本章内容包括:
- 在流水线中转换API定义
- 将生成的API工件发布到工件存储库
- 创建SDK和模拟API
- 部署API网关配置
在第8章中,我讨论了源代码阶段的治理控制,帮助团队在API设计阶段对API定义应用自动化治理检查。API定义经过审核和批准后,API团队可能需要执行以下操作:
- 从API定义生成工件,这些工件可能包括SDK、替代的API定义格式以及面向开发者门户的人类可读API参考文档。
- 将API服务部署到更高环境。
- 部署API网关配置。
- 测试已实现的API是否符合规范。
本章详细介绍如何在部署流水线中执行这些任务,部署流水线位于构建阶段以及部署和测试阶段(见图9.1)。
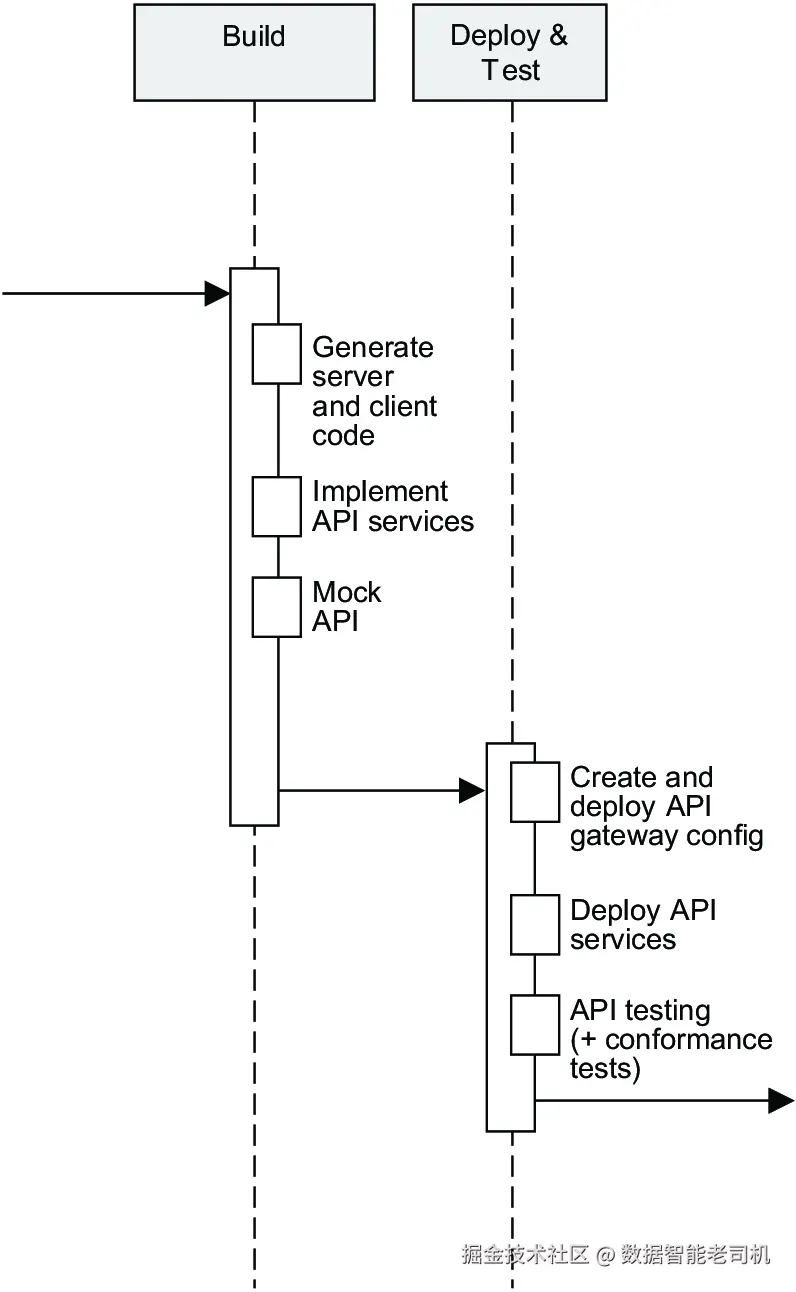
本章实践部分主要面向需要搭建部署流水线以部署和发布API的开发人员。你将通过一个示例,了解如何使用 GitHub Actions 搭建流水线,生成并发布API工件到内部API工件存储库。你还将实现通过APIOps(即基于GitOps的)工作流,在两个开源API网关中部署API配置。
虽然本章面向开发者,但API产品负责人也能从中获得对API工件流水线主要阶段的宏观了解。他们将理解参与APIOps部署工作流的不同团队类型,以及它如何融入组织的团队拓扑结构。API产品负责人和产品经理还应关注关于SDK管理及构建挑战部分提出的要点。
注意:本章代码示例复用并扩展了第8章的代码,相关代码可见 mng.bz/ngo2,且包含额外代码 mng.bz/GZAD 和 mng.bz/z8O1。我鼓励你动手实践这些示例,但如果想直接查看完整解决方案,代码库中也提供了以.completed为后缀的相关文件,使用时请根据需要重命名。
具备Docker和Kubernetes经验对本章有帮助,但非必需。附录E中有简要介绍。
9.1 构建阶段:转换API定义文件
假设在将API定义文件发布到开发者门户之前,你需要完成以下任务:
- 将多文件API定义打包成单个文件。
- 过滤结果定义文件,例如移除所有带有
x-internal:trueOpenAPI扩展标记的OpenAPI对象。 - 对OpenAPI定义文件中的
operationId字段进行排序,使其顺序一致。比如对所有API操作对象,operationId排在首位,接着是summary、description、parameters、requestBody和responses字段,依此顺序排列。 - 去除定义文件中未使用的组件。
- 根据OpenAPI文件创建Postman集合。
- 将处理后的OpenAPI定义文件上传到API工件存储库,以便流水线后续步骤能够检索、使用或发布到开发者门户。
注:在第4章中,我介绍了OpenAPI扩展机制,它允许向API定义文件添加额外数据。一种典型用例是API定义文件同时包含面向内部和外部的端点。你可以通过注释内部端点对象,添加如 x-internal:true 这样的扩展标记,区分它们与外部端点。支持该扩展的工具会按需处理它,而其他工具则会忽略。
我称对API定义文件所做的这些修改为"转换"。无论具体是哪种转换,都应在部署流水线中自动执行,使API定义适合对外发布或针对特定用户使用。外部视图可能来源于过滤、重命名、重写、打包、多API定义合并或其他转换。当组织维护的API定义视图与对外发布的不同,转换尤为必要。另一个常见示例是API定义中服务器URL需要从内部服务器改为外部沙箱服务器。
注:"打包"指将多文件API定义合并为单个API定义文件;"合并"或"连接"则指将两个或多个独立API定义合并为一个文件。
转换后的API定义可以存储在API工件存储库中,供需要使用的团队和应用检索。该工件存储库可为API注册中心、Postman工作区,甚至二进制工件仓库(如JFrog Artifactory或GitHub Packages)。API注册中心存储API定义文件,并提供API供用户上传、搜索和检索。Postman工作区类似于Postman平台上的目录,用于管理和共享API定义、已保存的API请求集合及环境文件。不论使用何种存储,关键是流水线CI阶段生成工件后,流水线后续步骤可以检索并使用这些工件。
图9.2展示了CI阶段如何从源代码仓库检索多文件API定义,进行转换,并存储到工件存储库的流程。
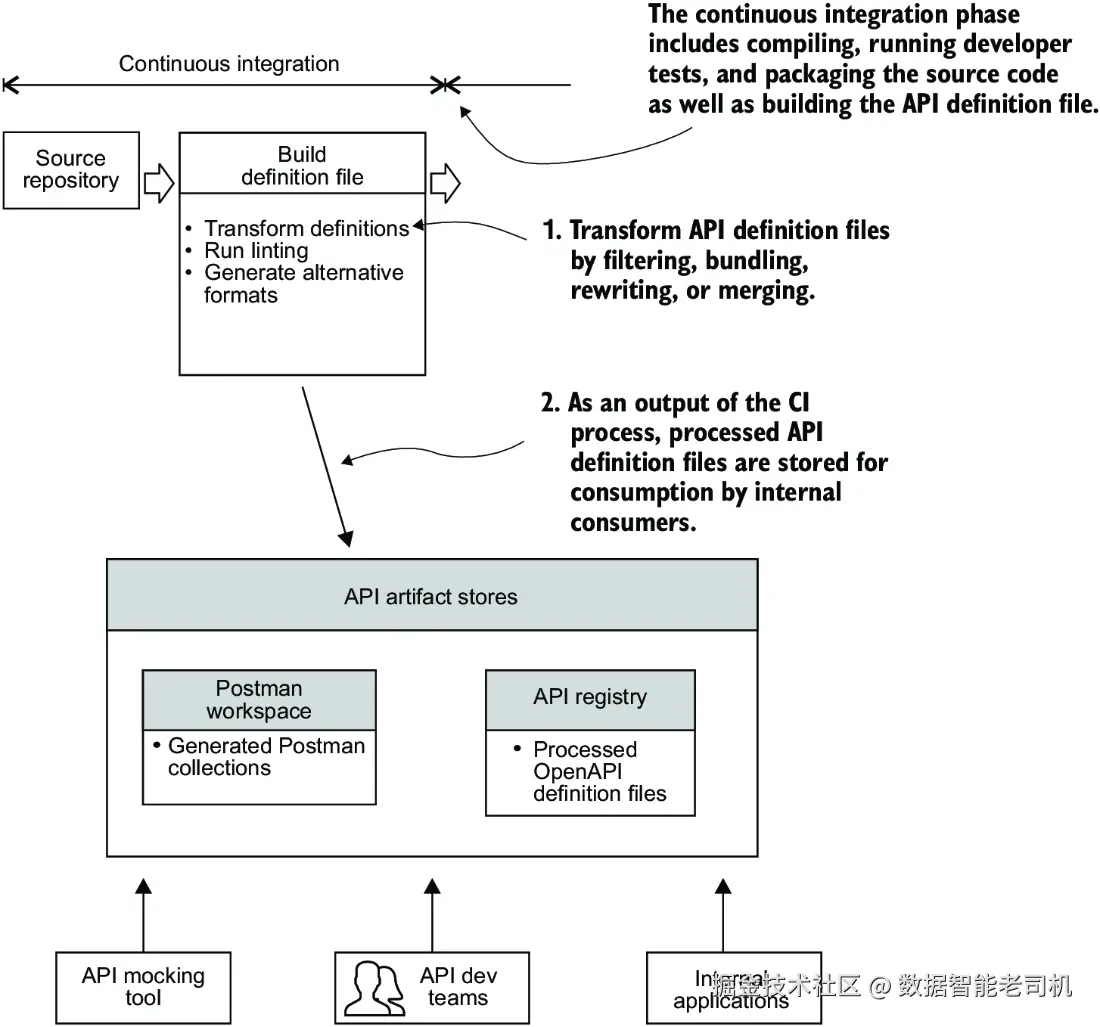
为了清晰展示你的API工件------这里指处理后的API定义文件------如何被使用,你可以将工件的使用者和生成该工件所用的工具总结在一个表格中,如表9.1所示。通过这样的表格记录流水线生成的API工件,有助于跟踪你生成了哪些工件,工件的用户是谁,以及他们使用工件的目的,从而让你更专注于满足工件用户的需求。
表9.1 生成的API定义工件总结
| 工件类型 | 工件用户 | 使用目的 | 生成工件所用的源文件 | 生成工件所用工具 | 工件存储位置 |
|---|---|---|---|---|---|
| 处理后的OpenAPI定义 | 外部API消费者开发者门户CI/CD流水线后续阶段 | 与外部API消费者共享用于开发者门户的API参考文档生成用于生成SDK | 多文件API定义 | Redocly CLI、openapi-format、openapi-filter | Apicurio API注册中心 |
我已向你介绍了在流水线的CI阶段对API定义进行转换并存储到API工件库的方法。现在,我将引导你编写流水线中的代码实现这些操作。
9.1.1 更新流水线代码
通常,部署流水线的CI阶段包括检出源码、编译、运行快速开发测试(单元测试)、将编译后的代码打包成可执行文件,并将可执行文件存储到二进制工件库中。除此之外,你还希望流水线能对API定义文件执行转换,并将转换后的定义文件存储到API工件库。
以下示例展示了如何在流水线中完成这些步骤。
首先,从 main 分支新建一个分支用于你的改动。创建一个GitHub工作流文件,使其在合并PR时构建应用。在示例代码仓库中,创建新工作流文件 .github/workflows/build.yaml,内容如下:
yaml
name: Deployment pipeline
on:
push:
branches:
- main
env:
GITHUB_RUN_NUMBER: ${{ github.run_number }}在该文件中,创建一个名为 pipeline 的任务,用于检出源码并将其编译成可执行的 .jar 文件。该任务需要读取仓库内容的权限和写入包的权限(写入到GitHub Packages,即GitHub的二进制工件仓库)。示例如下:
yaml
jobs:
pipeline:
name: Pipeline
runs-on: ubuntu-latest
permissions:
contents: read
packages: write
steps:
- name: Build - Checkout
uses: actions/checkout@v3
- name: Build - Set up JDK 17
uses: actions/setup-java@v3
with:
java-version: '17'
distribution: 'temurin'
cache: maven
- name: Build - Check Java version
run: |
mvn -version
echo $JAVA_HOME
- name: Build - Create application jar
run: |
cd chapter8
./run_app_build.sh在使用CI/CD构建微服务时,应用通常会被编译成可执行文件并打包到容器中(如使用Docker,详见附录E)。这些容器包含应用运行所需的所有库和依赖,存储在容器仓库中,流水线的下游环境可以从中获取并运行。
注意:本示例中构建API服务的应用代码未必体现使用Maven构建Spring Boot应用的最佳实践,代码中做了一些简化。
在示例中,增加一个步骤将生成的 .jar 打包成Docker镜像并推送到GitHub容器注册表(GHCR),示例如下:
yaml
- name: Build - Log in to the GitHub Container Registry
uses: docker/login-action@65b78e6e13532edd9afa3aa52ac7964289d1a9c1
with:
registry: ghcr.io
username: ${{ github.repository_owner }}
password: ${{ secrets.GITHUB_TOKEN }}
- name: Build - Build and push Docker image
uses: docker/build-push-action@f2a1d5e99d037542a71f64918e516c093c6f3fc4
with:
context: .
push: true
tags: ghcr.io/${{ github.repository_owner }}/products-api-service:${{ github.run_number }}
file: chapter8/Dockerfile接下来,编写流水线中转换API定义的步骤。你需要将多文件API定义打包成单个文件,可以用Redocly CLI的 bundle 命令实现。添加步骤将API定义打包,并将结果文件移动到 build-output 目录,如下:
bash
- name: Build - Create output directory for API artifacts
run: mkdir build-output
- name: Build - Bundle API definition file
run: |
cd chapter8/apis/product-catalog-api
npx @redocly/cli bundle openapi.yaml --output api.bundled.yaml
mv api.bundled.yaml ../../../build-output/api.bundled.yaml然后,过滤内部端点和未使用组件,并按要求排序OpenAPI字段。帮助过滤OpenAPI定义的工具有Mike Ralphson的 openapi-filter<[github.com/Mermade/ope...github.com/thim81/open...),或者Redocly CLI的过滤和自定义插件功能(github.com/Redocly/red...)。你也可以自己写代码将API定义解析成内存对象,再按需过滤。 本示例中,编写步骤用Mermade/openapi-filter工具过滤带有 x-internal:true 扩展的OpenAPI对象(包括GET /v1/catalog/products/{id}/reviews端点)。命令格式为 openapi-filter <选项> -- <输入文件> <输出文件>。接着,编写步骤移除未使用组件,并用thim81/openapi-format工具按需排序字段。命令格式为 openapi-format <openapi定义> --filterFile <过滤配置> --sortFile <排序配置>。
示例如下:
bash
- name: Build - Filter internal endpoints
run: |
npx openapi-filter --flags x-internal --verbose -- build-output/api.bundled.yaml build-output/api.yaml
- name: Build - Remove unused components
run: |
npx openapi-format build-output/api.yaml --filterFile chapter9/unused-components-filter.yaml --sortFile chapter9/sort.json --output build-output/api.yaml
- name: Build - Run API linting
run: |
npx @stoplight/spectral-cli lint build-output/api.yaml --ruleset chapter8/apis/rulesets/json-api.ruleset.yaml- 使用
openapi-filter过滤定义文件。 - 移除未使用组件并排序定义文件。
过滤配置文件 chapter9/unused-components-filter.yaml 指定了要移除的未使用组件类型,内容示例如下:
markdown
unusedComponents:
- schemas
- parameters
- examples
- headers
- requestBodies
- responses排序配置文件 chapter9/sort.json 指定了每个OpenAPI对象字段的层级排序顺序,示例如下:
json
{
"root": ["openapi", "info", "servers", "paths", "components", "tags", "x-tagGroups", "externalDocs"],
"get": ["operationId", "summary", "description", "parameters", "requestBody", "responses"],
"post": ["operationId", "summary", "description", "parameters", "requestBody", "responses"],
"put": ["operationId", "summary", "description", "parameters", "requestBody", "responses"],
"patch": ["operationId", "summary", "description", "parameters", "requestBody", "responses"],
"delete": ["operationId", "summary", "description", "parameters", "requestBody", "responses"],
"parameters": ["name", "in", "description", "required", "schema"],
"requestBody": ["description", "required", "content"],
"responses": ["description", "headers", "content", "links"],
"content": [],
"components": ["parameters", "schemas"],
"schema": ["description", "type", "items", "properties", "format", "example", "default"],
"schemas": ["description", "type", "items", "properties", "format", "example", "default"],
"properties": ["description", "type", "items", "format", "example", "default", "enum"]
}提交更改并推送到你的GitHub仓库。你应该能看到GitHub Actions工作流成功运行。
我们回顾一下内容:你已经了解了多种处理OpenAPI定义文件的方法。流水线中可以重命名API定义文件标题,将定义文件从YAML转换成JSON或反之,移除未使用组件,剥离供应商扩展,过滤定义文件中的对象。处理后的定义文件需要被存储,而API注册中心就是常见的存储方案。下一节我们将详细介绍API注册中心。
9.1.2 在 API 注册中心存储 API 定义
API 注册中心是你组织的 API 目录。它是一个运行时系统,允许用户上传和共享 API 定义文件及组件给其他用户和软件系统。API 注册中心还提供 API,供客户端程序以编程方式访问 API 工件。换句话说,它为组织的 API 定义提供了统一的接口。常见的 API 注册中心包括 Apicurio Registry(www.apicur.io/registry)、S...mng.bz/0GeJ)和 Apigee Registry API(github.com/apigee/regi... API 定义或事件模式在运行时验证消息。API 定义的搜索与发现功能也有助于提升组织内模式和组件的一致性及复用。
正如我之前提到的,开源 API 注册中心的一个示例是 Apicurio Registry。它是由 Red Hat 赞助的开源 Apicurio 项目的一部分,支持创建、更新和删除以 OpenAPI、AsyncAPI、GraphQL、Apache Avro、Google Protocol Buffers、JSON Schema、Kafka Connect Schema、Web Service Description Language (WSDL) 和 XML Schema Definitions (XSD) 等格式定义的 API。
在 Apicurio Registry 中,注册中心内的条目,如 OpenAPI 定义文件和 Avro 模式,被称为工件(artifact)。一组逻辑相关的 API 工件称为工件组(artifact group)。同一组中的工件通常由单一实体、应用或组织管理。Apicurio Registry 还支持工件引用,即一个 API 定义文件或模式可以引用另一个,从而实现模式和组件的复用。你可以通过 Apicurio 的 REST API 编程管理这些工件。本文撰写时,该 API 参考文档可见于:mng.bz/KZrX。接下来,我将... Apicurio API 注册中心中存储和查看条目。
从本地发布到 API 注册中心
在项目根目录,运行以下命令启动 Apicurio(以及 Kong API 网关)的 Docker 容器:
bash
docker compose -f chapter9/compose.yaml up -d然后,你可以通过浏览器访问 http://localhost:9090/ui/artifacts 查看 Apicurio 界面。现在上传一个 API 定义文件到 Apicurio。你可以不用 UI,而通过 Apicurio 的 REST API 来实现。运行命令:
bash
./chapter9/publish-to-apicurio.sh该脚本执行的 curl 请求如下:
lua
curl -v -X POST 'http://localhost:9090/apis/registry/v2/groups/acmeapis/artifacts?ifExists=UPDATE' \
--header 'Content-Type: application/x-yaml' \
--header 'X-Registry-ArtifactId: productsapi' \
--header 'X-Registry-ArtifactType: OPENAPI' \
--data-binary "@chapter8/apis/product-catalog.oas.yaml" \
--output created-artifact.json \
--fail-with-body#1创建一个新的工件,提交工件内容。#2指定内容类型为 YAML。#3指定工件的唯一标识符。#4指定工件类型为 OpenAPI。#5以二进制格式发送 API 定义文件,保持换行和空格。#6将响应输出写入文件。#7如果 HTTP 状态码≥400,curl 返回非零错误码。
上传后,在浏览器访问:http://localhost:9090/ui/artifacts/acmeapis/productsapi/versions/latest 查看你的 Products API 定义文件。页面右侧的版本下拉菜单可查看已发布的所有版本。Documentation 标签页展示渲染后的 API 定义(ReDoc 格式,详见 github.com/Redocly/red... 标签页显示原始 API 定义文件。
你还可以用 UI 上的搜索功能搜索 API 工件。访问首页 http://localhost:9090/ui/artifacts ,将搜索条件从默认的"名称"切换为"描述",搜索包含"catalog"的工件。你注册中心中只有一个工件------Product Catalog API,它会出现在搜索结果中。
你已经了解了如何在本地使用 API 注册中心,接下来我将介绍如何在 GitHub Actions 流水线中完成相同操作。
从流水线发布到 API 注册中心
理想情况下,应有一个长期运行的 API 注册中心实例,供其他团队和应用后续检索工件。但为简单起见,本例中可以在 GitHub Actions 的运行容器中启动 API 注册中心(流水线执行完毕后销毁),并发布到此临时实例。
在你之前创建的 checkout 步骤后,向 .github/workflows/build.yaml 文件中添加启动 API 注册中心的步骤,如下所示。(注意该步骤也会启动 Kong 网关,后续流水线会用到它。)
yaml
steps:
- name: Build - Checkout
uses: actions/checkout@v3
- name: Build - Start background services (Kong gateway and Apicurio API registry)
run: |
docker compose -f chapter9/compose.yaml up -d
- name: Build - Set up JDK 17(#1 新增启动 API 注册中心的步骤)
在执行 API linting 的最后一个步骤后,添加以下步骤,用于归档转换后的 API 定义文件(方便后续下载查看)、发布到 API 注册中心,并保存注册中心返回的工件版本号,如下:
yaml
- name: Build - Run API linting
run: |
npx @stoplight/spectral-cli lint build-output/api.yaml --ruleset chapter8/apis/rulesets/json-api.ruleset.yaml
- name: Build - Archive artifacts
uses: actions/upload-artifact@v3
with:
name: dist-after-linting
path: |
build-output
- name: Build - Publish updated API definition to registry
run: |
curl -v -X POST 'http://localhost:9090/apis/registry/v2/groups/acmeapis/artifacts?ifExists=UPDATE' \
--header 'Content-Type: application/x-yaml' \
--header 'X-Registry-ArtifactId: productsapi' \
--header 'X-Registry-ArtifactType: OPENAPI' \
--data-binary "@build-output/api.yaml" \
--output created-artifact.json \
--fail-with-body
- name: Build - Get created artifact version
id: artifact-version
run: |
echo "ARTIFACT_VERSION=$(cat created-artifact.json | jq -j '.version')" >> $GITHUB_OUTPUT#1新增归档工件步骤。#2新增发布 API 定义到 API 注册中心步骤。
将修改提交并推送,创建 PR 合并到 main 分支。合并后,你应能在 GitHub 仓库的 Actions 标签页看到工作流执行。
注意 :本示例仅演示如何将 OpenAPI 定义上传到 API 注册中心。你还可以添加步骤,通过 Portman CLI(github.com/apideck-lib... OpenAPI 定义生成 Postman 集合并上传到 Postman 工作区。Portman 在第7章已有介绍,文档也包含详细说明,你可以在学习本节后尝试实现。
9.2 构建阶段:使用 Mock 模拟 API
当你还在编写 API 服务代码时,下游集成该 API 的应用可能就想开始集成工作了。问题是:在你还未完成实现时,如何给他们提供一个可以用来开发的 API?换句话说,如何针对一个可能不可用或不受你控制的 API 依赖进行开发和测试?
API 模拟可以解决这个问题。API 模拟通过接受与真实 API 相同类型的请求,并返回相应类型的响应,来模拟真实 API,使开发人员能够在没有真实服务的情况下开发和测试依赖该 API 的应用程序。图 9.3 展示了这一过程。没有 API 模拟,API 使用者可能不得不停下来等待该 API 依赖变得可用后才能继续开发。
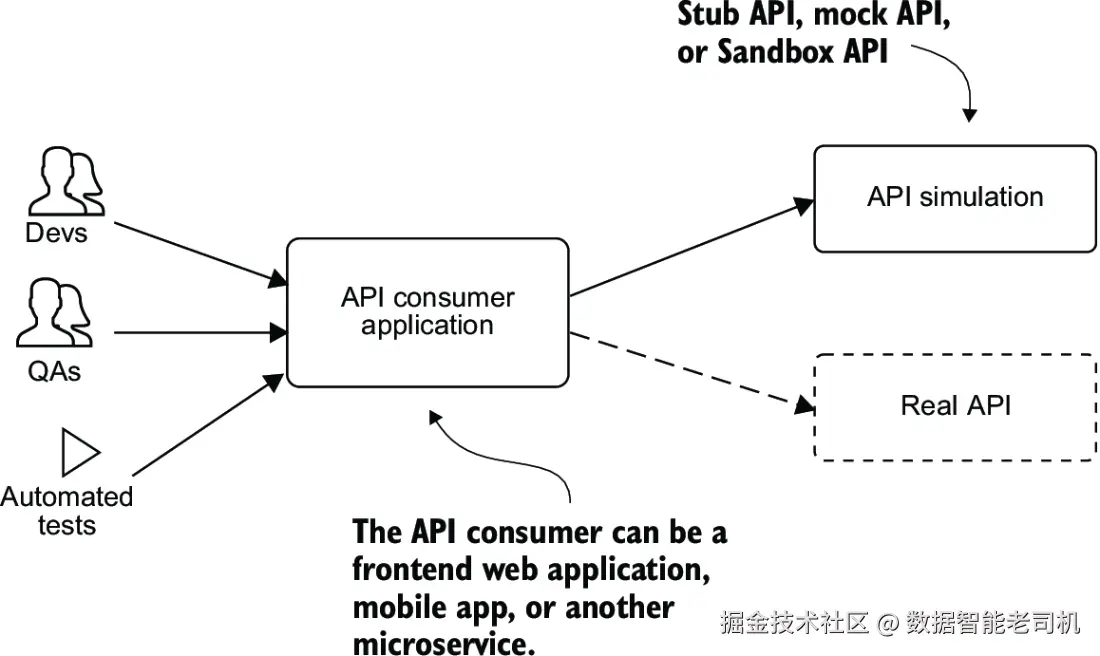
API 模拟可以分为以下几类:
Stub 或 Dummy API------这是对 API 服务器的简单模拟,功能有限。它通过返回预定义的响应给客户端请求,或者对所有请求都返回相同的响应,来实现模拟。这种方式适用于集成测试的早期阶段,重点是让客户端应用能实现一个可用的集成,而不是测试所有交互和失败场景。
Mock API------这是对真实 API 行为的更高级模拟。它可以根据指定条件定制返回动态响应,允许开发者测试各种成功和错误交互场景,更准确地模拟真实环境下的情况。
Sandbox API------是真实 API 的实现,运行在受控且隔离的环境中,开发者可以用它来探索、测试和了解 API 的工作原理,而不会影响生产数据和系统。API 提供商通常会提供功能有限的 Sandbox API,作为开发者入门流程的一部分,并提升开发体验。比如 Uber API sandbox 和 eBay API sandbox。
Stub 和 Mock API 通常可以用 OpenAPI 定义文件创建(例如从 API 注册表中获取定义文件),或者通过其他静态文件(如 JSON 或 YAML)指定预期请求和响应。它们还支持程序化配置以及记录和使用真实 API 的响应。理想情况下,Stub 和 Mock API 的行为应尽可能接近真实 API,但创建和维护不应过于繁琐。
Mock-First API 设计
除了支持开发和测试,Mock API 还非常适合在 API 设计阶段做原型设计。这种方法被称为原型优先或 Mock 优先设计,指 API 设计者先通过 Mock API 工具创建一个 Mock,而不是直接写 OpenAPI 定义。API 设计者和使用者可以通过 Mock 工具协作快速搭建原型草图,之后再根据原型生成 OpenAPI 定义。
更多关于 Mock-First 设计方法,可参考 Tom Akehurst 的文章《Mock-First API Prototyping》。
9.2.1 API 模拟的优势
API 模拟为开发者和测试人员带来多方面好处:
- 支持并行开发------前端团队可以使用 API 模拟进行集成和测试,后端团队同步开发 API。
- 支持可用性------开发和测试期间不必依赖真实 API 服务的稳定性和可用性。
- 帮助测试隔离------自动化测试可以用 Mock API 运行,避免依赖可能不稳定、昂贵或有限制的真实 API。
- 支持真实场景测试------Mock API 能模拟各种测试场景,比如高网络延迟或随机失败,帮助验证应用在真实环境下的表现。
- 降低成本------减少开发集成时对昂贵第三方 API 的请求次数,降低资源开销。
- 提升测试效率------使用 Mock 或 Stub API 进行部分测试能加快测试速度,降低网络延迟。
9.2.2 Mock API 类型与工具模式
Mock 和 Stub API 可以使用多种开源 API Mock 工具创建,如 Prism、Microcks、WireMock 和 Hoverfly。
根据运行位置,Mock API 可分为:
- 本地 Mock------运行在开发者工作站,适合需要灵活本地测试或离线访问的场景。
- 服务器 Mock------又称公共、托管或云 Mock,部署在公共或内部服务器,供多人或多应用访问。
根据所模拟的 API 类型,Mock API 又分为:
- 内部 Mock API------由你自己拥有和管理的 Mock。
- 外部 Mock API------模拟第三方 API,适合第三方 API 请求配额有限、成本高或不稳定难用的情况。
根据模拟模式,Mock 工具通常支持:
- 静态或 Stub 响应模式------为每个接口返回固定的预设响应,数据可能重复且过时。
- 动态响应模式------返回动态生成的响应,响应结构相同但内容会变化。
- 记录回放模式(Record-Replay)------作为代理服务器记录真实请求与响应,后续用保存的响应模拟。
- 代理模式(Proxy)------对已定义请求返回 Mock 响应,未定义请求转发给真实 API。
9.2.3 使用 Mock API 测试真实场景
举例来说,如果你想测试 API 消费者在遇到随机响应延迟时的表现,比如模拟响应延迟在 50 到 800 毫秒之间的均匀分布,这种行为在真实服务中难以实现,但可以用 Mock API 来完成。
使用 WireMock 这类开源 Mock 工具,可以通过 JSON 映射文件配置请求匹配规则和延迟模拟。启动 WireMock 后多次请求指定接口,可以观察到响应时间在预期范围内变化,从而测试应用在延迟场景下的表现。
到目前为止,我们讨论了如何在部署流水线中转换 API 定义、如何存储到 API 注册表,以及如何创建 API Mock 以支持开发和测试。接下来我将讲述构建阶段的另一项任务------为 API 生成 SDK。
9.3 构建阶段:生成并存储 SDK
如果你想根据 OpenAPI 定义文件生成客户端 SDK 呢?比如你的 API 使用者需要一个 Java SDK,这将帮助他们快速开始集成你的 API。你会如何在流水线中生成这个 SDK 呢?
在构建阶段,你有几种方式可以生成客户端 SDK。你可以使用 SDK 生成器(例如第6章中介绍的 OpenAPI Generator CLI)从捆绑好的 OpenAPI 定义文件生成 SDK。你也可以使用代码生成即服务(Codegen-as-a-Service,简称 CGaaS)提供商,这类服务会接入你的部署流水线,生成多语言 SDK。示例包括 Speakeasy(www.speakeasyapi.dev)和-321g/) APIMatic(www.apimatic.io)。./)
生成 SDK 后,你需要把生成产物存储在一个方便团队和应用共享的位置。在部署流水线中,通常会将生成的产物存储在二进制产物仓库中。二进制产物仓库是存放文本和二进制产物(如软件包)及其元数据的仓库。
为 API 使用者提供多语言 SDK 非常有价值。SDK 不仅比单纯提供 API 文档更好地提升开发体验,还能帮助使用者更快地集成 API,从而提高 API 产品的采用率和使用频率。SDK 之所以能加速 API 消费,是因为它提供了工具类和认证辅助函数。语言绑定让开发者可以直接用该语言的对象和函数来调用 API。下面我会总结为 API 提供 SDK 的一些好处。
9.3.1 提供 SDK 的好处
SDK 带来更好开发体验的原因主要有两个:
- 减轻使用者负担
没有 SDK 时,API 使用者必须自己用各自的编程语言写调用 API 的函数,遵守正确的编码规范,构建一个高质量的 SDK。而且 API 更新后,他们还得维护和更新自己的代码。 - 提供抽象层,简化使用
某些操作可能涉及多个 API 调用,设计良好的 SDK 可以将这些细节封装起来,让使用者只需调用一个函数。比如请求中可能涉及的认证令牌刷新,没有预构建 SDK 的情况下,使用者必须检测令牌过期并主动调用刷新接口;而 SDK 能自动隐藏这些复杂逻辑,减少使用者的工作量。在某些情况下,这种抽象还能减少用户支持问题,因为 SDK 接口比原始 REST 调用更易用,不需要太多指导。
对于构建 API 优先产品(API 是主要集成接口的平台)的组织,应该考虑提供客户端 SDK。对于不是 API 优先的组织,则需要权衡是否值得投资建设 SDK。
决定是否提供 SDK 时,应考虑该语言的 SDK 是否能帮助潜在客户做出购买决策,以及是否愿意自己维护 SDK 带来的更佳开发体验,而非让开发者依赖第三方或开源方案。
9.3.2 构建 SDK 的挑战
构建和维护 SDK 也存在一些挑战:
- 维护开销
首次为某语言创建 SDK 需要投入,包含修改流水线支持生成、测试和文档的工作。此外,还要维护特定语言的问题修复和更新。 - 资源投入
不同语言有各自的编码标准和惯用法,API 提供方需在每种语言上具备专业知识,保证 SDK 质量。多语言 SDK 维护需要投入大量时间和人力,小型组织可能难以承受。 - 版本管理
新版本 API 可能与旧版 SDK 不兼容,因此需要发布新 SDK,并进行充分测试。说服旧版本 SDK 用户升级也是难点。大规模跟踪用户使用的 SDK 版本和语言也具有挑战。
替代方案包括只提供 API 定义文件和文档,让使用者自己生成 SDK,或发布开源 SDK 并由社区维护和贡献。但这会导致组织失去对开发者集成体验的掌控和支持。
9.3.3 在流水线中集成 SDK 生成
下面演示如何在 GitHub Actions 流水线中集成 OpenAPI Generator CLI,并将生成的 SDK 存储到 GitHub Packages(二进制包仓库)。
表 9.2 总结了生成 Java SDK 的理由和其他要点。
| 产物类型 | 使用者 | 使用目的 | 生成源文件 | 生成工具 | 存储位置 |
|---|---|---|---|---|---|
| Java 客户端 SDK | 外部 API 使用者内部集成应用 | 集成外部 API 的内部应用 | OpenAPI 定义文件 | OpenAPI Generator | GitHub Packages |
生成 SDK 的另一种 API 定义格式:Fern
本例中,你是从 OpenAPI 定义生成 SDK。但也有其他选择。Fern(buildwithfern.com)是一个开源-o84fuio19hj9lxyr/) REST API 构建工具包,Fern API 定义格式是 OpenAPI 的替代品。Fern 附带编译器,可生成客户端 SDK、服务端代码存根、Postman 集合,甚至 OpenAPI 定义文件。Fern 定义使用 YAML,设计上比 OpenAPI 更简洁,避免了 OpenAPI 中一些生成器难处理的歧义(如非判别联合和 anyOf 关键字)。编译器还致力于生成符合语言习惯的代码。详情可见 Fern 官网(mng.bz/8w9K)。
生成 Java SDK 的示例模板和命令
章节目录 chapter8/java-template 中包含了基于 okhttp-gson 客户端的 Java SDK OpenAPI 生成器模板。
你可能想知道这个模板怎么来的,正如第6章提到的,可以用 openapi-generator-cli author template 命令生成模板,或者直接复制 OpenAPI Generator 的源码模板。我已经帮你准备好了模板文件,放在了 chapter8/java-template 目录下,更多信息见 openapi-generator.tech/docs/templa... 。
现在,在流水线中添加生成 SDK 的步骤,示例如下:
bash
- name: Build - Generate Java SDK
run: |
sed -i "s/OWNER/${{ github.repository_owner }}/g" chapter8/java-template/libraries/okhttp-gson/pom.mustache
sed -i "s/REPO_NAME/${{ github.event.repository.name }}/g" chapter8/java-template/libraries/okhttp-gson/pom.mustache
tail -8 chapter8/java-template/libraries/okhttp-gson/pom.mustache
npm install -g @openapitools/openapi-generator-cli
openapi-generator-cli generate \
--input-spec build-output/api.yaml \ #1 OpenAPI 规范文件路径
--generator-name java \ #2 使用 Java 客户端生成器
--output build-output/java-client \ #3 生成代码输出目录
--template-dir chapter8/java-template \ #4 使用的模板目录
--library okhttp-gson \ #5 使用 OkHttp + Gson 库
--additional-properties=invokerPackage=com.acmepetsupplies.client,apiPackage=com.acmepetsupplies.api,modelPackage=com.acmepetsupplies.model,groupId=com.acmepetsupplies,artifactId=acmepetsupplies-java-client,artifactVersion=1.0.0-SNAPSHOT指定 GitHub Packages Maven 仓库
注意,步骤开始的两行用 sed 命令替换了模板文件 pom.mustache 中的 OWNER 和 REPO_NAME 为你的 GitHub 账户名和仓库名。pom.mustache 模板会生成 pom.xml 文件,其中 <distributionManagement> 元素的 URL 包含 https://maven.pkg.github.com/OWNER/REPOSITORY,告诉 Maven 把包发布到哪里,这一步将在下一节进行。
提交变更,创建并合并 PR,触发构建。这样,你就完成了 SDK 的生成。但生成的产物该放哪儿呢?我们接着讲。
9.3.4 在产物仓库中存储 SDK
软件部署流水线的持续集成(CI)阶段会生成各种产物,这些产物可能包括已编译的代码、可部署的发布候选包、SDK 以及其他产物。虽然也可以将这些产物存储在版本控制系统中,但这样做效率低下,因为版本控制系统主要设计用于管理文本文件,而非二进制文件。
二进制产物仓库则作为一个集中存储地点,用来保存 CI 阶段构建生成的产物,以便流水线后续阶段------持续交付(CD)阶段------无需重新生成这些产物,而是直接从产物仓库获取它们。图 9.4 中对此进行了说明。
常见的产物仓库管理工具包括 Sonatype Nexus、JFrog Artifactory 和 GitHub Packages。
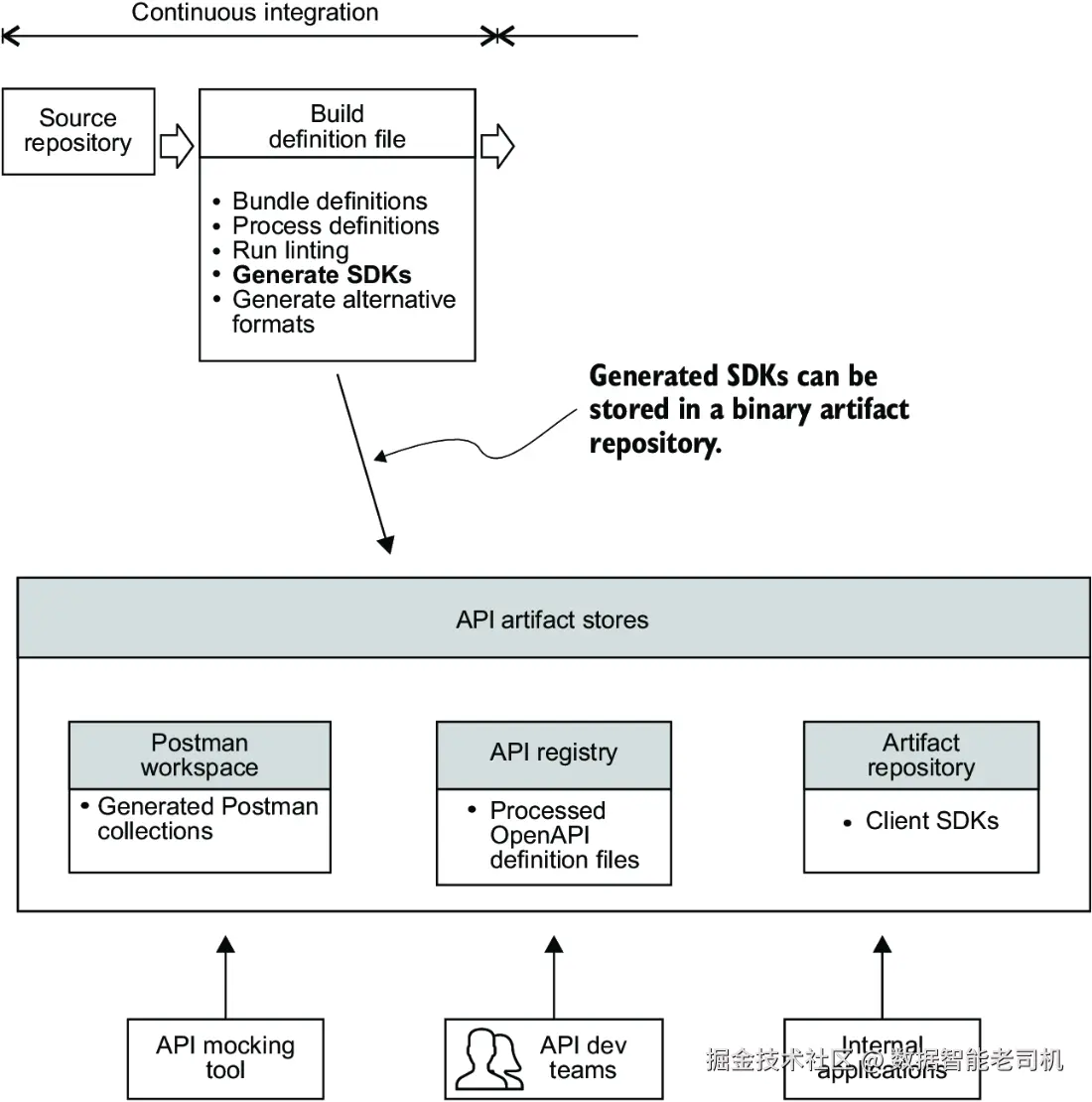
产物仓库提供以下几个好处:
- 协作与依赖管理 --- 产物仓库为团队间共享产物提供了一个集中平台。组织中可能有多个持续集成(CI)服务器生成产物,产物仓库可以作为它们发布这些产物的中央地点,使各个团队及部署流水线后续阶段能够访问它们。产物仓库还能存储构建过程所需的软件包和依赖。
- 高效构建 --- 一旦流水线构建完成产物,就无需针对同一版本重复运行流水线,后续阶段可以直接从仓库获取所需产物。
- 版本化产物及元数据 --- 产物仓库会将每个产物存储为新版本,同时存储诸如产物哈希值、构建时间等元数据信息。此外,一旦产物发布到仓库,其内容和元数据就不会再改变,这有助于定位和调试历史版本的软件问题。你可以直接下载报告缺陷的产物包进行调试。
- 分阶段发布 --- 你可以通过将产物移动到仓库中不同的文件夹来表示它在组织中跨越不同环境(如开发、测试、预发布、生产)的状态转变。且无需在仓库中保留所有生成的产物,只需保留成功通过所有流水线阶段的产物,未通过的可清理掉。
- 访问控制 --- 产物仓库具备访问权限管理功能,帮助你控制谁有权限发布和获取仓库中的产物。
你现在了解了将 SDK 存储在产物仓库的好处。接下来,我会展示如何把你生成的 SDK 存储到仓库中。
9.3.5 更新流水线以存储 SDK
在你的 .github/workflows/build.yaml 文件中,添加一个步骤,将生成的 SDK 发布到 GitHub Packages,示例如下。Maven 的 deploy 命令会将 SDK 的 .jar 文件连同其它元数据、MD5 和 SHA1 哈希文件一起发布到远程包仓库。
bash
- name: Build - Publish SDK to GitHub Packages
run: |
cd build-output/java-client
mvn --batch-mode deploy #1
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} #2
#1 将生成的代码部署到 GitHub Packages
#2 用于认证 GitHub Packages 的 GitHub 令牌提示:完整工作流的示例可查看 .github/workflows/build-transform.yaml.completed。
完成后,提交变更创建 PR,合并后你应能看到构建流程运行且生成的 SDK 已发布到产物仓库。在你的 GitHub 仓库主页右侧,会看到一个 Packages 区块,其中包含生成的包链接:com.acmepetsupplies.acmepetsupplies-java-client 1.0。
随着 API 产物生成完毕,接下来我们进入流水线的持续交付(CD)阶段------在更高环境中将 API 部署到 API 网关。
9.4 部署与测试阶段:部署 API 网关配置
设想你已经构建了后端 API 服务,现在想将其部署并通过 API 网关在某个环境中对外暴露接口。假设你只想暴露 API 中的一个端点------GET /v1/catalog/products/<uuid>。图 9.5 展示了你需要在哪个流水线阶段部署该配置。
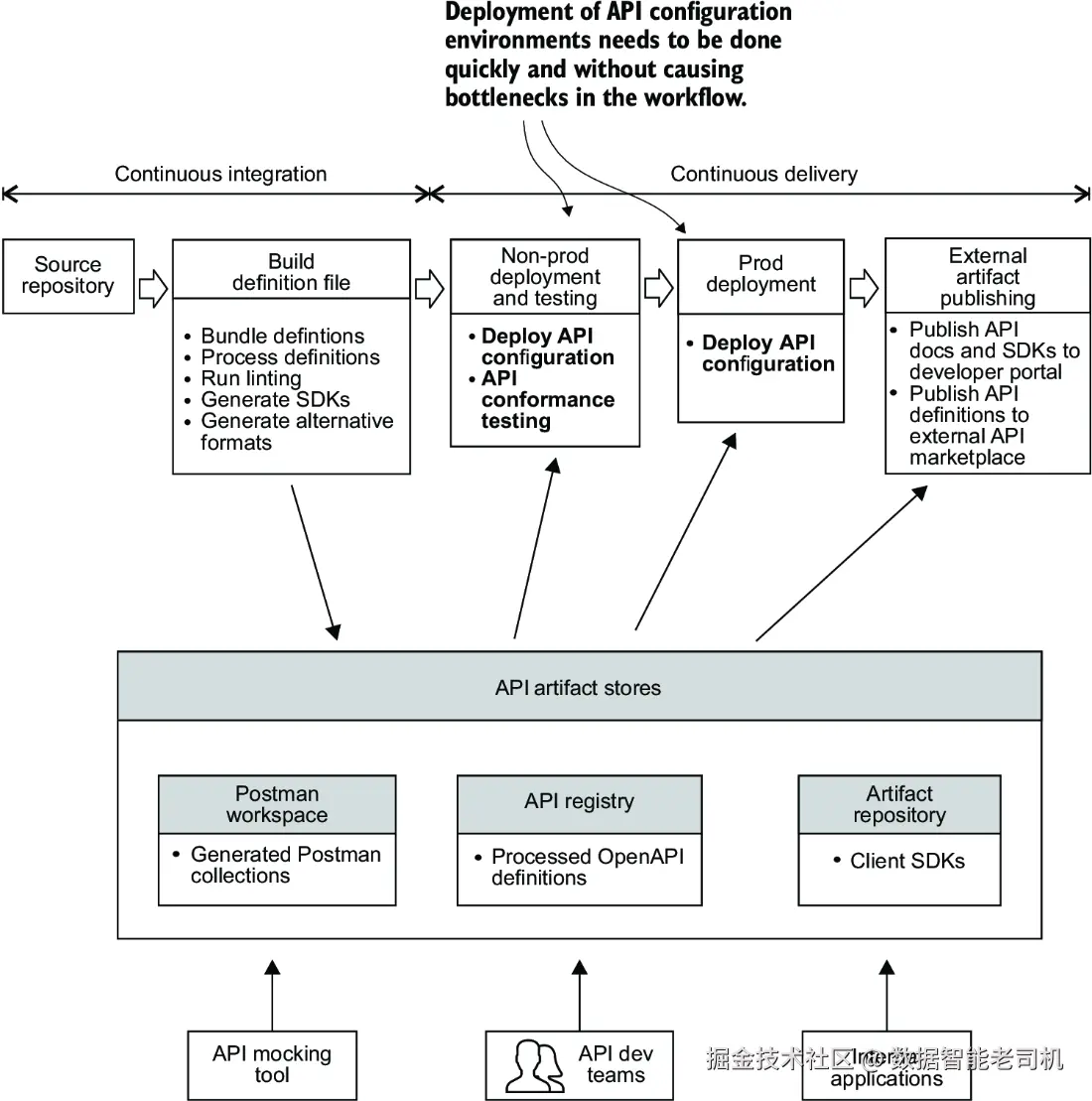
假设你的 API 只是组织中许多需要通过中央 API 网关暴露的 API 之一,而这个网关由 API 平台团队负责管理。那你如何创建配置以暴露该 API,而无需为管理 API 网关的团队提交工单?换句话说,如何避免将工作交接给另一个团队所导致的流程瓶颈和交付周期延长?
答案正是 APIOps 的核心,它提供了一种基于 GitOps 原则自动部署 API 配置到 API 网关的方法。接下来你将看到这是如何实现的。
9.4.1 APIOps 部署
在 APIOps 中,所有对配置状态的变更都是通过更新版本控制系统(VCS)中的配置状态文件来完成的。这就是 GitOps 工作流在 API 配置上的应用。如第一章所述,GitOps 模型的基本原则包括:
- 声明式配置 --- 被管理系统的期望状态(即重新创建该系统实例所需的所有配置信息)以声明式方式描述。声明式配置描述的是期望的运行状态,但不指定如何实现该状态。这种方式将定义配置的职责和其实现分开。实现指的是为了达到期望状态所调用的命令式指令、API 调用和脚本。
- 版本化且不可变的配置 --- 期望状态以不可变版本的方式存储。存储库包含完整的状态声明版本历史,并对状态变更提供访问控制和审计功能。Git 是最典型的状态存储工具。通过 PR(Pull Request)和 CODEOWNERS 等机制审批对期望状态配置的更改。
- 自动拉取配置 --- 由软件代理(自动化进程)从存储期望状态声明的源(通常是 Git 版本控制系统)自动拉取配置。软件代理可以是独立进程或部署流水线。
- 持续调和配置 --- 软件代理持续比对实际系统状态与期望状态,即监控实际状态是否偏离期望(称为漂移),一旦发现偏离,代理会尝试更新实际状态以匹配期望状态。
GitOps 不鼓励手动更改配置,比如通过 API 网关的用户界面,因为手动操作易出错、难调试,且缺乏版本控制日志提供的审计历史。简言之,GitOps 结合了基础设施即代码(IaC)、PR 和 CI/CD 流水线的做法。IaC 是将基础设施配置声明式维护在版本控制系统中的实践,GitOps 依此模式管理状态配置,并用 PR 管理更改,部署流水线则负责将变更推送到不同环境的运行系统。
关于团队在此模型下的工作,有几点需要注意:
- 开发团队无需为 API 平台团队提交工单来创建 API 配置。也就是说,不需要配置工作的交接。开发团队自助完成配置创建,并通过 PR 发起配置验证,平台团队可以进行审查。合并到主分支后,部署流程自动启动。该模式加快了部署速度,各功能开发团队可以一天多次发布更新,部署 API 配置并快速看到效果。
- 开发团队不使用 API 网关 UI 来更新配置,所有操作均通过版本控制系统完成。此外,开发团队不需要直接访问运行 API 网关的环境,仅需访问环境配置仓库,提升了部署安全性。
- 团队可以访问版本控制系统中所有 API 配置变更的历史。环境变更的完整历史记录保存在版本控制仓库中。配置状态文件完整描述了 API 网关的状态,提交日志说明了状态随时间的演变,为团队提供了清晰的部署文档。回滚配置变更只需执行
git revert并观察部署流程自动执行。版本控制记录既是审计历史,也是环境变更的事务日志,支持任意点的回滚和前滚。
提示
想了解 GitOps 的更多优势,可以阅读 Thomas A. Limoncelli 的文章《GitOps: A Path to More Self-Service IT》(queue.acm.org/detail.cfm?...
GitOps 部署有两种执行方式:推送式部署(push-based)和拉取式部署(pull-based),下面分别介绍。
推送式部署
在这种模式下,每当开发者提交代码到应用仓库时,部署流水线触发,构建应用容器。同时更新配置仓库中的部署清单(deployment manifests)以及 API 网关等配置文件。通常部署清单模板存储在应用仓库,部署流水线基于模板生成实际的清单文件,随后存储到配置仓库。当配置仓库的主线合并变更时,部署流水线触发,将更新后的清单应用到指定环境中的运行系统,如图 9.6 所示。你之前练习的示例场景即采用了推送式部署方法。
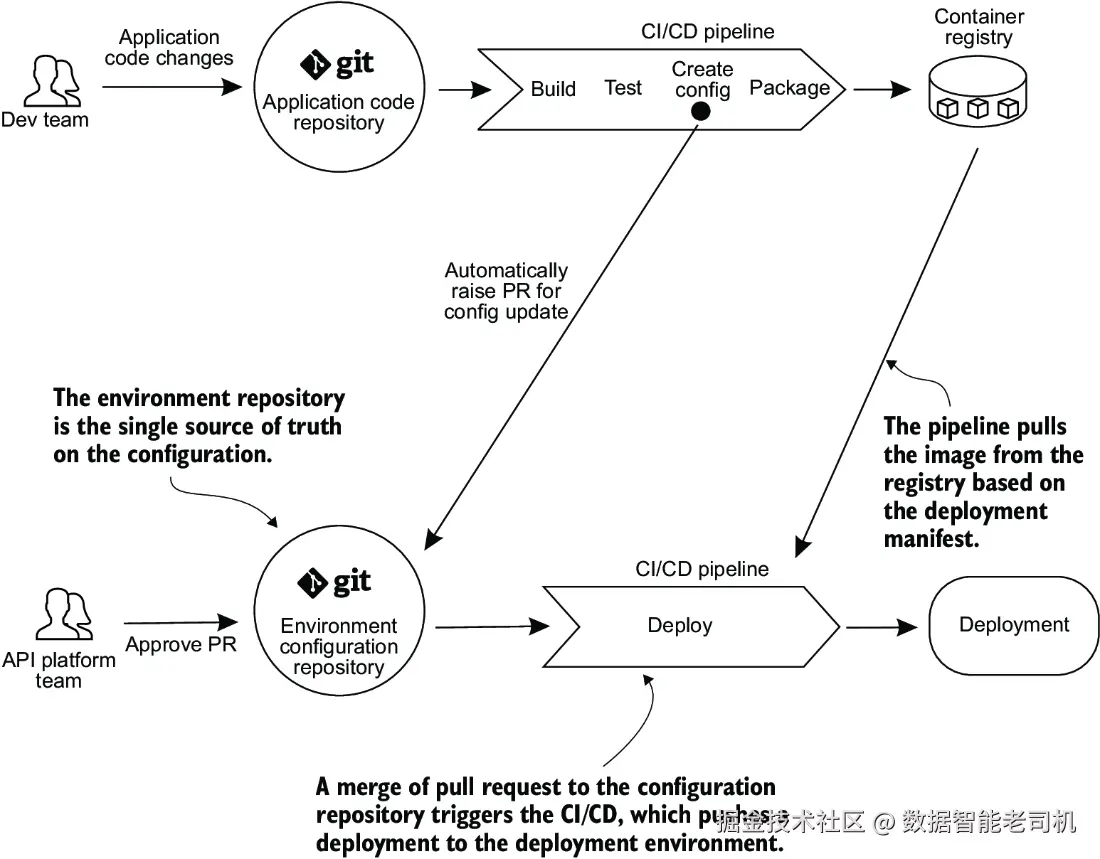
这种方法有两个需要注意的限制。首先,它要求将目标环境的凭据存储在 CI/CD 系统中,以便系统能够访问目标环境并更新那里的配置文件。虽然在某些情况下这是可接受的,但这也可能被视为一个安全隐患,因为如果 CI/CD 系统被攻破,攻击者就可能获得目标环境的凭据。
其次,目标状态的部署仅在环境仓库发生变更时触发。如果有人登录 API 网关的用户界面手动修改配置,配置仓库中存储的目标状态和 API 网关中的实际状态之间就可能出现漂移(drift)。除非设置了持续监控以检测漂移,否则这种差异可能不会被立即发现。例如,我在第一个示例中使用过的 decK 命令行工具就有一个 diff 命令,可以比较正在运行的 Kong 实例中的当前配置状态与指定的目标配置状态文件之间的差异。对于运行在 Kubernetes 集群中的网关,也可以使用 kubectl diff 查看配置差异。
拉取式部署(PULL-BASED DEPLOYMENTS)
采用拉取式部署时,操作器会持续监控 Git 仓库的变化。GitOps 操作器是一种软件工具,持续监控系统状态,并使其与期望配置源(通常是 Git 仓库)保持同步。当操作器检测到差异时------无论是由于期望配置仓库的变更,还是运行系统状态发生变化(例如通过系统 UI 进行的手动配置更改)------它会从 Git 仓库拉取更新后的配置状态,并将其应用到目标环境。操作器运行在与已部署网关相同的环境或集群中,因此不需要凭据访问环境,从而比推送式模型提供了更高的安全性。Kubernetes 环境中常见的此类操作器有 Argo CD 和 Flux。图 9.7 展示了基于拉取的 GitOps 部署示意。
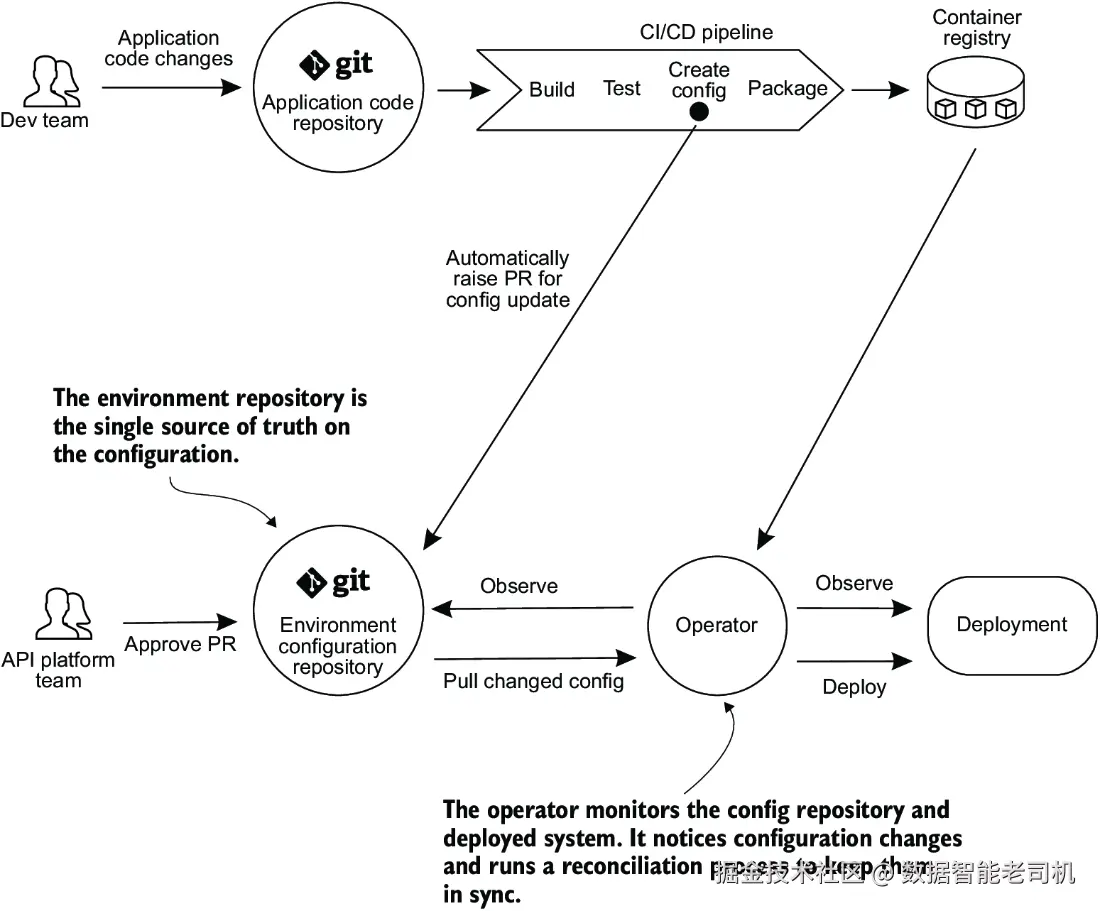
我们已经了解了如何将部署推送到某个环境。接下来,我将讨论 API 如何在多个环境间进行发布推广。
9.4.2 更新应用配置
在企业环境中,通常有许多应用服务,每个服务都有自己的代码仓库。这些服务及其相关的 API 配置需要在多个环境之间进行推广,例如开发环境(Dev)、测试环境(QA)、预发布环境(Staging)和生产环境(Production)。在更新应用配置时,有两个方面需要考虑。
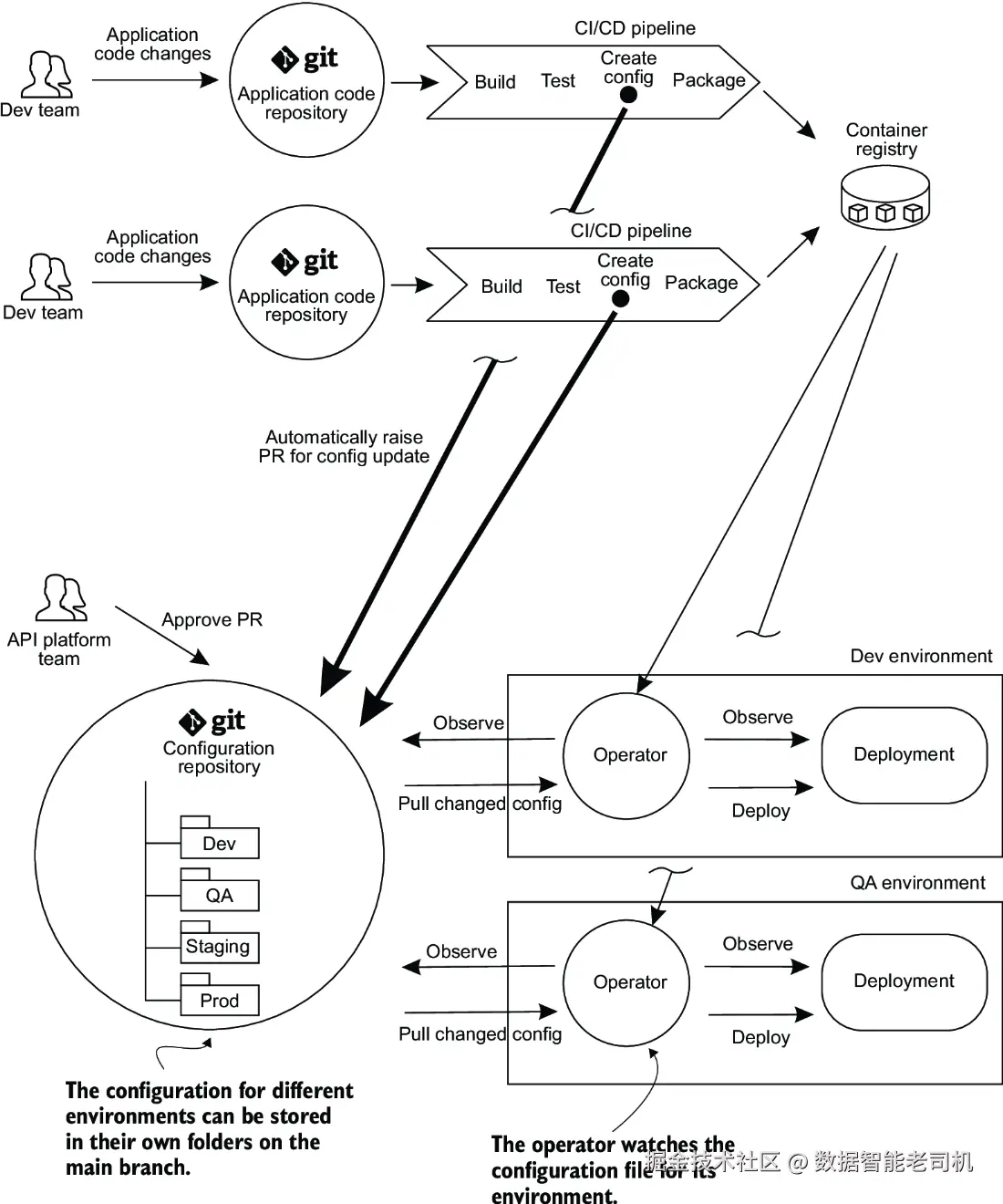
首先,是如何让应用仓库的变更触发配置仓库的更新(例如更新应用配置,在 Kubernetes 场景下,这可能是用更新的容器版本去更新 Kubernetes 的 manifest 文件)。为此,可以在应用仓库中维护应用配置模板,用这些模板生成实际的配置文件和 manifest 文件,再通过自动化的拉取请求(PR)推送到共享的环境配置仓库中。配置仓库包含每个环境所需的应用及基础设施配置。当这些 PR 合并到主分支后,部署流水线就可以将变更发布到对应的环境。
其次,是如何在多个环境之间推广配置。一种方法是为不同环境维护不同的 Git 分支,但这会带来分支间变更追踪的复杂性。更简单的做法是为每个环境维护一个独立的配置文件夹,推广配置时,只需将配置从一个环境文件夹复制到另一个环境文件夹(如图 9.8 所示)。需要注意的是,有些团队可能会选择维护多个不同的配置仓库,而不是使用一个中央配置仓库,这样可以减少不同流水线尝试发起自动化 PR 时的冲突风险。
提示
关于这种方法的更多细节,请参阅 Kostis Kapelonis 的文章《How to Model Your GitOps Environments and Promote Releases between Them》(mng.bz/NRrE)。
我已经讲过 GitOps 的原则、部署模型以及更新配置文件的方法。但和所有有优势的事物一样,GitOps 模型也存在一些缺点。
9.4.3 GitOps 面临的挑战
采用 GitOps 时可能遇到以下挑战:
- 配置仓库上的自动 PR 可能导致冲突
流水线中的 CI 部分会在每次构建新版本应用或应用配置发生变更时,自动向配置仓库发起 PR。随着代码开发的进行,这种情况会很频繁。当多个应用的 CI 流程同时更新同一个配置仓库时,由于不同进程克隆同一仓库时没有同步(本地副本过时,需要先 pull 再重试 push),可能会发生冲突。可以通过设计复杂的 PR 重试机制或拆分配置仓库(例如按命名空间拆分)来减少冲突。 - 管理大量 Git 仓库的负担
与上述问题相关,随着应用和配置仓库数量增加,仓库管理负担也随之加重,因为需要为这些仓库设置正确的访问权限,并与软件同步代理(用于同步集群状态和期望配置状态的软件进程或构建代理)连接。配置这些仓库需要开发时间。可以通过为每个 API 网关集群设立一个配置仓库来缓解。 - 缺少对集中管理 Secrets 的支持
企业环境通常需要在部署流水线之外管理私钥、密码、证书等秘密信息,通常集中存储在可审计的秘密仓库中。GitOps 并没有针对秘密管理提供建议。将秘密存储在源码版本控制系统(如 Git)中不被推荐,因为 Git 的日志会保留持久历史记录,且克隆仓库的开发者都会获得这些秘密,任何有仓库访问权限的人都可以访问秘密。
关于如何缓解这些问题的讨论超出本书范围,但你可以参考 Ádám Sándor 的文章《GitOps: The Bad and the Ugly》(mng.bz/Ddry)了解一些工具...
除了了解 GitOps 可能面临的挑战外,考虑 GitOps 作为一种实践如何适配典型企业中的团队类型也很有用,接下来我们来探讨这个。
9.4.4 APIOps 与团队拓扑
在《Team Topologies》(IT Revolution,2019)一书中,Matthew Skelton 和 Manuel Pais 描述了企业软件组织中的四种基本团队类型:流对齐团队(stream-aligned teams)、平台团队(platform teams)、复杂子系统团队(complicated-subsystem teams)和赋能团队(enabling teams)。以下是每种类型的简要描述:
- 流对齐团队
这些团队专注于单一工作流,构建能够带来客户价值的产品或服务。为了快速交付,他们需要尽可能独立地工作,尽量减少将工作移交给其他团队的情况。流对齐团队是典型的功能团队,负责价值流的端到端交付,包括收集用户需求和反馈、构建软件产品、测试、生产支持及修复缺陷。 - 平台团队
这些团队构建和维护内部平台------自助 API、内部工具、文档和支持------供流对齐团队使用,以更快的速度、更少的协调完成产品或服务交付。平台团队维护的内部平台不直接影响组织的市场竞争力,但能减少流对齐团队的认知负担,提升他们的工作流程。例如维护 API 网关的团队,以及负责身份认证和授权管理系统的团队。 - 赋能团队
由某个技术或产品领域专家组成,支持流对齐团队进行研究和实验,探索能改善其工作流程的新技术和实践。赋能团队帮助流对齐团队克服障碍,发现缺失能力。他们不拥有软件组件,而是作为专家群体,提供指导和辅导。例如帮助演进 API 标准、探索自动化 API 管理工具,并协助团队快速启动 API 开发的 API 治理团队。 - 复杂子系统团队
专注于构建和维护需要深厚专业知识的复杂系统部分,比如算法或人工智能。这些团队成员通常是该子系统领域的专家,承担着减少流对齐团队认知负担的责任。
提示
关于平台定义的讨论,可以参考 Evan Botcher 的优秀文章《What I Talk about When I Talk about Platforms》(martinfowler.com/articles/ta...
应用于 APIOps 工作流时,流对齐团队(之前提到的开发团队)负责按需更新 API 配置(通过 PR)以暴露其 API。平台团队(即 API 平台团队)负责审查并批准 API 配置更改的 PR。他们还负责搭建或指导搭建 APIOps 流水线、配置同步工具和 Operator。平台团队确保 PR 不会因等待审查而停留太久,从而优化流对齐团队的工作流。平台团队还会自动化尽可能多的 API 配置校验(比如配置文件有效性和特定设置检查),内嵌于流水线中。其目标是通过消除审查等待的浪费,缩短整体交付周期。许多代码托管平台提供 PR 统计分析(如 PR 频率和审查时间),这可作为跟踪该价值流部分工作流的有用指标。接下来,我将引导你完成示例流水线中网关配置的部署。
9.4.5 在示例流水线中部署
API 网关的配置定义了 API 的外部路由方式,以及可应用于请求和响应的安全策略、转换和编排。APIOps 倡导采用 GitOps 模式部署 API 配置,流程如下:
- 开发团队在配置版本控制仓库中更新指定环境的 API 网关声明式配置,并提交 PR。
- 对更新的配置文件运行自动校验。API 平台团队审查更改,满意后批准 PR。
- PR 合并后,软件代理运行,将期望配置与运行环境中网关的实际实例进行对齐并应用。
- 应用配置的软件代理可以是推送配置到网关环境的部署流水线,也可以是监控配置 Git 仓库变更的 Kubernetes Operator,检测到变更时拉取并应用配置。
以下章节中,我将展示如何用部署流水线分别在 Kong API 网关和 Kusk API 网关中进行配置对齐。两个示例的流水线均包括以下步骤:
- 部署后端 API 服务
- 对齐网关配置
- 运行 API 一致性测试,验证路由配置已成功应用并符合 API 规范
- 若一致性测试通过,在 API 注册表中标记 API 定义文件通过测试
两种仓库类型
GitOps 模型使用应用代码仓库和环境配置仓库两类仓库。应用代码仓库包含部署后端应用的源码及构建打包所需文件(例如 Dockerfile)。环境配置仓库包含 API 网关配置以及其他基础设施和应用配置(对 Kubernetes 集群来说称为部署清单)。本书中我只用一个仓库,使用 chapter8 和 chapter9 目录组合存放应用代码和环境配置。
第9.4节中,我向你展示了如何以APIOps方式将你的Products API服务部署到API网关。基于之前介绍的概念步骤,下面我将演示如何在Kong网关中完成这项操作。
将配置部署到Kong
首先,在build.yaml文件中,添加清单9.12中的步骤,在运行环境中安装Kong的decK工具。decK(docs.konghq.com/deck)是一个用于声明式管理Kong配置的工具,它可以同步配置到Kong集群,并通过对比配置来检测配置漂移。
清单9.12 在runner中安装decK
bash
- name: Deploy-and-Test - Install Kong Deck
run: |
curl -sL https://github.com/kong/deck/releases/download/v1.18.0/deck_1.18.0_linux_amd64.tar.gz -o deck.tar.gz
tar -xf deck.tar.gz -C /tmp
sudo cp /tmp/deck /usr/local/bin/
deck version接下来,添加一个步骤,通过Docker Compose部署Product API服务。下面清单展示了需要添加到.github/workflows/build.yaml中的代码。
清单9.13 部署Product API服务
bash
- name: Deploy-and-Test - Deploy Products API service
run: |
sed -i "s/OWNER/${{ github.repository_owner }}/g" chapter9/compose-api-service.yaml
cat chapter9/compose-api-service.yaml
docker compose -f chapter9/compose-api-service.yaml up -d然后,添加一个步骤,将chapter9/kong.yaml中定义的Kong网关路由配置应用到网关实例中。该步骤应首先验证配置文件是否有效,然后执行同步流程,将期望配置状态应用到网关。Kong的管理API运行在http://localhost:8001,decK sync命令即与之交互。该步骤代码如下。
清单9.14 同步Kong配置状态
bash
- name: Reconcile API gateway state
run: |
deck validate --state chapter9/kong.yml
deck sync --state chapter9/kong.yml --kong-addr http://localhost:8001接着,添加步骤使用chapter8/run_integrationtest.sh脚本运行集成测试。集成测试验证路由是否正确配置,并校验API是否符合API定义文件。该测试脚本会调用ProductCatalogueEndToEndSchemaTest.java测试,后者从注册表获取最新API定义文件并进行一致性测试。
然后,添加步骤,调用API注册表的REST API,为通过一致性测试的API定义文件打上passed-conformance-test标签。代码如下。
清单9.15 运行API一致性测试
bash
- name: Deploy-and-Test - Run API conformance tests
run: |
cd chapter8
./run_integrationtest.sh
- name: Deploy-and-Test - Mark API definition as passing API conformance testing
run: |
curl -X PUT \
http://localhost:9090/apis/registry/v2/groups/acmeapis/artifacts/productsapi/versions/${{ steps.artifact-version.outputs.ARTIFACT_VERSION }}/meta \
--header "Content-Type: application/json" \
--data '{"labels": ["passed-conformance-test"] }' \
--fail-with-body创建PR并合并更改。合并后,你会看到流水线运行且在集成测试阶段失败,因为此时端点的API网关路由尚未创建。
提示
完整的工作流文件可在示例代码仓库中.github/workflows/build-kong.yaml.completed找到。
现在你准备好创建网关配置了。在Kong配置文件chapter9/kong.yaml中,添加对外部端点路由到后端API服务的配置,如下所示。
清单9.16 Product Catalog API的路由配置
yaml
_format_version: "2.1"
_transform: true
services:
- name: Product_Catalog_API
protocol: http #1
host: product-api #1
port: 8080 #1
path: / #1
routes:
- name: viewProduct
methods: #2
- GET #2
paths: #2
- "~/v1/catalog/products/(.+)$" #2
strip_path: false #2
#1 将请求路由到上游Product API服务docker容器的基础路径 http://product-api:8080/
#2 匹配到此路由的请求会被代理到上游API服务,同时保持匹配的URL路径不变提交该更改并发起PR。以本例为例,你可以直接批准并合并PR。此时流水线将运行通过,因为网关路由已存在。
提示
完成示例请参见示例代码仓库中的chapter9/build-kong.yaml.completed。
此时,你已经更新了API网关配置,使API服务端点对外暴露,并通过decK将变更应用到API网关。接下来,我将展示如何在Kubernetes中运行的Kusk API网关上做类似的操作示例。
部署配置到KUSK
Kusk是一个开源API网关,支持将API配置嵌入到OpenAPI定义文件中。它基于高性能代理Envoy构建,并部署在Kubernetes集群中。在本例中,你将把Kusk部署到Kubernetes集群。
首先,给产品目录API添加Kusk路由。为此,需要在API定义文件 chapter8/apis/product-catalog-api/openapi.yaml 中添加路由配置的x-kusk供应商扩展,如下所示:
清单9.17 在API定义中添加Kusk路由
yaml
...
servers:
- url: https://api.acme-pet-supplies.co.uk
x-kusk: #1
upstream:
service:
name: productsapi-svc
namespace: default
port: 8080
tags:
- name: Categories
...
#1 将x-kusk扩展作为顶层对象添加接下来,需要重写build.yaml工作流文件,使其部署到Kusk而非Kong。在build.yaml文件中,删除上一节中为Kong添加的步骤,然后在"Build - Publish SDK to GitHub Packages"步骤之后,添加安装Kusk CLI的步骤,如下:
清单9.18 在流水线中安装Kusk CLI
yaml
- name: Deploy-and-Test - Install Kusk CLI
run: |
curl -sSLf https://raw.githubusercontent.com/kubeshop/kusk-gateway/main/cmd/kusk/scripts/install.sh | bashKusk网关需要安装在Kubernetes集群中,因此你需要先搭建集群。可以使用minikube(github.com/kubernetes/... Action(github.com/medyagh/set...
添加步骤来设置minikube并安装配置Kusk,示例如下(清单9.19)。需要注意三点:
- 当流水线运行"Install Kusk Gateway"步骤时,可能会出现"resource mapping not found for name: 'kusk-devportal-envoy-fleet'"的错误。这个错误与示例无关,可以忽略,通过
continue-on-error: true继续执行。 - 要向集群中的Kusk网关发送请求,需要设置端口转发,将本地机器(GitHub runner)上的9000端口映射到集群内Kusk网关监听的80端口。
- 后续将部署产品目录API服务容器时,需为Kubernetes提供从容器仓库拉取镜像的凭据(secret),这里通过创建包含GitHub凭据的Kubernetes secret对象实现。
清单9.19 在流水线中安装Kusk网关
yaml
- name: Deploy-and-Test - Start minikube
uses: medyagh/setup-minikube@master
- name: Deploy-and-Test - Install Kusk Gateway
continue-on-error: true
run: |
kusk cluster install
- name: Deploy-and-Test - Setup Kusk port forwarding to port 9000
run: |
nohup kubectl port-forward svc/kusk-gateway-envoy-fleet -n kusk-system 9000:80 &
- name: Deploy-and-Test - Create GitHub Container Registry secret
run: |
kubectl create secret docker-registry ghcr-secret \
--docker-server=https://ghcr.io \
--docker-username=${{ github.repository_owner }} \
--docker-password=${{ secrets.GITHUB_TOKEN }} \
--docker-email=${{ github.event.pusher.email }}接下来,添加步骤将products-api服务部署到集群。需要替换Kubernetes清单文件product-api-deployment.yaml中的变量,使Kubernetes能从容器仓库拉取镜像。如下:
清单9.20 将Products API服务部署到Kubernetes
bash
- name: Deploy-and-Test - Deploy products API service
run: |
sed -i "s/APP_VERSION/${{ github.run_number }}/g" chapter9/product-api-deployment.yaml #1
sed -i "s/OWNER/${{ github.repository_owner }}/g" chapter9/product-api-deployment.yaml #2
kubectl apply --filename chapter9/product-api-deployment.yaml #3
kubectl apply --filename chapter9/product-api-service.yaml #4
#1 替换部署文件中的APP_VERSION变量
#2 替换部署文件中的OWNER变量
#3 将Kubernetes部署对象应用到集群
#4 将Kubernetes服务对象应用到集群然后,使用kusk deploy命令将OpenAPI定义中的API配置部署到Kusk,并检查集群状态以确认pod运行情况,如下:
清单9.21 部署API配置到Kusk
bash
- name: Reconcile API gateway state
env:
LATEST_ARTIFACT_VERSION: ${{ needs.build.outputs.LATEST_ARTIFACT_VERSION }}
run: |
kusk deploy --in http://localhost:9090/apis/registry/v2/groups/acmeapis/artifacts/productsapi/versions/$LATEST_ARTIFACT_VERSION
- name: Deploy-and-Test - Check status of the cluster
run: |
./chapter9/check_cluster_status.sh第7章介绍了Portman和Newman作为一致性测试工具。在一致性测试步骤中,可以使用它们代替之前的Java集成测试。用Portman生成Postman集合,并用Newman运行该集合。若想生成包含请求响应详情的漂亮HTML报告,可以使用newman-reporter-htmlextra(mng.bz/lM5j)作为Newm...
清单9.22 为Kusk添加Portman一致性测试
bash
- name: Deploy-and-Test - Run API conformance tests
run: |
cd chapter9
npm install -g @apideck/portman
npm install -g newman-reporter-htmlextra
npm install -g newman
portman --cliOptionsFile portman/portman-cli.json
newman run collection.postman.json --verbose --reporters cli,htmlextra --reporter-htmlextra-export ../build-output/conformance-test-report.xhtml最后,添加步骤归档测试报告(方便流水线运行后查看),并在测试成功时为API定义文件打上通过一致性测试的标签。示例如下:
清单9.23 在Kusk中标记API文件通过一致性测试
bash
- name: Deploy-and-Test - Archive conformance test report
uses: actions/upload-artifact@v3
with:
name: conformance-test-report
path: |
build-output/conformance-test-report.xhtml
- name: Deploy-and-Test - Mark API definition as passing API conformance testing
run: |
curl --request PUT http://localhost:9090/apis/registry/v2/groups/acmeapis/artifacts/productsapi/versions/${{ steps.artifact-version.outputs.ARTIFACT_VERSION }}/meta \
--header "Content-Type: application/json" \
--data '{"labels": ["passed-conformance-test-kusk"] }' \
--fail-with-body
- name: Mark API definition as passing API conformance testing
env:
LATEST_API_VERSION: ${{ needs.build.outputs.LATEST_ARTIFACT_VERSION }}
run: |
curl -X PUT http://localhost:9090/apis/registry/v2/groups/acmeapis/artifacts/productsapi/versions/$LATEST_API_VERSION/meta \
--header "Content-Type: application/json" \
--data '{"labels": ["passed-conformance-test-kusk"] }' \
--fail-with-body以上即为所有步骤。创建PR并合并更改,观察流水线执行。
流水线运行完成了示例流水线的构建、部署和测试阶段。你已成功将API定义文件转换、存储于API注册表、基于它生成SDK、将API配置部署到网关,并对API进行了测试。
总结
在部署流水线的构建阶段,API定义文件可以被处理和转换,以准备发布到外部。这些转换可能包括过滤OpenAPI定义文件、替换值、对文件中的对象排序等操作。
处理后的API定义文件可以存储在API注册表中,方便部署流水线下游的团队、应用和系统访问。API注册表作为组织API的目录,应提供API接口,支持对API定义制品的程序化访问。
目前存在多种库和代码生成服务,可用于从API定义文件生成SDK。客户端API SDK能够为集成API的团队提供更好的开发体验。SDK包可存储在二进制制品仓库中。
APIOps部署工作流遵循GitOps实践,将配置以声明式方式存储在版本控制中。所有变更通过Pull Request完成,随后由部署流水线或Kubernetes Operator将配置同步到API网关实例。