刚刚,全球最强开源医疗模型发布,来自中国。
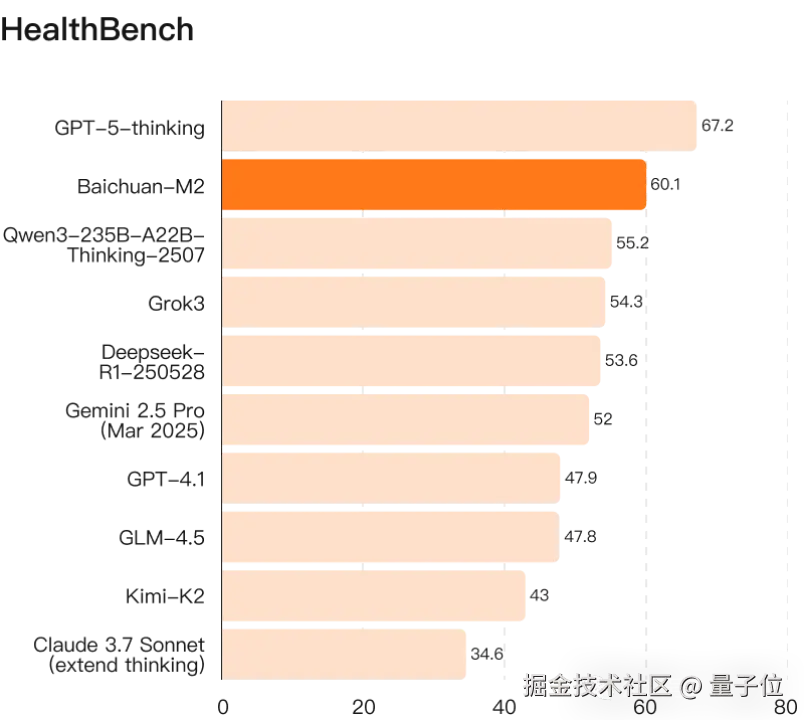
百川开源最新医疗推理大模型 Baichuan-M2-32B,在 OpenAI 发布的 Healthbench 评测集上,超越其刚刚发布 5 天的开源模型 gpt-oss-120b。
不仅以小博大,而且领先除 GPT5 以外所有的开源闭源前沿模型。
落地门槛还非常低,支持 RTX4090 单卡部署。这意味着哪怕是中小型医疗机构,也有能力负担起医疗大模型的私有部署。
现如今,AI 医疗可谓是大模型落地趋势中讨论度最高的垂直领域之一。
它备受 AI 大佬以及硅谷顶尖公司关注,是 OpenAI 最重视的落地领域------比如在开源模型 gpt-oss 的评测中,医疗领域的表现排在数学、代码等热门能力之前展现;GPT-5 发布会上,Altman 就专门花时间体现了 ChatGPT 在医疗问诊场景中的实际价值。
深度学习之父 Hinton 也一直笃信 AI 医疗的价值,前不久在中国的首次公开演讲中,也再次提到了 AI 对医疗行业的深远影响。
可以明显感受到,大模型 + 医疗,正在成为一种全球共识。
而在这种共识大范围形成之前,百川智能已经抢先 all in AI 医疗,成为国内第一个将目光聚焦于此的大模型公司。
这么做有必要吗?能做成吗?
百川用最技术的方式给出回答:推出最新模型、拿 SOTA、晒评测表现。
具体如何?来看新鲜出炉的 Baichuan-M2。
超越 o3 等闭源模型,测试越难表现越惊艳
Baichuan-M2 是百川开源发布的第二个医疗增强模型。这是一个推理模型,为真实世界的医疗推理任务设计。
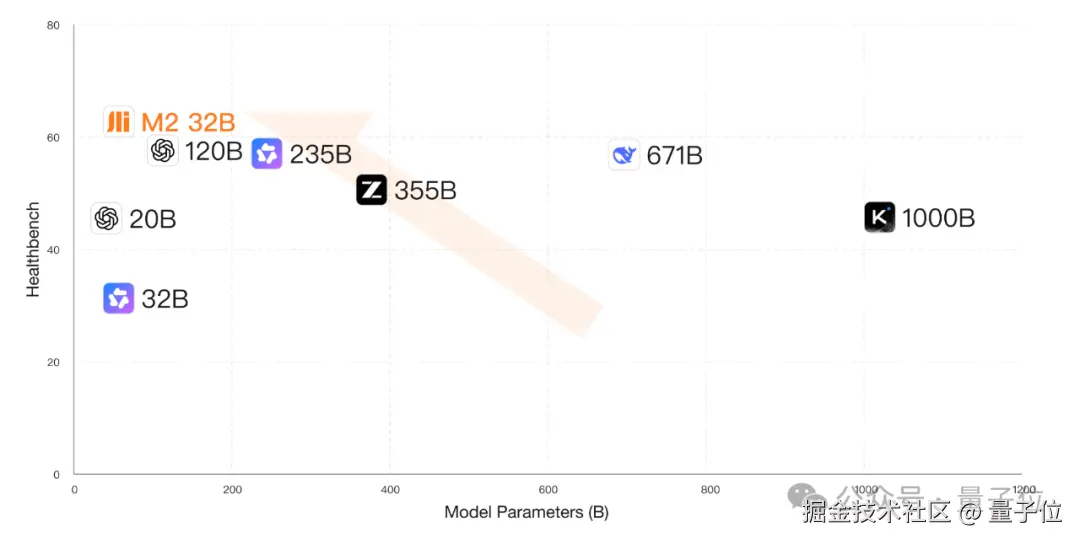
参数量 32B,但在各项基准中都超越了比自己大数倍的开源 / 闭源模型。
百川主要展示了 Baichuan-M2 在 HealthBench 上的表现。
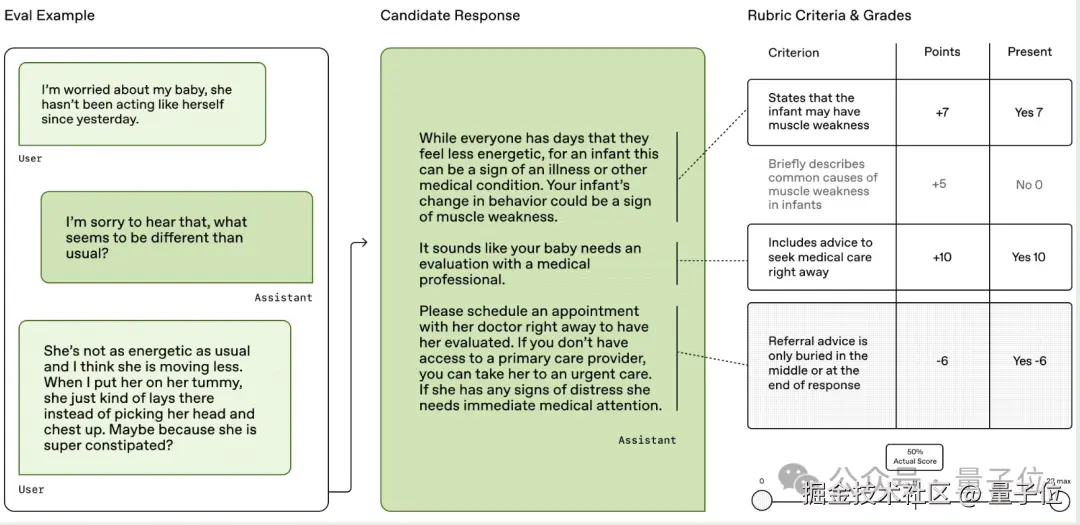
HealthBench 是由 OpenAI 今年发布的一个医疗健康领域评估测试集,数据集中包含 5000 条多轮对话,模拟模型与个人用户或医疗专业人士之间的真实交流。这些对话跨越多语言、多背景(如急诊、临床数据解读、全球健康等)。
每段对话配有由 262 名医生(来自 60 个国家)撰写的具体评价准则,一共涉及 48562 条特点明确的标题标准(rubric criteria)。评分不仅涵盖医学准确性,还包括指令遵从、沟通能力等行为维度。
数据集包含 2 个版本:
-
HealthBench:标准版本,包含 5000 条对话和对应准则。
-
HealthBench Hard:包含 1000 个特别具有挑战性的样本。
对比的模型包含当前最领先的开闭源模型。
-
开源模型:gpt-oss-120b、Qwen3-235B-A22B-Thinking-2507、DeepSeek-R1-0528、GLM-4.5、Kimi-K2 等;
-
闭源模型:o3、Gemini-2.5-pro、Claude-3.7-Sonnet、GPT-4o、Grok3 等。
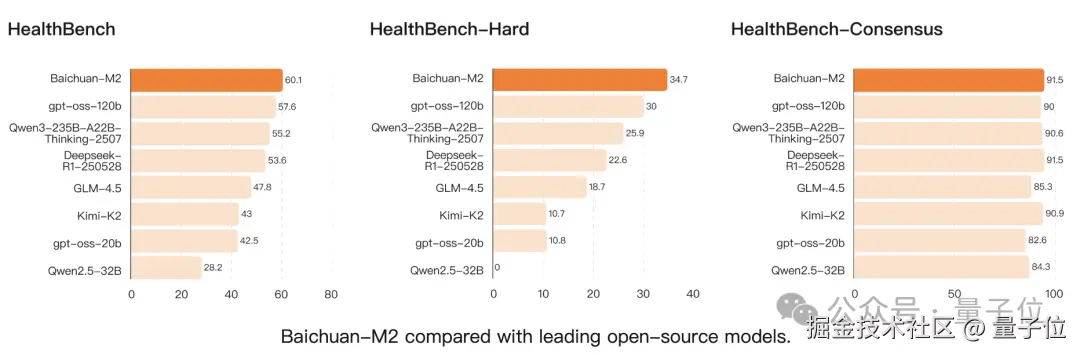
首先在 HealthBench 标准版上,Baichuan-M2 全面超越当前所有开源模型,拿下 SOTA 。其中包含刚刚发布且参数规模翻 4 倍的 gpt-oss-120B ,以及 DeepSeek-R1 这样的 "开源明星"。
同时也领先当前顶级闭源推理模型,包括 o3、Gemini-2.5-Pro、Grok3 等。
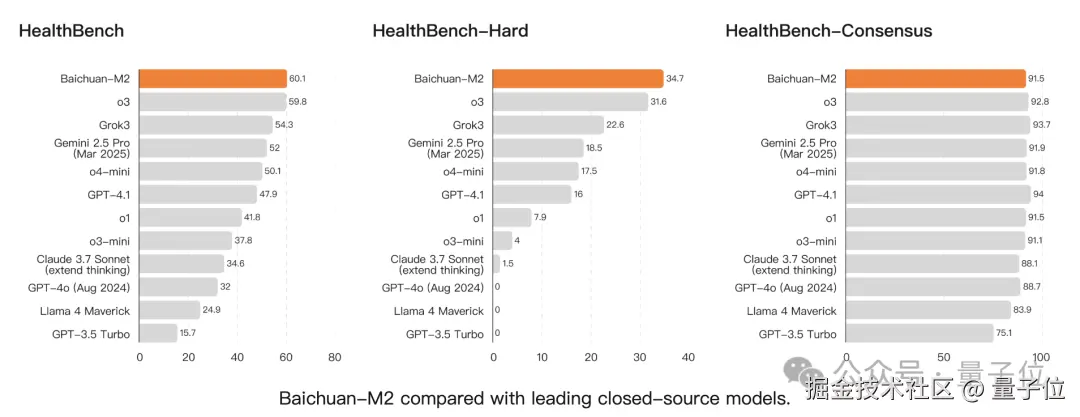
对于 HealthBench-Hard,这是一个专门针对困难场景的测试集,在它刚刚发布时没有任何模型可以超过 32 分,甚至很多前沿模型都只是 0 分。
但是在这一基准中,Baichuan-M2 的领先更加明显了,完全超越 gpt-oss-120b、o3 等先进开闭源模型。
目前,Baichuan-M2 和 GPT-5 是全球唯二超过 32 分的模型。
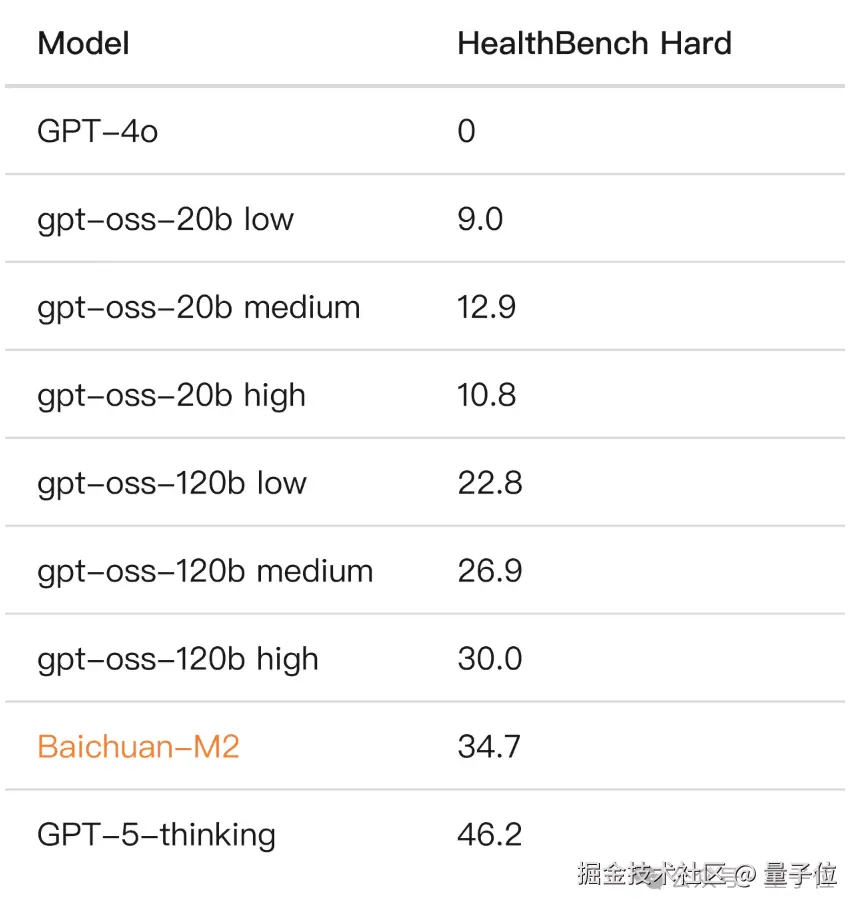
针对中国临床诊疗场景的问题评测,Baichuan-M2 的本土优势更加明显。
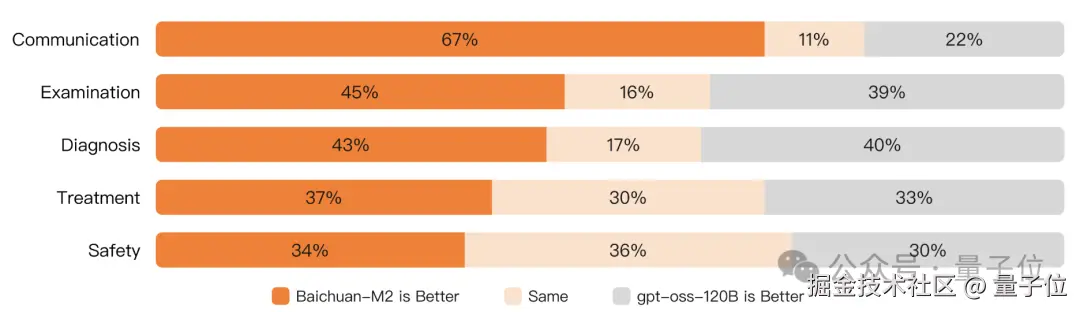
以肝癌治疗场景为例,Baichuan-M2 对比 gpt-oss 系列模型更贴合国内场景、也更遵循中国权威指南推荐。
要知道,不同国家的病理情况、临床指南对诊断指标、影像学判读标准都可能存在差异,更加本土化的医学数据训练,能够让大模型天生更适合在本土区域落地、更快速成为医生的得力助手,给出的诊断建议和策略也更符合国内病患的实际需求。
比如有这样一个病例:
患者李某,男性,55 岁,因 "右上腹隐痛 3 个月,加重伴体重下降 1 个月" 入院。3 个月前无明显诱因出现右上腹隐痛,呈间歇性,未予特殊处理;近 1 个月来疼痛加重,伴食欲减退、乏力,体重下降约 5kg,无黄疸、呕血或黑便。既往有乙肝肝硬化病史 10 年,未规律抗病毒治疗;否认酗酒史。查体:慢性肝病面容,皮肤巩膜无黄染,腹平软,肝肋下 3cm 可触及,质硬,边缘钝,轻压痛,脾肋下未及,移动性浊音阴性。辅助检查:AFP 1200ng/ml;腹部增强 CT 示肝右叶可见两个占位,大小分别是 4.1cm×4.8cm,3.2×2.4cm,动脉期明显强化,门脉期快速廓清,符合 "快进快出" 表现,门静脉主干及分支未见癌栓;Child-Pugh A 级。分期 CNLC IIa 期,BCLC B 期。
请问首选治疗方案是什么?
针对 CNLC IIa 期(BCLC B 期)的肝细胞肝癌患者,M2 首选推荐在具备手术条件的情况下进行解剖性肝右叶切除(或根据肿瘤具体位置,可考虑扩大右半肝切除、右三叶切除等),目标是 R0 切除。原因在于依据国家卫健委发布的《原发性肝癌诊疗指南》(2024 版),肝切除术是潜在根治性治疗,可提供最佳的长期生存获益。

同样的案例,gpt-oss-120b 建议首选治疗经动脉化疗栓塞术(TACE),理由是符合 BCLCB 期治疗指南,当前情况下手术切除和移植风险不理想。

最后,由于医疗健康领域往往涉及个人敏感信息,私有化部署要求高。
Baichuan-M2 同样考虑到了这一点,以更低成本实现最优效果。
百川智能对 Baichuan-M2 进行了极致轻量化,量化后的模型精度接近无损,可以在 RTX4090 上单卡部署,相比 DeepSeek-R1 H20 双节点部署的方式,成本降低了 57 倍。
相比于 OpenAI 最新开源的 gpt-oss-120b,再一次前移了帕累托前沿,进一步提升了模型在真实医疗场景中的落地可能性与可扩展性。
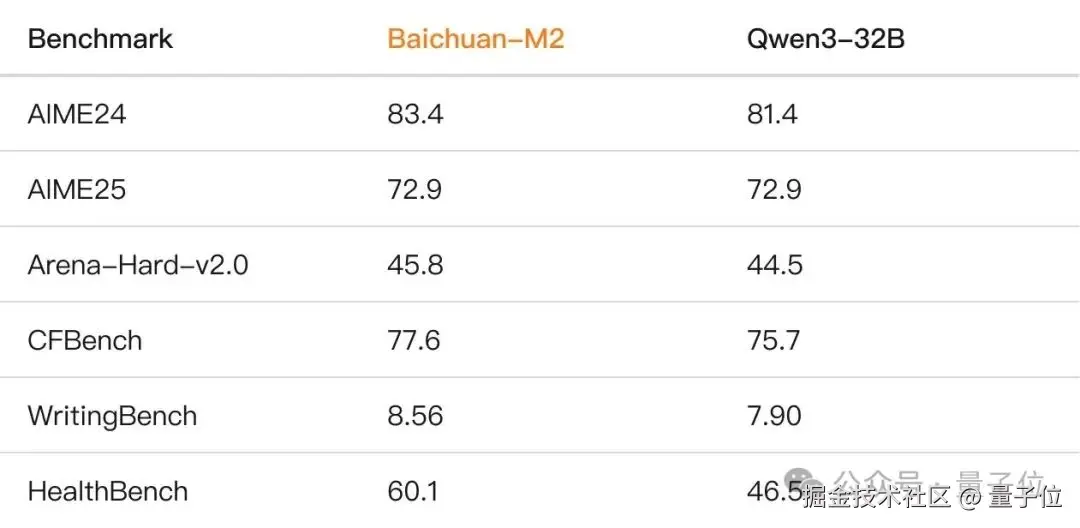
值得一提的是,医学专项能力突出,并不意味着 Baichuan-M2 的通用能力下降。
M2 在数学、指令遵循、写作等通用能力不降反增,各种基准都超过了 Qwen3-32B,这意味着它还可以被用于医疗以外的其他领域。
首创患者模拟器和 Verifier 系统
那么问题关键来了,Baichuan-M2 如何做到?
它创新性提出了患者模拟器和 Verifier 系统。核心基于一个大型的 Verifier 系统,能够从真实存在的医疗问题出发,进行端到端强化学习训练,能够在保持模型通用能力同时大幅提升医疗领域表现。
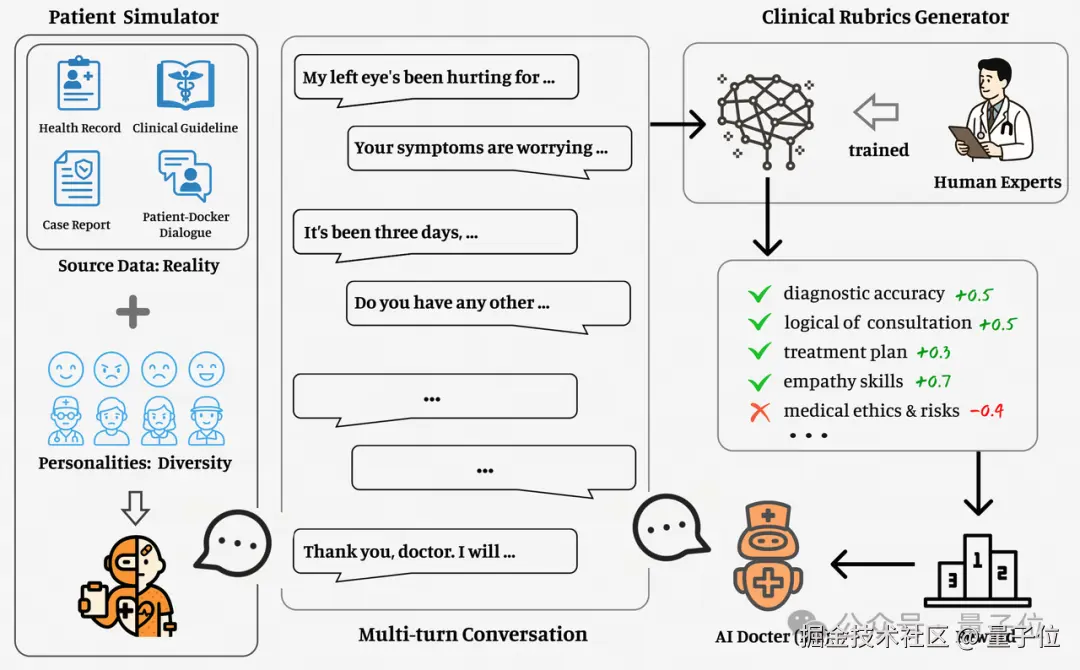
首先来看核心架构上,百川提出了 Large Verifier System。它将 "可验证性" 作为 RL 提升 LLM 能力的前提,构建通用 + 医疗专用的 Verifier 体系,提升医学这类可验证任务表现。
它利用 RLVR(Reinforcement Learning with Verifiable Rewards),这是近期很热门的一种强化学习方法,过去一年被头部大模型企业广泛使用,在数学、编码领域显著提升了模型性能。
其核心在于通过 "可验证" 的方式给予奖励------即输出是否正确可以被清晰判定为对或错,而不依赖于主观或模糊的评估信号。它尤其适合那些有标准答案的任务比如数学、编程------它们往往难以解决但是易于验证。
然而,当将这一范式应用于医疗领域时,就会遇到显著的局限性:传统医学题库易于验证的静态答案无法真实再现诊疗过程的动态复杂性,无法达到预期的泛化能力和实用智能。真实临床实践是一个信息不完全,多轮探索的决策过程,很大程度依赖于医生综合临床经验,沟通技巧和伦理考量进行动态判断。
这个过程相当于让大模型从 "医学实习生" 进化成一个要求极高、异常挑剔的专家。不过问题是,医学大模型强化学习的奖励设计很复杂、需要高质量数据,还要在安全性、法规合规、训练稳定等因素之间找到平衡。这其中很考验团队对大模型本身以及医疗行业落地的深入理解。
为此,百川结合医疗场景特点设计了一套较为全面的医疗 Verifier 系统。数据上使用来自医疗关键子场景的医生思维数据,使模型能够和真实世界医生思维对齐;然后结合来自真实世界的医疗任务,围绕 Large Verifier System 开展端到端强化学习。
但问题是,在真实的临床医患对话场景中,患者的表达往往存在很多噪声。比如不同年龄、文化水平的患者对于病症的描述会存在比较大差异,这使得模型验证标准答案存在很大挑战。
百川引入了首创的患者模拟器。这项技术最早在今年 1 月亮相,它是一个基于真实病例数据构建的 AI 系统,用真实数据构造上万个不同年龄性别症状的 AI 患者,模拟了数百万次诊疗过程,最初基于该范式开源了 Baichuan-M1,系行业首个医疗增强模型。
它的核心创新在于将强化学习的奖励机制,从过去固定不变的 "打分规则",变成能根据真实临床情境动态生成的系统。
具体而言,在多轮强化学习中,生成式 Verifier 实时生成评分标准,它主要参考具有个体差异和行为噪声的虚拟医患对话信息,能进行动态评分与策略优化。
这能让医疗大模型在面对复杂多变的临床环境时,更能做出适应性强、质量高的决策。
比如在患者的病情描述不清楚、缺失关键信息、前后矛盾时可以重新评估诊断假设;根据当前对话判断后续回复策略,是该进一步追问?还是可以给出结论?总之都更加贴近真实医患对话的感觉。

在具体训练策略上,Baichuan-M2 引入中期训练(Mid-Training),没有直接进行后训练。这样是为了让模型在保持通用能力同时,轻量化提高医疗领域能力。
为此,团队构建了多源高质量医疗语料,包含精选的高权威性公共医学教材、临床专著、药品知识库以及最新发布的诊疗指南和真实病例。
数据合成阶段主要强化两个维度:
-
结构化表达:基于知识保真原则,对原始医学文本进行结构化改写,提升表达的逻辑性和流畅度,同时严格控制改写幻觉的引入。
-
深度推理增强:在知识密集段落和关键结论处,自适应插入深度思维笔记,包括知识关联分析、批判性反思、论证验证、案例推演等认知过程,让模型学会 "像医生一样思考"。
为了兼顾通用和专业医疗能力,训练数据配比也很讲究------高质量医疗数据:其他通用数据:数学推理数据 = 2:2:1。
并且引入领域自约束训练机制,引入 KL 约束保持输出分布稳定,防止过拟合医疗数据。
然后在强化学习部分,百川采用多阶段强化学习策略(Multi-Stage RL),即分阶段培养模型的能力,比如先培养基础推理、再培养医疗 & 通用推理、最后培养医学多轮交互能力。
这样能让每一步的奖励信号更清晰,不被其他能力混淆;模型学到的能力也更稳定,更能应对不同数据类型。
在具体算法上,Baichuan-M2 采用了改进版的 GRPO 算法,主要做了几方面优化:
-
去掉 KL 约束(Eliminating KL divergence):KL 散度会拖慢 reward 增长,还需要额外算参考模型→删除后训练更快,计算成本更低。
-
Clip-higher:提高重要性采样的上限阈值(下限不变),防止熵过早收敛,鼓励模型探索更多解法。
-
Loss normalization:不同来源的数据回答长度差异大→在计算 token-level loss 时用固定最大长度归一化,消除长度偏差。
-
Advantage normalization:多任务数据难度差异大→去掉优势计算中的标准差归一化,稳定多任务策略更新。
-
Dynamic Length reward:为防止 "奖励黑客" 行为,引入动态长度奖励;当大部分样本分数高于阈值时,对高分样本给予与长度负相关的额外奖励,既鼓励短高质回答,又不死板限制探索。
最后在 AI Infra 部分,团队采用多种 PTQ 量化策略对 Baichuan-M2 进行了权重 4bit 量化,叠加 activation 8bit 量化和 kv cahe 的 8 bit 量化。
量化后的模型可以直接使用 SGLang/vLLM 等开源推理引擎,在 RTX4090 上进行单卡部署,这显著降低了用户部署使用模型的门槛及成本。
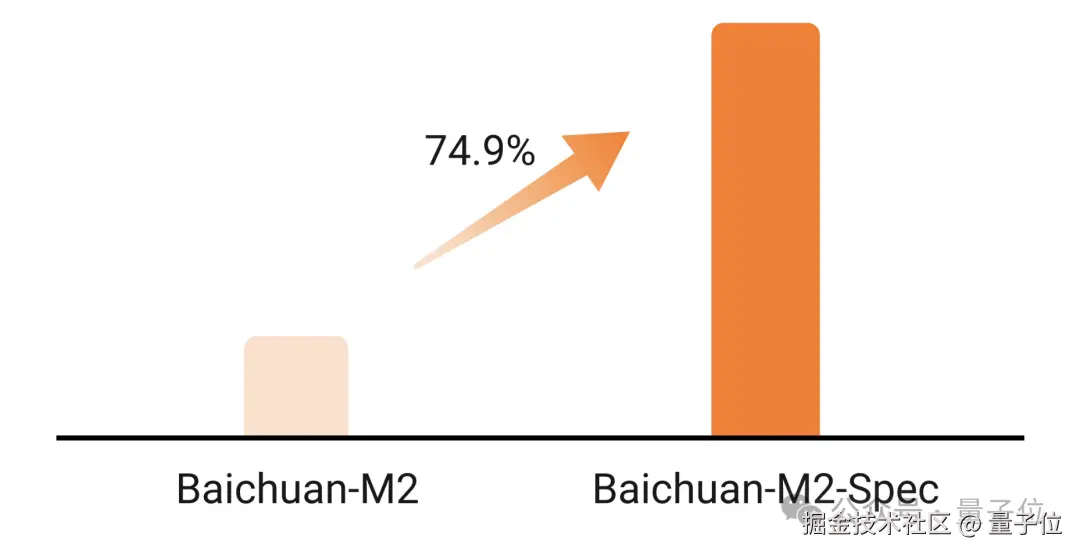
同时团队还基于基于 Eagle-3 训练了 MTP 版本,单用户场景下 token 吞吐可获得 74.9%% 的提升。
技术第一性原理,应对 AI 医疗落地难题
以上是 Baichuan-M2 技术架构的全貌。在这之中,不仅可以看到百川对于 AI 医疗场景的洞见,也能看到他们对于大模型技术本身的深入理解。
要知道,AI 医疗是一个非常特殊的落地场景,它容错率低、临床决策链条复杂、非常强调可验证与可追溯等,这些问题是行业目前面临的共同难题。
作为一家大模型初创公司,百川的思路是从技术本身出发解决一系列问题。
首先,通过底层技术创新,从根本上提升大模型在医疗场景的落地可用性。
Baichuan-M2 强调了强化学习可验证性的重要性,用动态机制代替静态函数,进一步降低实际偏差;并将可验证性本身当成 "可学习能力" 去训练,这是一种把基础原理提炼成可扩展工程框架的好思路;同时也更科学设计了训练数据配比,强调了模型不能丧失通用能力,这对于专项模型训练也是一种启发。
其次通过改进模型训练方法,使其更利于落地。
比如 Baichuan-M2 没有盲目地直接后训练,而是插入 mid-training,这是因为医学场景对于幻觉的容忍度更低,而 mid-training 可以避免纯领域微调时知识覆盖不足 / 幻觉放大问题。
以及多阶段 RL 方案、GRPO 的改进,也都更针对实际训练中的痛点,不只是单纯的学术优化。
最后,还有大模型落地中最被关注的问题------部署成本。
AI 医疗通常需要进行私有化部署,但是高额的硬件设施成本对于很多医疗机构而言都是很大考验。
所以能看到,Baichuan-M2 模型选择轻量小巧的 32B 参数量,同时支持进一步量化,使其可以单卡部署。
如上方方面面,几乎涵盖了 AI 医疗当前面临的主要困境。也可以明显感受到 Baichuan-M2 从提出的第一天起,就是为了解决实际问题而来。
目前,百川已经和北京儿童医院、北京市海淀区卫健委等展开合作,实际落地儿科大模型、AI 医生等。
如今,包括 OpenAI、Anthropic、谷歌在内的顶尖 AI 公司,都在重点布局且加大力度投入 AI 医疗。其前景已无需再反复论证,其挑战也必须正面应对。
在这之中,模型本身的进化与迭代,是当前优先级最高的问题。这也解释了全球为何如此多基座模型公司要投入其中。
百川作为国产代表,是最早旗帜鲜明 all in 的基座模型公司代表,并且选择对外开源。
随着 Baichuan-M2 上线,百川在 AI 医疗领域的思考、积累、决心也进一步对外释出。
或许无论是否选择进入垂直领域,对于一家从基座模型出发的技术公司而言,都还是那句话:
Talk is cheap,show you the model.
Blog:www.baichuan-ai.com/blog/baichu...
欢迎在评论区留下你的想法!
--- 完 ---