论文:Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
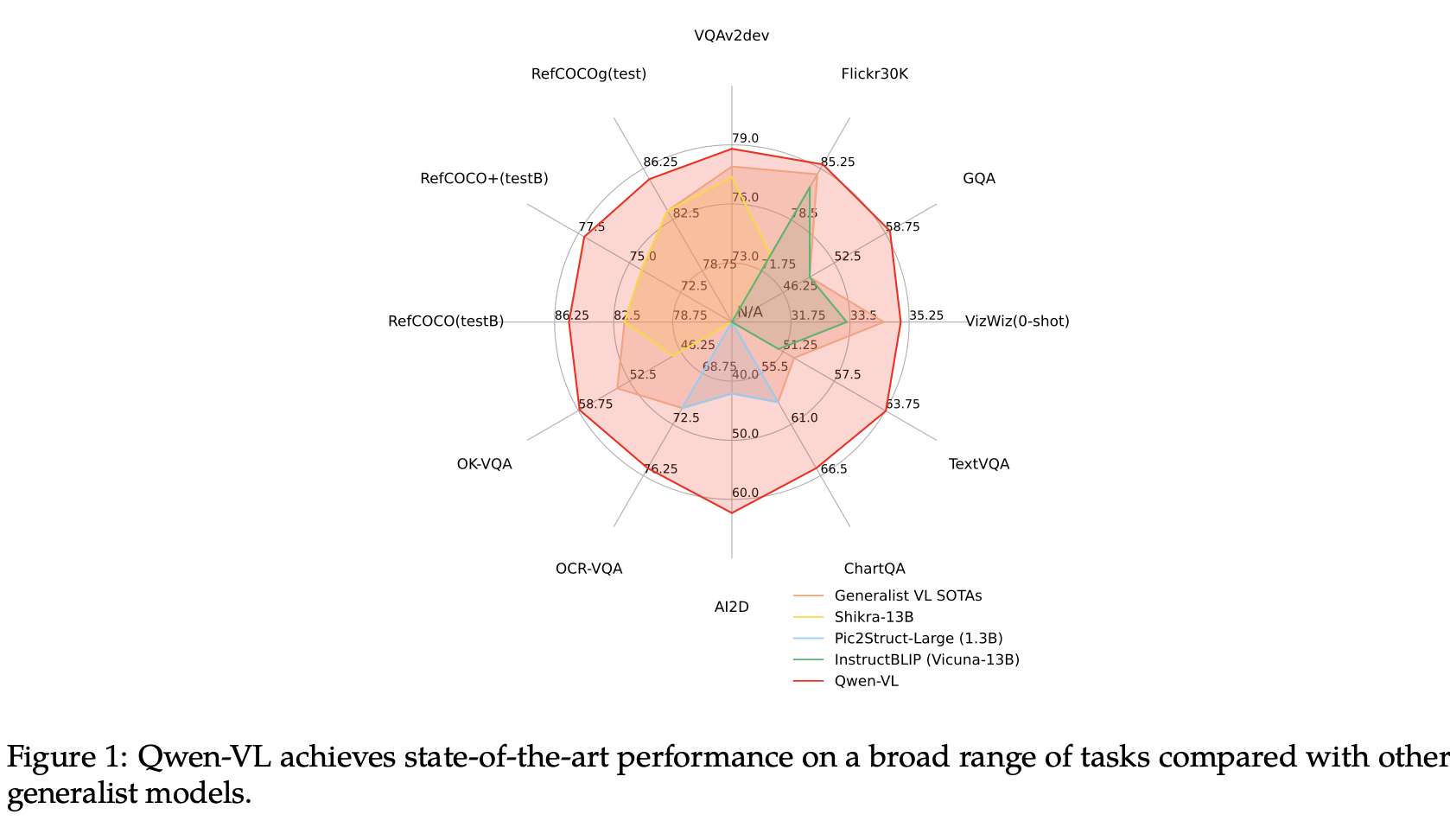
总结:Qwen VL是一种旨在感知和理解文本和图像的大规模视觉语言模型(LVLM)。以Qwen LM为基础,通过精心设计的(i)visual receptor、(ii)input-output interface,、(iii)三阶段训练pipeline和(iv)multilingual multimodal cleanedcorpus赋予它视觉能力。除了传统的图像描述和问答之外,我们还通过对齐image-caption-box来实现Qwen VL的visual grounding和文本阅读能力。
2. Methodology
2.1 Model Architecture
Qwen-VL的网络架构由三部分组成,模型参数的详细信息显示在表1中:

大型语言模型Large Language Model:Qwen VL使用Qwen-7B作为其语言模型,并利用其预训练权重进行初始化;
视觉编码器Visual Encoder:视觉编码器采用ViT架构,使用Openclip的ViTbigG中的预训练权重进行初始化;在训练和推理期间,输入图像都会调整到特定的分辨率。视觉编码器通过将图像分割成步长为14的Patch来处理图像,生成一组图像特征。
位置感知视觉语言适配器Position-aware Vision-Language Adapter:为了缓解长图像特征序列引起的效率问题,Qwen VL引入了一种压缩图像特征的视觉语言适配器。该适配器包括一个随机初始化的单层交叉注意力模块。该模块使用一组可学习的embedding作为query,并使用来自视觉编码器的图像特征作为交叉注意力操作的key。该机制将视觉特征序列压缩到256的固定长度。此外,考虑到位置信息对细粒度图像理解的重要性,2D绝对位置编码被纳入交叉注意力机制的query-key对中,以减轻压缩过程中位置细节的潜在损失。长度为256的压缩图像特征序列随后被输入到大语言模型中。
2.2 Inputs and Outputs
Image Input: 图像通过视觉编码器和适配器进行处理,产生固定长度的图像特征序列。为了区分图像特征输入和文本特征输入,两个特殊标记(<img>和</img>)分别按照图像特征顺序出现在开头,表示图像内容的开始和结束。
Bounding Box Input and Output:为了增强模型对细粒度的视觉理解和定位能力,Qwen-VL训练数据格式涉及区域描述、问题和检测的形式。与涉及图像文本描述或问题的传统任务不同,此任务需要模型准确理解并以指定格式生成区域描述。对于任何给定的边界框,都会应用归一化过程(在[0,1000范围内),并将其转换为指定的字符串格式:"(Xtoplef t,Ytoplef t),(Xbottom right,Ybottom right)"。该字符串是基于文本的,不需要额外的位置符号。为了区分检测字符串和常规文本字符串,在边界框字符串的开头添加了两个特殊标记(<box>和</box>)。此外,为了将边界框与其相应的描述性单词或句子适当地关联起来,还引入了其他特殊标记(<ref>和</ref>),标记了边界框引用的内容。
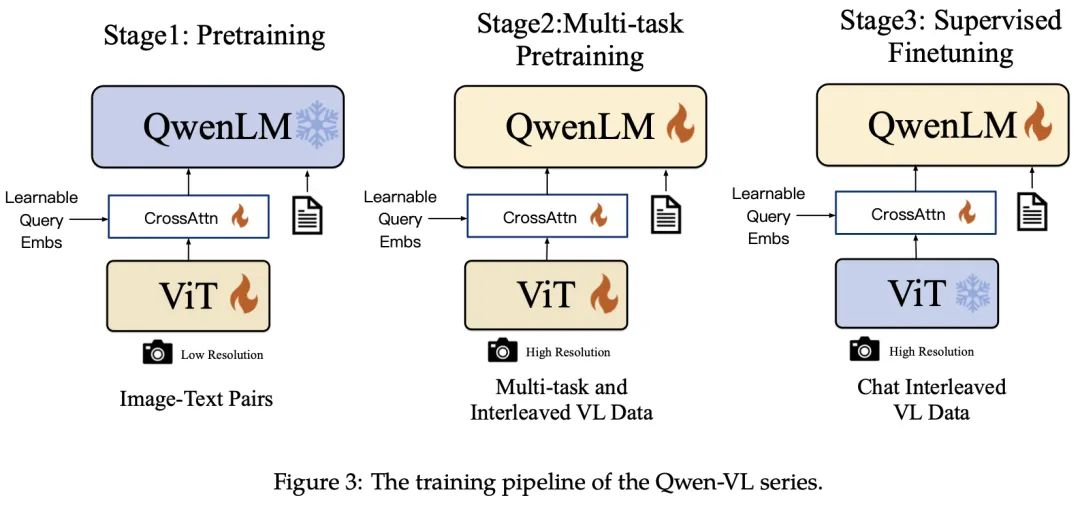
3. Training
如图3所示,Qwen VL模型的训练过程包括三个阶段:预训练的两个阶段和指令微调训练的最后阶段。
3.1 Pre-training
在预训练的第一阶段,我们主要使用大规模、弱标注、网络抓取的图像文本对。我们的训练数据集由开源数据+内部数据组成。
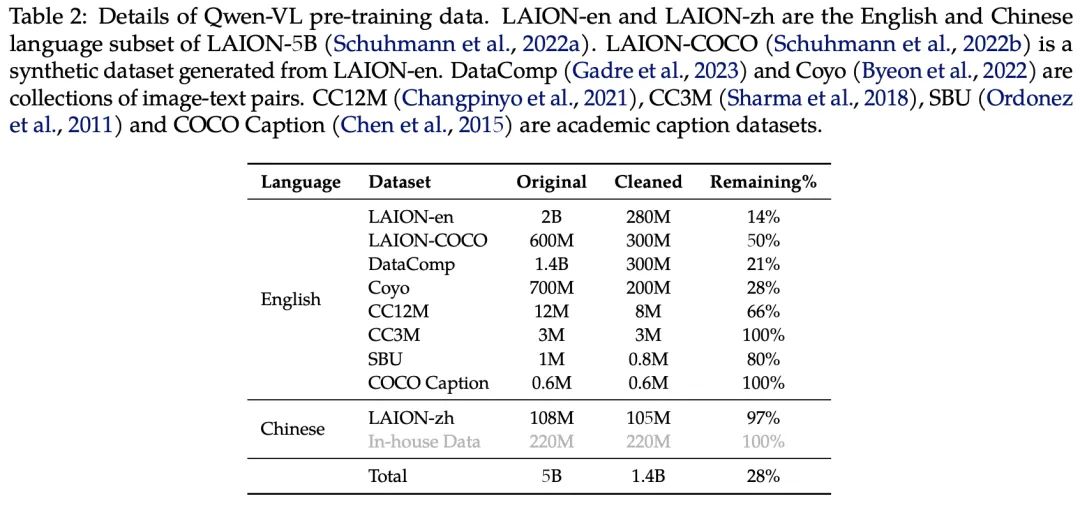
在此阶段,我们冻结了大型语言模型,只优化了视觉编码器和VL适配器。输入图像的大小调整为224×224。训练目标是最小化文本标记的交叉熵。最大学习率为2e-4,训练过程bs大小为30720,整个预训练的第一阶段持续50000步,消耗了大约15亿个图像-文本样本。
3.2 Multi-task Pre-training
在多任务预训练的这一阶段,我们将引入高质量、细粒度的VL Annotation数据,这些数据具有较大的输入分辨率和交互式图像文本数据。
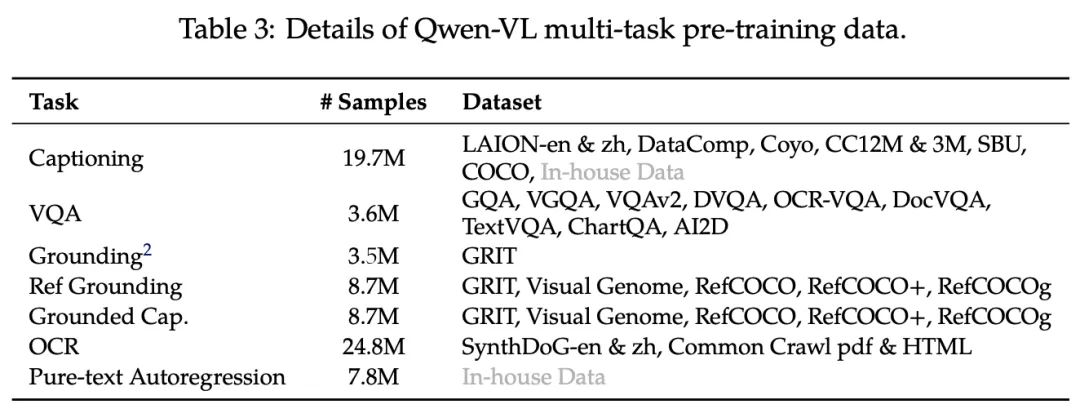
我们将视觉编码器的输入分辨率从224×224提高到448×448,减少了图像下采样造成的信息损失。此外,我们在附录E.3中消融window attention和global attention。最后,模型的所有组件均参与训练。
3.3 Supervised Fine-tuning
在此阶段,我们通过指令微调来微调Qwen VL预训练模型,以增强其指令跟随和对话能力,从而得到交互式Qwen VL-Chat模型。指令调优数据总计350k。在这个阶段,我们冻结了视觉编码器,并优化了语言模型和适配器模块。
4. Evaluation
在本节中,我们对一系列多模态任务进行了全面评估,以全面评估我们模型的视觉理解能力。在下文中,Qwen VL表示多任务训练后的模型,而Qwen VL-Chat表示SFT阶段后的模型。
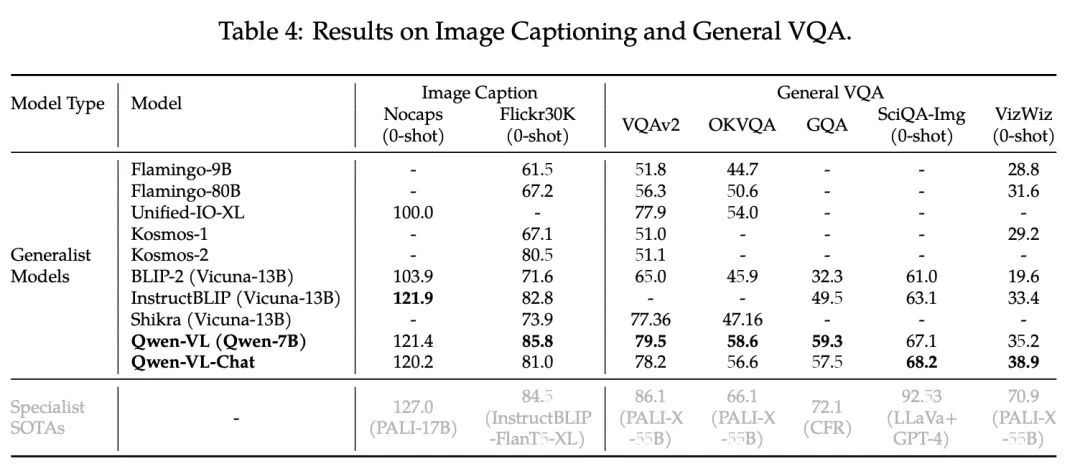
CIDEr是一种通过衡量生成描述与参考描述之间相似性的指标。它基于共识的概念,即如果多个参考描述都包含某些特定的n-gram(n个连续单词的组合),那么这些n-gram在评估生成描述时应该具有更高的权重。CIDEr使用TF-IDF(Term Frequency-Inverse Document Frequency)权重来计算n-gram的权重,以反映它们在参考描述中的重要性和独特性。