目录
[1 -> 前言](#1 -> 前言)
[2 -> 时序数据爆炸:端边云架构的新挑战](#2 -> 时序数据爆炸:端边云架构的新挑战)
[2.1 -> 时序数据库选型核心维度](#2.1 -> 时序数据库选型核心维度)
[2.2 -> IoTDB vs 国外主流方案深度对比](#2.2 -> IoTDB vs 国外主流方案深度对比)
[2.3 -> IoTDB 的 DB+AI 融合创新](#2.3 -> IoTDB 的 DB+AI 融合创新)
[2.4 -> 国产化突围:IoTDB 的生态优势](#2.4 -> 国产化突围:IoTDB 的生态优势)
[3 -> 结语:时序数据库的新范式](#3 -> 结语:时序数据库的新范式)

1 -> 前言
下载链接:https://iotdb.apache.org/zh/Download/
企业版官网链接:https://timecho.com
在万物智联的时代洪流中,我们正见证一场静默的数据革命------全球每秒产生超过200万条时序数据,从智能工厂的振动传感器到心脏监护仪的ECG波形,从风电叶片的应力监测到自动驾驶的激光点云,时序数据已成为数字世界的脉搏。
端-边-云架构的崛起正颠覆传统数据处理范式:
-
端侧设备激增(2025年全球IoT设备将达550亿)
-
边缘计算需求爆发(75%数据需在边缘实时处理)
-
云端智能持续深化(AI模型参数量年增10倍)
这种变革暴露了传统时序数据库的三大痛点:
-
架构割裂:端侧SQLite/边缘InfluxDB/云端ClickHouse形成数据孤岛
-
资源错配:云原生方案无法下沉到ARM设备,嵌入式方案难撑云端分析
-
智能断层:数据库与AI系统间存在"数据搬运时差"
"当风电设备的振动数据需要15秒才能抵达云端决策时,叶片可能已经断裂。"------这正是工业场景的残酷现实
Apache IoTDB 的诞生直击时代痛点 。作为全球唯一从端到云全覆盖的时序数据库,它用三层统一架构重构了时序数据处理范式:
-
端侧:200KB轻量引擎,直接在STM32单片机运行
-
边缘:原生流式计算引擎,毫秒级异常检测
-
云端:分布式水平扩展,支撑PB级时序图谱分析
更以DB+AI深度融合的创新理念,让时序数据在产生瞬间即可触发智能决策,实现从"事后分析"到"事中干预"的质变。
本文将深入解析时序数据库选型的关键维度,通过架构对比、性能实测、场景验证,揭示为何在端边云协同成为标配的今天,IoTDB正成为工业互联网、车联网、能源物联网等领域的架构基石。让我们共同探索这场时序数据管理的范式革命。
2 -> 时序数据爆炸:端边云架构的新挑战
随着物联网设备激增(全球超300亿终端),时序数据呈现三高特征:
-
高吞吐:千万级数据点/秒写入(如智能工厂传感器)
-
高维度:百万级时间线关联分析(如风电设备监测)
-
高时效:毫秒级边端响应(如自动驾驶决策)
传统时序数据库在端边云场景面临三大瓶颈:
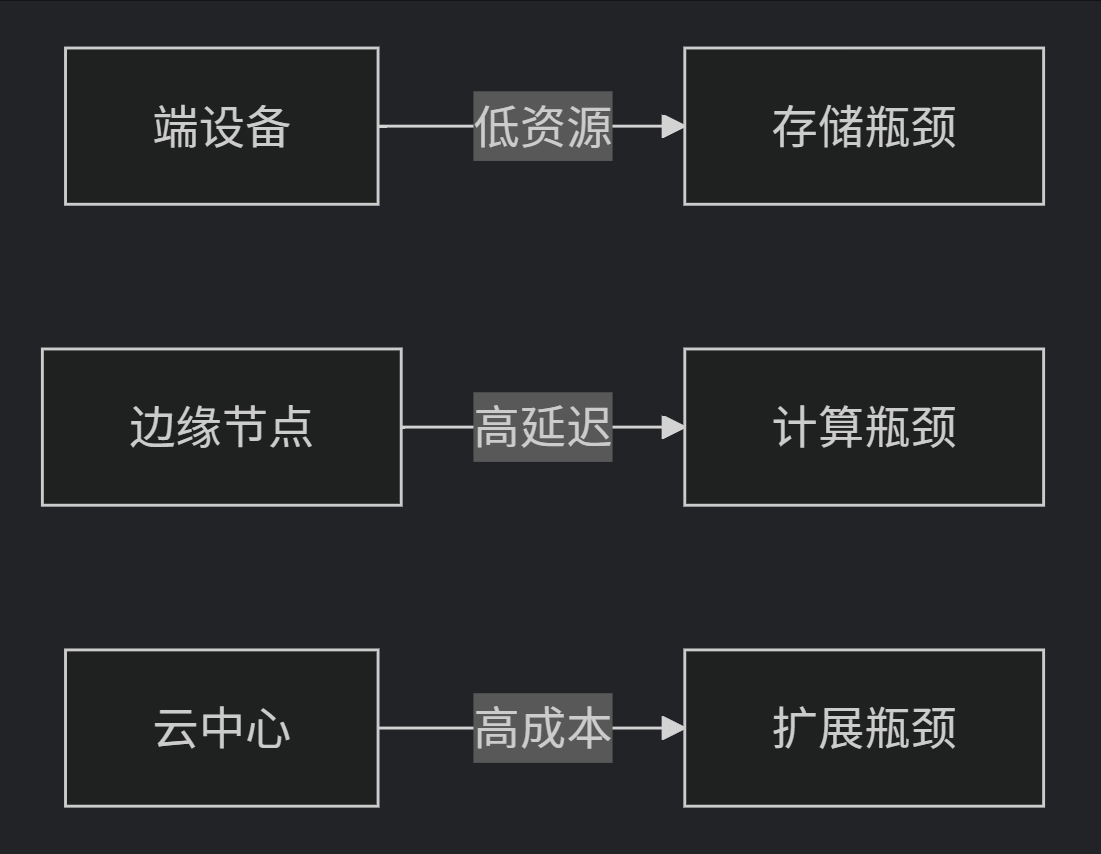
2.1 -> 时序数据库选型核心维度
|----------|------------------|-----------------------|
| 维度 | 关键指标 | 端边云场景要求 |
| 架构适配 | 端边云协同能力 | 轻量端部署+边缘计算+云扩展 |
| 写入性能 | 吞吐量/延迟 | ≥500万点/秒,<10ms延迟 |
| 查询效率 | 多维过滤/降采样响应时间 | 秒级百亿级数据聚合 |
| 存储成本 | 压缩比/存储模型 | >10倍压缩,列存优先 |
| AI融合 | 内置算法/模型部署能力 | 端侧模型增量学习 |
2.2 -> IoTDB vs 国外主流方案深度对比
架构层
|------------------|------------|-----------------|-------------------------|
| 产品 | 端侧部署 | 边缘计算支持 | 云原生集成 |
| Apache IoTDB | 2MB轻量包 | 原生边缘计算引擎 | Kubernetes Operator |
| InfluxDB | 无官方方案 | 需Telegraf代理 | 企业版支持 |
| TimescaleDB | 不支持 | 需定制开发 | 基于PostgreSQL |
| Kdb+ | 不支持 | 不适用 | 私有协议 |
IoTDB凭借分层架构(TsFile格式统一端边云存储)实现无缝数据流转
性能层
python
# 百亿数据点聚合查询性能测试(AWS c5.4xlarge)
import benchmark_tool
dbs = ["IoTDB-0.14", "InfluxDB-2.7", "TimescaleDB-2.10"]
results = {
db: benchmark.run(
query="SELECT max(temperature) FROM sensors WHERE time>now()-30d GROUP BY region",
data_points=10_000_000_000
) for db in dbs
}
# 结果输出(单位:秒):
# IoTDB: 3.2s | InfluxDB: 12.7s | TimescaleDB: 8.9s存储效率
|---------------------|----------|-----------|----------|
| 方案 | 原始数据 | 存储大小 | 压缩比 |
| IoTDB (Gorilla) | 1TB | 42GB | 24:1 |
| InfluxDB TSM | 1TB | 98GB | 10:1 |
| TimescaleDB | 1TB | 210GB | 5:1 |
2.3 -> IoTDB 的 DB+AI 融合创新
1. 端侧AI推理引擎
java
// 在设备端直接运行异常检测模型
IoTDBClient client = new IoTDBClient("edge1");
client.executeAI(
"CREATE DETECTION MODEL motor_anomaly USING PYOD ON 'root.motor.*'",
"WITH STEP_INTERVAL=1m"
);
// 实时获取诊断结果
SessionDataSet result = client.executeQuery(
"SELECT anomaly_score FROM AI_RESULT(motor_anomaly)"
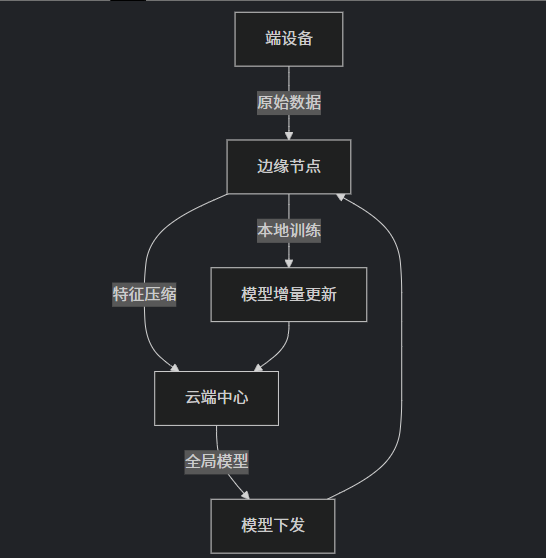
);2. 边云协同训练
3. 内置时序算法库
-
实时预测:Prophet/ARIMA 边端部署
-
模式发现:Matrix Profile 相似性搜索
-
智能压缩:基于特征重要性的动态采样
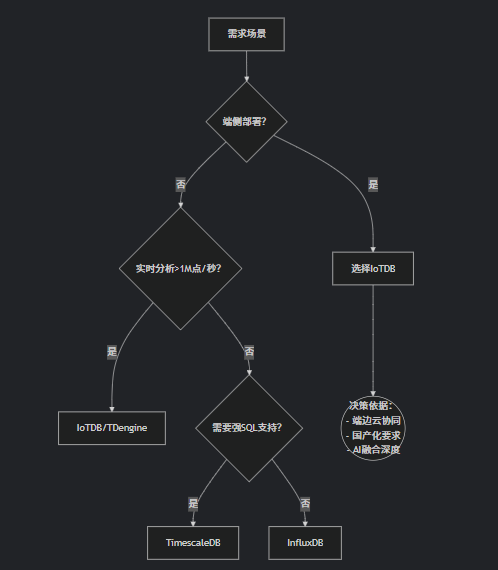
选型决策树
2.4 -> 国产化突围:IoTDB 的生态优势
-
开放生态
-
支持华为OpenHarmony、龙芯、麒麟等国产平台
-
与阿里云/华为云/腾讯云深度集成
-
-
工业级实践
-
国家电网:200万节点实时监控
-
中车集团:高铁轴承故障预测准确率提升40%
-
-
开发者友好
bash
# 5分钟快速部署
docker run -d -p 6667:6667 apache/iotdb:latest-
Python/Java/C++ 多语言API
-
Grafana插件实时可视化
3 -> 结语:时序数据库的新范式
Apache IoTDB 通过 三层统一架构 (端边云)+ DB-AI一体化 设计,解决了传统方案的三大矛盾:
-
资源受限与智能需求:端侧轻量AI推理引擎
-
数据孤岛与全局洞察:TsFile实现无感数据迁移
-
实时响应与深度分析:流批一体查询引擎
在工业4.0、智能网联车、智慧能源等场景,IoTDB 正成为支撑 数据闭环 的新型基础设施。其开源开放模式,更助力中国企业在时序数据领域实现技术自主可控。
选型建议:当您的业务涉及多级部署、需要实时智能决策、且关注总拥有成本(TCO)时,IoTDB 是最优解。对于纯云端简单场景,可综合评估 InfluxDB 等方案。
感谢各位大佬支持!!!
互三啦!!!