技术干货|Kafka 如何实现零停机迁移
文章导读
随着越来越多企业将 Kafka 迁移至云原生架构,AutoMQ 正逐渐成为 Kafka 用户的云端优选。💡 作为兼容 Apache Kafka 协议、专为云设计的新一代发行版,AutoMQ 具备高性能、弹性扩展和更优成本,广泛应用于云上实时数据平台。AutoMQ 目前已在 GitHub 开源,Star 数已达 6.9k,受到全球开发者关注。
但从传统 Kafka 平滑迁移至 AutoMQ,依旧面临业务不中断、数据完整性和偏移量一致性的挑战。传统方案多依赖停机或复杂切换,难以满足高可用需求。
Kafka Linking 是 AutoMQ 针对这些挑战推出的创新方案,支持 Kafka 与 AutoMQ 集群双向写入及精准消费位点同步,通过滚动迁移实现业务与迁移解耦,真正做到"零停机"上线。
本文提供了一种基于 Kafka Linking 的全新迁移思路,涵盖核心原理、架构设计及关键机制,并对比 MirrorMaker 2。无论是否考虑迁移,均值得一读,为 Kafka 架构演进提供参考。
注意:内容原始内容为英文,如需追求最原汁原味和准确的阅读体验,请直接点击底部 查看原文 阅读原始英文素材。
引言
在当今这个数据驱动的时代,Apache Kafka 已成为企业数据基础设施中不可或缺的核心组件。无论是处理金融交易、物联网数据,还是驱动用户行为追踪与微服务通信,Kafka 都是众多组织的首选方案。
然而,随着企业规模扩大、基础设施升级或优化成本的需要,迁移 Kafka 集群的需求也随之产生。这类迁移可能包括从本地部署迁移至云托管服务、在不同云厂商之间切换、升级至更高版本的 Kafka,或者替换为一种更高效的新一代 Kafka 方案。
这类迁移面临一系列独特挑战,因此亟需一个可靠的 Kafka 迁移方案来应对。问题的核心在于 Kafka 本身作为企业数据"中枢神经系统"的角色------任何中断都可能引发连锁反应,影响业务连续性。
本文将先回顾当前 Kafka 迁移工具的常规方式,并进一步介绍 AutoMQ 提出的一种全新方案,该方案可确保 Kafka 迁移过程实现真正意义上的零停机。
想了解更多 AutoMQ 的技术细节,可以阅读我之前的文章
为什么会出现停机时间?
传统的 Kafka 集群同步工具(如 Kafka 自带的 MirrorMaker 2)主要聚焦于将数据复制到一个独立的目标集群。为了确保在迁移过程中不丢数据、不发生乱序,通常要求 Producer 停止发送新数据,并等待所有剩余数据完整落地于新集群。只有在这些数据"稳定"后,Producer 才能正式接入新集群恢复写入操作。而在此期间,Consumer 也将处于"无数据可读"的状态,完全依赖 Producer 的同步进度。
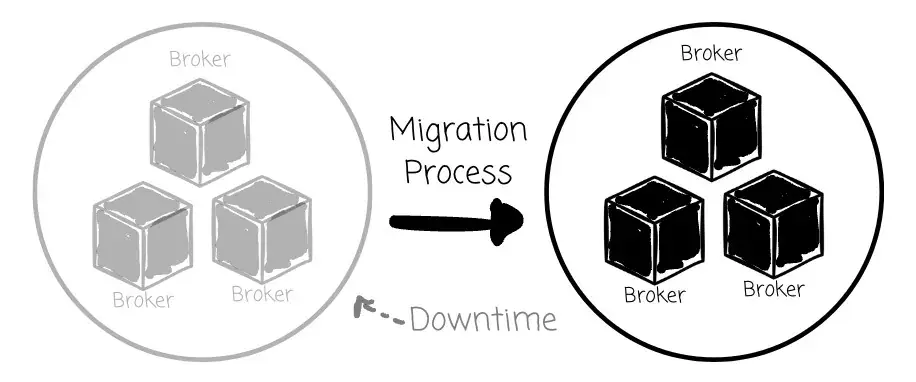
这种方式带来的最直接影响就是:所有依赖该 Kafka 集群的应用将遭遇停机。在迁移过程中,Producer 停止发送数据,Consumer 也就无数据可读。此外,这个"等待"过程本身具有高度不确定性,受数据量、网络延迟、同步工具的处理能力等因素影响,难以准确控制。
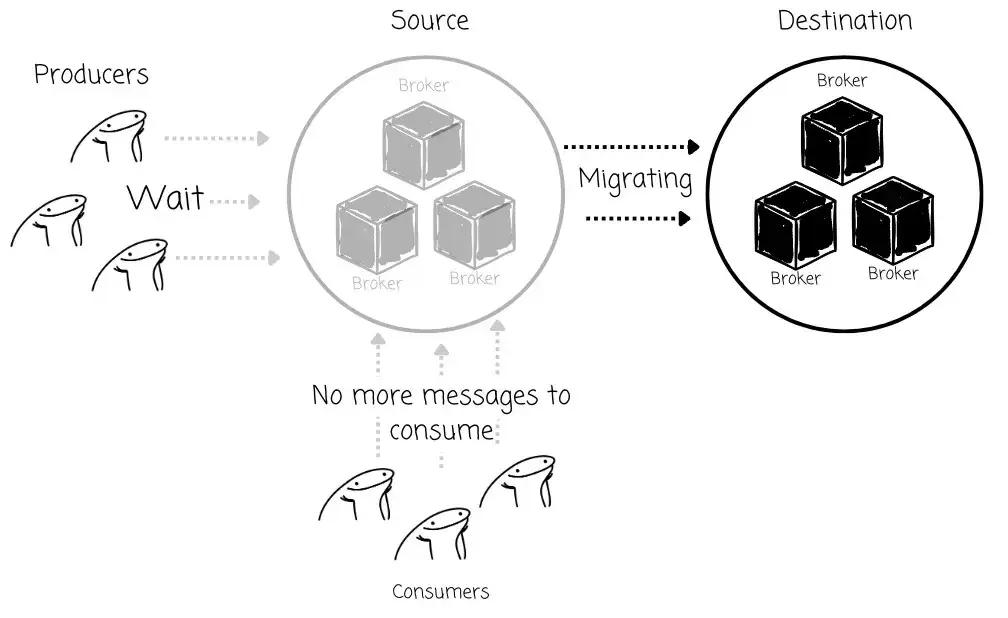
同时,这一迁移流程还会引入大量的运维复杂性与人工操作成本。团队不仅需要协调多个应用实例的启动与停止,还必须跨团队配合,并经常手动验证数据一致性,才能最终"放行"进入新集群。这大大增加了人为错误的风险,延长了维护窗口时间。
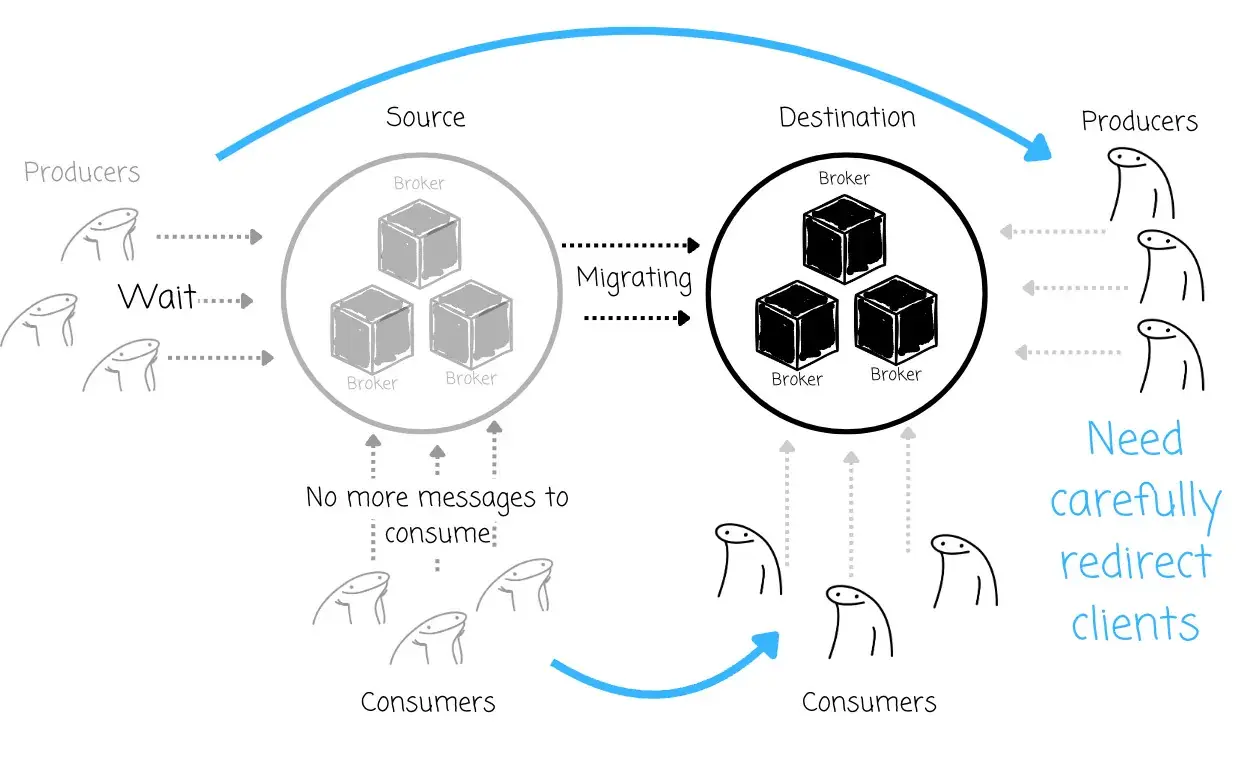
更糟糕的是,Kafka 本身缺乏原生的 Client 重定向机制,这进一步提升了迁移的复杂度和出错概率。对于包含大量服务的大规模 Kafka 集群而言,这种方式的风险尤其高。
此外,广泛使用的 MirrorMaker 2 并不能有效保留 Message Offset 1。因为它依赖的是一种不精确的 Offset 映射机制,而非直接复制。该映射机制并不会为每条数据建立完整对应关系,这可能导致 Consumer 迁移后出现重复消费或数据重处理的问题。
而对于像 Flink 或 Spark 这类在外部独立管理 Offset 的应用,MirrorMaker 2 的 Offset 映射机制更是完全失效,因此难以支持这类应用的无缝迁移。
也就是说,像 MirrorMaker 这样的方案,并不能在所有使用场景中保证 Kafka 集群的安全迁移。
那么,有没有一种方法能够真正解决上述所有问题呢?
01 AutoMQ Kafka Linking
AutoMQ 提出了 Kafka Linking,用于实现从 Apache Kafka 到 AutoMQ 的集群迁移。这是业界首个在迁移过程中同时保证 零停机 与 数据 Offset 保留 的解决方案。Kafka Linking 方案基于两个核心设计原则构建:双写(Dual Write)机制 与 滚动升级(Rolling Upgrade)策略。
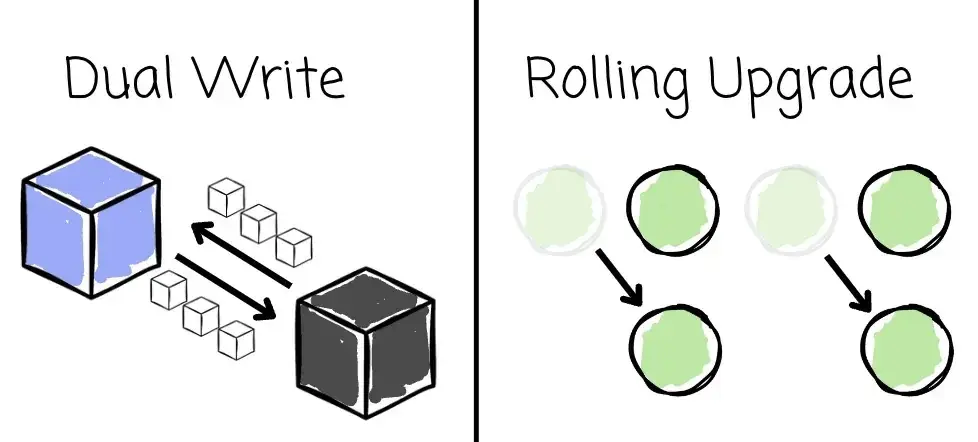
其目标是确保整个迁移过程稳定可靠,并支持 Client 无感知重定向,从而实现真正意义上的零停机迁移。
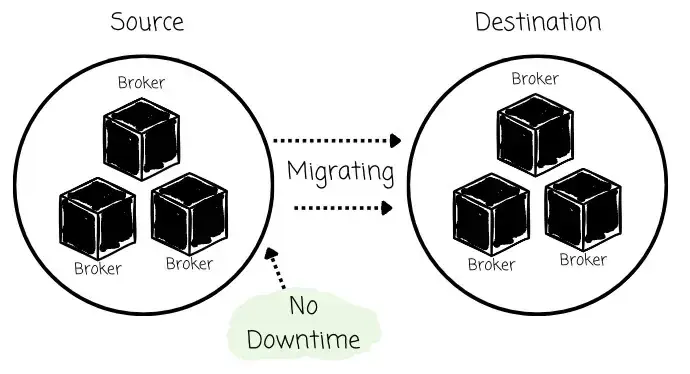
目前该方案只支持从 Kafka 迁移到 AutoMQ,我个人也十分期待未来支持 Kafka → Kafka 的迁移能力。
02 双写机制(Dual Write)
确保 Kafka 集群与 Client 在迁移过程中持续可用的关键在于"双写机制":
Kafka 中写入的数据会同步到 AutoMQ,反之,AutoMQ 中写入的数据也会同步回 Kafka。这种双向同步机制允许管理员在遇到问题时安全回滚,避免数据丢失或业务中断。
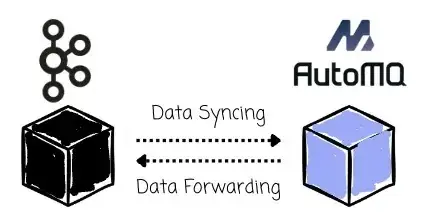
在 Kafka Linking 方案中,负责迁移流程的是 AutoMQ 中的 Partition Leader。它们一方面会作为 Consumer,从 Kafka 的 Partition Leader 中拉取数据;另一方面又作为 Producer,将数据回写到 Kafka 的 Partition Leader,实现双写。
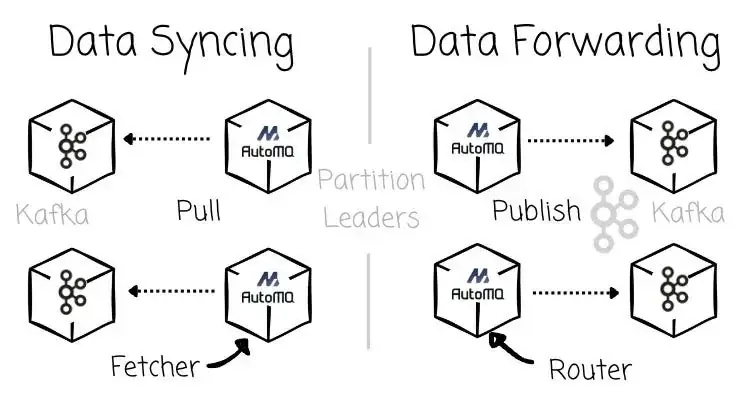
根据职责不同,这些 Partition Leader 拥有不同角色名称:
-
Kafka → AutoMQ 同步:Fetcher,即 AutoMQ 的 Partition Leader,作为 Consumer,从 Kafka 中拉取数据;
-
AutoMQ → Kafka 回写:Router,即 AutoMQ 的 Partition Leader,作为 Producer,将数据发布到 Kafka。
03 Kafka → AutoMQ
在开始迁移前,Kafka Linking 需要用户提供源 Kafka 集群的配置信息、待迁移的 Topic 列表、以及初始同步的起点(例如是否全量迁移历史数据、仅同步新增数据,或从某个指定时间点开始)。
AutoMQ 会根据这些信息,在自身集群中预创建相应的 Topic 与 Partition。
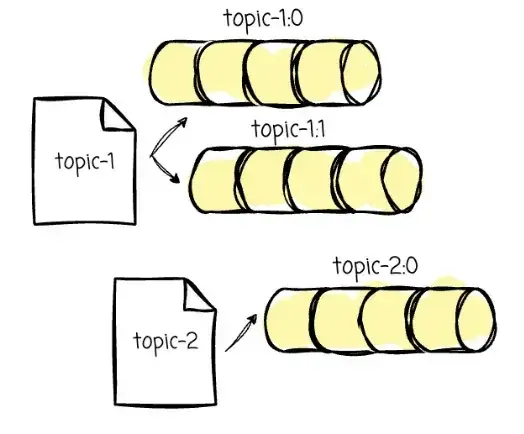
假设我们有两个需要迁移的 Kafka Topic:
-
topic-1:包含两个 Partition(topic-1:0, topic-1:1)
-
topic-2:包含一个 Partition(topic-2:0)
Kafka Linking 会持续监控 Kafka 集群的状态,尤其是 Partition Leader 的变化,以确保 AutoMQ 总是与最新的 Leader 建立连接进行数据迁移。一旦 Kafka 集群中某个 Partition 的 Leader 发生变化,Kafka Linking 会立刻捕捉到这一事件,并将对应 Partition 加入 "预处理队列(Pre-processing Queue)"。
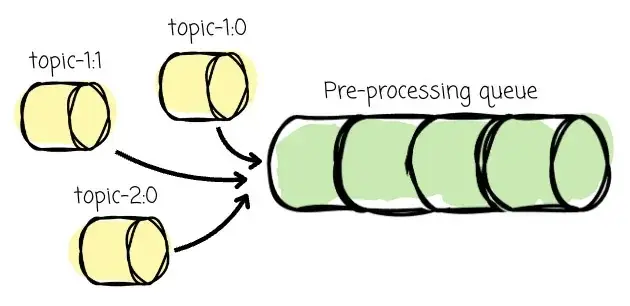
在初始化阶段,Kafka Linking 会将 topic-1:0、topic-1:1、topic-2:0 加入队列,随后在后台异步预处理这些 Partition。每个 Partition 会经历以下处理流程:
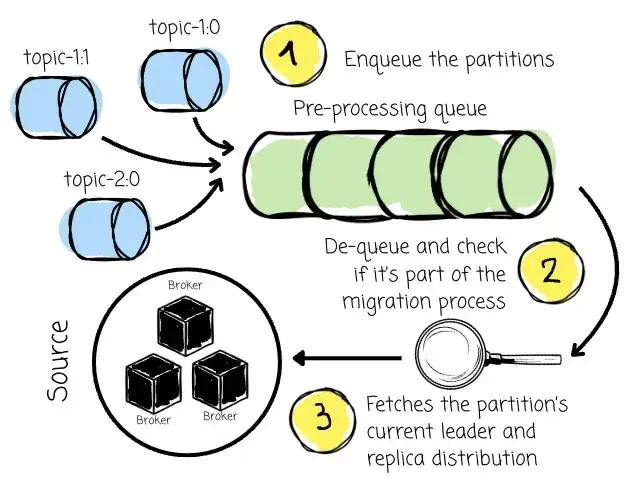
-
检查其元数据,确认是否属于迁移任务,是否需要从 Kafka → AutoMQ 同步;
-
建立与 Kafka 集群的连接,获取 Partition 当前的 Leader 及 Replica 分布,以避免跨可用区(AZ)拉取数据造成的成本与延迟;
接下来,AutoMQ 中的 Partition Leader(即 Fetcher)会从对应的 Kafka Partition Leader 开始拉取数据。Fetcher 优先选择位于同一机架(Rack)上的节点进行数据拉取以提高效率。
Fetcher 执行如下操作:
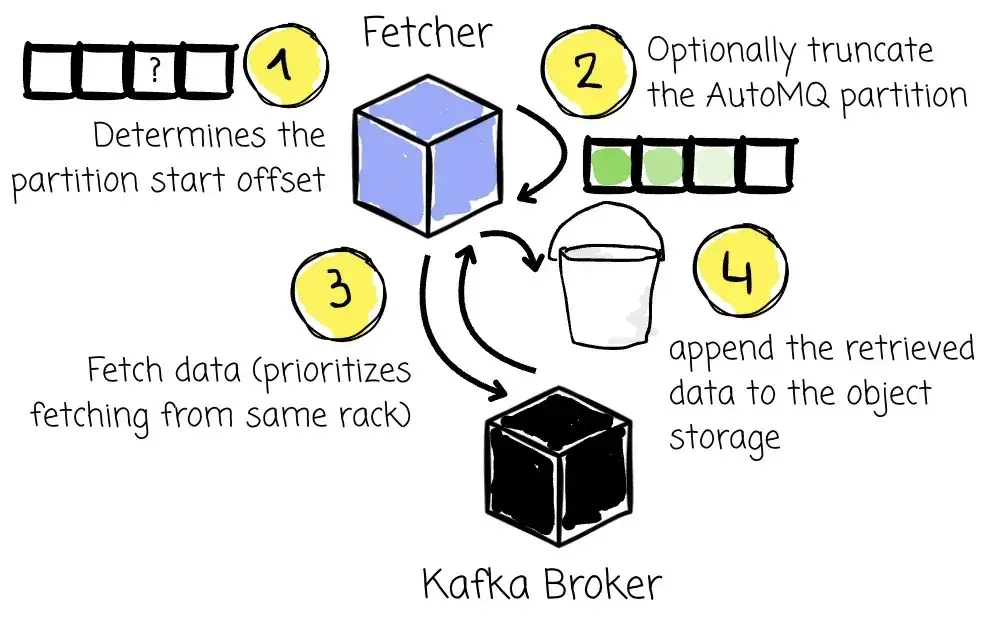
-
确定数据复制的起始 Offset:如果用户选择 earliest,则从最早的 Message Offset 开始;如果选择 latest,则从当前最后一条数据开始;如果指定时间戳,则获取对应时间点的 Offset;
-
若该 Partition 首次在 AutoMQ 中创建,且用户选择的是 latest 或 timestamp,Fetcher 可能会对 AutoMQ 中的 Partition 进行内部 "截断",以保证其起点与 Kafka 保持一致;
-
Fetcher 持续为该 Partition 构建拉取请求,并向源 Kafka 的对应 Partition Leader 发送;
-
与常规 Consumer 一样,Fetcher 会按增量拉取,仅请求上次成功同步后的新增数据;
-
当 Fetcher 从源 Kafka 收到响应后,会将数据追加写入 Object Storage;若响应失败,则根据错误类型重试或重新定位 Leader;
-
一旦某 Partition 的数据成功追加至 AutoMQ,Fetcher 会确保下次拉取从上次结束处继续,保证 不丢数据、不重复写入。
这一过程会不断循环,直至同步完成。
04 AutoMQ → Kafka
如前所述,正是这种双写机制,使 Kafka Linking 能够在整个迁移过程中保持 Client 正常运行的同时,可靠地完成迁移任务。
Kafka Linking 不仅支持从 Kafka → AutoMQ 的数据同步,也支持将 AutoMQ 中的数据回传至 Kafka。
- 当 Producer 仍全部写入 Kafka 时,仅需执行单向同步,即 Kafka → AutoMQ。
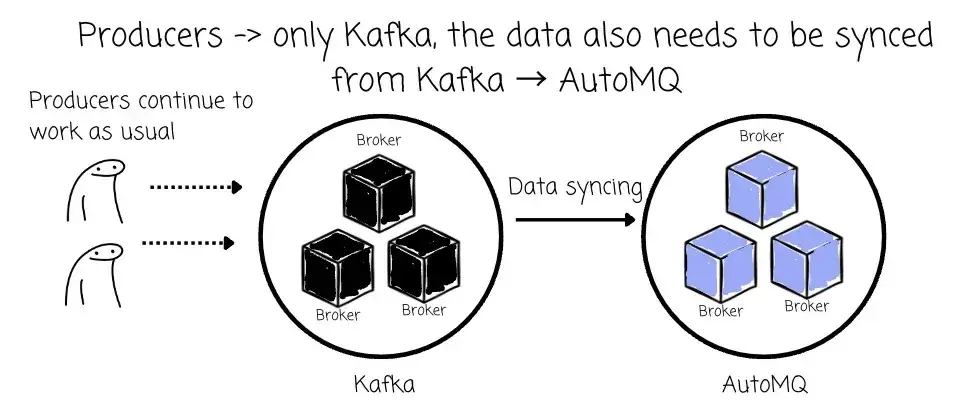
- 进入滚动升级阶段后(下文将详细介绍),部分 Producer 开始向 AutoMQ 写入数据,仍有部分 Producer 保持写入 Kafka。此时,AutoMQ 中的数据也需实时转发回 Kafka,实现双向写入。
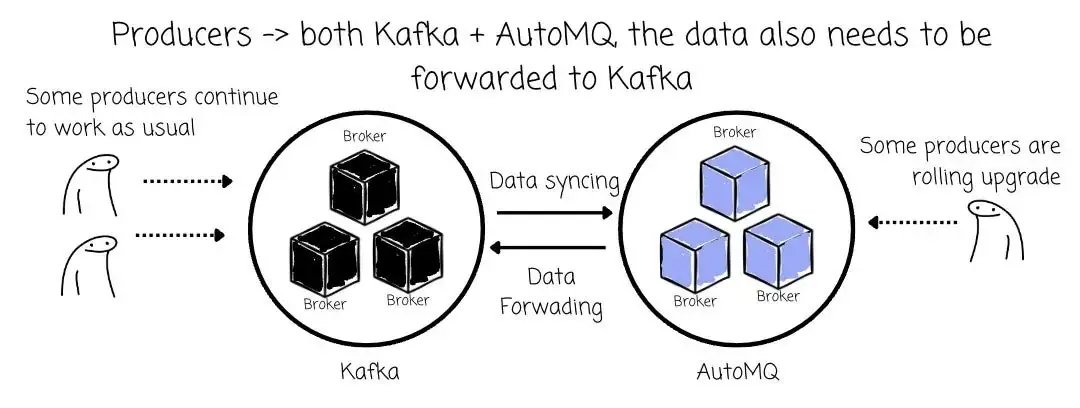
在这一过程中,由 AutoMQ 中的 Partition Leader(在此角色为 Router)负责将数据从 AutoMQ 转发回 Kafka。
具体机制如下:
!Image(cdnLink: image.automq.com/20250811bot...)
-
Router 首先将接收到的数据映射至内存中的 Message Map,以实现高效处理,并最关键地,确保数据顺序不被打乱;
-
该 Map 的 Key 是 Partition,Value 是一个数据池(Message Pool),其中包含所有待发送回 Kafka 的数据;
-
在每个 Partition 的数据池中,数据会按原始 Producer 进一步分组;
-
Kafka 保证 "每个 Partition 下,Producer 级别的 FIFO(先进先出)顺序";因此,Router 会在转发时严格按照各个 Producer 的原始顺序写回 Kafka;
-
Router 同时也识别出这些数据通常已被原始 Kafka Producer 打包成批,因此避免对同一 Partition 进行不必要的二次聚合;
-
当准备构建 Kafka 的发送请求时,Router 会从相关 Partition 的数据池中选取一个或多个完整批次;
-
请求构建完成后,Router 会立即将数据发送至 Kafka,并并行构建下一个请求;
-
来自不同 Producer 的批次可并发发送,以提升吞吐;
-
同一 Producer 的批次则必须顺序发送,以确保顺序一致性。
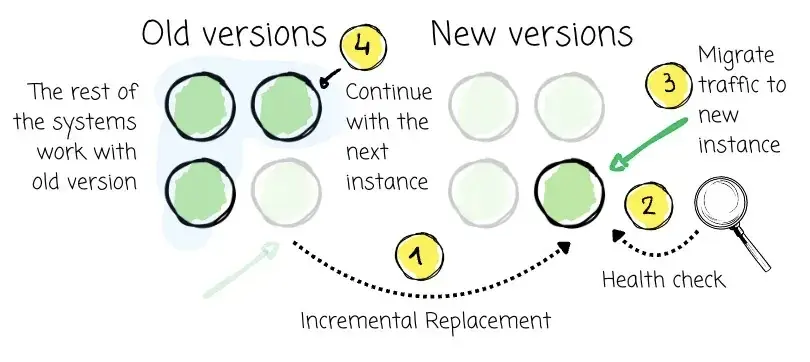
05 滚动升级(Rolling Upgrade)
滚动升级 是一种常用的应用部署策略,用于以最小的风险将系统逐步更新至新版本,并确保业务不中断。它的基本步骤如下:
-
增量替换:一次仅升级系统的一小部分节点或单个实例;
-
保持服务可用性:升级过程中,其余大部分系统仍继续运行旧版本,处理业务流量;
-
健康检查与验证:每个新版本实例部署后需通过健康检查,确保其正常运行后才可接收流量;
-
流量渐进切换:新实例验证通过后,逐步将流量导向其上,旧实例再被移除或升级;
-
迭代执行:重复以上过程,直到所有实例完成升级;
-
可回滚性:一旦某个批次出问题,可快速回滚到稳定版本,降低影响范围。
AutoMQ 将这一滚动升级理念应用于 Kafka Linking 的集群迁移过程,目标是在 Client 无感知迁移 的同时,实现真正的 零停机切换。
Producer 迁移
在传统的迁移方式中,管理员通常需要先停止所有 Producer,等待数据同步完成后,再将 Producer 统一指向新集群并重启。这会导致服务不可用。
而借助 Kafka Linking,可以对 Producer 实施 分批滚动迁移: 一次只将部分 Producer 指向目标 AutoMQ 集群,其余 Producer 仍继续向原 Kafka 集群写入数据。
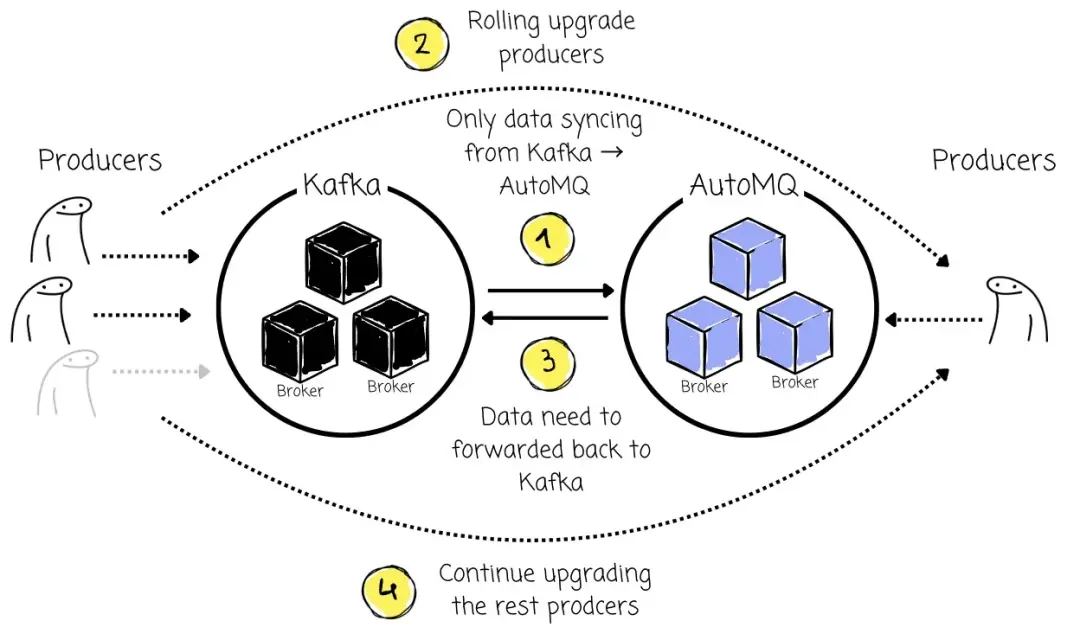
对于已迁移到 AutoMQ 的 Producer,其发送的所有数据会立即回传至源 Kafka 集群,确保即使发生问题,也能安全回滚至旧集群。
因此,Producer 始终保持在"可发送状态",无论写入 AutoMQ 还是 Kafka,最终都能被消费者从 Kafka 中读到。此阶段中,所有 Consumer 依旧连接 Kafka 集群,从中消费所有数据。
这样,Kafka 源集群在整个 Producer 迁移阶段,始终作为数据消费的 单一可信来源(Single Source of Truth),迁移过程完全无缝。
Consumer 迁移
Consumer 的迁移过程与 Producer 类似,用户可以按实例或批次对 Consumer 应用执行滚动升级,将其逐步指向 AutoMQ 集群。
关键在于:当某个 Consumer 实例首次连接至 AutoMQ 集群时,AutoMQ 会主动禁用该 Consumer 的读取能力,以避免出现重复消费。 如果在 Consumer Group 还未全部迁移完的情况下,允许一部分 Consumer 在 AutoMQ 读数据,而另一部分还在 Kafka 读数据,就可能导致同一条数据被消费多次。
因此,AutoMQ 会持续检测 Consumer Group 的状态,直到确认该组所有 Consumer 已断开与源 Kafka 集群的连接后,Kafka Linking 才会从源 Kafka 集群同步该 Consumer Group 的 Offset。这样,连接至 AutoMQ 的 Consumer 就可以从完全正确的位置继续消费,无需担心丢数据或重复数据。
Offset 同步完成后,Kafka Linking 会正式开启该 Consumer Group 在 AutoMQ 上的读取权限。此后,这些 Consumer 就可以在 AutoMQ 集群中无缝继续消费。
上述整个过程由 AutoMQ 的控制面统一管理。它能够自动监测 Consumer Group 状态,并在合适的时机自动完成 Offset 同步与切换,让整个迁移流程对用户来说"开箱即用"。
Topic 迁移
当某个 Topic(如 topic-a)对应的 Producer 和 Consumer 全部完成滚动升级,并成功切换到 AutoMQ 后,用户可手动对该 Topic 执行"升格操作(Promote)",切换其主集群角色。
具体步骤包括:
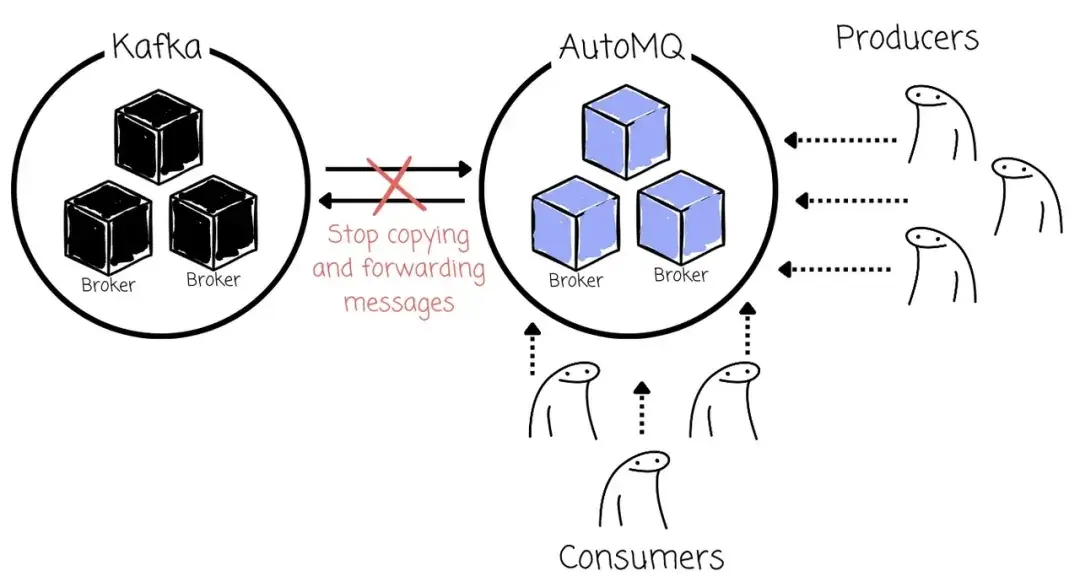
-
AutoMQ 停止从源 Kafka 集群同步该 Topic 的数据;
-
AutoMQ 停止将该 Topic 的新数据回写至源集群;
-
AutoMQ 集群正式成为该 Topic 的主集群,独立承担读写操作,不再依赖原 Kafka 集群。
对于其它 Topic,用户也可采用相同的滚动迁移方式分批执行,确保整个 Kafka 集群迁移过程平滑、可控,并实现真正的 零停机切换。
结语
感谢你读到这里。
本文回顾了传统 Kafka 迁移工具的典型实现方式,指出了它们可能带来的数据停机与运维复杂度问题。随后,我们深入介绍了 AutoMQ 的 Kafka Linking 方案,它不仅保证了迁移过程的可靠性,还能让相关应用在整个过程中保持完全在线、零停机。
💡 AutoMQ Kafka Linking 是 AutoMQ 的内置功能,无需引入额外组件或第三方系统即可实现 Kafka 集群的无中断迁移。结合共享存储架构,AutoMQ 可在提升系统弹性与运维效率的同时,显著降低整体 Kafka 成本。
💡 目前该方案已支持在 AWS Marketplace 一键部署,提供两周免费试用,企业可低成本验证效果。
🎉 立即开始免费试用 AutoMQ:
参考资料
1 Kafka Replication Without the (Offset) Gaps
2 AutoMQ, Beyond MirrorMaker 2: Kafka Migration with Zero-Downtime (2025)