前言
在智能应用的浪潮中,语言模型(LLM)不再只是文本生成器,而是具备调用外部工具、检索数据、搜索互联网信息、甚至记忆上下文的"智能体"(Agent)。借助 LangChain 框架,我们可以轻松地创建一个能与多种不同工具交互的 Agent,让它具备信息检索、搜索和多轮对话记忆的能力。
本文将深入解析如何:
- 使用语言模型的 工具调用能力;
- 创建并封装 本地数据库检索器(Retriever);
- 集成 在线搜索工具;
- 构建一个可 多轮对话记忆 的智能 Agent;
- 通过示例代码展示从初始化到运行的完整过程。
1. Agent 系统架构概览
整个 Agent 系统由四个核心组件构成:
| 层级 | 模块 | 功能说明 |
|---|---|---|
| 检索层 | Retriever | 从本地索引或文档源检索相关信息 |
| 工具层 | Tool | 将检索器、本地数据库和搜索引擎封装成可供 LLM 调用的函数接口 |
| Agent 层 | Planner / Agent | 驱动 LLM,根据上下文和需求动态选择工具并整合结果 |
| 记忆层 | Memory | 按 user_id 存储对话历史,使 Agent 能进行多轮上下文对话 |
下图展示了整体流程:
User Query → Agent (LLM) → Tool 调用决策
↓ ↓
Memory ← 结果 ← Retriever / Web Search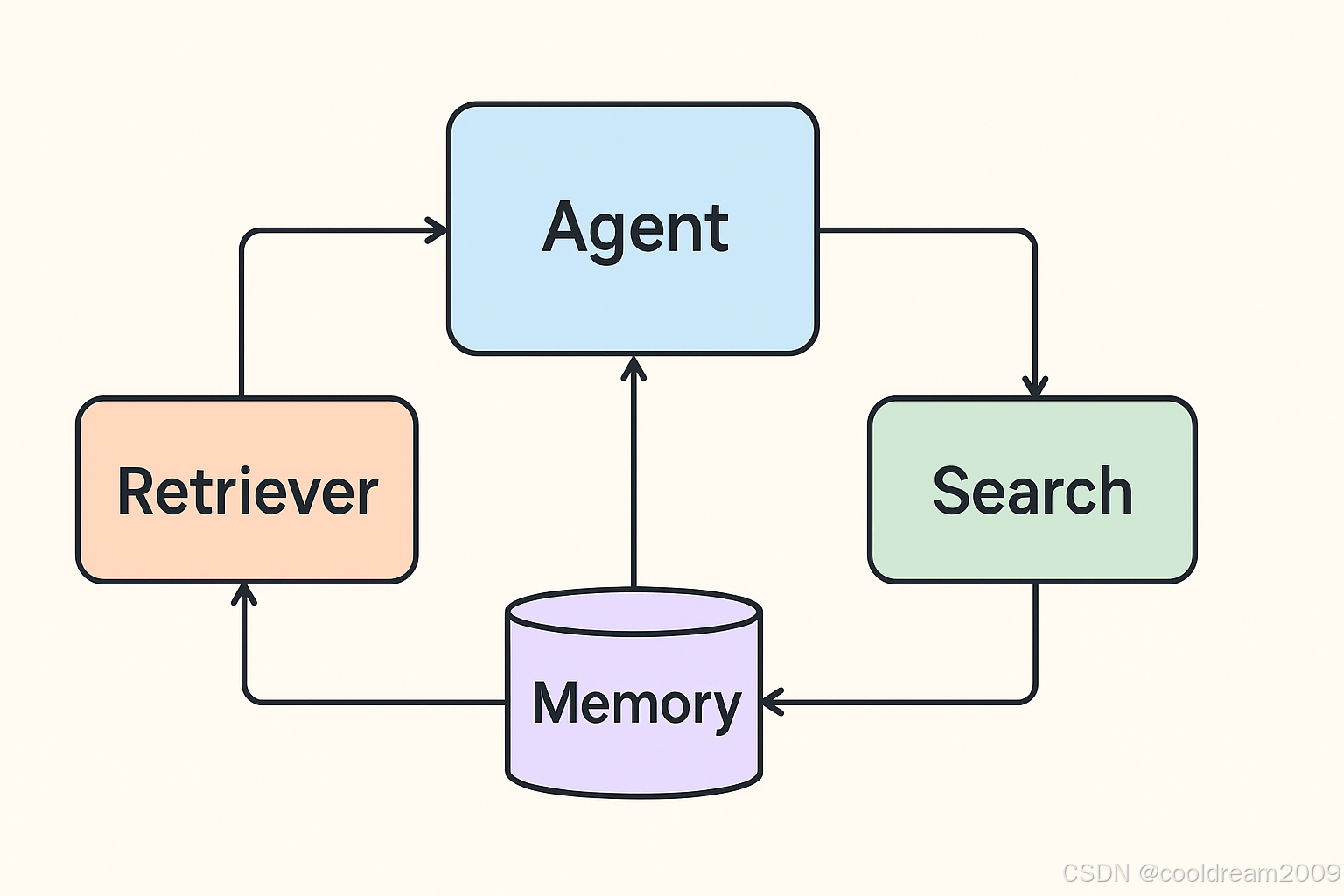
2. 环境准备与依赖版本
| 组件 | 推荐版本 |
|---|---|
| Python | ≥ 3.10 |
| langchain | 0.1xx |
| openai | ≥ 0.27.0 |
| 向量数据库 | faiss-cpu 或 chromadb |
| 其他依赖 | tiktoken、requests |
确保在环境变量中配置好 OPENAI_API_KEY,并安装上述库:
bash
pip install langchain openai faiss-cpu tiktoken requests3. 构建 Retriever:从 URL 到索引
我们首先从一个网页抓取内容,将其拆分、向量化,并建立索引,最终形成一个可检索的 Retriever。
python
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import UnstructuredURLLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
1. 加载网页内容
urls = ["https://example.com/some-article.html"]
loader = UnstructuredURLLoader(urls=urls)
docs = loader.load()
2. 拆分文档块
splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
doc_chunks = splitter.split_documents(docs)
3. 生成向量索引
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(doc_chunks, embeddings)
4. 创建检索器
retriever = vectorstore.as_retriever(search_kwargs={"k": 4})通过这种方式,我们获得了一个本地知识库的检索接口。
4. 封装工具:让 LLM 能调用 Retriever 与搜索引擎
4.1 本地检索工具
python
def local_retriever_tool(query: str) -> str:
docs = retriever.get_relevant_documents(query)
return "\n---\n".join([d.page_content for d in docs])
from langchain.tools import Tool
local_retriever = Tool(
name="local_retriever",
func=local_retriever_tool,
description="从本地索引中检索与查询相关的文档片段。"
)4.2 在线搜索工具
示例中我们使用 SerpAPI(你也可以换成 Bing 或 Google Custom Search):
python
import requests
SERPAPI_KEY = os.environ.get('SERPAPI_KEY')
def serp_search_tool(query: str) -> str:
params = {'engine': 'google', 'q': query, 'api_key': SERPAPI_KEY}
resp = requests.get('https://serpapi.com/search', params=params)
data = resp.json()
snippets = []
for r in data.get('organic_results', [])[:5]:
snippets.append(f"{r.get('title')} - {r.get('snippet', '')} ({r.get('link')})")
return "\n".join(snippets)
search_tool = Tool(
name="web_search",
func=serp_search_tool,
description="使用在线搜索引擎检索最新的信息,返回摘要和链接。"
)5. 创建并运行 Agent
现在我们把所有组件整合起来,构建可交互的智能 Agent。
python
from langchain import OpenAI
from langchain.agents import initialize_agent, AgentType
from langchain.memory import ConversationBufferMemory
llm = OpenAI(temperature=0)
tools = [local_retriever, search_tool]
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
memory=memory
)
question = "请基于本地索引中的资料,说明 example.com 上关于 X 的关键观点;如果没有,在线搜索最新资料。"
result = agent.run(question)
print(result)运行后,你会看到 Agent 自动决定调用哪个工具(本地或网络),并整合结果生成自然语言回答。
6. 多用户对话记忆机制
为不同用户维护独立的上下文,可以让 Agent 记住每个用户的历史对话:
python
from collections import defaultdict
from langchain.memory import ConversationBufferMemory
user_memories = defaultdict(lambda: ConversationBufferMemory(memory_key="chat_history", return_messages=True))
user_id = "user_123"
memory = user_memories[user_id]
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, memory=memory)
agent.run("上次我们关于 X 的讨论,请继续。")在生产系统中,你可以把 memory 存储在 Redis、Postgres 等外部数据库中,并定期做摘要压缩,避免上下文过长。
7. 实践建议
- 限制工具输出长度:对检索内容先摘要,避免 token 超限。
- 安全沙箱:对搜索结果做可信度检查,防止注入恶意内容。
- 函数调用模式:可结合 OpenAI 的 Function Calling,把工具注册为可调用函数。
- 缓存与并发控制:对频繁调用的外部工具结果进行缓存,设置超时重试。
- 日志与解释性:保存 Agent 调用链路以便调试与审计。
8. 总结
本文完整展示了如何利用 LangChain 构建一个能与本地数据库和搜索引擎交互的智能 Agent。通过整合 Retriever、Tool、Memory 模块,Agent 能够根据用户需求自动选择合适的信息源,执行多轮对话,并保持记忆。
未来,你可以进一步拓展:
- 使用
ChatOpenAI与 Function Calling 构建更智能的决策代理; - 将索引替换为 Chroma 或 Milvus 实现分布式知识库;
- 接入网页、PDF、数据库等多种数据源,实现真正的知识增强型 AI 助手。
这就是一个具备检索、搜索与记忆能力的 LangChain 多工具智能体的全貌。