Situation
前几天遇到一个线上问题反馈,用户的某一个文件访问对应的页面时,加载不出来,其他文件都没有问题,拿到这个文件后一看,大概知道了原因,文件名称包含了 % ,name作为query参数拼接到了url后面,name没有做编码,导致浏览器自动解码时遇到 % 报错,结果给用户的表现就是页面空白,啥也没有。
js
decodeURIComponent('%');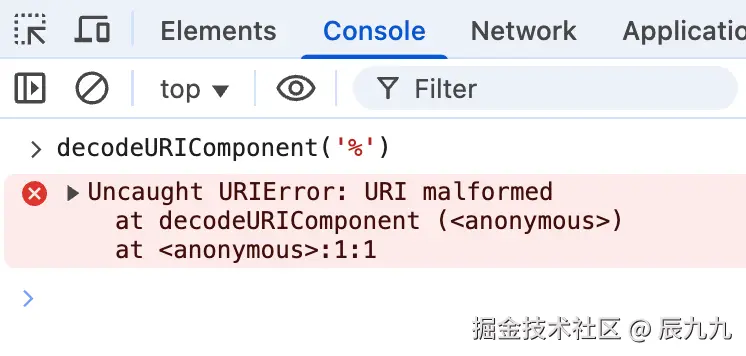
运行后,浏览器抛出错误:
js
Uncaught URIError: URI malformed这是因为 % 在 URL 编码中有特殊意义,而 decodeURIComponent 解析时会严格按照 百分号编码规则 来处理。
URIError 是 js 的内置错误类型,表示 URI 相关的错误。在解析 URI 编码时,如果遇到非法格式,就会抛出这个错误
Action
如何解决这个问题呢?
1、凡是query中字符串可能存在 % 等特殊字符的情况下,都需要encode编码后再传参
js
name: encodeURIComponent(name)同时,在接收方解析url的query参数时,需要使用try catch包裹,避免代码报错阻塞后续流程进行。但这只是容错方式,并不是根本解决办法,比如上述线上问题还是需要编码query参数才能解决,因为报错在浏览器自动decode解码环节,代码还没执行到接收方呢
js
function safeDecodeURIComponent(str) {
try {
return decodeURIComponent(str);
} catch (e) {
console.warn('非法 URI 编码:', str);
return str;
}
}2、使用标准 API 解析参数
URLSearchParams 是浏览器提供的一个内置 Web API,专门用来操作 URL 的query参数,可以帮我们解析、获取、设置、删除、遍历 URL 的参数,而不需要自己手写 split('?')、split('&') 这种容易出错的代码
js
const params = new URLSearchParams(location.search);
console.log(params.get('name'));decodeURI和decodeURIComponent
| 特性 | decodeURI | decodeURIComponent |
|---|---|---|
| 解码范围 | 解码整个 URI,但不会解码保留字符(?、&、#、= 等) | 解码 URI 组件,所有非字母数字和保留字符都会被解码 |
| 作用目标 | 用于解析完整 URL 字符串 | 用于解析 URL 的片段(如 query 参数值) |
| 是否保留结构 | 会保留 URL 的结构,不会破坏参数分隔符 | 可能会解码结构字符,从而破坏 URL 格式 |
| 输入 | example.com/search?q=%E... | %E4%BD%A0%E5%A5%BD |
| 输出 | example.com/search?q=你好 | 你好 |
开发过程中需求是解析query参数&保留特殊字符,所以基本都是使用的decodeURIComponent
Result
遇到 Uncaught URIError: URI malformed,不要只是 try-catch 一下了事,而是应该:
- 确认数据源是否正确编码
- 区分 decodeURI 与 decodeURIComponent
- 对外部数据加防御性解析
只要保证 URL 里 path字段没有裸%,就不会有 URIError。
参考
URIError:developer.mozilla.org/zh-CN/docs/...
URLSearchParams:developer.mozilla.org/zh-CN/docs/...