欢迎关注微信公众号:科技洞察者 📌
今日科技前沿聚焦:OpenAI 在代码生成领域大展拳脚,阿里巴巴的 AI 绘画模型 Qwen-Image 在中文文字渲染上独树一帜,而谷歌 Magenta 则将实时音乐创作带入开源新纪元。
GPT-5:代码生成的新范式
OpenAI 近日发布了一个名为"GPT 5 Coding 编码案例库"的演示仓库,全面展示了其 GPT-5 模型在代码生成方面的惊人实力。

这个仓库不仅是一个技术演示,更是一个未来编程模式的缩影:所有收录的演示应用,从功能完善的网站到交互式界面,乃至小型游戏,都是完全由 GPT-5 根据单个自然语言提示自动生成,全程无需人工编写任何代码。
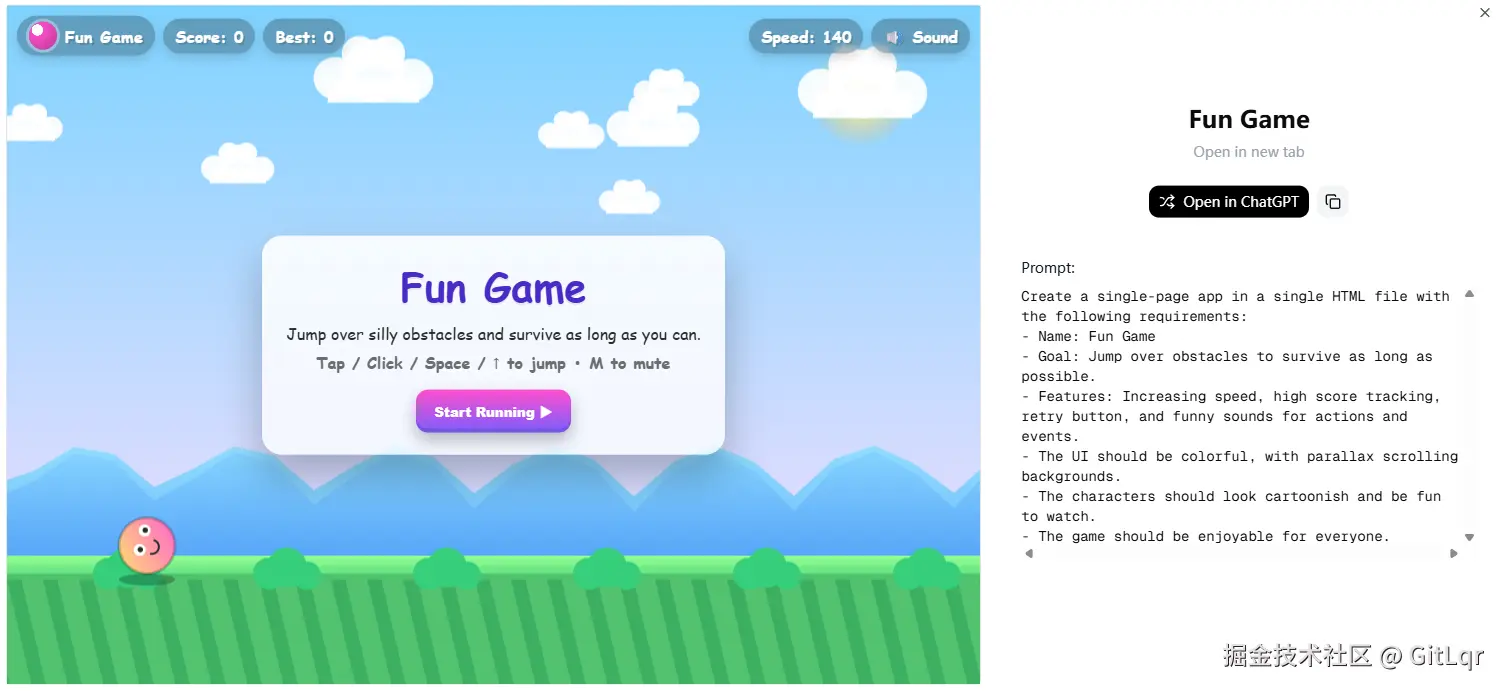
这意味着,你只需用一句人类语言描述你的想法,GPT-5 就能将其转化为可运行的真实网页或应用程序。每个案例都细致地包含了相应的演示和生成该应用所使用的原始提示词,极大地降低了开发门槛,让创意可以直接跃迁为现实。目前,你可以在 gpt-examples.com 探索这些案例,其源代码也已开放托管在 GitHub 的 openai/gpt-5-coding-examples 仓库中。这无疑预示着一场由 AI 驱动的编程效率革命正在加速到来。
GitHub:github.com/openai/gpt-...
Qwen-Image:中文图文生成的里程碑
阿里巴巴最新推出的 200 亿参数 AI 图像生成模型 Qwen-Image,在视觉 AI 领域投下了一颗重磅炸弹。这款模型不仅具备强大的图像生成和精细修改能力,更在"图中文字"渲染方面实现了突破性进展,尤其是在处理中文文本时,展现出前所未有的自然与精准。

卓越的文字渲染能力
Qwen-Image 在中文排版习惯的理解上超越了许多国外模型。它能轻松实现多行文字排布、段落级语义生成与对齐,甚至在小字号、高密度场景下,也能精准还原细节,确保中文文字在图像中的自然融入,而非生硬叠加。无论是中英文混合渲染,还是复杂的文字布局,Qwen-Image 都能游刃有余。

细腻自然的图像编辑
得益于其多任务训练范式,Qwen-Image 在图像编辑方面也表现出色。无论是文字的替换、扩写、删除,还是物体的添加、去除,抑或是风格迁移、光影调节,它都能保持出色的视觉一致性与语义连贯性,不破坏整体画面,效果细腻自然,如同专业设计师手工操作。

全球领先的综合实力
在多项国际权威评测中,Qwen-Image 在图像生成、图像编辑和文本渲染(特别是中文识别率和对齐度)方面均取得了全球领先的成绩,甚至在某些指标上超越了 GPT-4V 等现有模型。
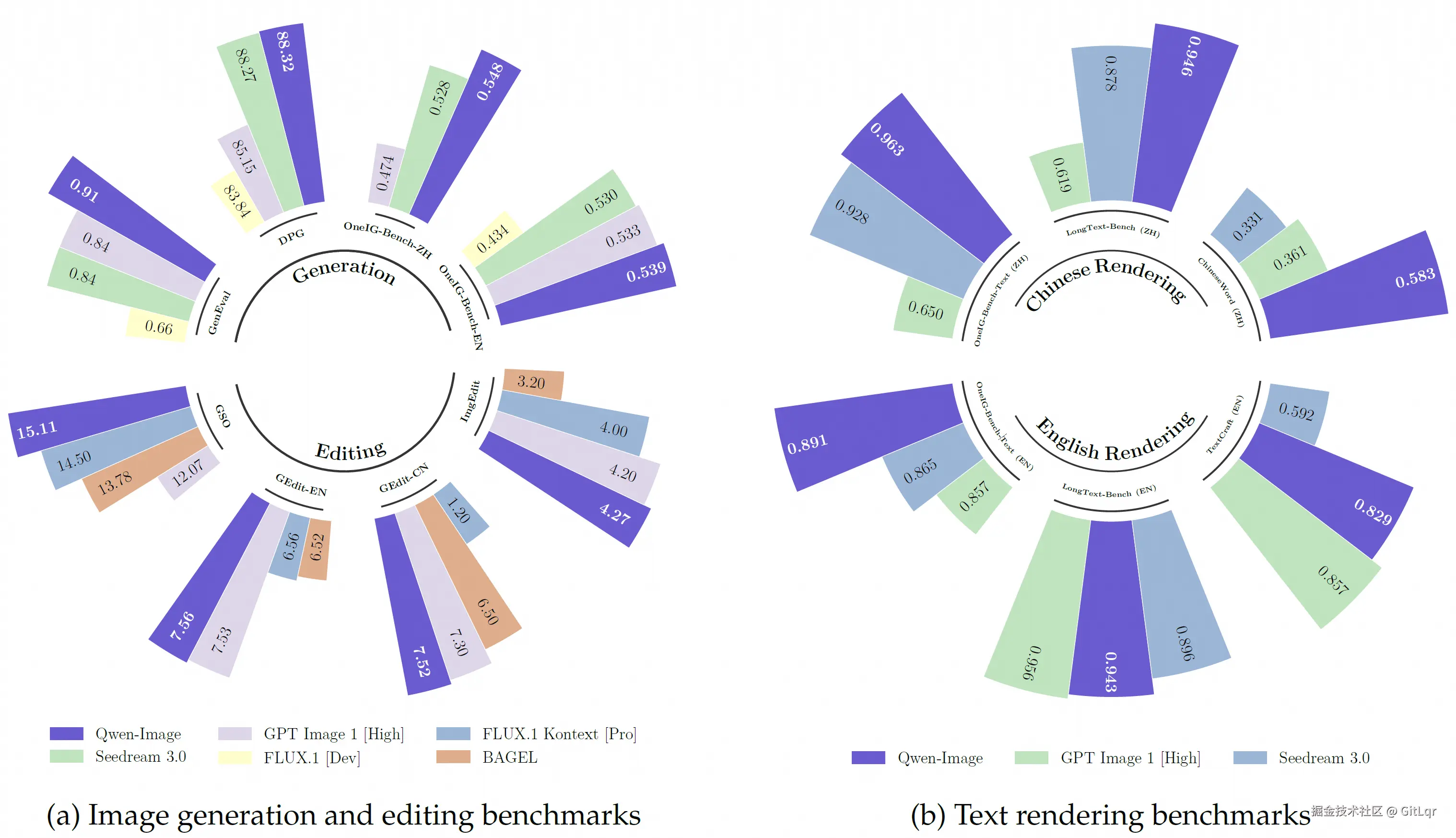
此外,模型还支持写实、动漫、水墨画、科幻等多种风格的图像生成,并具备目标检测、语义分割、深度估计等深度视觉理解能力,为智能图像编辑提供了坚实基础。用户目前已可通过 Qwen Chat 的"图像生成"功能体验到这款强大模型。

GitHub:github.com/QwenLM/Qwen...
HuggingFace:huggingface.co/Qwen/Qwen-I...
Magenta RT:实时音乐创作的开源力量
谷歌 Magenta 项目推出了其首个开源实时音乐生成模型------Magenta RealTime (Magenta RT),旨在为音乐创作者和演奏者带来前所未有的实时互动体验。作为此前 Lyria RealTime 的"开放版",Magenta RT 主要面向研究人员、艺术家和创意开发者,并可在 Colab 免费 TPU 上本地运行。
边想边演的实时互动
Magenta RT 的核心魅力在于其卓越的实时性,它能真正实现"边想边演"。用户在创作和演奏时,可以根据指令、节奏和风格引导,即时切换音乐风格、混合音频样本,并以高质量、无卡顿的 48kHz 立体声输出。这种即时反馈的能力,让音乐创作变得更加流畅和富有探索性。
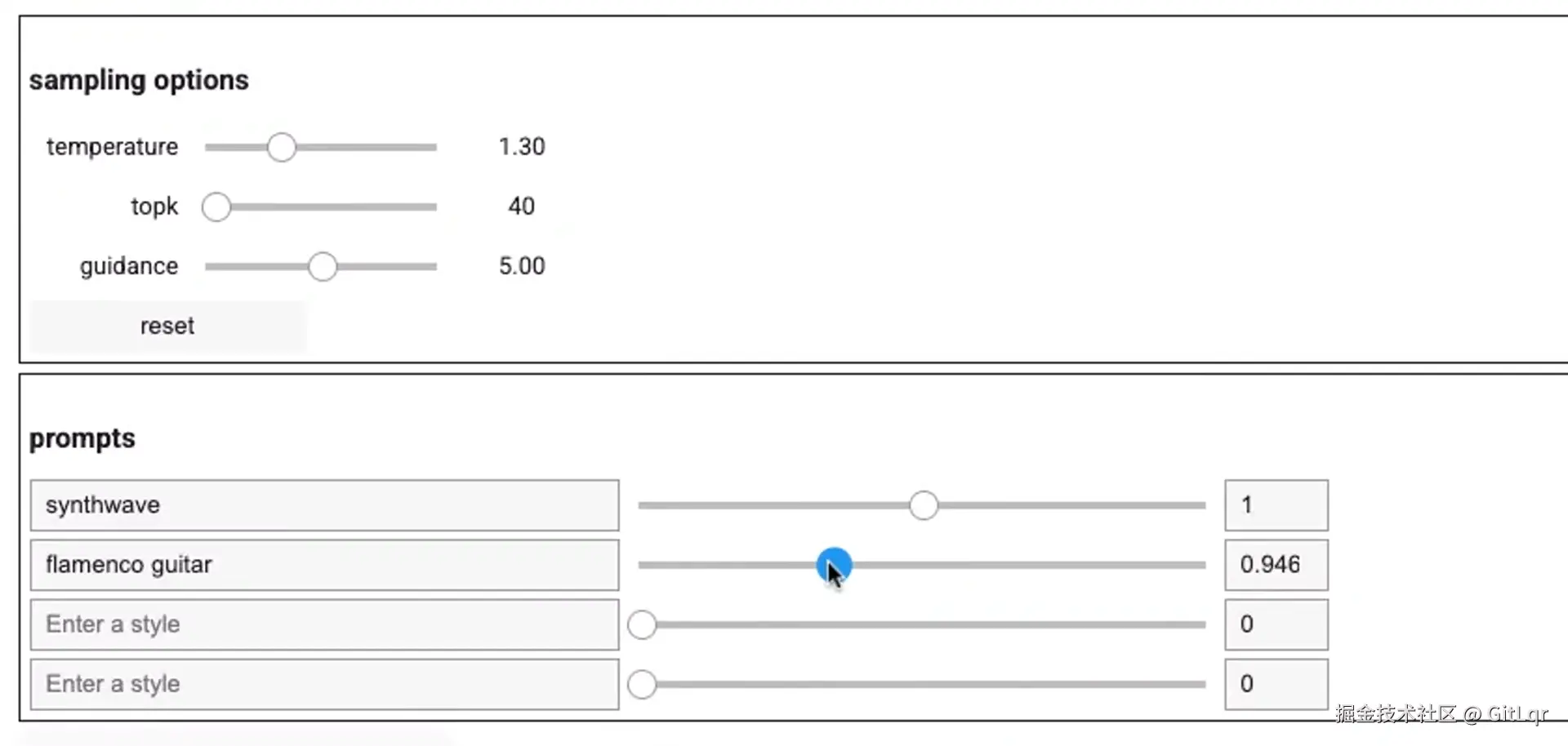
技术突破实现无缝体验
实现这种无缝实时体验的关键在于三个技术突破:首先,生成速度快于播放速度(实时因子大于 1),确保了音乐的即时生成;其次,通过分块自回归技术将音乐切成小块生成,保证了连贯性和可变性;最后,低延迟控制确保用户指令能够迅速响应,带来极致的交互感。
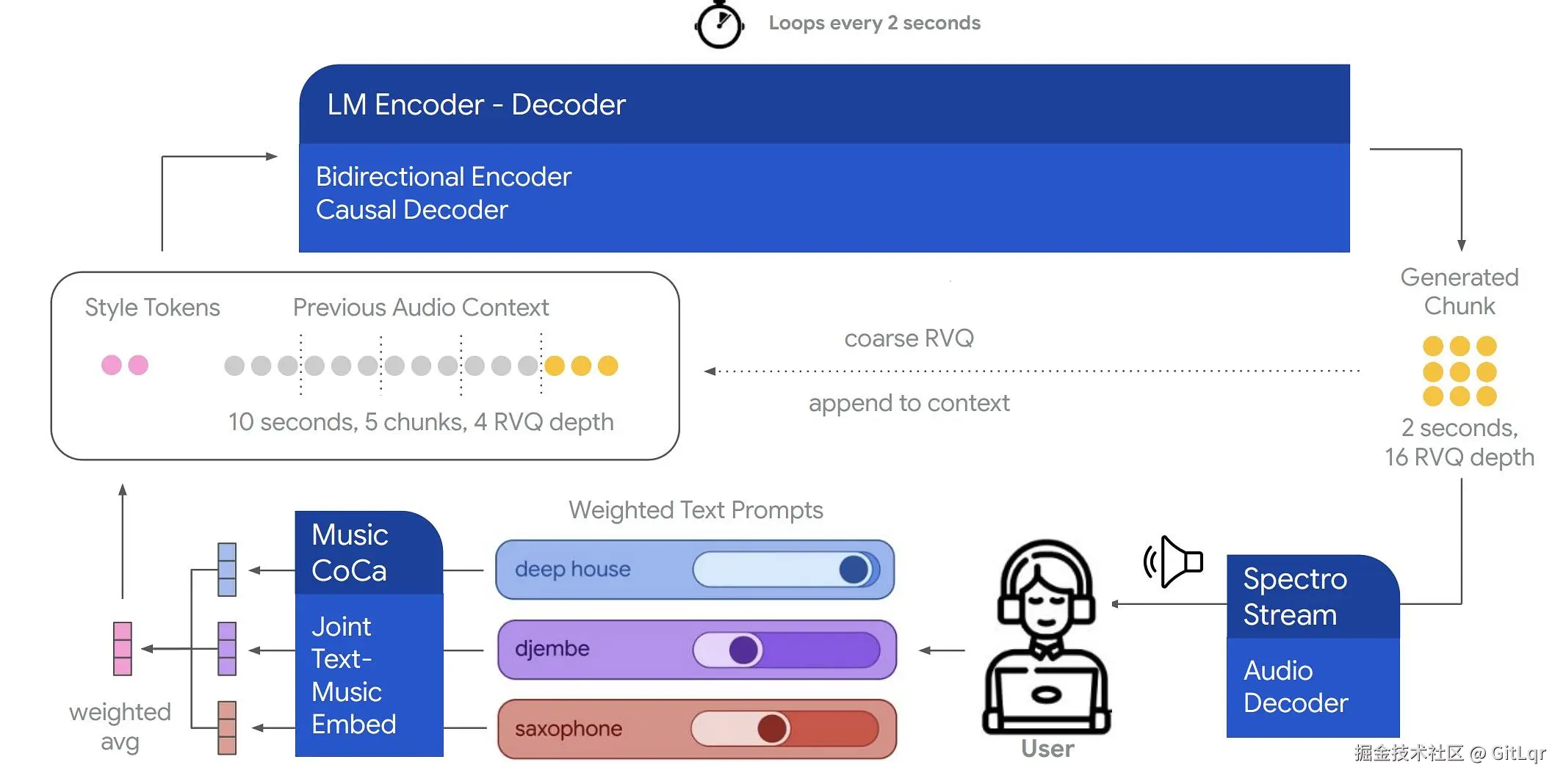
广阔的应用前景
Magenta RT 具有高度交互性、开源可定制性,并支持本地运行和微调,用户可以通过文字或音频提示控制音乐风格,甚至混合多种风格。其应用场景广泛,从音乐风格混搭、即兴探索,到现场表演,乃至游戏或艺术装置的动态背景音乐,都将因 Magenta RT 的出现而变得更加生动有趣。
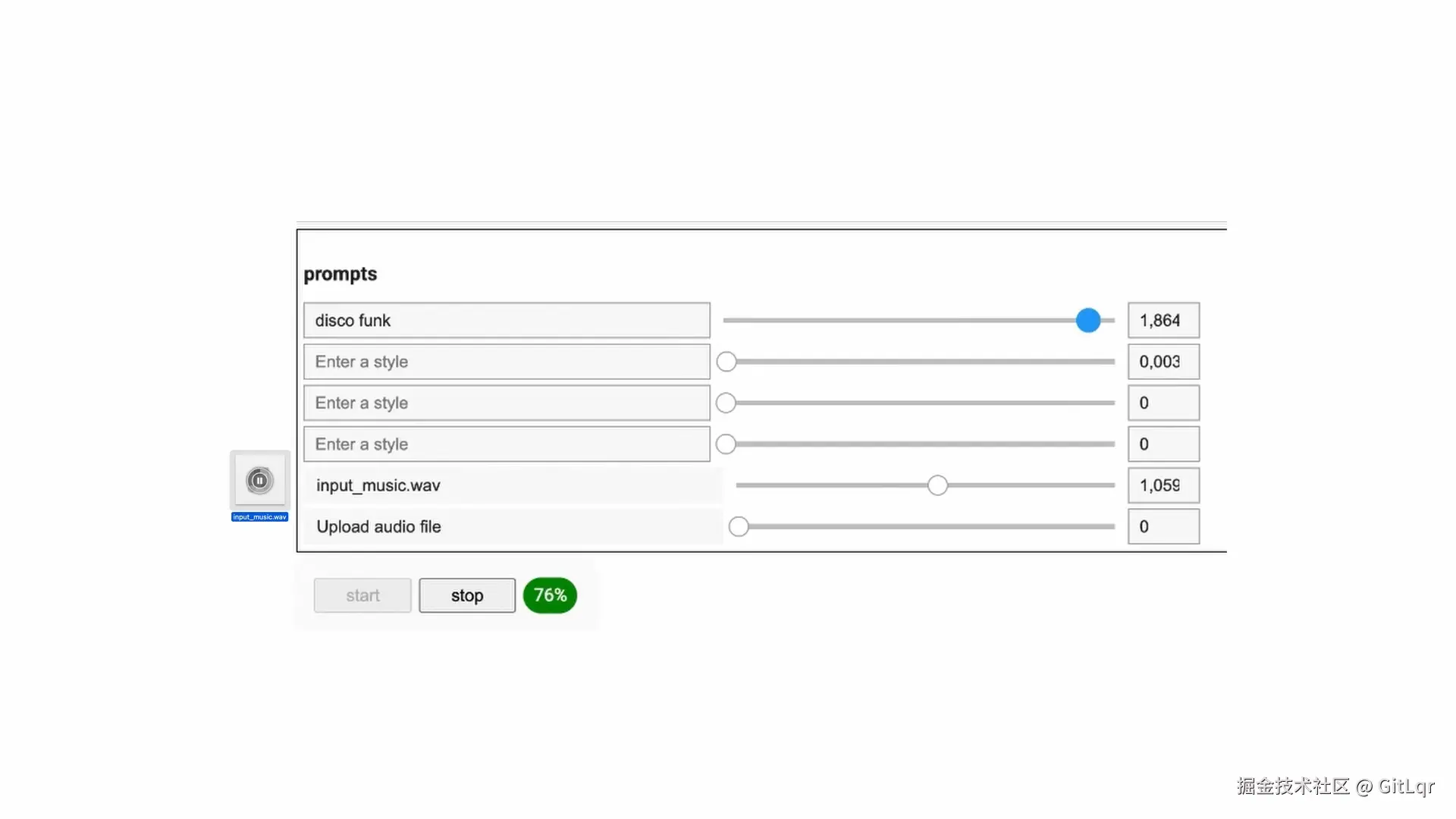
在技术层面,它是一个拥有 8 亿参数的自回归 Transformer 模型,基于 MusicLM 架构改造,并通过 MusicCoCa 模型实现多模态风格控制,利用 SpectroStream 技术进行高保真音频编码。
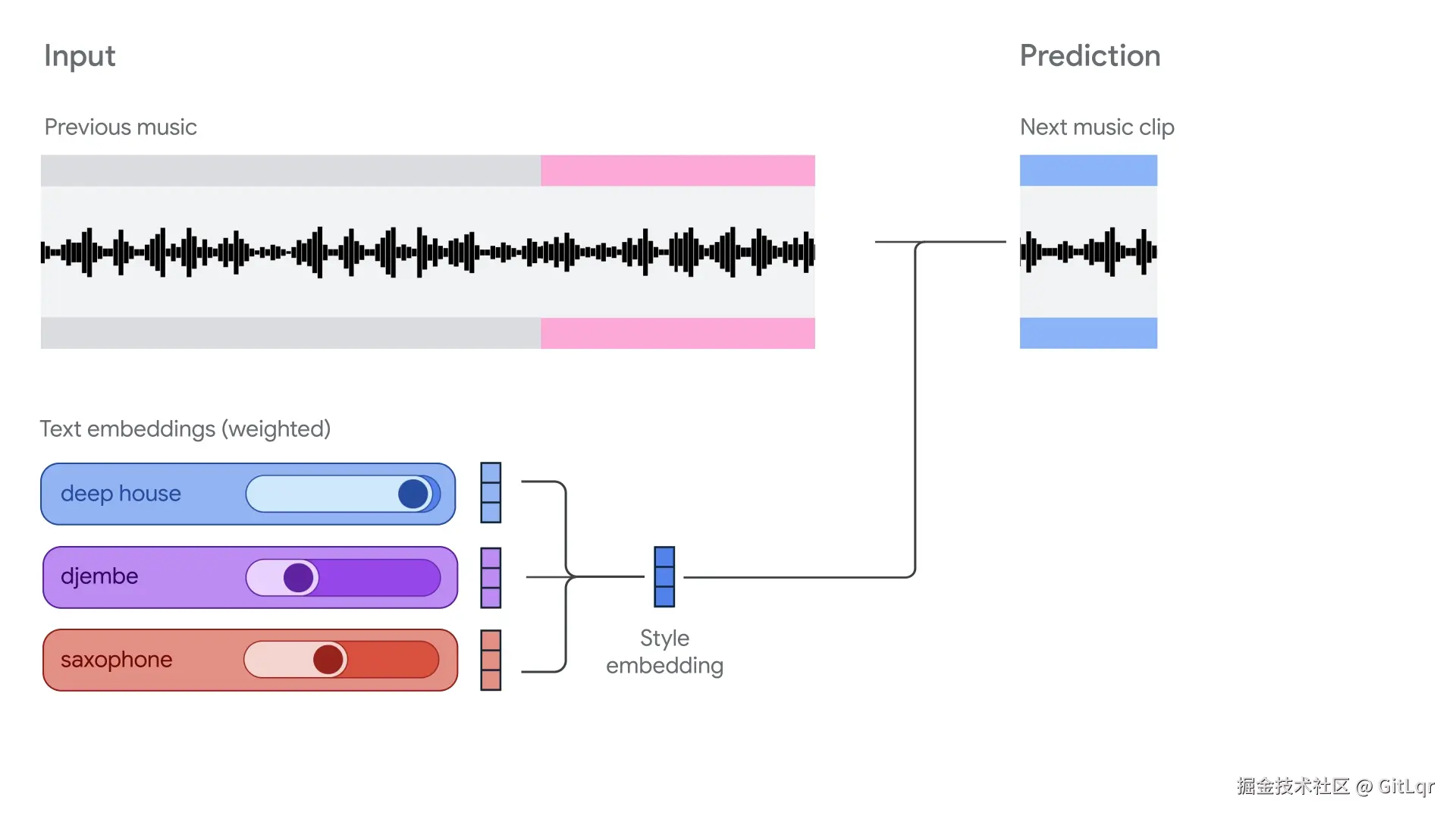
Magenta RT 的发布,无疑将为音乐创作和 AI 艺术领域注入新的活力。
官网:magenta.withgoogle.com/magenta-rea...
GitHub:github.com/magenta/mag...
HuggingFace:huggingface.co/google/mage...
论文:arxiv.org/abs/2508.04...
如果对你有帮助的话,请点赞、分享。关注微信公众号 科技洞察者,第一时间获取 前沿科技讯息,还有 数字人播客、演示视频 等丰富内容,我们下期再见。