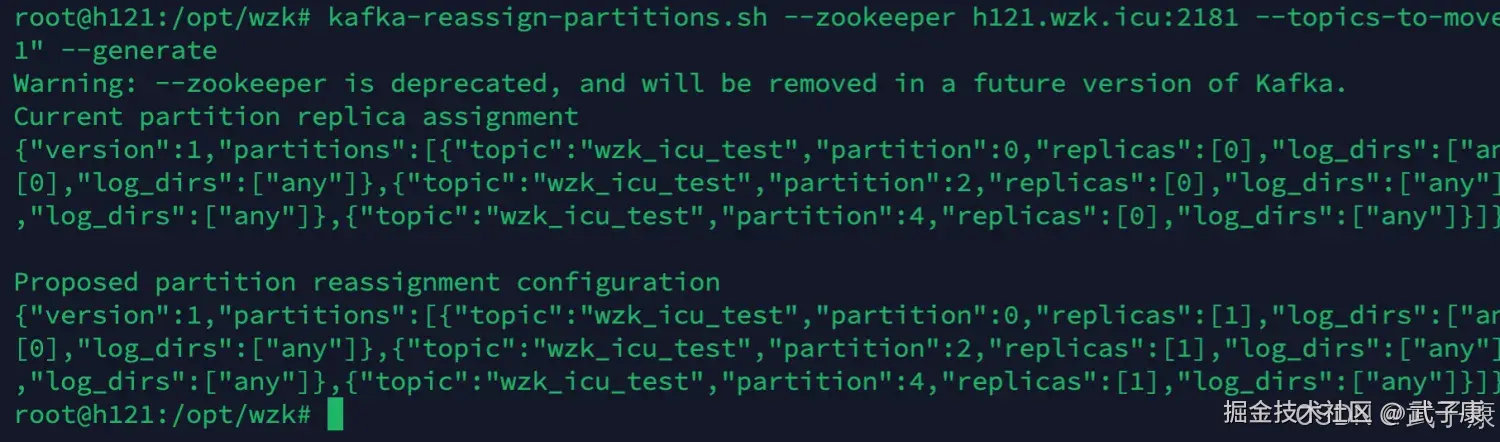
执行计划
Proposed Partition Reassignment Configuration 下面生成的就是将分区重新发布到 Broker 1上的结果,我们将这些内容保存到 result.json 中
shell
vim result.json
{"version":1,"partitions":[{"topic":"wzk_icu_test","partition":0,"replicas":[1],"log_dirs":["any"]},{"topic":"wzk_icu_test","partition":1,"replicas":[0],"log_dirs":["any"]},{"topic":"wzk_icu_test","partition":2,"replicas":[1],"log_dirs":["any"]},{"topic":"wzk_icu_test","partition":3,"replicas":[0],"log_dirs":["any"]},{"topic":"wzk_icu_test","partition":4,"replicas":[1],"log_dirs":["any"]}]}运行后的写入情况如下:  我们继续执行:
我们继续执行:
shell
kafka-reassign-partitions.sh --zookeeper h121.wzk.icu:2181 --reassignment-json-file wzk_icu_test_to_move_result.json --execute显示结果如下,已经完成分区: 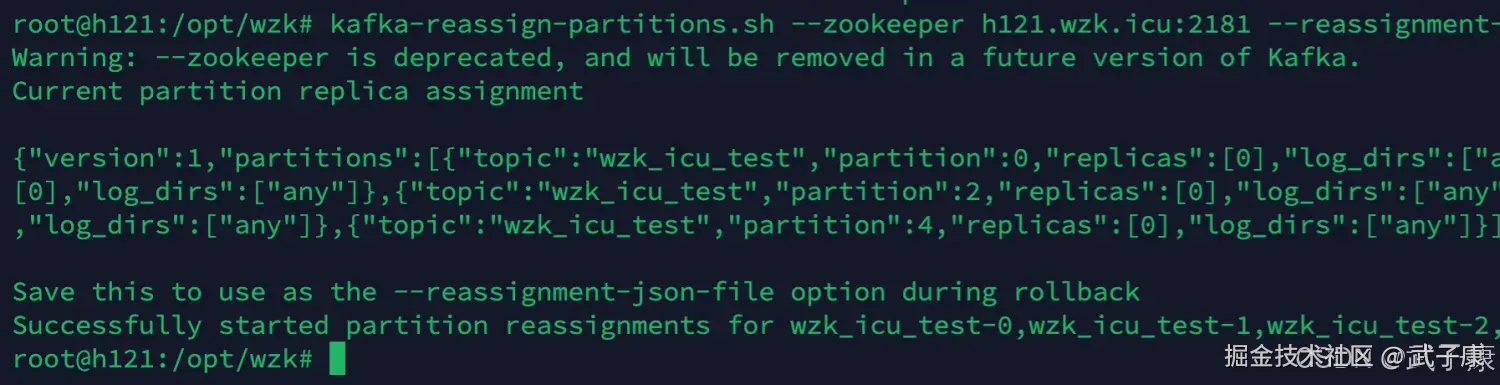
校验结果
shell
kafka-reassign-partitions.sh --zookeeper h121.wzk.icu:2181 --reassignment-json-file wzk_icu_test_to_move_result.json --verify显示结果如下: 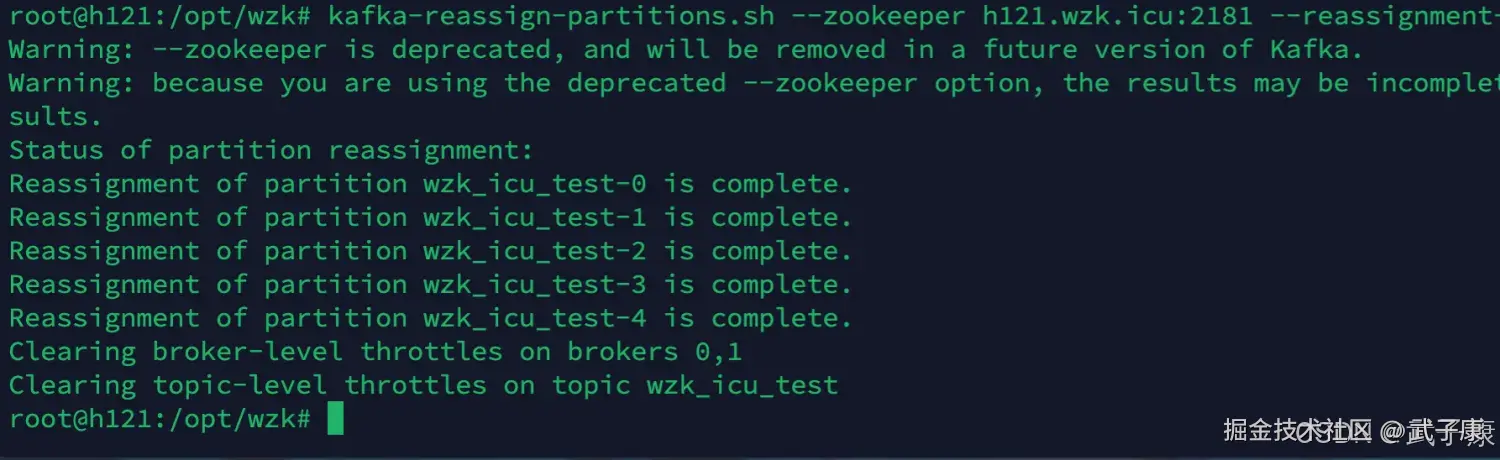
重新查看分区情况
shell
kafka-topics.sh --zookeeper h121.wzk.icu:2181 --describe --topic wzk_icu_test 显示的内容如下:  可以看到我们已经顺利的完成了重新分区分配!
可以看到我们已经顺利的完成了重新分区分配!
实际应用中的分区设计与优化
在实际应用中,Kafka 分区的数量、分区副本因子、以及如何合理地重新分配分区,是保证 Kafka 集群高效运行的关键因素。
- 合理设置分区数量:分区数量不宜过多或过少,应根据系统的吞吐量需求和 Broker 的资源情况进行规划。
- 定期检查与调整:随着业务的发展,Kafka 集群的负载情况可能会发生变化,定期检查分区的分布情况,并根据需要进行调整,是保持系统稳定运行的重要手段。