Apache RocketMQ:分布式消息与流处理平台深度技术解读
1. 整体介绍
1.1 项目概况
Apache RocketMQ 是一个由阿里巴巴开源,后捐赠给Apache软件基金会的分布式消息中间件和流式计算平台。其项目地址为 github.com/apache/rock...。根据公开数据,该项目在GitHub上拥有超过2万个Star和1.1万个Fork(注:数据会动态变化),体现了其在开源社区中的广泛关注度和采纳率。
1.2 主要功能与技术架构
RocketMQ的核心定位是提供低延迟、高吞吐、高可靠、可弹性扩展的海量消息通信能力。其架构遵循典型的发布-订阅模型,主要由四个核心角色构成:Producer(生产者) 、Consumer(消费者) 、NameServer(名字服务) 和 Broker(代理服务器)。
一个简化的架构视图如下:
scss
[Producer Cluster] -> [NameServer Cluster] (路由发现)
| |
v v
[Broker Cluster] (Master/Slave) -> [Consumer Cluster]NameServer 作为轻量级的元数据管理和服务发现组件,无状态且节点间无通信,Broker会向所有NameServer定时注册和发送心跳。Broker 负责消息的存储、投递和查询,采用主从(Master-Slave)架构保证高可用。Producer和Consumer通过查询NameServer获取Topic的路由信息,然后与具体的Broker建立连接进行消息收发。
1.3 面临问题与目标场景
在分布式系统,特别是互联网、金融和物联网等领域,普遍面临以下核心问题:
- 应用解耦:模块间依赖过重,需要异步通信降低耦合度。
- 流量削峰:应对突发流量,避免后端服务被压垮。
- 数据分发:一份数据需要分发给多个下游系统进行处理。
- 事务最终一致性:在分布式环境下,保证跨系统的事务操作最终一致。
- 海量数据实时处理:对消息流进行实时计算和分析。
- 顺序保证:在特定场景(如证券交易)下,需要保证消息的处理顺序。
传统的解决方案,如使用数据库表模拟消息队列,或在早期消息队列(如ActiveMQ)中,常面临吞吐量低、堆积能力弱、顺序和事务支持不完善、无法水平扩展等问题。
1.4 RocketMQ的解决方案与优势
RocketMQ针对上述问题提供了系统性的解决方案:
- 以前的解决方式:自建基于数据库的队列,或采用早期设计较简单的消息中间件,在性能、可靠性和扩展性上存在瓶颈。
- 新方式的优点 :
- 高性能与低延迟:采用零拷贝、顺序写盘等技术,保障高吞吐与低延迟。
- 海量消息堆积:单队列支持百万级消息堆积,为业务峰值和消费延迟提供缓冲。
- 强顺序与事务消息:提供队列级别的严格顺序消息和金融级分布式事务消息支持。
- 可扩展性:无状态NameServer和可分片存储的Broker集群设计,支持水平扩展。
- 生态集成:原生支持与Flink、Spark等流批计算引擎集成,并提供多语言客户端。
1.5 商业价值预估
从商业价值角度评估,RocketMQ的核心价值在于显著降低企业构建高性能、高可靠分布式通信系统的综合成本。
- 代码/研发成本:作为成熟的开源解决方案,企业无需从零自研消息中间件,节省了数百万甚至数千万的研发人力和时间成本。
- 运维与风险成本:其经过大规模生产验证(如阿里巴巴双十一),内置高可用、监控、运维工具,降低了系统不稳定带来的业务风险和维护复杂度。
- 覆盖问题空间效益:它统一解决了从基础应用解耦、流量削峰到复杂的事务消息、实时流处理等多个场景的需求,避免了企业为不同场景引入多种中间件带来的技术栈碎片化和集成成本。其价值难以用单一数字衡量,但对于中大型互联网和数字化企业,采用RocketMQ通常意味着在消息通信领域获得了一个可靠、高效且成本可控的基础设施。
2. 详细功能拆解
2.1 核心消息通信能力
-
发布/订阅模型:基础能力,支持一对多的广播消息和集群消费。
-
顺序消息 :通过将需要保证顺序的消息哈希到同一个队列(
MessageQueue)中实现。RocketMQ保证同一个队列内消息的FIFO顺序。java// 伪代码:顺序消息发送示例 Message msg = new Message("OrderTopic", "订单创建".getBytes()); // 使用订单ID作为选择键,确保同一订单的消息进入同一队列 SendResult result = producer.send(msg, new MessageQueueSelector() { @Override public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) { Long orderId = (Long) arg; long index = orderId % mqs.size(); return mqs.get((int) index); } }, orderId); -
事务消息 :采用"两阶段提交"的思想。生产者先发送"半事务消息"到Broker,Broker将其存储在特殊主题中并回复生产者。生产者执行本地事务,根据结果向Broker提交
COMMIT或ROLLBACK指令。若生产者未响应,Broker会定时回查生产者本地事务状态。 -
延时消息:消息在Broker端延迟指定时间后才对消费者可见。通过内部不同的延时级别主题实现。
2.2 高可用与可扩展架构
- NameServer无状态集群:提供最终一致的路由信息,任意节点宕机不影响服务。
- Broker主从复制:基于DLedger(Raft协议实现)或异步/同步复制,保障数据可靠性。Slave节点可分担读压力。
- 消息过滤 :
- Tag过滤:消费者订阅时指定Tag,Broker在服务端进行过滤,效率高。
- SQL92过滤:支持更复杂的属性过滤,需Broker消耗更多计算资源。
2.3 流处理与生态集成
- RocketMQ Streams:一个轻量级、嵌入式的流计算引擎,允许用户以类似Flink/Spark Streaming的API对MQ中的消息进行实时处理,无需部署独立的流计算集群。
- RocketMQ Connect:提供标准化的Source(从外部系统拉数据到MQ)和Sink(从MQ推数据到外部系统)框架,便于与数据库、文件系统等进行数据集成。
3. 技术难点挖掘
RocketMQ的实现攻克了多个分布式系统的经典难题:
- 海量队列与高效路由:支持数万级Topic和队列的管理,NameServer需高效维护和推送路由元数据。
- 高性能消息存储 :如何在保证持久化的同时实现高吞吐、低延迟的读写。解决方案涉及内存映射文件(MappedByteBuffer) 、顺序写盘 和零拷贝(sendfile) 技术。
- 主从数据强一致性:在保证高可用的同时,如何实现主从数据的强一致同步,DLedger Controller模块基于Raft共识算法解决了此问题。
- 海量消息堆积下的快速检索 :为支持按时间或偏移量回溯消费,设计了高效的索引文件(
IndexFile)结构。 - 事务消息的最终一致性保证:解决了网络分区、生产者宕机等异常场景下的事务状态判定问题,通过"事务回查"机制实现。
4. 详细设计图
4.1 核心架构图
下图描述了RocketMQ集群的物理部署与逻辑交互关系。 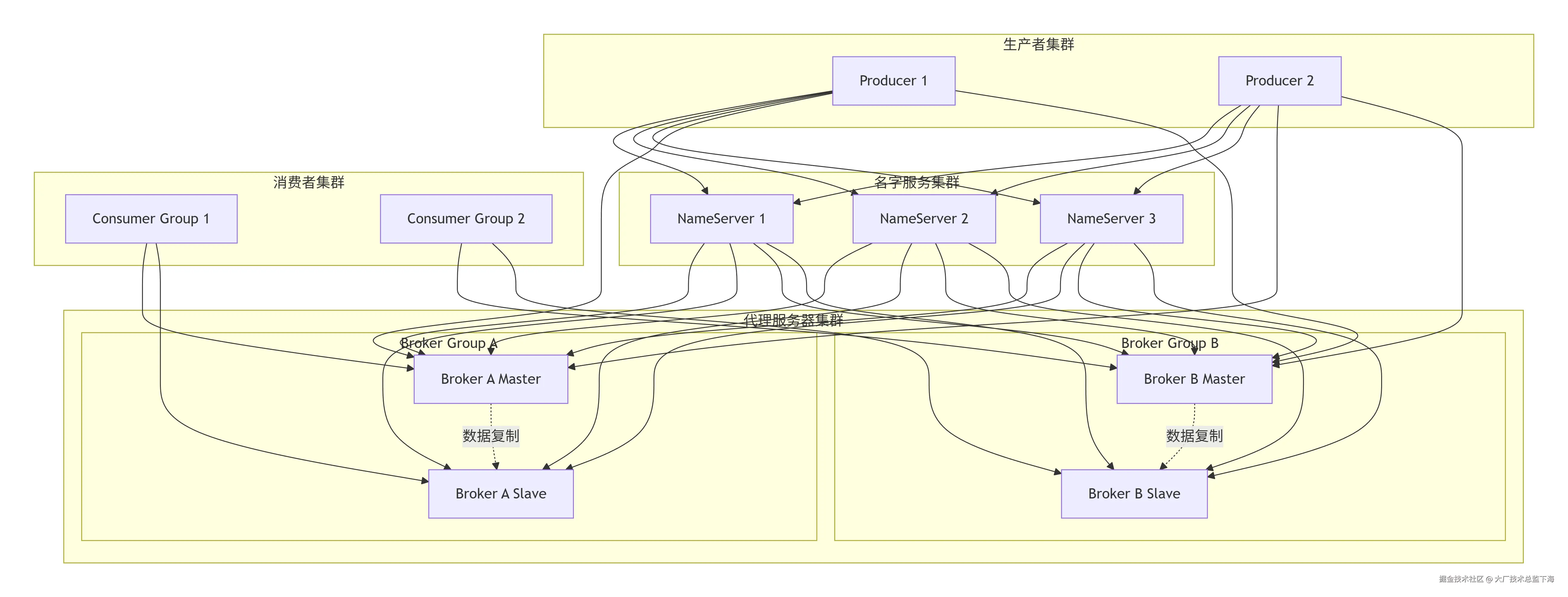
4.2 消息存储核心链路序列图
以消息存储为例,展示Broker内部的关键处理流程。
4.3 核心类图(简略)
展示Broker端存储模块的核心类关系。
5. 核心函数解析
5.1 消息存储入口:DefaultMessageStore.putMessage
这是消息持久化的核心入口。
java
// 代码位置:org.apache.rocketmq.store.DefaultMessageStore
public PutMessageResult putMessage(MessageExtBrokerInner msg) {
// 1. 前置检查 (存储状态、Broker角色、系统页缓存等)
if (this.shutdown) {
return new PutMessageResult(PutMessageStatus.SERVICE_NOT_AVAILABLE, null);
}
if (BrokerRole.SLAVE == this.messageStoreConfig.getBrokerRole()) {
// 从节点通常拒绝写请求
return new PutMessageResult(PutMessageStatus.SERVICE_NOT_AVAILABLE, null);
}
if (!this.runningFlags.isWriteable()) {
// 检查是否可写
return new PutMessageResult(PutMessageStatus.SERVICE_NOT_AVAILABLE, null);
}
// 2. 将消息追加到 CommitLog (核心存储文件)
PutMessageResult result = this.commitLog.putMessage(msg);
// 3. 根据写入结果,后续处理 (如构建索引、刷盘等是异步触发)
return result;
}5.2 CommitLog追加消息:CommitLog.putMessage
这是实现高性能写入的关键。
java
// 代码位置:org.apache.rocketmq.store.CommitLog
public PutMessageResult putMessage(final MessageExtBrokerInner msg) {
// ... 参数校验、消息属性设置 ...
// 获取最后一个MappedFile(内存映射文件),如果已满则创建新的
MappedFile mappedFile = this.mappedFileQueue.getLastMappedFile();
if (null == mappedFile || mappedFile.isFull()) {
mappedFile = this.mappedFileQueue.getLastMappedFile(0); // 参数0表示如果最后一个文件满,则强制创建新文件
}
// 将消息序列化为字节,追加到MappedFile的WriteBuffer
byte[] msgData = msg.serialize(); // 简化表示,实际序列化更复杂
AppendMessageResult appendResult = mappedFile.appendMessage(msgData);
switch (appendResult.getStatus()) {
case PUT_OK:
// 处理成功,可能触发刷盘(异步或同步)和HA复制
handleDiskFlush(appendResult, msg);
handleHA(appendResult, msg);
break;
case END_OF_FILE: // 文件已满,重试
// 创建新的MappedFile并重试追加
return new PutMessageResult(PutMessageStatus.END_OF_FILE, null);
// ... 其他状态处理 ...
}
// 返回结果,包含消息的物理偏移量等
return new PutMessageResult(PutMessageStatus.PUT_OK, appendResult);
}技术要点:
- 顺序写 :所有Topic的消息都顺序追加到同一个
CommitLog文件集合中,极大利用了磁盘顺序写的性能优势。 - 内存映射文件 (Mmap) :
MappedFile内部使用MappedByteBuffer将文件映射到进程内存空间,写入操作直接作用于内存,由操作系统负责刷盘,减少了用户态与内核态的数据拷贝。 - 异步化 :消息写入
CommitLog后,ConsumeQueue(逻辑队列索引)的更新和IndexFile(消息键索引)的构建是异步进行的,这分离了写入主路径和后台任务,保证了写入的响应速度。
5.3 对比与总结
与同类主流消息中间件相比,RocketMQ的特点如下:
- vs Apache Kafka :Kafka设计更偏向于高吞吐的日志流处理,在分区内保证顺序。RocketMQ在功能上更丰富,提供了事务消息、延时消息、多种过滤方式,其NameServer设计比Kafka依赖的ZooKeeper更轻量,主从切换机制在早期版本中更为灵活。Kafka的生态(如Kafka Streams, Connect)与RocketMQ Streams/Connect各有侧重。
- vs RabbitMQ :RabbitMQ基于AMQP协议,提供了强大的路由规则(Exchange),在消息路由的灵活性上更胜一筹 。而RocketMQ在吞吐量、堆积能力、分布式扩展性以及国内生态集成方面更有优势,更适合互联网级的海量数据场景。
总结:Apache RocketMQ是一个经过大规模生产验证、功能全面、性能优异的分布式消息和流处理平台。其架构设计巧妙平衡了性能、可靠性和扩展性,通过核心的存储引擎、灵活的部署模式和完善的生态系统,为构建现代分布式应用提供了坚实的基础通信设施。深入理解其架构与实现,对于设计高并发、高可用的系统具有重要参考价值。