主题:持久化 Graph、Multi-Agent 协同
目标:理解如何为图式 Agent 工作流 落盘存档 、跨会话恢复 、长时任务分段执行 ,以及 多智能体共享有状态上下文。
1)为什么要"持久化 + 有状态"?
现实中的 Agent 往往是 长流程:检索 → 规划 → 工具调用 → 人工干预(Human-in-the-Loop) → 复盘总结。没有持久化与有状态协作,会遇到:
- 崩溃或中断 后无法 恢复上下文;
- 多智能体合作 时状态乱飞,难以追踪"谁更新了什么";
- 长时间任务 (持续数小时甚至几天),无法分阶段执行 ,也没法回头查看进度。
LangGraph 用 状态(State) 作为 唯一事实源 ,并允许你为每个字段定义 合并规则 ;再配合 检查点(Checkpointer) 把进度保存到磁盘,就能做到随时恢复、方便回溯、多人协作不乱套。
2)状态建模与合并:唯一事实源与可控覆盖
LangGraph 的 StateGraph 要求你声明一个 State 类型 。你可以对每个字段指定"合并策略",例如对列表使用累加 ,对标量使用覆盖。
python
from typing import TypedDict, List, Annotated
import operator
class ProgressState(TypedDict, total=False):
# "scratchpad" 为追加式合并(List + List)
scratchpad: Annotated[List[str], operator.add]
# "progress" 为后写覆盖(最新值覆盖旧值)
progress: int
# "result" 也是覆盖式
result: str小贴士:
- 追加式字段适合日志、轨迹;
- 覆盖式字段适合进度、最终答案;
- 需要去重时可自定义合并函数来取代
operator.add。
3)持久化基座:Checkpointer(内存 / SQLite)
LangGraph 通过 Checkpointer 把每次节点更新的状态快照写入存储。常用实现:
MemorySaver:内存(调试 / 单进程测试)SqliteSaver:SQLite(本机持久化,推荐入门)- 其他:可扩展到 Redis、Postgres、S3 等(不同包/扩展)
关键用法 :在 compile() 阶段挂上 checkpointer,并在调用时提供 thread_id(会话标识)。
- 同一个
thread_id下,所有更新会被持续记录; - 若中断后再次以相同
thread_id调用,就会在已有状态上继续执行。
4)示例 A:长时间任务的断点续跑
场景:把一个"大任务"分成多批次执行,每批次都落盘;即使中途中断或重启进程,再次运行时会接着从进度继续。
安装:
bash
pip install -U langgraph langchain-core langgraph-checkpoint-sqlite代码:
python
from __future__ import annotations
import sqlite3
import time
import operator
from typing import TypedDict, List, Annotated
from langgraph.checkpoint.sqlite import SqliteSaver
from langgraph.graph import StateGraph, END
# 1) 定义状态(追加式日志 + 覆盖式进度/结果)
class ProgressState(TypedDict, total=False):
scratchpad: Annotated[List[str], operator.add]
progress: int # 0..N,覆盖式
result: str # 覆盖式
chunks: int # 总批次数,覆盖式
# 2) 入口节点:初始化与继续
def start(state: ProgressState) -> dict:
if "progress" not in state:
sp = ["[start] 初始化任务"]
return {"progress": 0, "chunks": 5, "scratchpad": sp}
else:
sp = [f"[start] 恢复任务:进度={state['progress']}/{state.get('chunks', 5)}"]
return {"scratchpad": sp}
# 3) 执行一个"批次"(模拟长耗时)
def run_chunk(state: ProgressState) -> dict:
p = state.get("progress", 0)
total = state.get("chunks", 5)
if p >= total:
sp = ["[run_chunk] 无需执行,已达终点"]
return {"scratchpad": sp}
# 模拟耗时工作(真实工程可替换为检索、解析、OCR等)
time.sleep(0.5)
p += 1
sp = [f"[run_chunk] 完成第 {p}/{total} 批"]
return {"progress": p, "scratchpad": sp}
# 4) 是否完成?未完成则循环回 run_chunk
def check_done(state: ProgressState) -> dict:
p = state.get("progress", 0)
total = state.get("chunks", 5)
if p >= total:
sp = ["[check_done] 已完成全部批次,生成结果"]
return {"result": f"已处理 {total} 批次", "scratchpad": sp}
else:
sp = ["[check_done] 尚未完成,继续执行下一批"]
return {"scratchpad": sp}
# 5) 构图
def build_app():
builder = StateGraph(ProgressState)
builder.add_node("start", start)
builder.add_node("run_chunk", run_chunk)
builder.add_node("check_done", check_done)
builder.set_entry_point("start")
builder.add_edge("start", "run_chunk")
builder.add_edge("run_chunk", "check_done")
# 条件流转:已完成 -> END;未完成 -> run_chunk
def route(state: ProgressState):
return "END" if state.get("result") else "run_chunk"
builder.add_conditional_edges("check_done", route,
{"END": END, "run_chunk": "run_chunk"})
# 挂 SQLite 持久化(断点续跑关键)
conn = sqlite3.connect("checkpoints.sqlite", check_same_thread=False)
checkpointer = SqliteSaver(conn)
return builder.compile(checkpointer=checkpointer)
if __name__ == "__main__":
app = build_app()
thread_id = {"configurable": {"thread_id": "task-42"}}
# 第一次执行:会跑一会儿
out = app.invoke({}, config=thread_id)
print("【输出】", out.get("result"))
print("【轨迹】\n" + "\n".join(out.get("scratchpad", [])))
# 模拟进程重启后再次执行(继续跑剩余批次)
out2 = app.invoke({}, config=thread_id)
print("\n【再次输出】", out2.get("result"))
print("【再次轨迹】\n" + "\n".join(out2.get("scratchpad", [])))
# 也可用 stream 观察过程
print("\n【流式事件(更新)】")
for event in app.stream({}, config=thread_id, stream_mode="updates"):
print(event)看点:
SqliteSaver把每一步状态更新 落盘到checkpoints.sqlite;

- 使用相同
thread_id重入时,直接从上次进度继续;

stream(..., stream_mode="updates")可观察增量更新事件。

5)示例 B:多智能体协作(研究员 ↔ 评审员)+ 持久化
场景:Researcher 生成草稿,Reviewer 审阅并给出修改意见,直到"通过"为止。整个对话上下文与版本演进持续落盘。
代码:
python
import os
import sqlite3
from langgraph.graph import StateGraph, END
from langgraph.checkpoint.sqlite import SqliteSaver
from langchain_openai import ChatOpenAI
from typing import TypedDict, List
# 1. 定义状态(State)类型
class AgentState(TypedDict):
messages: List[str]
# 2. 初始化 LLM
# 替换成你自己的 API Key 或本地模型配置
llm = ChatOpenAI(
temperature=0,
model="glm-4.5",
openai_api_key=os.getenv("ZAI_API_KEY"),
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
# 3. 定义由 LLM 驱动的节点
def researcher(state: AgentState):
"""研究员节点:提出解决方案思路"""
prompt = f"问题:{state['messages'][-1]}\n请给出初步分析和解决思路。"
resp = llm.invoke(prompt)
return {"messages": state["messages"] + [f"研究员: {resp.content}"]}
def reviewer(state: AgentState):
"""评审员节点:对研究员的方案提出改进建议"""
prompt = f"方案:{state['messages'][-1]}\n请指出其中的问题并提出改进建议。"
resp = llm.invoke(prompt)
return {"messages": state["messages"] + [f"评审员: {resp.content}"]}
# 4. 构建 Graph
workflow = StateGraph(AgentState)
workflow.add_node("researcher", researcher)
workflow.add_node("reviewer", reviewer)
# 节点连接
workflow.set_entry_point("researcher")
workflow.add_edge("researcher", "reviewer")
workflow.add_edge("reviewer", END)
# 5. 配置 SQLite 持久化
conn = sqlite3.connect("checkpoints.sqlite", check_same_thread=False)
checkpointer = SqliteSaver(conn)
app = workflow.compile(checkpointer=checkpointer)
# 6. 第一次运行(首次任务)
thread_id = {"configurable": {"thread_id": "task-001"}}
out1 = app.invoke({"messages": ["如何在火星上种土豆?"]}, config=thread_id)
print("=== 第一次运行输出 ===")
for m in out1["messages"]:
print(m)
# 7. 第二次运行(继续任务,保持上下文)
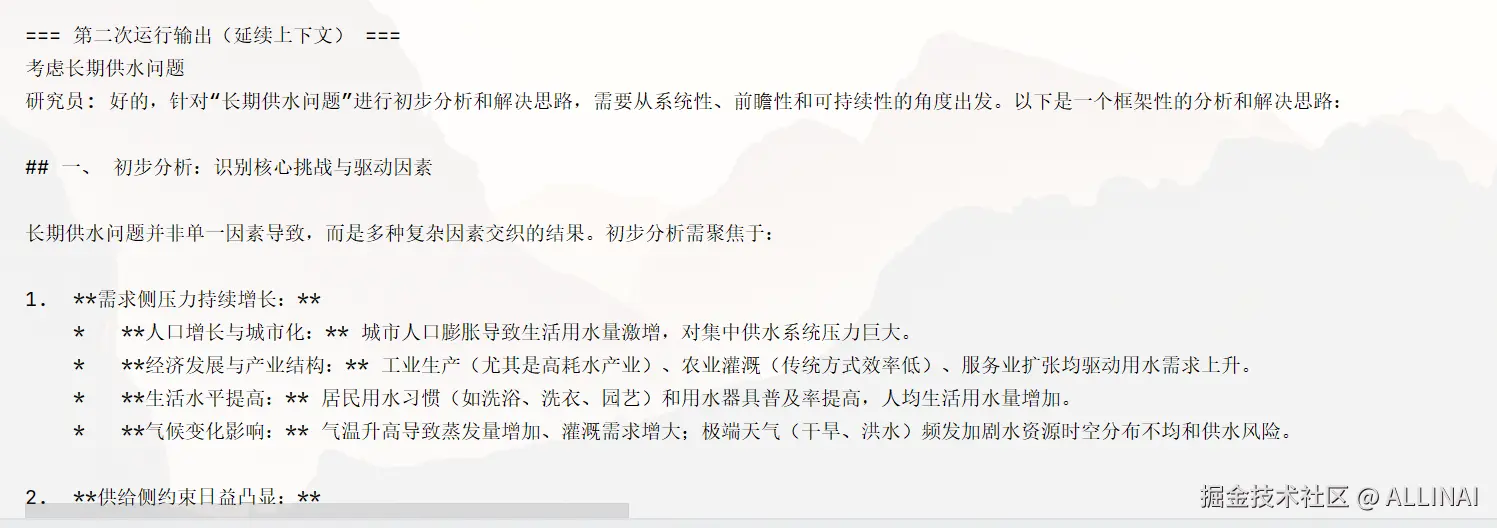
out2 = app.invoke({"messages": ["考虑长期供水问题"]}, config=thread_id)
print("\n=== 第二次运行输出(延续上下文) ===")
for m in out2["messages"]:
print(m)运行效果
第一次运行:

第二次运行(延续第一次的上下文):
6)运行时技巧:分叉与合流、流式观测、线程与会话
-
分叉 & 合流(并行工具)
将状态切分给多个分支(多路检索 / 多模型),各自产出后再在"合流"节点合并:
- 分叉通过多个
add_edge("fork", "branch_i")实现; - 合流节点读取
Annotated[List[Doc], operator.add]等字段,自动汇总来自多分支的结果; - 使用
ainvoke+async def节点可获得并发执行增益(I/O 密集型)。
- 分叉通过多个
-
流式观测(调试/监控)
stream_mode="values":看每个节点产出的值stream_mode="updates":看状态增量更新stream_mode="debug":包含更多执行细节
-
线程 / 会话
- 使用
config={"configurable": {"thread_id": "<id>"}}管理会话与恢复; - 一般把用户会话 、业务订单 、任务ID 映射到
thread_id。
- 使用
示例C:分叉与合流 + 流式观测 + 会话管理
python
import os
from langgraph.graph import StateGraph, START, END
from typing_extensions import Annotated
from typing import List, TypedDict
import operator
from langchain_openai import ChatOpenAI
import asyncio
# ===== 1. 定义 State =====
class State(TypedDict):
question: str
answers: Annotated[List[str], operator.add] # 合流时自动合并
final: str
# ===== 2. 定义节点 =====
llm = ChatOpenAI(
temperature=0,
model="glm-4.5",
openai_api_key=os.getenv("ZAI_API_KEY"),
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
# 接收用户问题
async def receive_question(state: State):
return {"question": state["question"]}
# 分支 1:从"学术视角"回答
async def branch_academic(state: State):
prompt = f"从学术角度用简短的一句话回答这个问题:{state['question']}"
resp = await llm.ainvoke(prompt)
return {"answers": [f"[学术视角] {resp.content}"]}
# 分支 2:从"通俗视角"回答
async def branch_casual(state: State):
prompt = f"用通俗易懂简短的一句话回答这个问题:{state['question']}"
resp = await llm.ainvoke(prompt)
return {"answers": [f"[通俗视角] {resp.content}"]}
# 合流:汇总两个视角的回答
async def merge_answers(state: State):
merged = "\n".join(state["answers"])
return {"final": merged}
# ===== 3. 构造 Graph =====
builder = StateGraph(State)
builder.add_node("receiver", receive_question)
builder.add_node("academic", branch_academic)
builder.add_node("casual", branch_casual)
builder.add_node("merge", merge_answers)
# 分叉:receiver -> academic & casual
builder.add_edge(START, "receiver")
builder.add_edge("receiver", "academic")
builder.add_edge("receiver", "casual")
# 合流:academic & casual -> merge
builder.add_edge("academic", "merge")
builder.add_edge("casual", "merge")
builder.add_edge("merge", END)
app = builder.compile()
# ===== 4. 演示流式运行 =====
async def run():
thread_id = "demo-thread-1" # 会话/任务ID
# 流式观测:每次状态更新都会输出
async for event in app.astream(
{"question": "黑洞是如何形成的?"},
config={"configurable": {"thread_id": thread_id}},
stream_mode="debug"
):
base_msg = f"{event['timestamp']} | {event['payload']['name']} | "
if event['type'] == 'task':
base_msg += f"Input:{event['payload']['input']}"
elif event['type'] == 'task_result':
base_msg += f"Result:{event['payload']['result']}"
print(base_msg)
print("\n=== 最终结果 ===")
result = await app.ainvoke(
{"question": "黑洞是如何形成的?"},
config={"configurable": {"thread_id": thread_id}}
)
print(result["final"])
if __name__ == "__main__":
asyncio.run(run())运行效果
流式观测可能输出:

最终结果:

7)工程化建议清单
- 字段合并策略先行 :日志/轨迹用追加 ,快照/指标用覆盖,必要时自定义合并函数做去重与裁剪。
- 粗细分层的持久化 :开发期
MemorySaver,上线用SqliteSaver或更强的存储(备份/审计/多副本)。 - 可恢复的长任务 :将长流程拆成小分段(批次),每段落盘,并在节点内识别"已处理进度"。
- 并行 + 合流 :对高延迟工具(检索/解析)进行多路并行 ,在合流节点做去重/排序/rerank。
- 流式与回放 :用
stream()做调试;必要时将更新事件写入日志系统,形成可回放的运行史。 - 人机协作:在循环节点中检测"待人工输入"状态,把外部反馈更新到状态后继续推进。
- 幂等与重试 :节点函数尽量幂等(同输入重复执行结果一致),便于重放与恢复。
🔚 小结
- 用 State + 合并规则 把图的"唯一事实源"收拢到一处;
- 用 Checkpointer 落盘,让 Agent 可恢复、可审计;
- 把长时任务拆批 +落盘进度 ,把多智能体共享状态 +清晰路由;
- 利用 并行分叉 / 合流 、流式观测 与线程会话,让复杂工作流真正可控。
接下来我们将从零实现把 Chain/Graph/Agent 暴露为 HTTP 服务。