不知道你是否也有同感?
当前对于大语言模型编码能力的评测,越来越像是一场追求创意与视觉效果的"军备竞赛" 。
从万年不变的贪吃蛇小游戏,到在旋转超立方体中弹跳的小球,再到号称能"徒手搓出一个《我的世界》"。
这些案例固然能在第一眼时带来"哇"的视觉震撼,但它们真的能代表模型解决现实编码问题的能力吗?
或许,只有这种视觉上的奇观,才能让不具备编程背景的普通读者,最直观地感受到 AI 编码能力的飞跃吧。
然而,我们必须清醒地认识到,编程的最终目的,不是为了交付一张漂亮的设计稿或一个封闭的单机应用。它的核心,是用严谨的代码逻辑来驱动真实的业务运转。
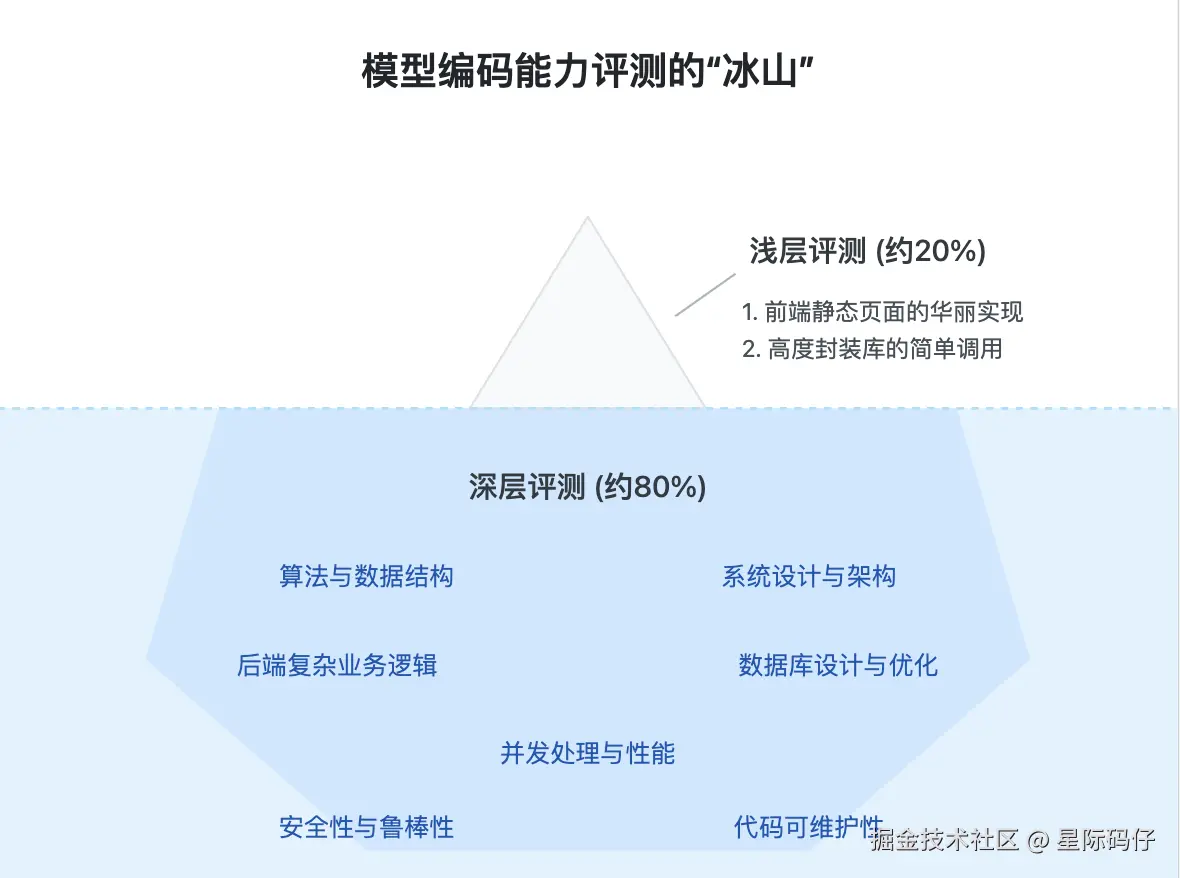
因此,我们甚至可以大胆地断言,如今市面上绝大部分对于模型编码能力的评测,都还停留在两个浅层维度:
- 对前端静态页面的华丽实现。
- 对高度封装的前端库的简单调用。
这种评测方式,就如同管中窥豹,只见一斑。它仅仅触及了冰山浮于水面的一角,而水下真正庞大而关键的部分,比如代码逻辑的严谨性、系统设计与架构、以及安全性和健壮性等,却被完全忽略了。
跳出窠臼:回归软件工程的本质
在这种背景下,我希望能够跳出当前主流评测方式的窠臼。
为此,我构思了一种更贴近真实软件开发流程、更能客观衡量一个 AI 模型真实编码能力的评测框架。
简单来说,我的评测框架遵循三大原则:轻UI、重逻辑、避俗套。
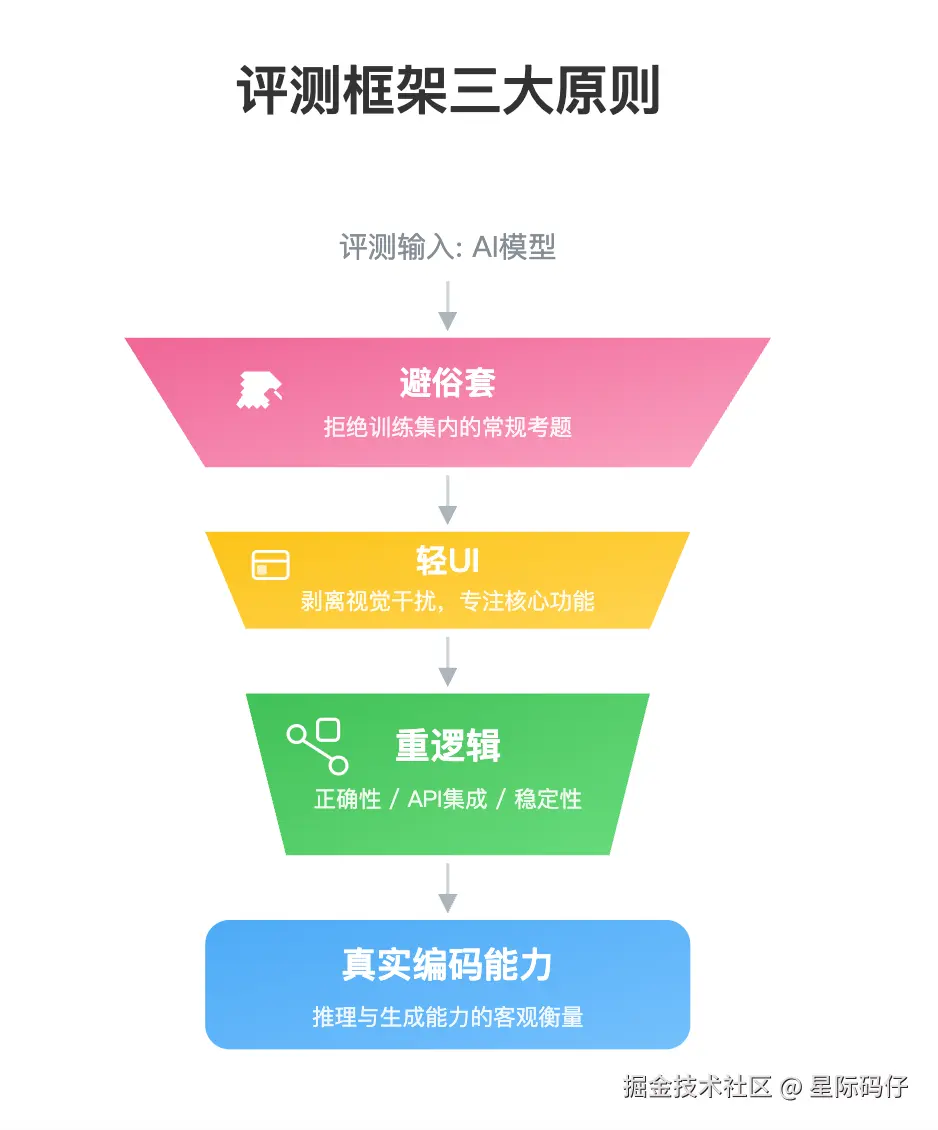
- 轻UI:不追求华丽的视觉效果,只验证最基本的前端交互能力。
- 重逻辑:将重点放在代码逻辑的正确性、外部 API 的集成能力以及系统的稳定性上。
- 避俗套:拒绝使用那些"烂大街"的案例。因为这些案例很可能早已成为大模型训练语料的一部分。在这种情况下,检验的或许只是模型的"记忆力",而非真正的"推理与泛化生成能力"。
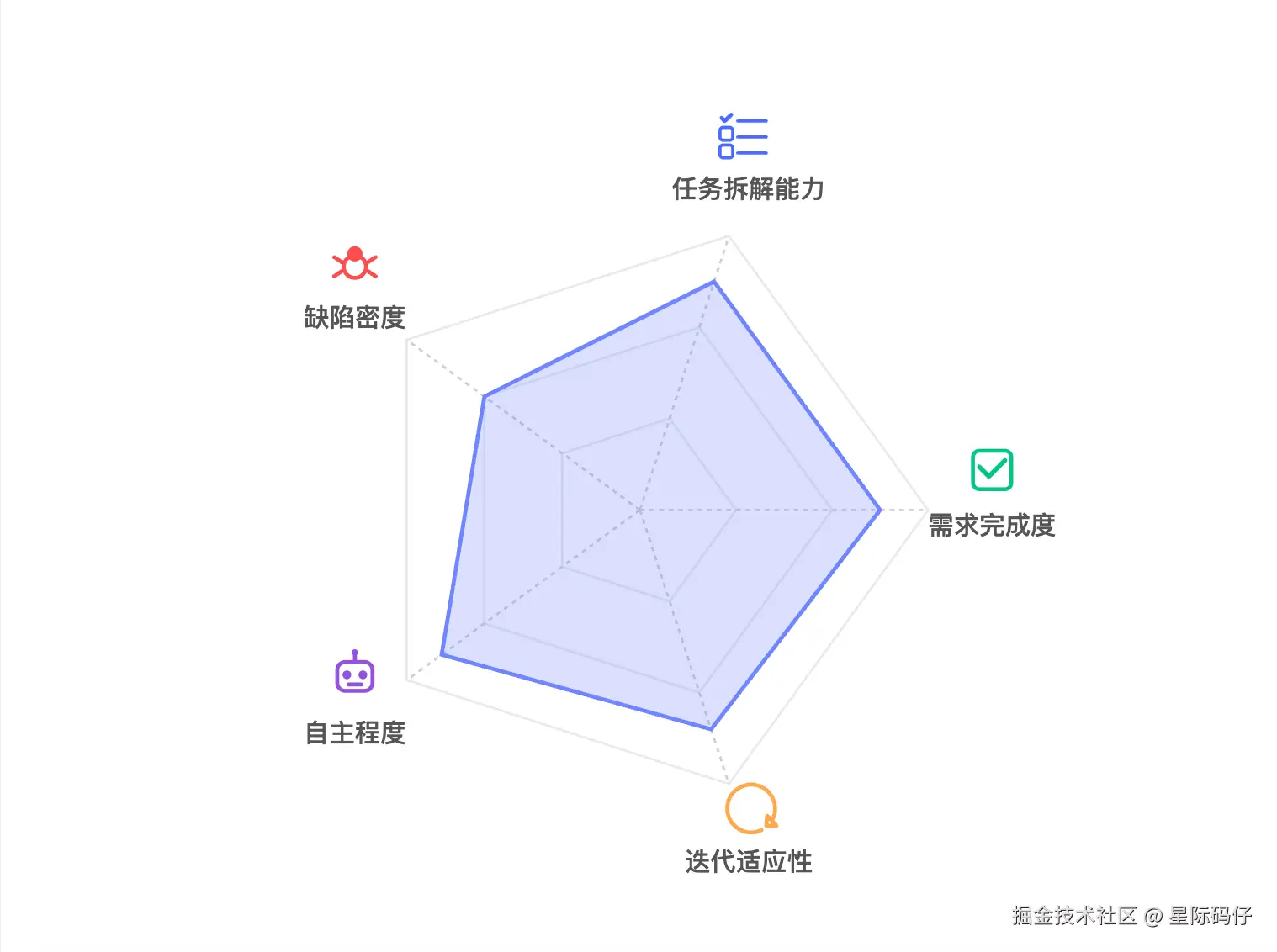
基于这三大原则,我建立了一个五维评测模型。它将从任务拆解能力、需求完成度、缺陷密度、迭代适应性、自主程度这五个方面,对 AI 模型的编码能力进行一次全面的考核。
有趣的是,基于这个模型,我对前段时间备受瞩目的 GLM-4.5 进行了一轮评测,但得到的结果,似乎与外界的普遍赞誉相去甚远。
在展开详细的评测过程之前,我会先阐述我基于这五个维度构建评测模型的灵感来源。
如果你想直接看结果,可以跳到「评测结果速览」这一章节。
五维评测模型:一套更科学的"考纲"
当前,AI 编程工具的发展,正在涌现出一种新的趋势,就是会把现实世界的软件开发流程,映射到 AI 编程工具的执行流程中。
比如 Kiro 提出的"规范驱动开发"范式,便是一个很好的例子。
受此启发,我也基于现实世界的开发流程,构建了这套多维度评估模型。
1.任务拆解能力
这映射的是软件开发中的"需求分析"阶段。
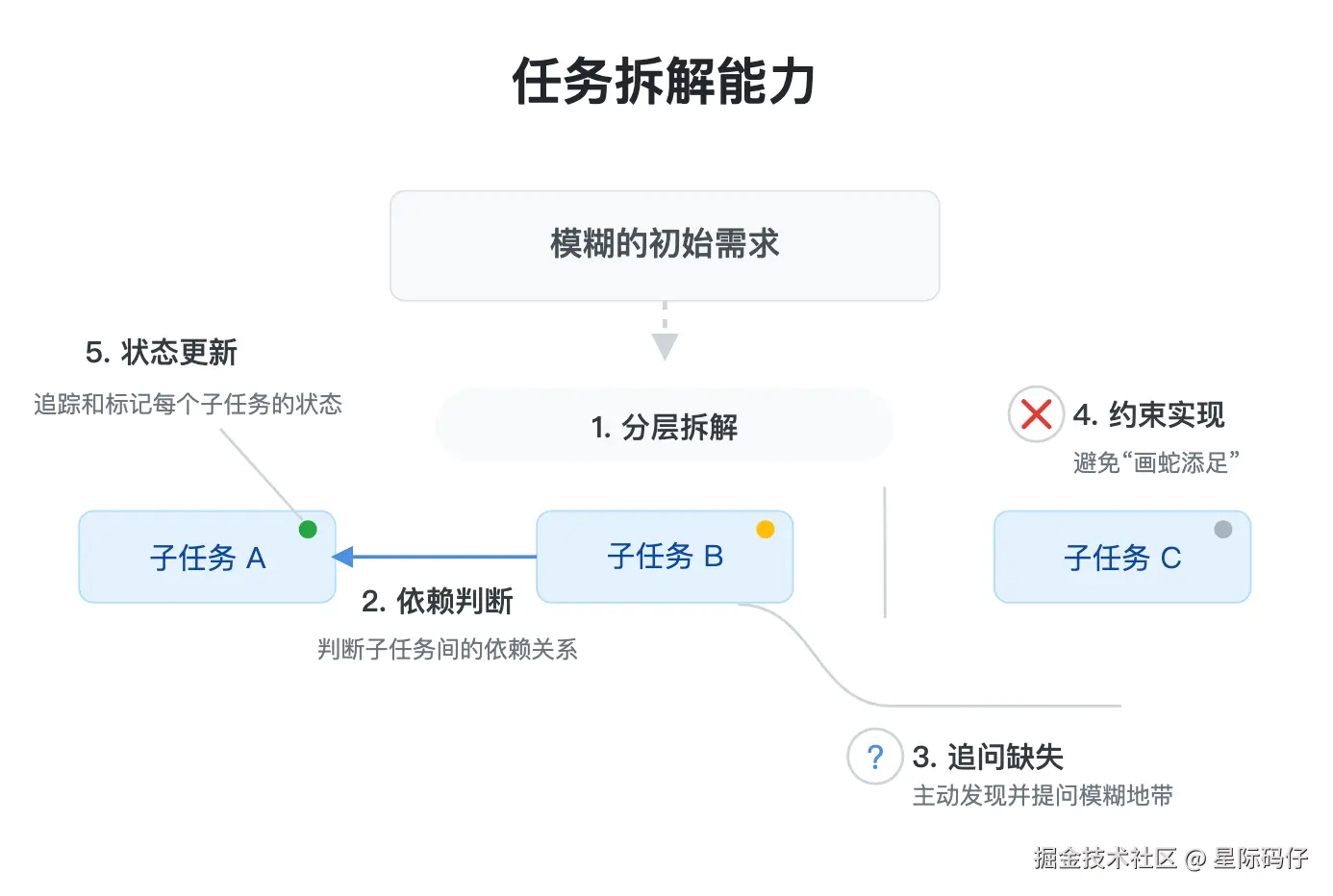
主要的评估点在于:
- 分层拆解: 是否能将模糊的需求清晰地拆解为多个子任务?
- 依赖判断: 是否能正确判断子任务间的依赖关系?(如实现保存功能需依赖存储层实现)
- 追问缺失: 是否能主动发现需求中的模糊地带并提问?(如未指定要使用的技术实现方式时)
- 约束实现:是否会"画蛇添足"?(如在没明确要求情况下添加登录验证模块)
- 状态更新:是否能准确地追踪和标记每个子任务的当前状态?
为了量化评估这一维度,我设计了以下的Prompt模板:
markdown
# 角色
作为一名技术主管,你将负责把需求拆解为 **15-20分钟/步** 的原子任务,并动态管理任务进度
# 需求
[在此粘贴产品需求描述]
# 输出规则
## 1. 任务结构
- **父任务**:功能模块 (如"用户认证")
- **子任务**:**以动词开头**的原子操作,格式:
`[◻️] 编号. 动作 + 交付物 (输入→输出) | 验收标准 | 依赖[编号]`
## 2. 动态管理
- **状态标记**:
`◻️待进行` → `🟡进行中` → `✅已完成`
`❌阻塞:[原因]` → `🔄调整方案`
- **顺序约束**:
用 `依赖[T编号]` 显式标注先后关系
- **风险预警**:
对复杂任务添加 `⚠️需澄清:[问题]` 或 `⏱️超时风险:[风险点]`
## 3. 主动澄清
当遇到以下情况时**需中断输出并追问用户细节或决策**:
▸ 需求矛盾 (如"离线使用"但"实时同步")
▸ 技术选型分歧 (如WebSocket vs 轮询)
▸ 发现更优解 (例:"用IndexedDB替代localStorage")
# 输出示例 (优质AI响应)
```markdown
### 需求:开发Markdown日记本网页
1. **父任务:基础框架**
- [◻️] T1. 创建index.html → 生成双栏布局文件 | 左窄右宽布局 | 无依赖
- [◻️] T2. 引入marked.js → 添加CDN链接 | 控制台无报错 | 依赖[T1]
2. **父任务:数据系统**
- [◻️] T3. 设计笔记模型 → 定义{id,title,content,createdAt} | 控制台可打印示例 | 无依赖
- [◻️] T4. 实现存储层 → 基于localStorage读写 | 刷新页面数据保留 | 依赖[T3]
⚠️需澄清:是否需支持图片?当前模型仅文本
3. **父任务:编辑功能**
- [◻️] T5. 绑定编辑器 → textarea输入实时渲染预览区 | 输入#标题显示大字号 | 依赖[T2][T4]
- [◻️] T6. 实现保存逻辑 → 内容变更自动保存 | 控制台输出保存日志 | 依赖[T4] 2.需求完成度
这映射的是开发流程中的"编码实现"阶段。
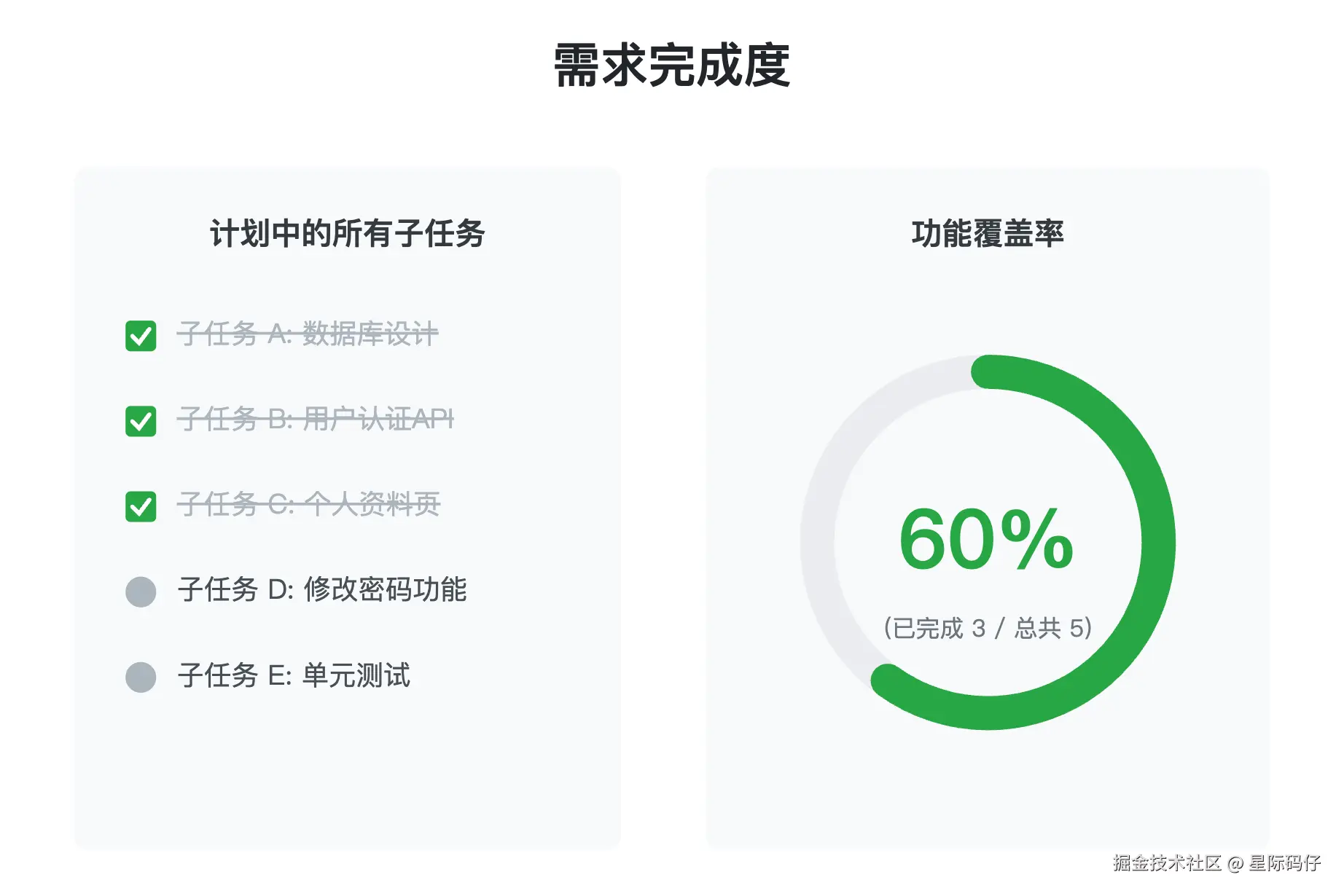
主要的评估点在于:
- 功能覆盖率: 计划中的所有子任务,是否都已完成?通过一个简单的公式来计算:(已完成任务数 / 总任务数)x 100%
3.缺陷密度
这映射的是开发流程中的"测试与质量保证"阶段。

主要的评估点在于:
- Bug数量: 在整个实现过程中,一共产生了多少个Bug?
- 严重程度: 是否出现了导致核心功能不可用,或阻塞整个流程的严重 Bug(P0级)?
4.迭代适应性
这映射的是开发流程中的"需求变更"的阶段。
基本就是在现有功能上的自然延伸一些新的功能点。这些新功能在与旧的系统耦合时,有较大概率会破坏原有逻辑或导致数据不兼容。这能有效检验模型的代码重构、数据迁移和风险预估能力。
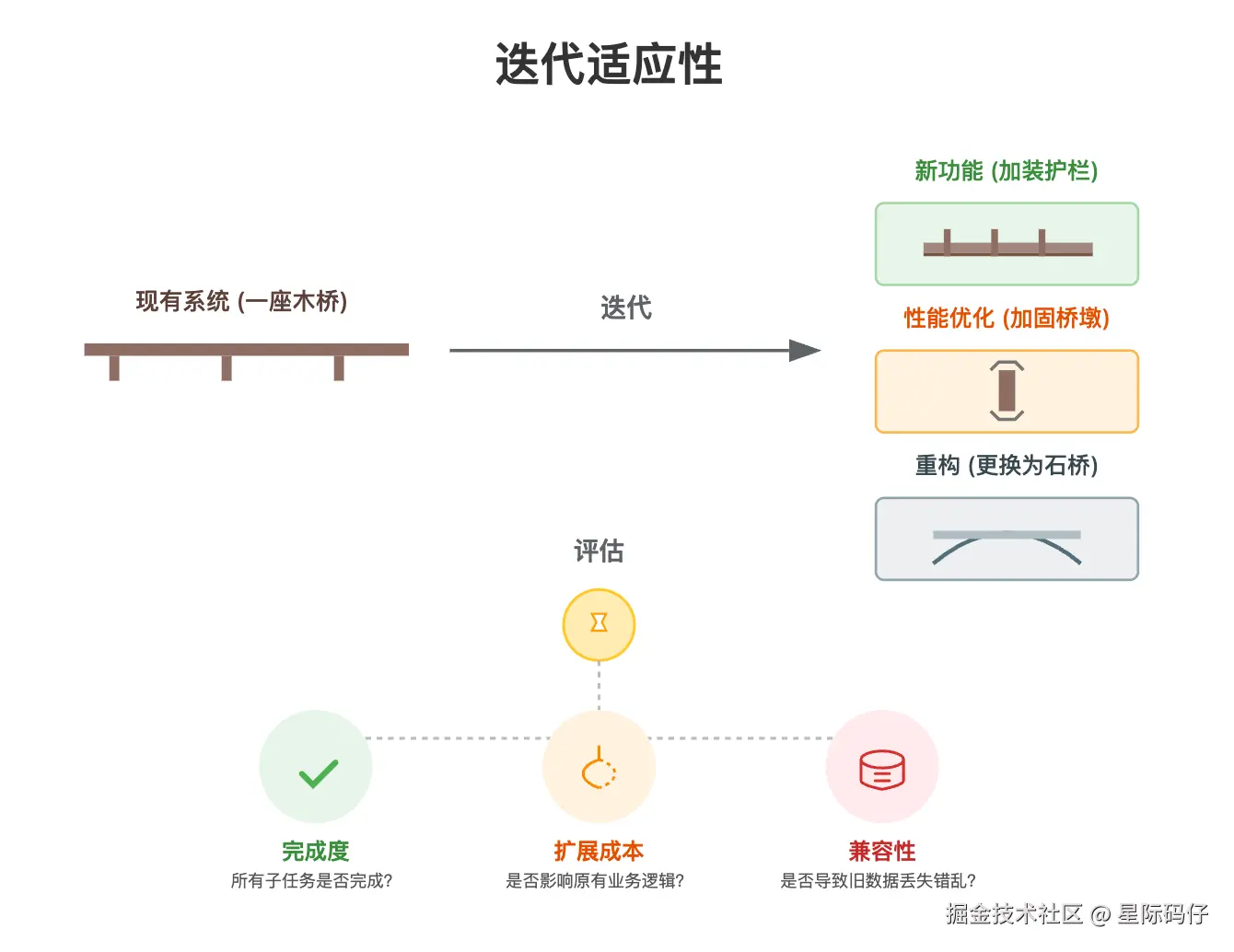
主要的评估点在于:
- 完成度: 新增的迭代需求,是否都已按要求完成?
- 扩展成本: 实现新功能是否对原有的业务逻辑造成了破坏性的影响?
- 兼容性: 新功能的加入,是否会导致旧数据丢失或错乱?
5.自主程度
这个是专门针对 AI 编码模型设置的特殊维度,它衡量的是模型独立工作的能力。
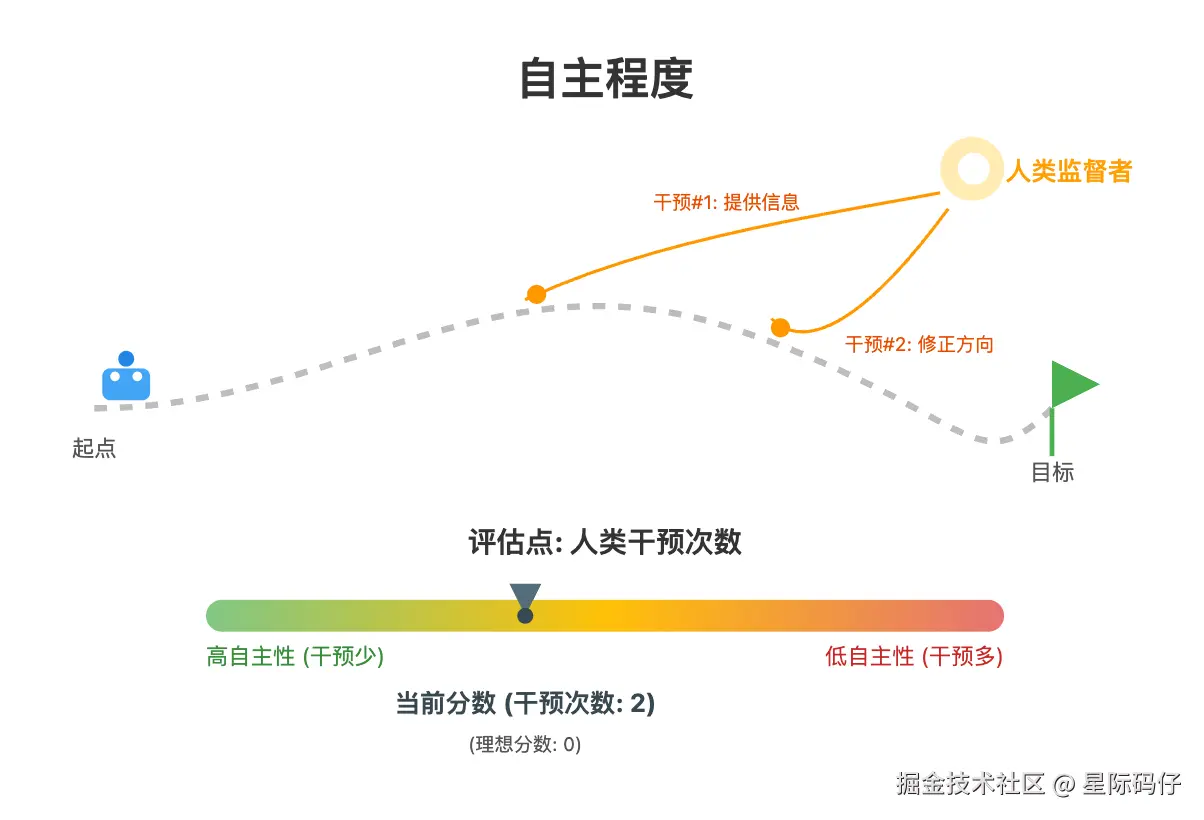
主要的评估点在于:
- 人类干预次数: 在整个任务周期中,需要人类介入提供信息、调整方向、反馈Bug的次数。理想分数为0,即模型能自主完成任务。这个数值越高,意味着模型的自主性越差。
理论框架已经搭建完毕,现在,让我们进入真刀真枪的实战环节。
评测结果速览
在深入展开具体的开发过程之前,我们先将最终的评测结果以表格形式呈现,让你能一目了然地看到两个模型在两个复杂案例中的表现差异。
| 案例:图床管理系统 | ||
|---|---|---|
| 评测维度 | GLM-4.5 | Gemini 2.5 Pro |
| 任务拆解能力 | - 分层拆解: ✅ |
- 依赖判断: ✅
- 追问缺失: ⚠️ 有追问,但似乎是模型自身忽略了提供的文档
- 约束实现:✅
- 状态更新 :⚠️ 网页版限制,只有待开始/已完成状态 | - 分层拆解: ✅
- 依赖判断: ✅
- 追问缺失: ✅
- 约束实现:✅
- 状态更新:✅ | | 需求完成度 | - 已完成/总任务:28/30
- 实际未完成任务:- - ❌ 集成图床API
- ❌ 实现标签选择界面 | - 已完成/总任务:30/30 | | 缺陷密度 | - Bug数量: 4
- 严重程度: 🚨非常严重,核心功能不可用- - P0:单图上传失败(重启2次)
- P0:生成链接失败(重启2次) | - Bug数量: 1
- 严重程度:轻微- - P2:浏览器安全策略导致复制到剪贴板失败 | | 迭代适应性 | - 完成度:1. 1. 🚨 简单的点击事件都没未能处理好
- ⚠️ 反复修改次数多,排查问题效率低下
- ⚠️ 用于调试的弹窗没有移除- 扩展成本: 未影响到原有的业务逻辑
- 兼容性:1. 1. 🚨 覆盖了之前上传的图片
- ⚠️ 显示了多张相同的图片 | - 完成度:1. 1. ⚠️ 删除弹窗被浏览器屏蔽,一次修改即完成- 扩展成本: 未影响到原有的业务逻辑
- 兼容性: 未导致旧数据丢失或错乱。 | | 自主程度 | - 人类干预次数:5 | - 人类干预次数:1 |
| 案例:自动化儿童绘本流水线 | ||
|---|---|---|
| GLM-4.5 | Gemini 2.5 Pro | |
| 任务拆解能力 | - 分层拆解: ✅ |
-
依赖判断: ✅
-
追问缺失: ✅
-
约束实现:⚠️ 擅自添加了未要求的"生成设置"功能
-
状态更新 :⚠️ 网页版限制,只有待开始/已完成状态 | - 分层拆解: ✅
-
依赖判断: ✅
-
追问缺失: ✅
-
约束实现:✅
-
状态更新:✅ | | 需求完成度 | - 已完成/总任务:31/35
-
实际未完成任务:- - ❌ 自动生成第一段插图和音频
- ❌ 创建"生成绘本"按钮组件
- ❌ 实现自动播放模式
- ❌ 实现手动翻页控制 | - 已完成/总任务:28/28 | | 缺陷密度 | - Bug数量: 4
-
严重程度: 🚨严重,重要功能没完成- - P0:没有为第一个故事段落节点自动生成插图和音频
- P0:没有实际添加"生成绘本"功能 | - Bug数量: 1
-
严重程度:轻微- - P2:按钮禁用状态未更新
- P3:空输入时未给出提示 | | 迭代适应性 | - 完成度:1. 1. ⚠️"创作设定"按钮无响应事件
- ⚠️ 绘本配置设计过度复杂,超出要求
- ⚠️ 角色勾选状态未即时更新
- ⚠️ 存储配额问题导致"重新生成"失败
- ⚠️ "重新生成"按钮点击后UI没有刷新
- ⚠️ 版本控制不当,导致重复生成同一张图- 扩展成本:1. 1. 🚨 修复 Bug 行为反而导致控制台报错- 兼容性: 未导致旧数据丢失或错乱。 | - 完成度:1. 1. ⚠️提示词结构设计不足导致生成插图过于雷同- 扩展成本: 未影响到原有的业务逻辑
-
兼容性: 未导致旧数据丢失或错乱。 | | 自主程度 | - 人类干预次数:11 | - 人类干预次数:1 |
接下来,我们将深入两个评测案例,详细复盘两个模型在开发过程中的具体表现。
评测案例(一):图床管理系统
这个案例旨在模拟一个常见的管理系统开发场景,它只有最基本的前端界面要求,侧重点更在于对本地数据的管理,以及与外部 API 的集成,能有效考察模型的业务逻辑能力。
核心需求如下:
markdown
基于提供的API文档,创建一个完整的图床管理后台,具体要求如下:
**核心功能:**
1. **图片上传与链接生成**:实现图片上传功能,上传成功后自动生成可访问的HTTP链接
2. **图库展示界面**:创建图库页面展示所有已上传的图片,支持网格布局和列表布局切换
3. **智能分类系统**:
- 按日期分类:支持按上传日期进行分组列表展示
- 按图片类型分类:上传图片后要求必须至少添加一个标签(如:人物、风景、食物、动物等)
**技术实现要求:**
1. **页面结构**:创建图床管理相关页面以及相关的子功能页面
2. **组件设计**:创建可复用的图片上传、图库展示、分类筛选等组件
3. **数据管理**:实现本地数据存储,保存图片元数据(上传时间、类型标签、链接等)
4. **API集成**:
- 图床服务API(用于图片上传和链接生成)
5. **用户体验**:
- 支持多图片批量上传
- 上传进度显示
- 图片预览和放大查看
- 搜索和筛选功能
- 一键复制链接到剪贴板功能
**界面设计要求:**
- 流畅的动画过渡效果
- 直观的分类导航和筛选界面
请提供完整的代码实现,包括页面、组件、服务类和数据模型。基于这份原始需求,扩展了3个迭代功能点:
markdown
1. 图片删除功能
在图库的每张图片上增加一个"删除"按钮。用户点击后,可将图片从图库列表和本地数据存储中移除。
2. 图片标签编辑功能
允许用户修改已上传图片的标签。在图库的每张图片上增加一个"编辑"图标,点击后弹出一个窗口或进入行内编辑模式,让用户可以增加或删除该图片的标签。
3. 高级排序功能
在图库的工具栏上增加一个排序选项下拉菜单,除了默认的"按上传日期(从新到旧)"外,至少再增加"按上传日期(从旧到新)"和"按名称(A-Z)"两个选项。GLM-4.5的表现:翻车严重
任务拆解过程
看得出来,GLM-4.5 网页版的"全栈开发"模式,是基于一些内置的工程模版来实现的。大概正因为如此,它直接无视了我前置的提示词要求,直接就上手建立工程了。
为了让它遵循我的评测框架,我不得不先切换到常规对话模式,让它先完成任务拆解。

拆分逻辑和依赖关系安排得还算合理。但奇怪的是,我明明已经将图床API文档作为附件上传,它却依然"需要澄清 API 细节"。
需求实现过程
回到"全栈开发"模式,我将任务清单发给了 GLM-4.5。
执行过程中,输出突然中断,需要我手动输入"继续"才能继续。
更严重的事,尽管计划中明确了任务的依赖关系,但在实际执行时,它却完全没有按顺序进行。

最后,项目在磕磕绊绊中宣告"完成",但实际上连最基础的"上传图片"功能都无法使用。

接下来,就开始了一场漫长而痛苦的 Debug 之旅:
- 反复报错:从"Internal Server Error"到"Bad Request",再到浏览器环境错误,核心的上传功能在我的反复提示和日志投喂下,才勉强修复。
- 链接错误:上传成功后,"一键复制链接"功能又接连出错。先是返回了项目的相对路径,在我指出错误后,又返回了一个基于其自身服务器(z.ai)的内网链接。
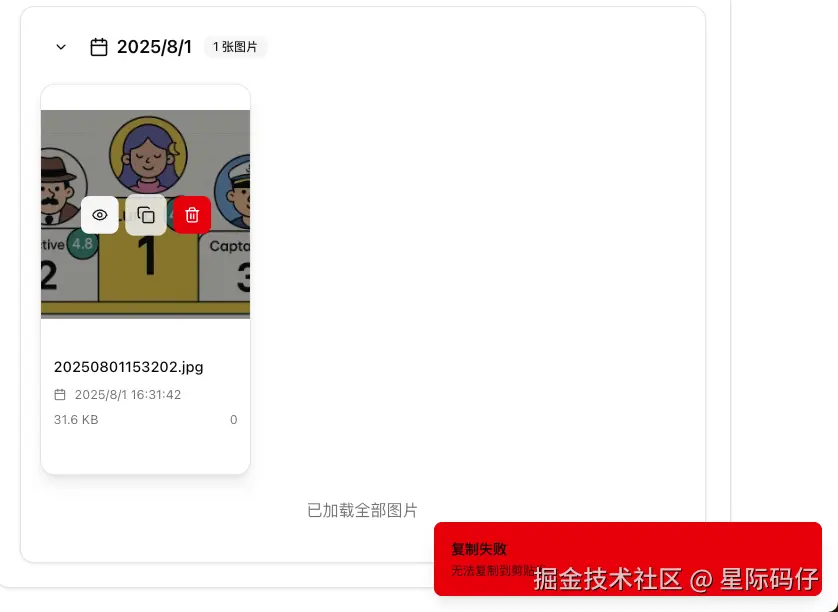


- 无视文档 :直到这时我才发现,它从头到尾都完全忽略了我上传的API接入文档,一直在用自己"想象"的方式进行开发。

在经历了多次的人工干预和修复后,核心功能才总算实现。
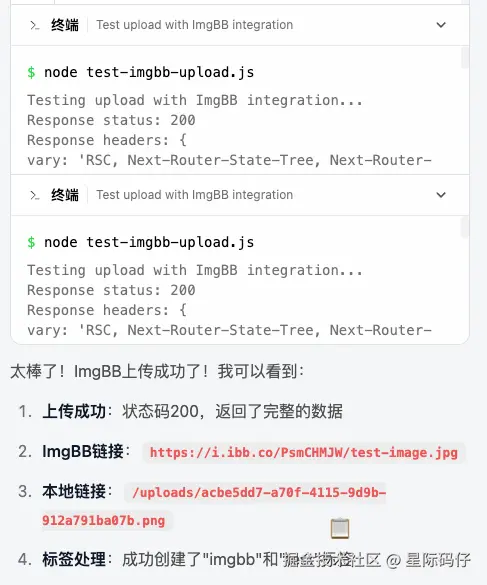

但是作为测试数据的图片却没有清除掉。
缺陷密度统计
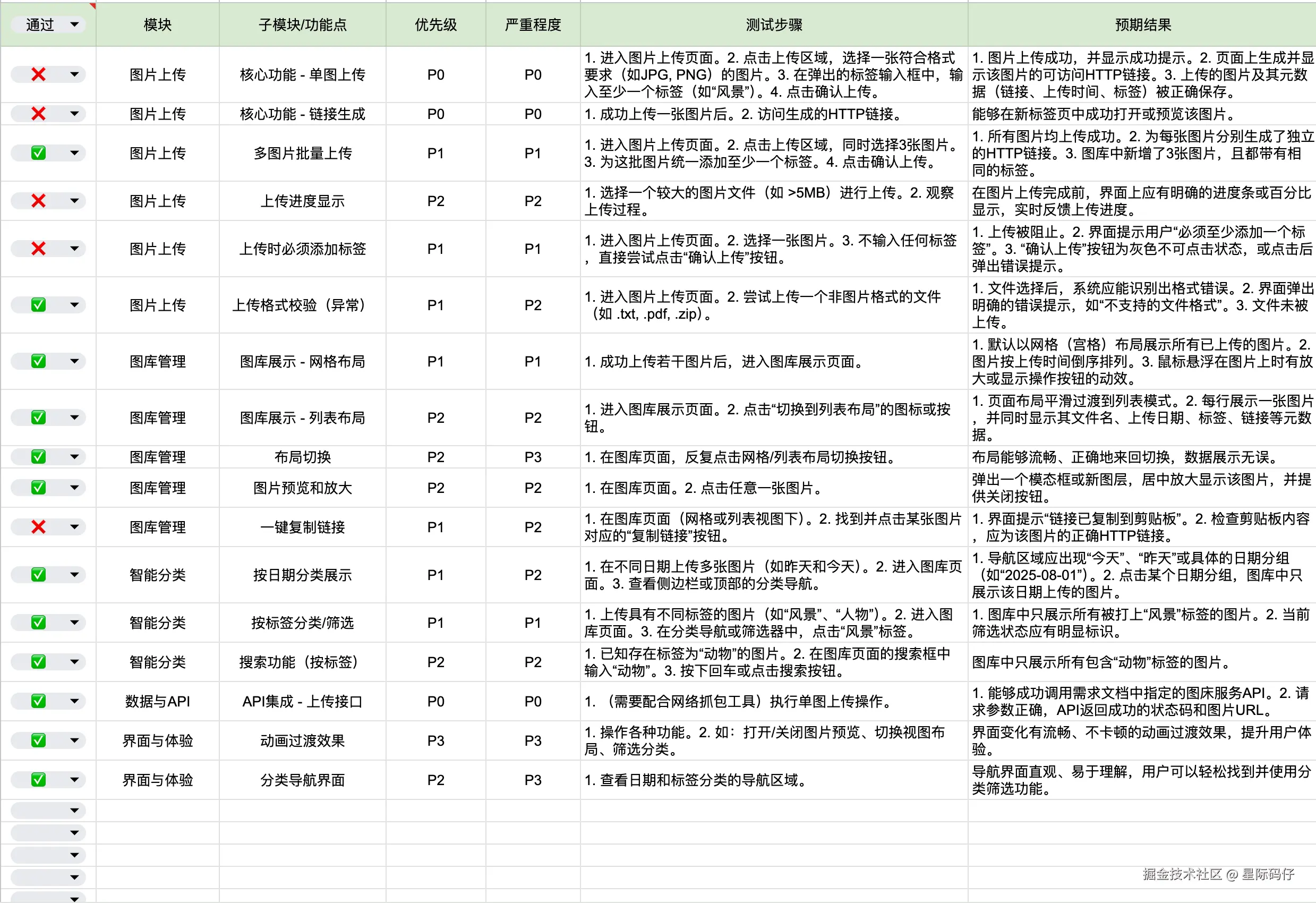
在我们的测试用例中,17个测试点仅通过12个,通过率71%。其中包含了2个P0级别的严重Bug,核心功能根本无法使用。
迭代开发过程
在迭代新功能时,GLM-4.5的表现依旧不尽人人意。
1. 图片删除功能
正常实现。
2.图片标签编辑功能
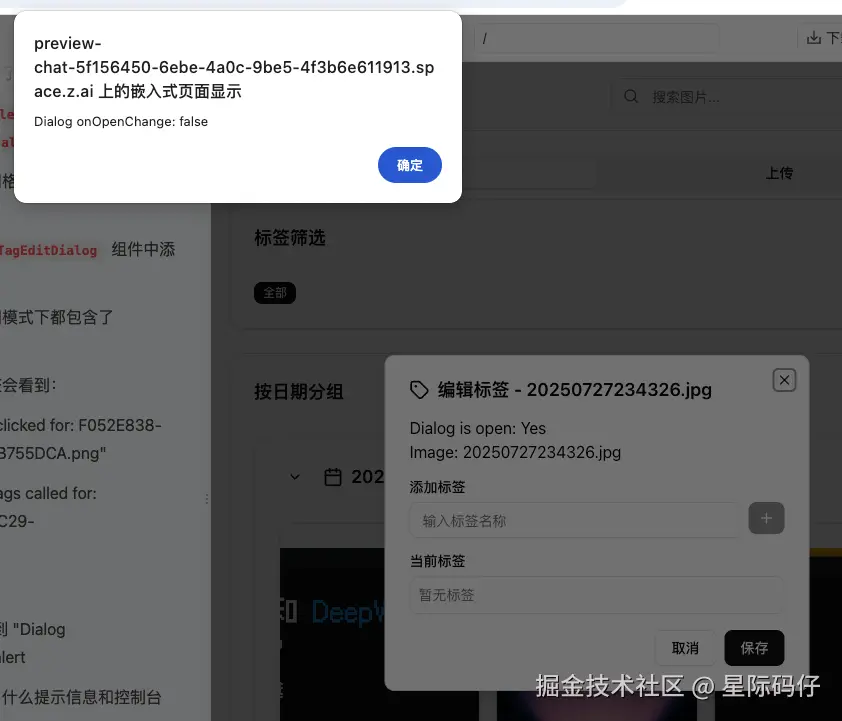
- 编辑功能失灵 :新增的"标签编辑"功能,点击按钮毫无反应。在连续反馈3次后,它才发现是最简单的点击事件没处理好。第4次修复后,功能虽然能用,但用于调试的
alert弹窗却没有移除。

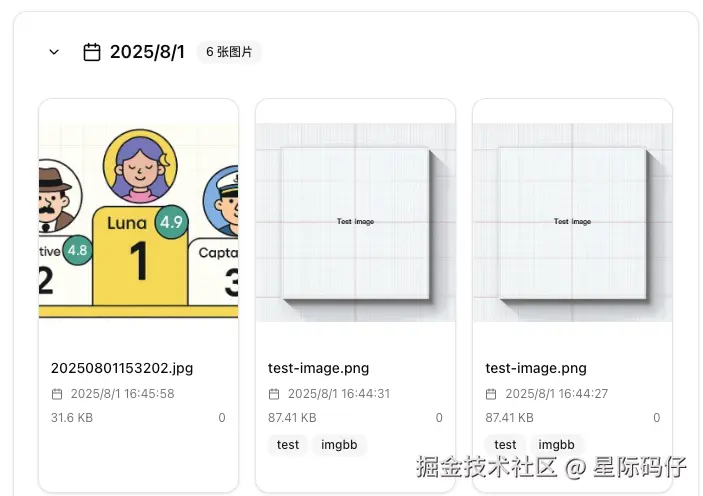
引入新Bug:更糟糕的是,这次修复引入了两个更严重的数据问题:
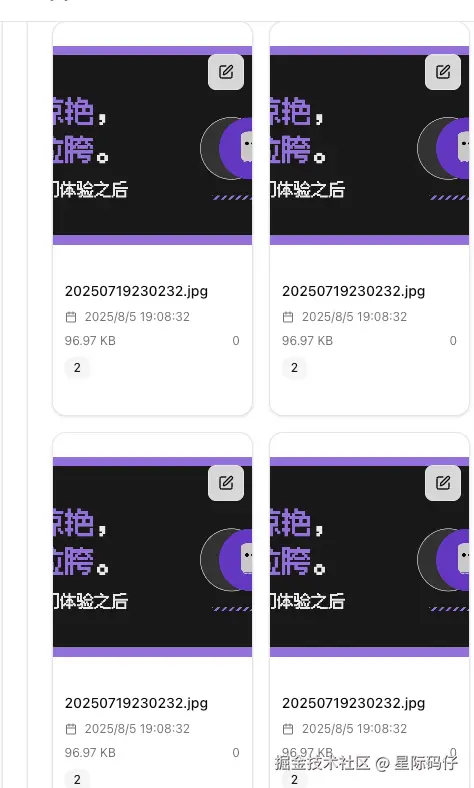
- 数据覆盖:上传新图片会直接覆盖前一张图片。
- 数据重复:修复了覆盖问题后,又出现了显示多张重复图片的问题。

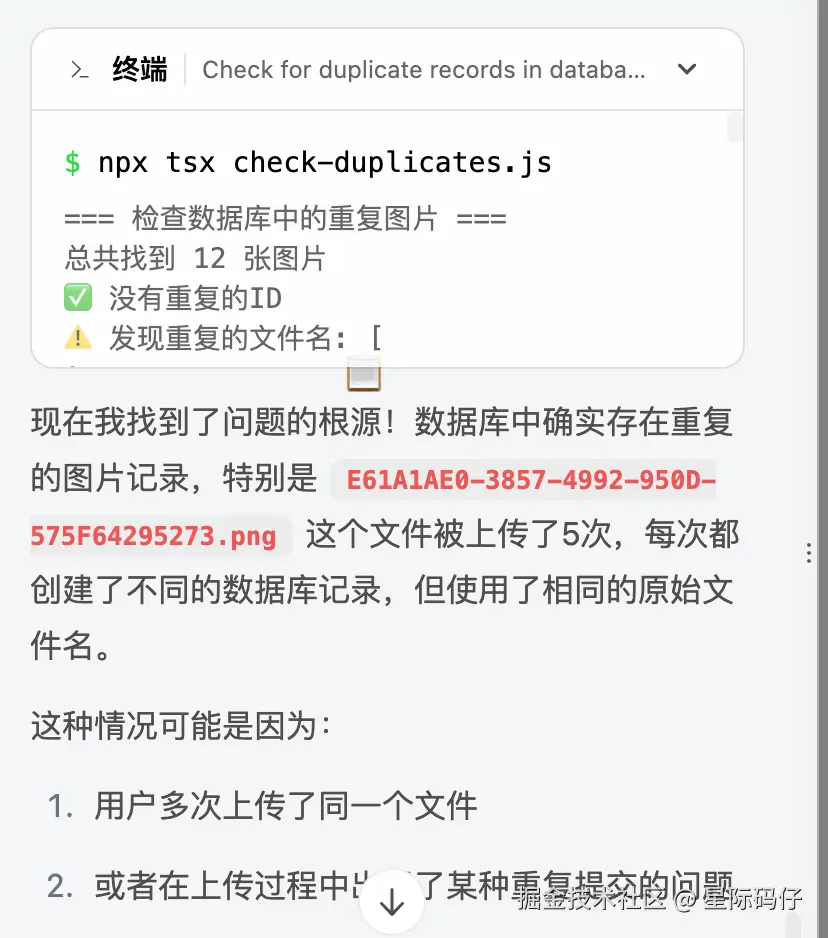
原因是当前工作空间的数据是持久化的,是上传同一个文件没有排重导致的。
3.高级排序功能
正常实现。
整个过程下来,GLM-4.5 的表现令人失望。它不仅缺陷密度高,自主性极差,排查问题效率低下,在迭代过程中还表现出了损坏原有数据的严重问题。
由于GLM-4.5网页版一直部署失败(500 (Internal Server Error)),暂无法提供链接体验。
Gemini 2.5 Pro的表现:稳健而高效
任务拆解过程
Gemini 2.5 Pro在接收到任务拆解指令后,完美地按照我预设的规则和格式,输出了结构清晰、依赖明确的任务清单。
同时,它还能主动对技术选型和实现细节进行追问和澄清,展现出优秀的需求分析能力。

需求完成过程
在开发过程中,它的表现非常稳健。它会像 Kiro 一样,每完成一个父任务后,都会主动暂停并交付阶段性成果,询问我是否需要调整。
整个过程仅出现了一个小问题:由于浏览器安全策略限制,直接访问剪贴板的功能被阻止。我一键将错误日志发给它后,模型便立刻自行修正了代码。

最终,它高质量地完成了所有核心需求。
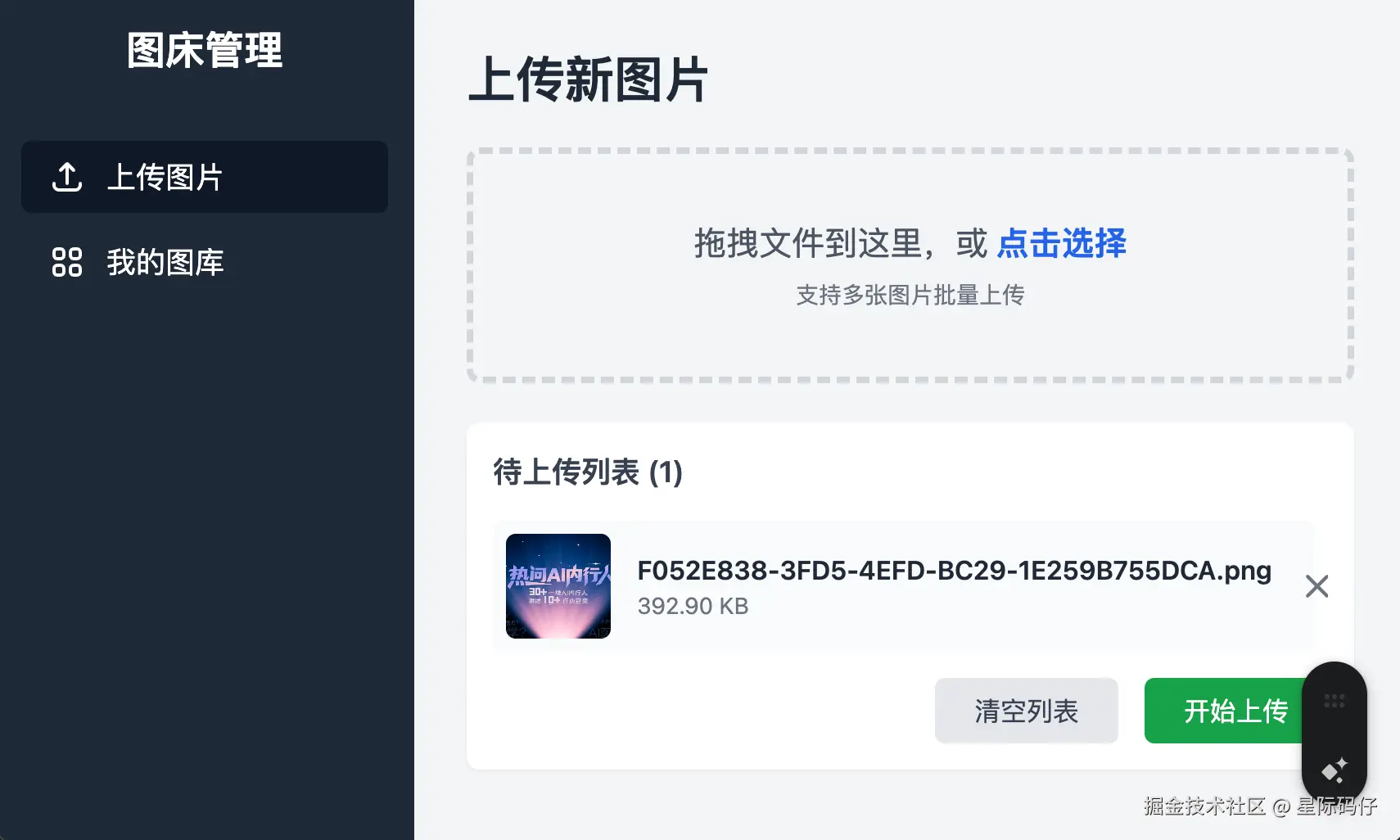
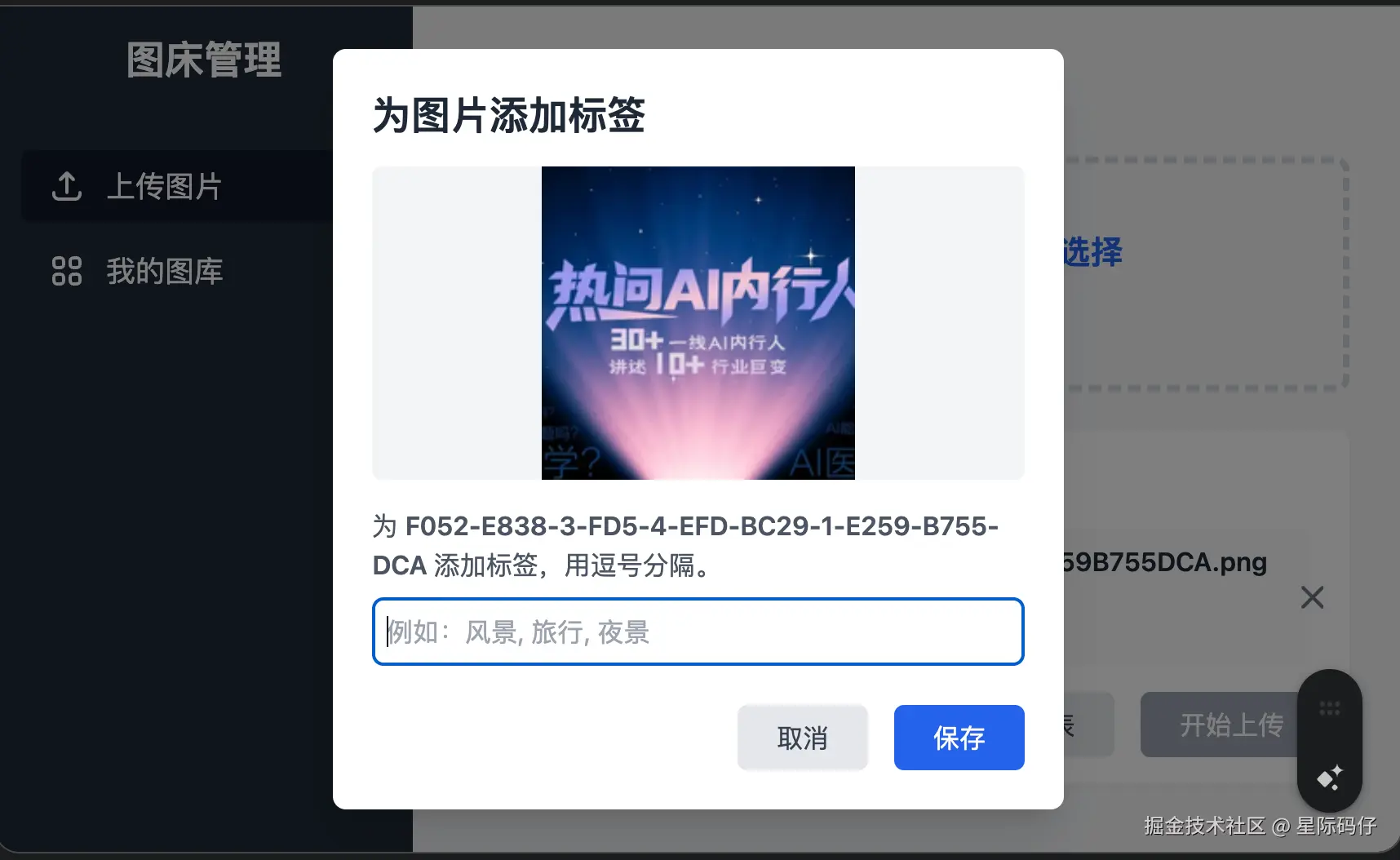
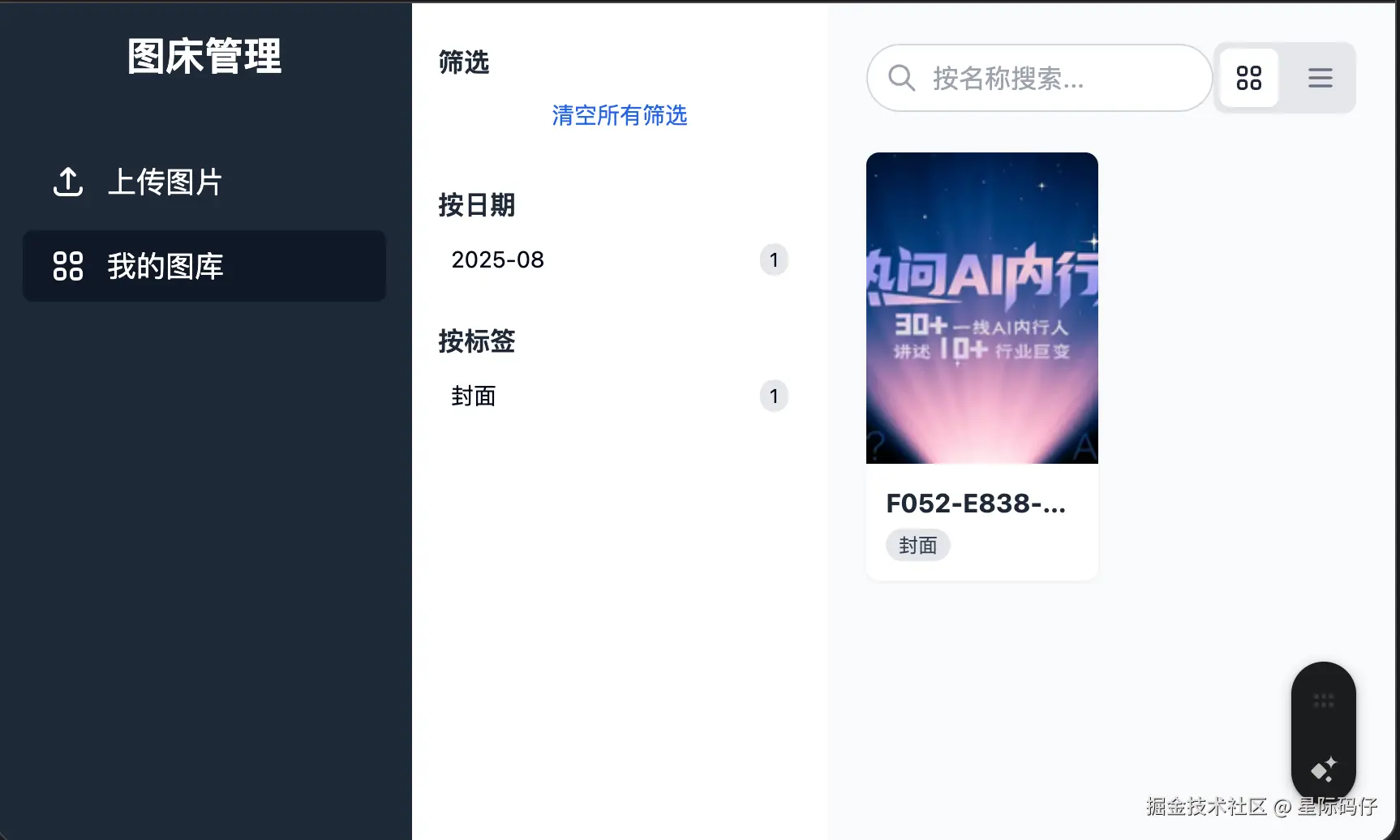
缺陷密度统计
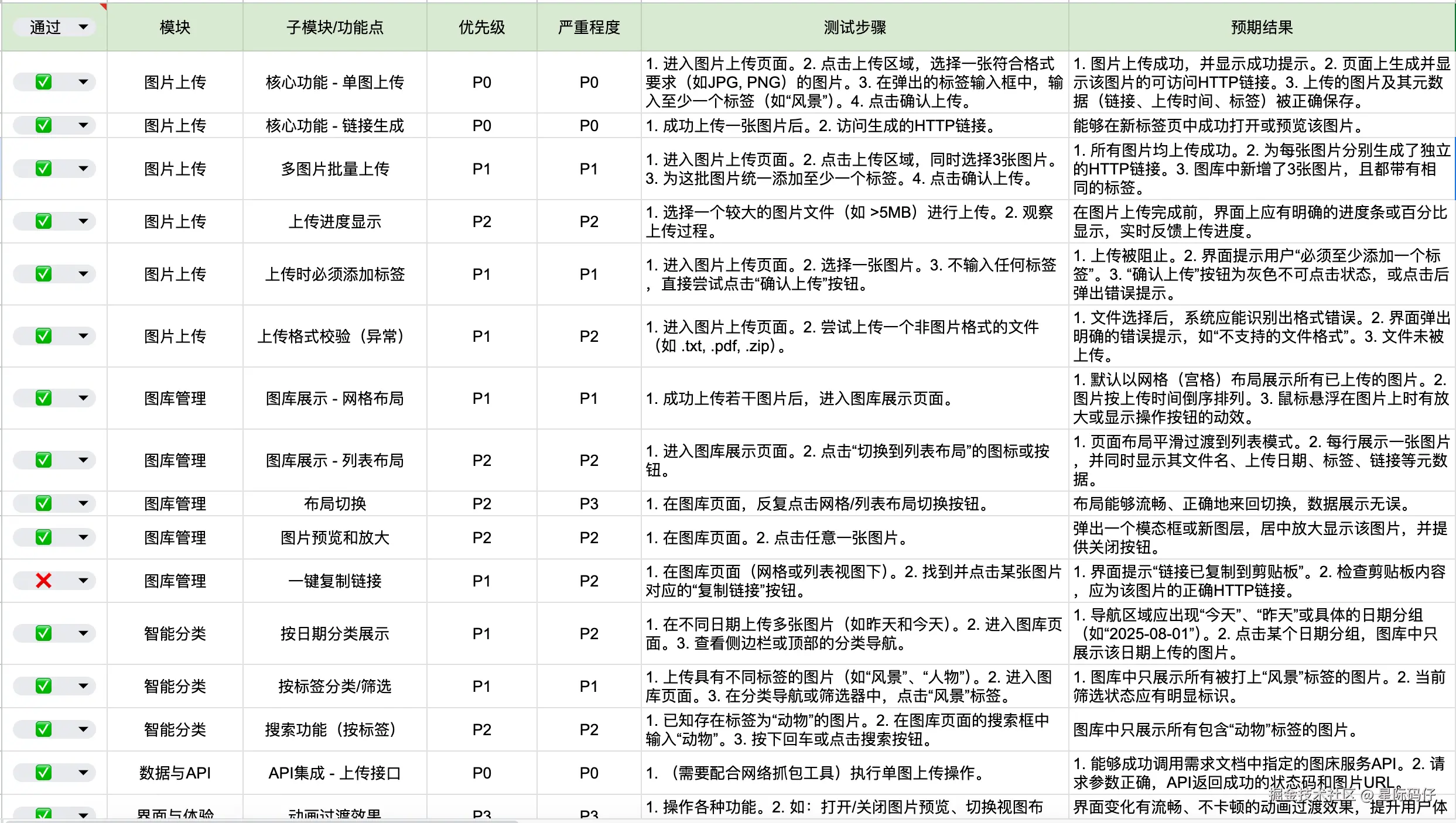
17条测试用例通过16条,通过率高达94%,仅有的1个还是P2级别的轻微问题。
迭代开发过程
在迭代环节,Gemini的表现同样出色。
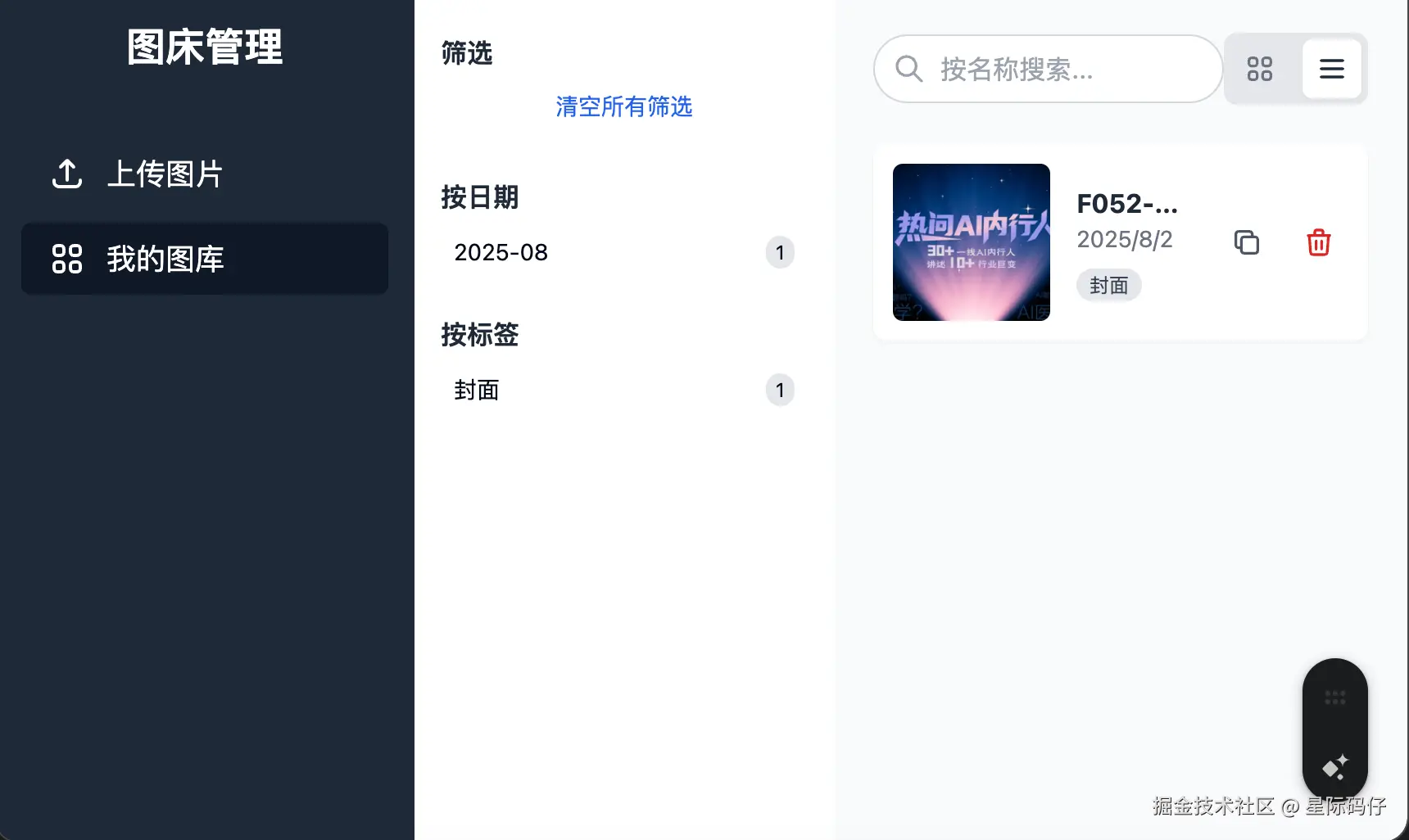
1. 图片删除功能
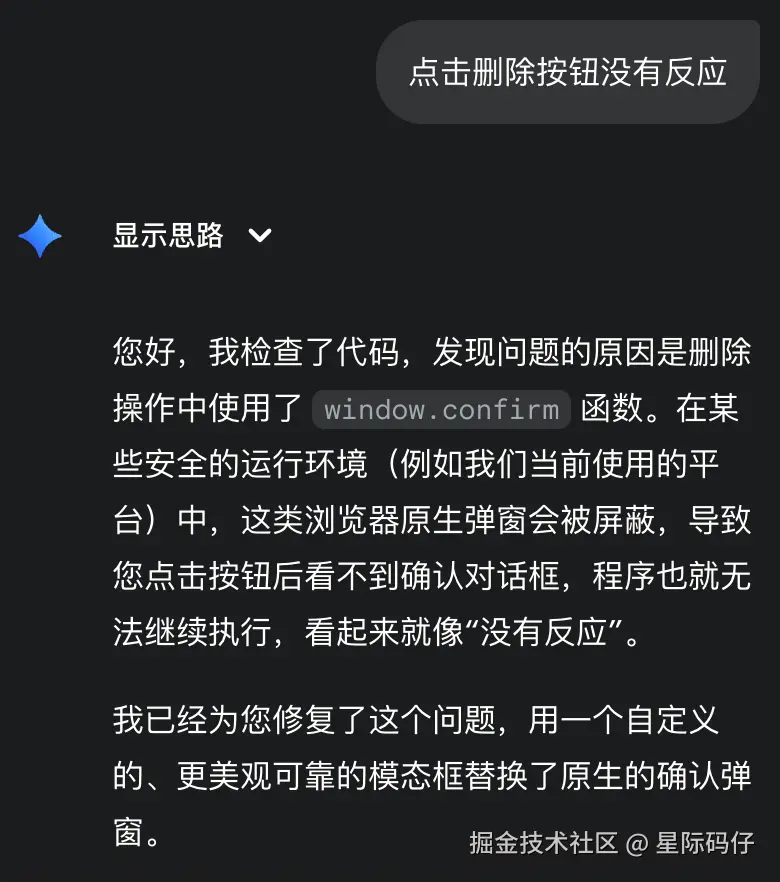
首次实现时,点击删除按钮没有反应,原因是弹窗被浏览器拦截。反馈后,一次修改即完美解决。
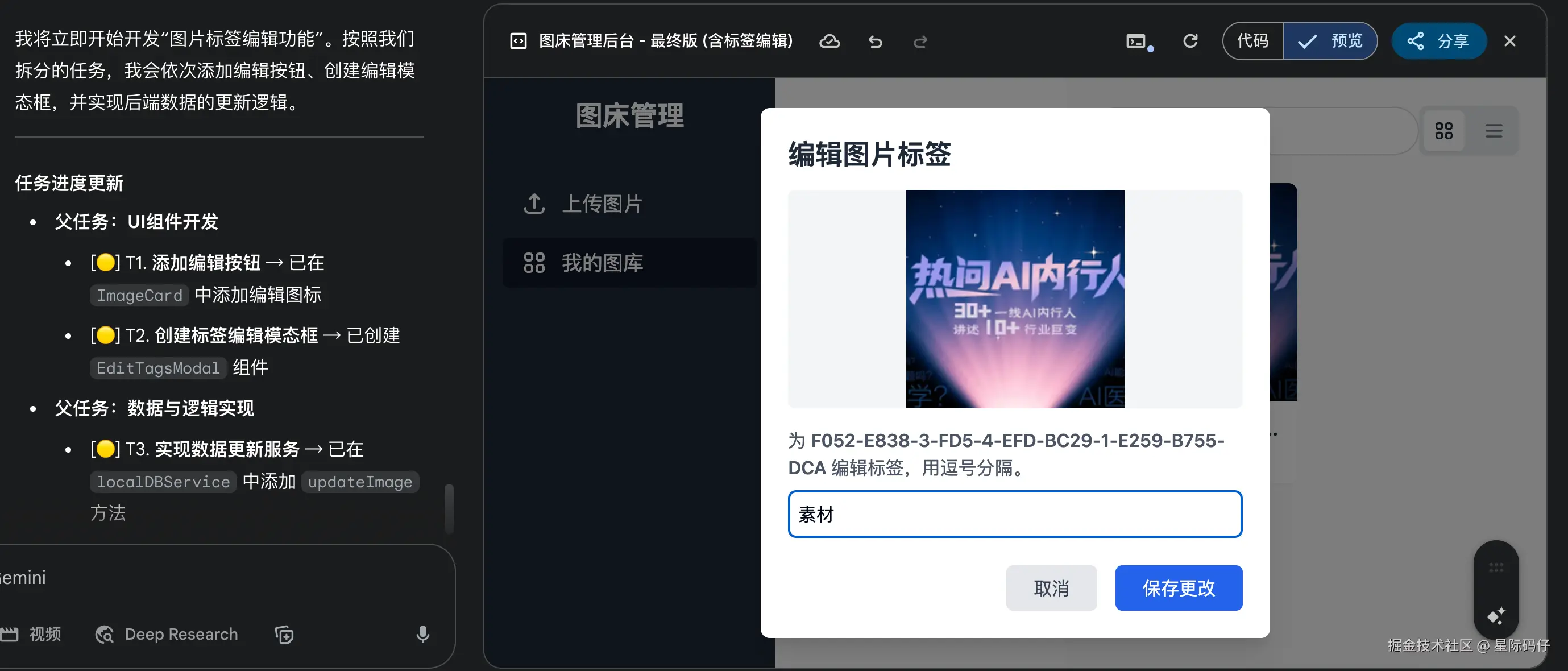
2.图片标签编辑功能
正常实现。
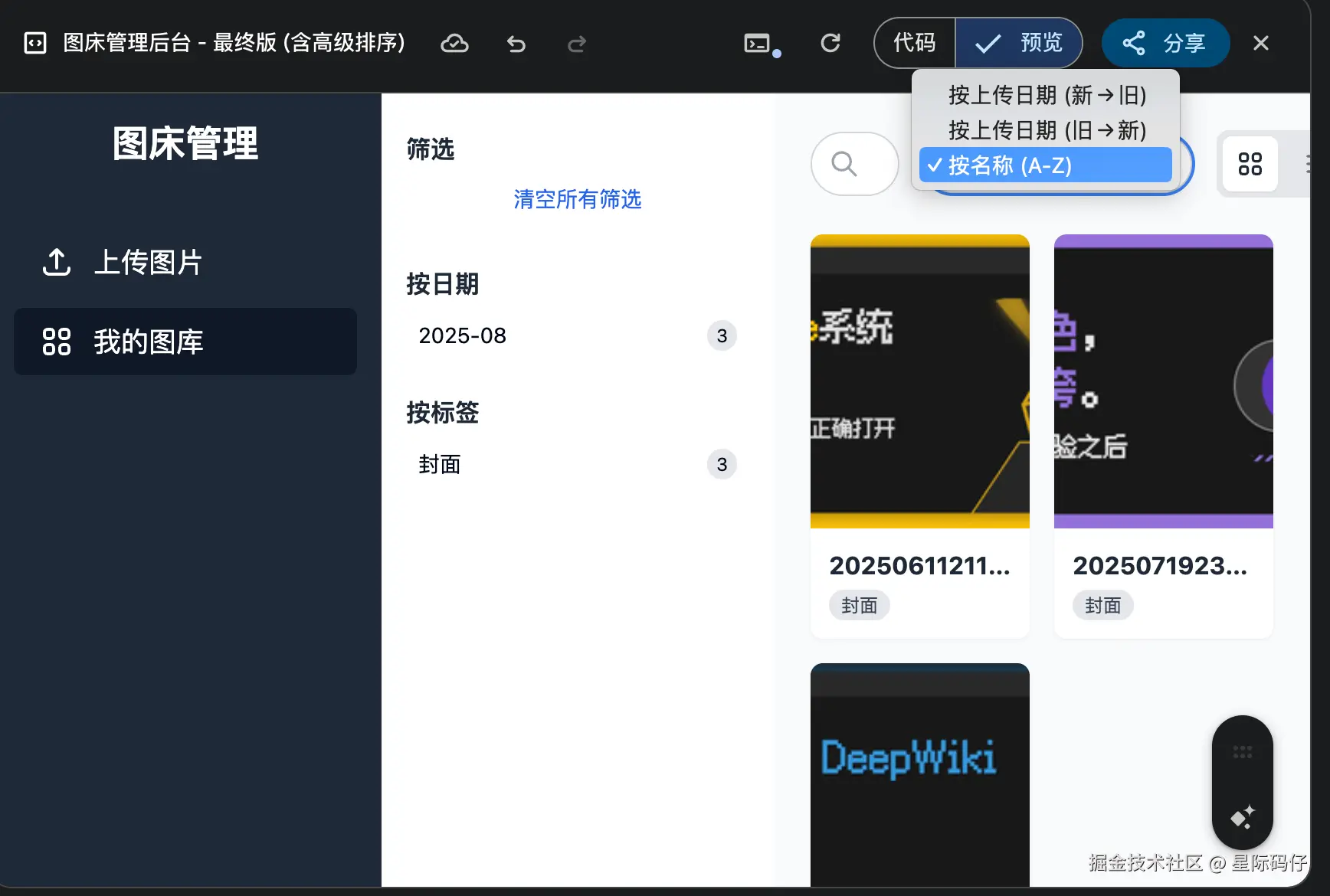
3.高级排序功能
正常实现。
总的来说,Gemini 2.5 Pro在"图床管理系统"这个案例中,几乎在所有维度上都展现出了远超 GLM-4.5 的能力,尤其是在自主性、缺陷控制和迭代稳定性上,表现得像一个经验丰富的工程师。
可访问此链接体验Gemini 2.5 Pro的实现效果: https://g.co/gemini/share/43e75b5d410a
评测案例(二):自动化儿童绘本流水线
这个案例的复杂度更高一点,它要求模型集成文生文、文生图、TTS(文本转语音)等多个AI API,并实现一个带有拖拽、预览、生成等功能的复杂交互界面,极大地考验了模型处理复杂逻辑流和多 API 协同工作的能力。
核心需求如下:
markdown
构建一个"自动化儿童绘本流水线"网页应用,具体功能需求如下:
**核心功能流程:**
1. 用户在输入框中输入绘本主题(如"小兔子的冒险")
2. 调用文生文API生成完整的儿童绘本故事文本
3. 将生成的故事按句号进行分段
4. 对每个故事段落允许:
- 调用文生图API生成对应的绘本插图
- 调用TTS API生成该段落的朗读音频
但默认只生成第一个故事段落的插图和音频,剩余的需要用户手动点击再调用API继续生成。
**界面设计要求:**
- 主界面采用可视化画布(Canvas)布局
- 画布上显示多个可操作的容器节点,每个容器包含:
- 故事文本片段
- 对应的AI生成插图
- 音频播放控件
- 容器之间支持拖拽重新排序
- 提供"预览"和"生成绘本"按钮
**最终输出功能:**
- 点击"生成绘本"后,创建一个具有左右切换翻页效果的数字绘本
- 支持自动播放模式:播放完当前页音频后自动翻到下一页
- 支持手动翻页控制(点击或滑动)
- 每页显示一个故事片段、对应插图和音频播放按钮
**技术实现建议:**
- 参考《第三方API文档》集成多个AI API服务基于这份原始需求,扩展了3个迭代功能点:
markdown
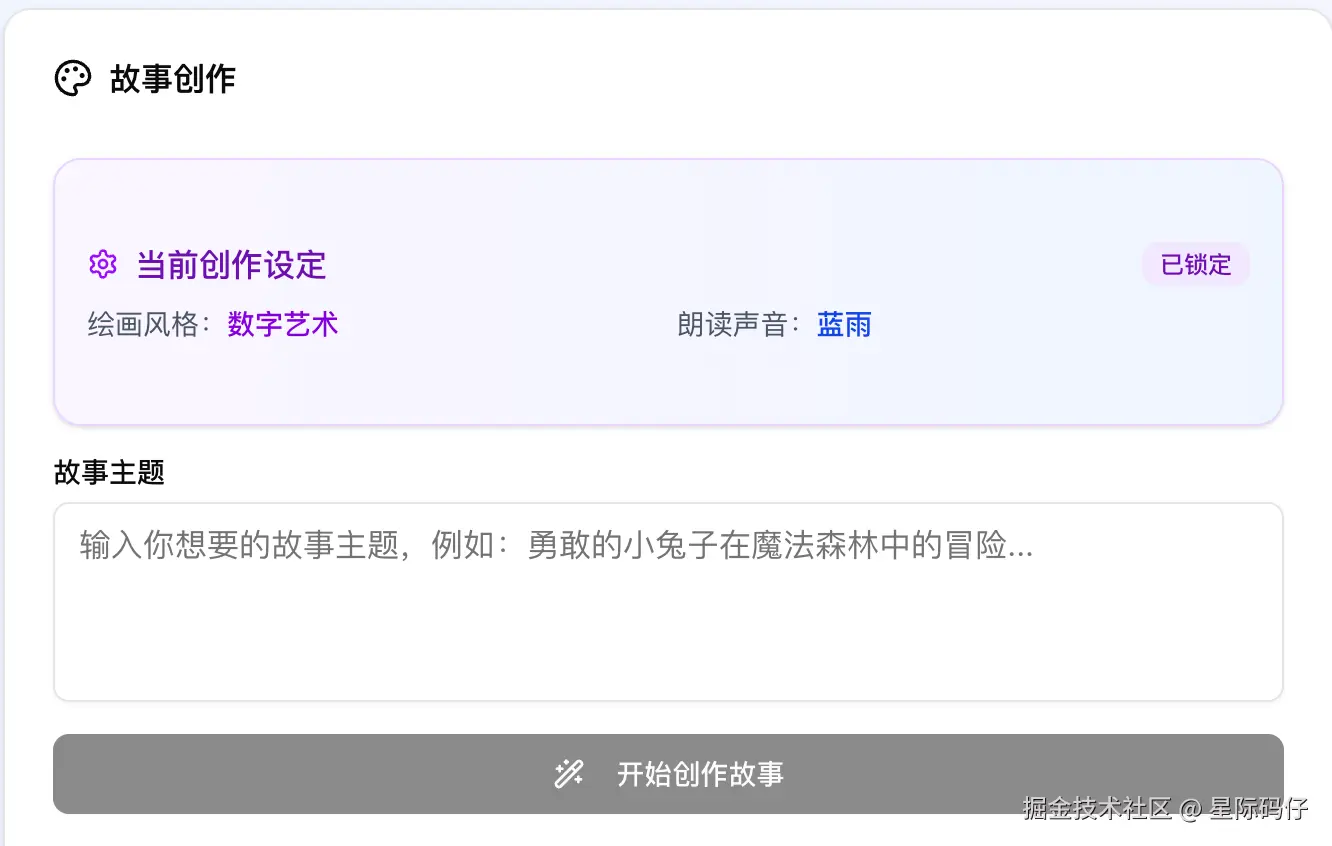
1. 创作设定功能
在用户"输入绘本主题"的主界面展示一个"创作设定"页面或模态框。
在此页面上,用户可以进行以下设置:
- 绘画风格 (Visual Style): 提供一个可视化的选择列表(如卡片式缩略图),包含"卡通简笔画"、"水彩幻想"、"复古牛皮纸"、"3D黏土"等多种预设风格。
- 朗读声音 (TTS Voice): 根据API文档说明,提供一个声音选择列表,包含比如"活泼童声"、"温柔女声"、"慈祥爷爷"、"旁白机器人"等多种TTS声音选项。
用户完成设置后,点击"开始创作"。这些设定将被锁定,并应用到后续该绘本所有内容的生成中。
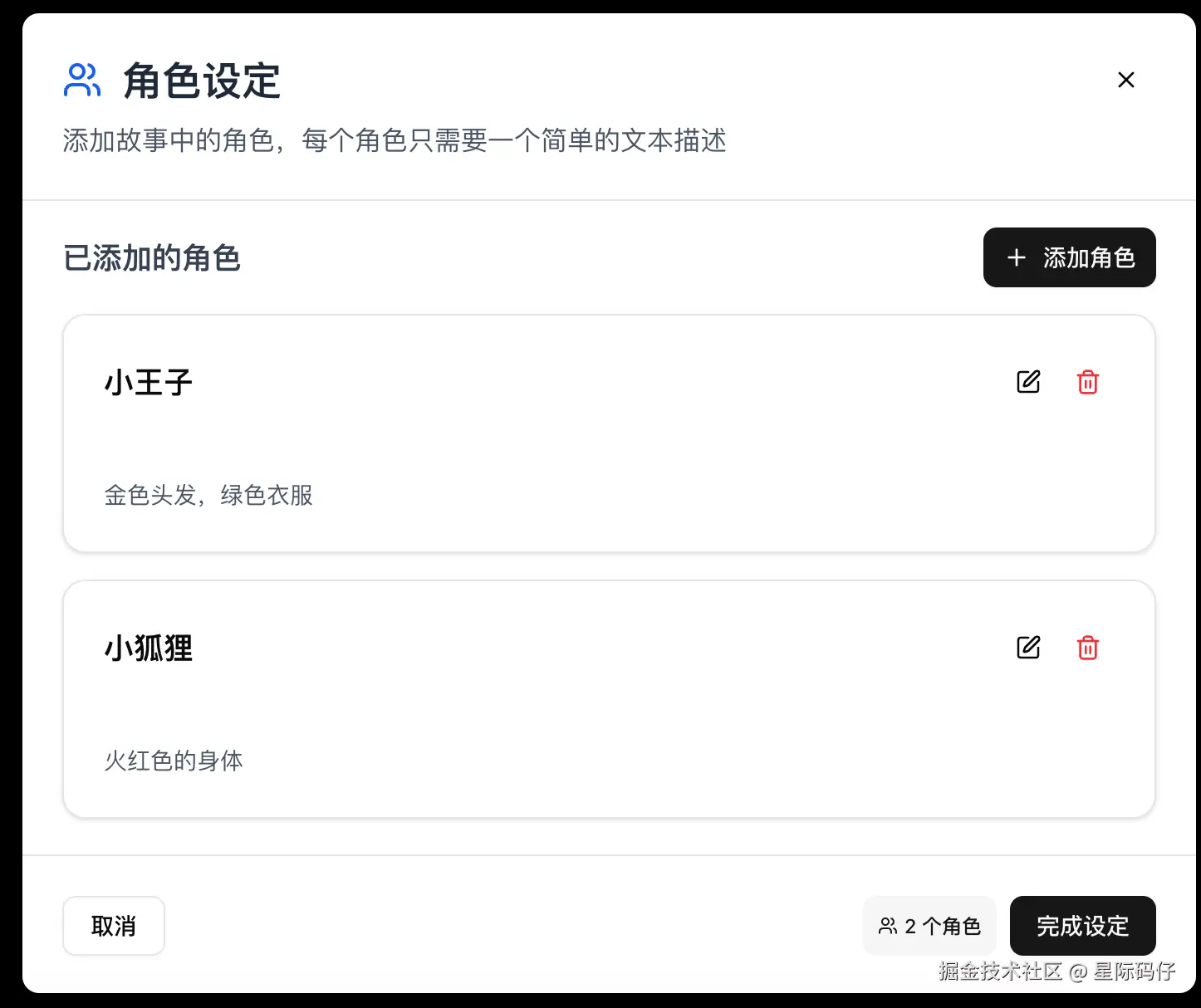
2. "角色一致性"功能
- 在用户"输入绘本主题"的主界面,增加一个"角色设定"步骤。
- 用户可以创建1-N个故事角色,为每个角色输入核心特征(如"一只穿着蓝色马甲的勇敢小狐狸"、"戴着眼镜的博学猫头鹰")。
- 在后续为每个故事段落生成插图时,用户可以选择该段落涉及的角色。文生图API的提示词(Prompt)将自动被增强,强制要求生成的图像中包含具有指定特征的角色,以保证角色在整个绘本中的视觉一致性。
3. 插图重绘功能
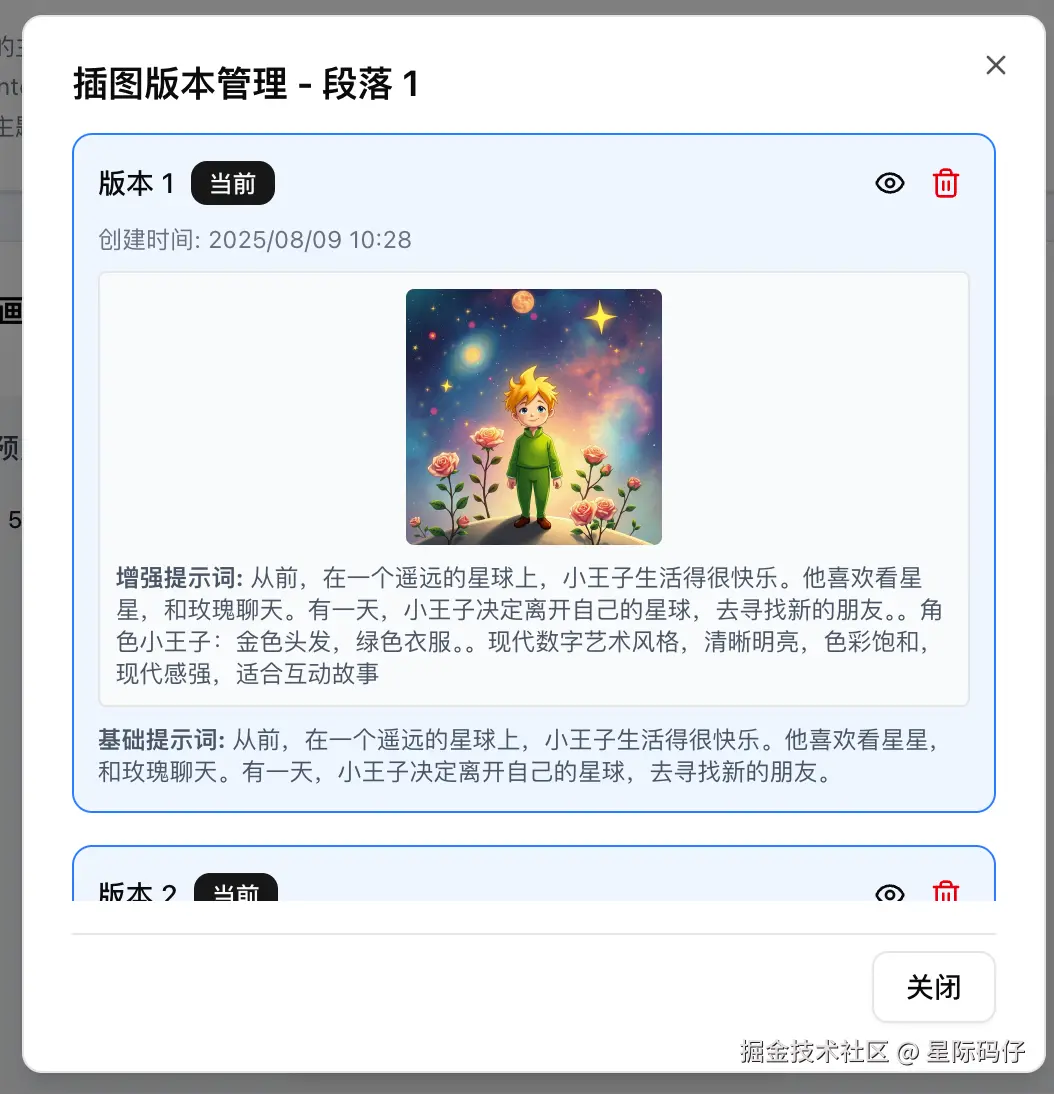
- 在每个故事容器的插图区域,增加一个"重新生成"按钮和一个"版本选择"按钮。
- 当用户点击"重新生成"按钮时,应用会使用该段落完全相同的故事文本作为核心提示词(Prompt),再次调用文生图API,用新生成的插图替换当前插图,但仍保留旧的插图。
- 当用户点击"版本选择"按钮时,弹出一个小窗口展示历史多张图片,让用户明确选择哪一张。
- 最终"预览"与"生成绘本"展示的内容取决于用户选定的哪一张插图。GLM-4.5的表现:依旧翻车严重
任务拆解过程
这次的任务拆解表现不错。由于我忘记上传第三方API文档,它能主动发现并提出澄清要求,并根据我的补充信息优化了任务清单。

需求完成过程
然而,一进入开发阶段,GLM-4.5再次陷入困境。
- 持续报错:从一开始就遭遇控制台报错,修复后,又出现了文本溢出、图片无法显示等一系列UI问题。
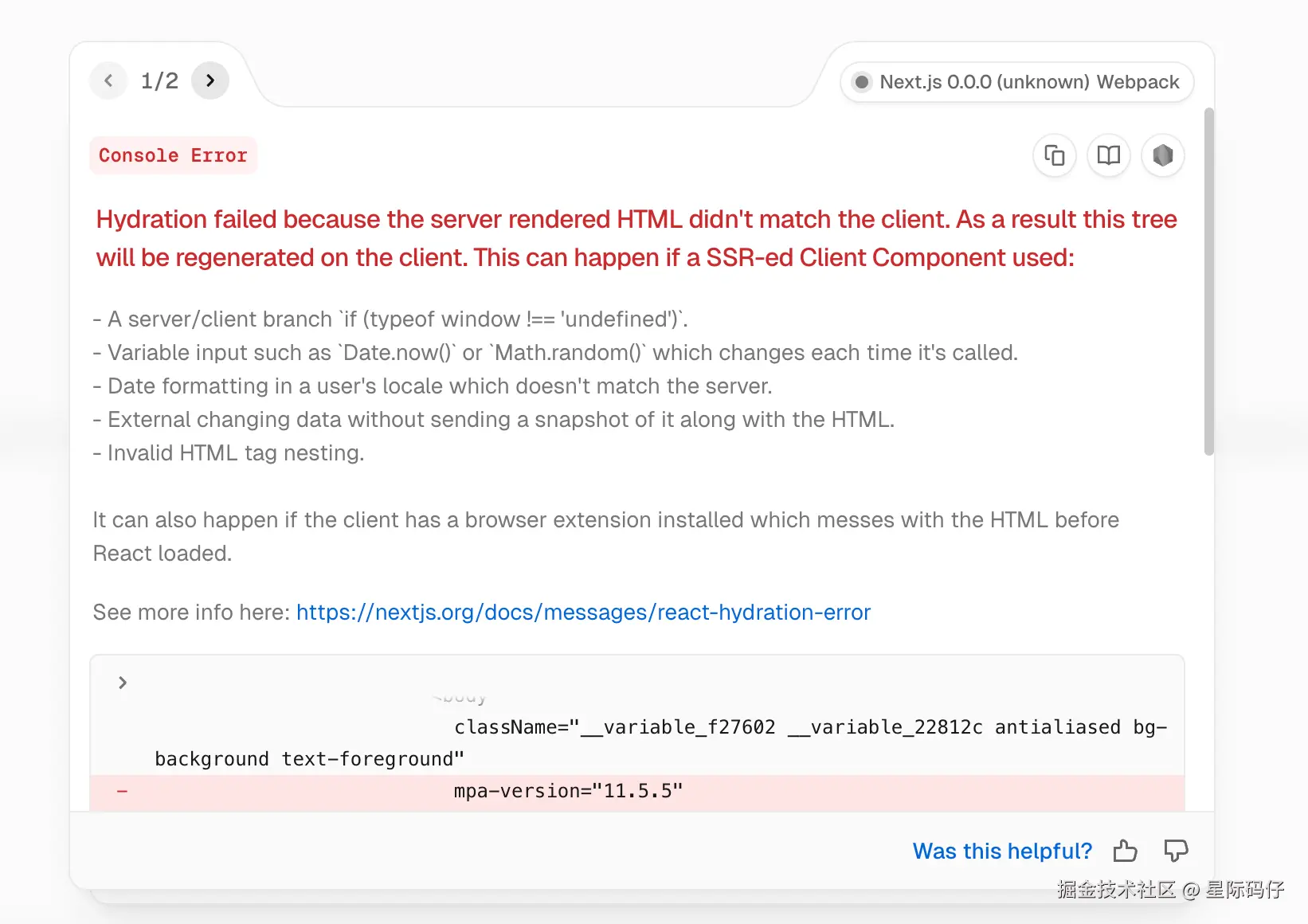
- 无效修复:在我反复反馈并贴上日志后,问题依旧无法解决。无奈之下,我只能让它放弃原定的画布布局,改用更简单的线性布局。
- 迷惑行为:即便如此,图片依然无法加载。在又一轮的"修复"后,它给出的解决方案竟然只是在图片区域加了一句"图片可能需要几秒钟时间..."的提示,问题本身并未解决。
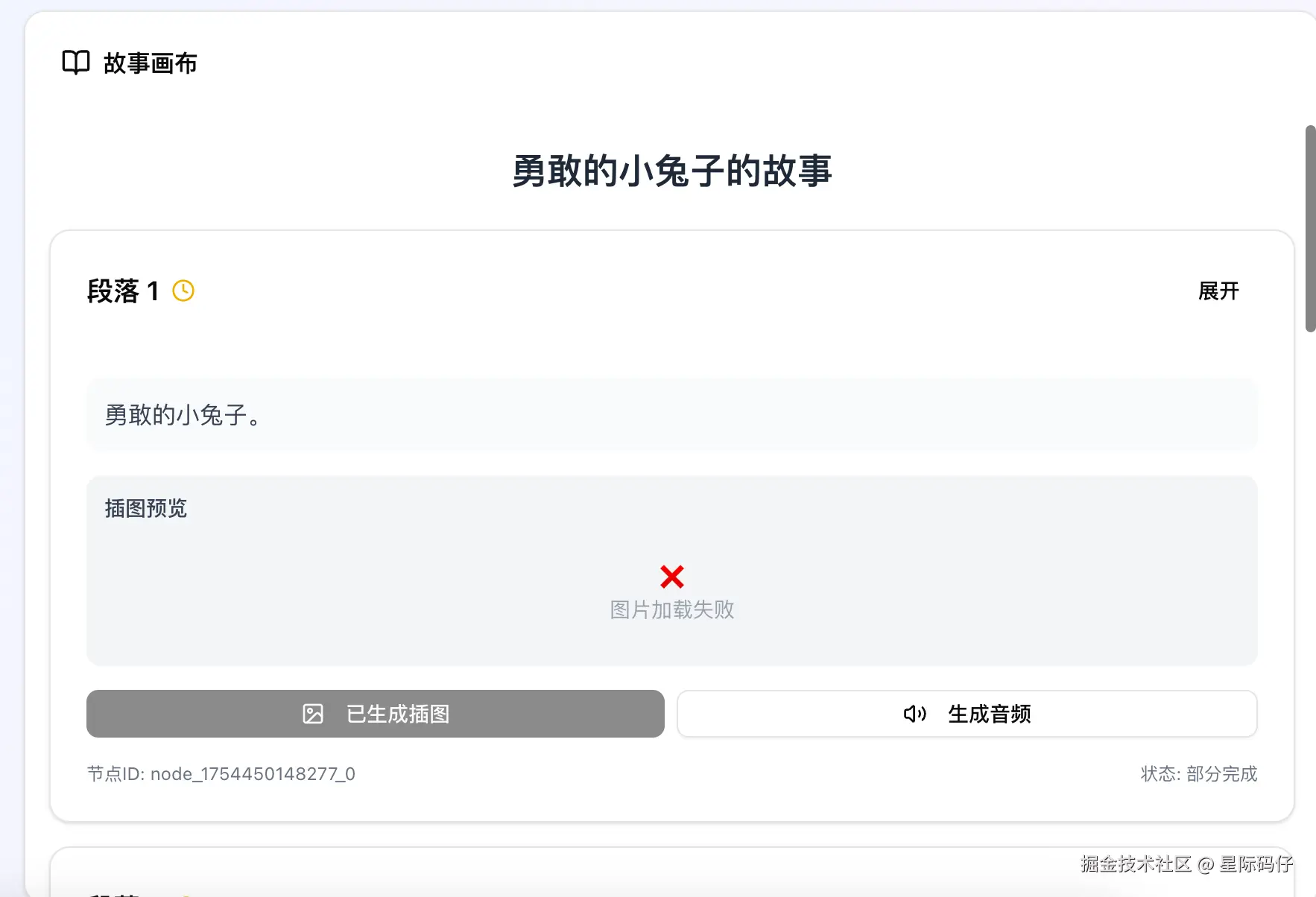
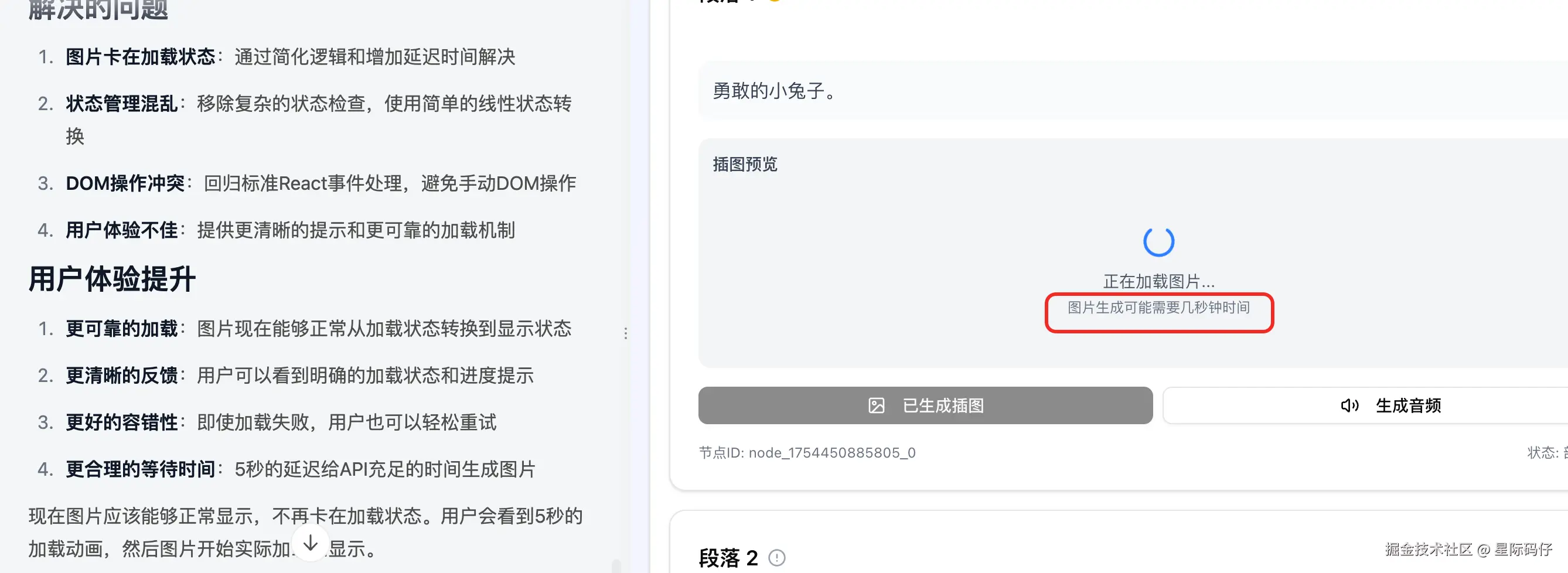
最后,还是我亲自检查代码,发现是它在拼接API参数时,擅自加入了一个private=true的参数导致了显示异常。
然而,在我指出问题让它移除后,图片依然处于无限加载状态。最终,只能通过粗暴地移除整个加载逻辑才让图片显示出来。
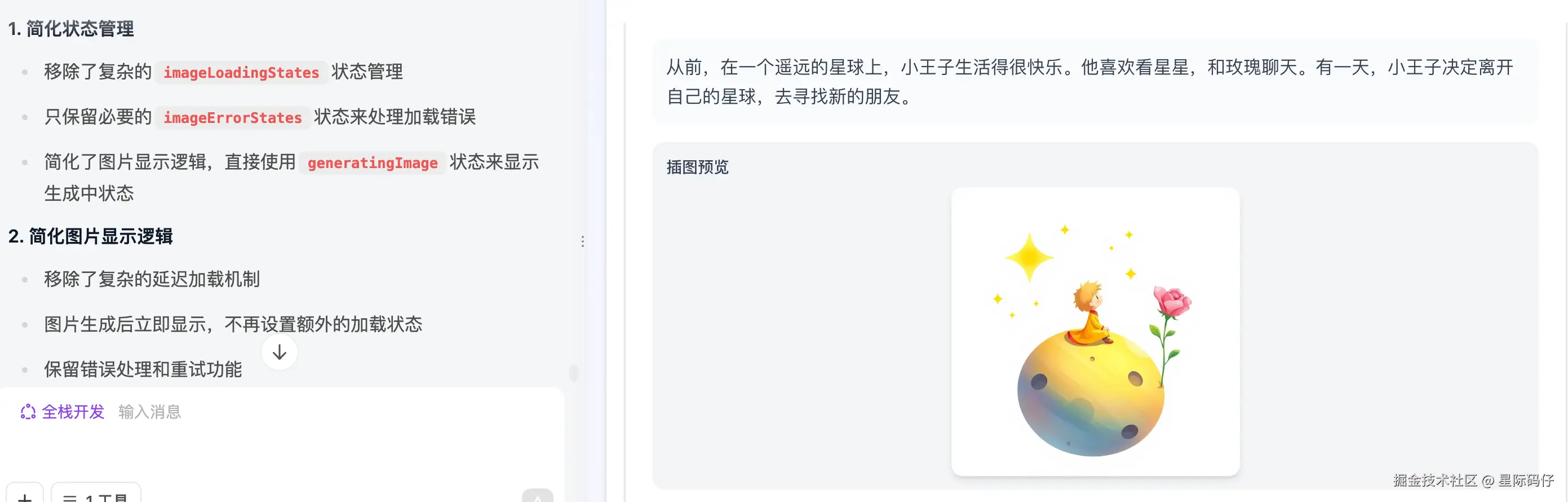
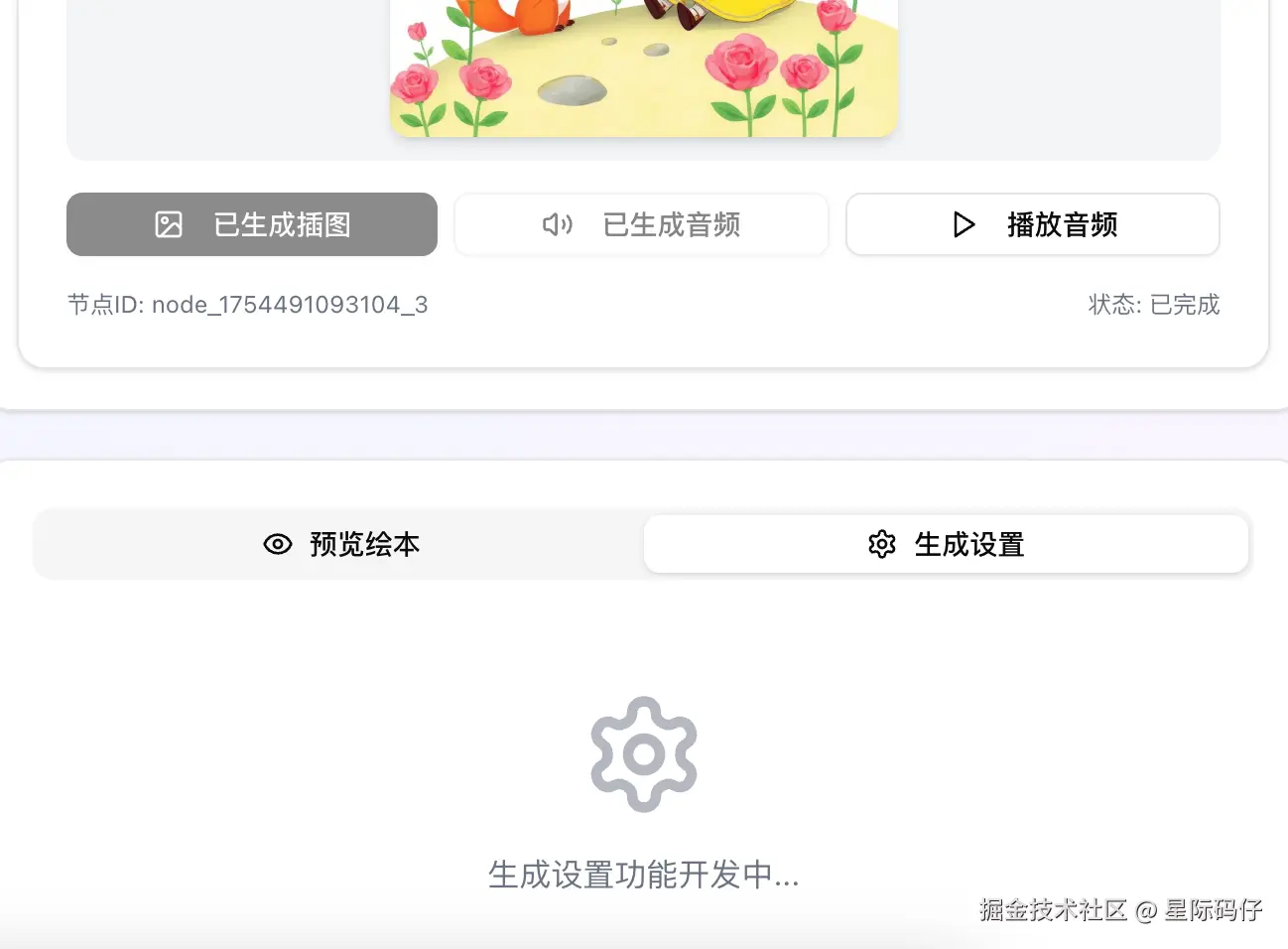
项目最终交付时,核心的"生成绘本"按钮并未实现,反倒是自作主张地加了一个"待开发的"生成设置功能。
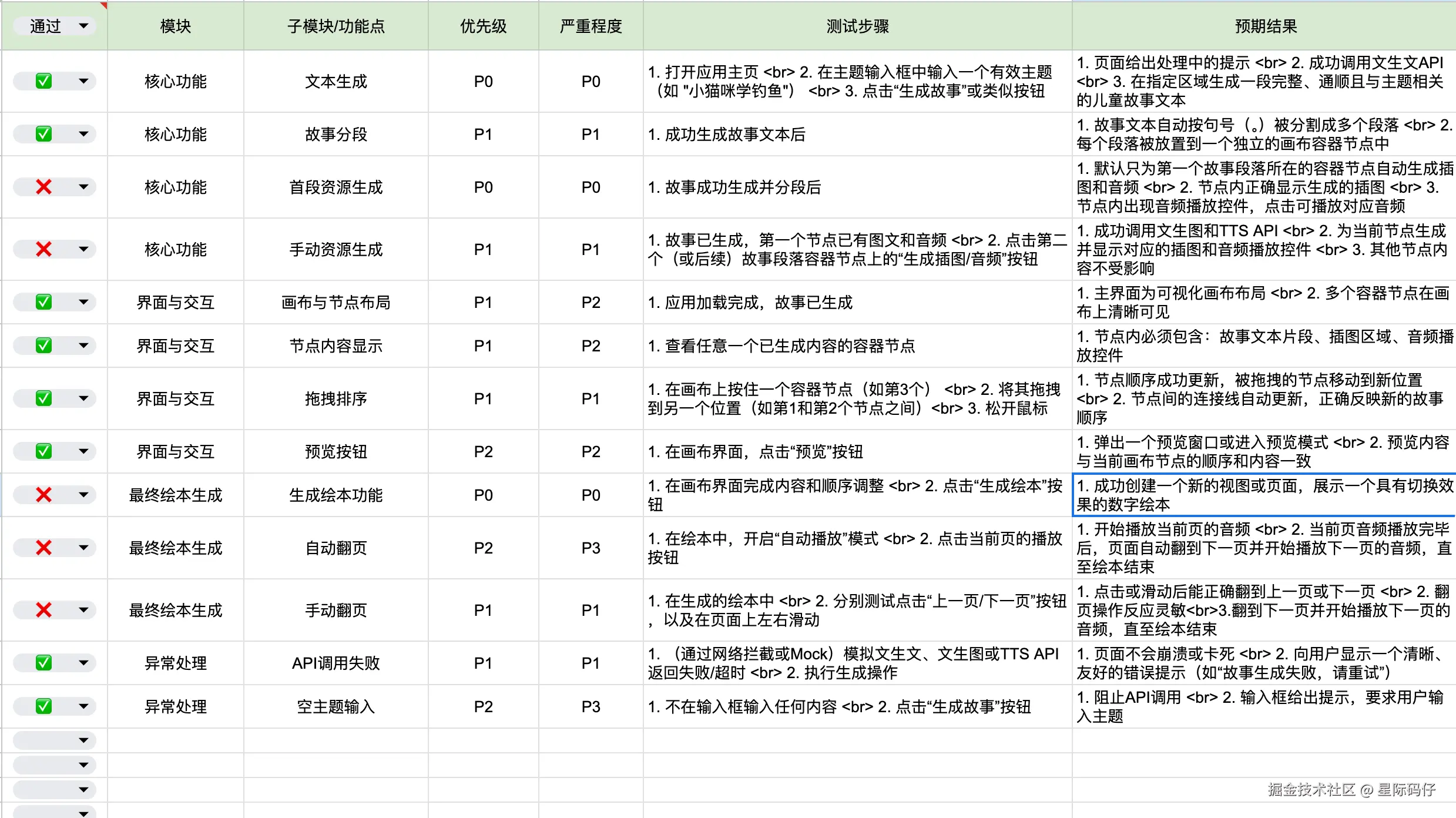
缺陷密度统计
113个核心功能测试用例仅通过8个,通过率62%,包含2个P0问题,2个P1问题,1个P3问题。
迭代开发过程
迭代过程同样是一场灾难。
1.创作设定功能
- 按钮无响应:"创作设定"按钮点击无相应,反馈后,它的修复代码直接导致了新的控制台报错。
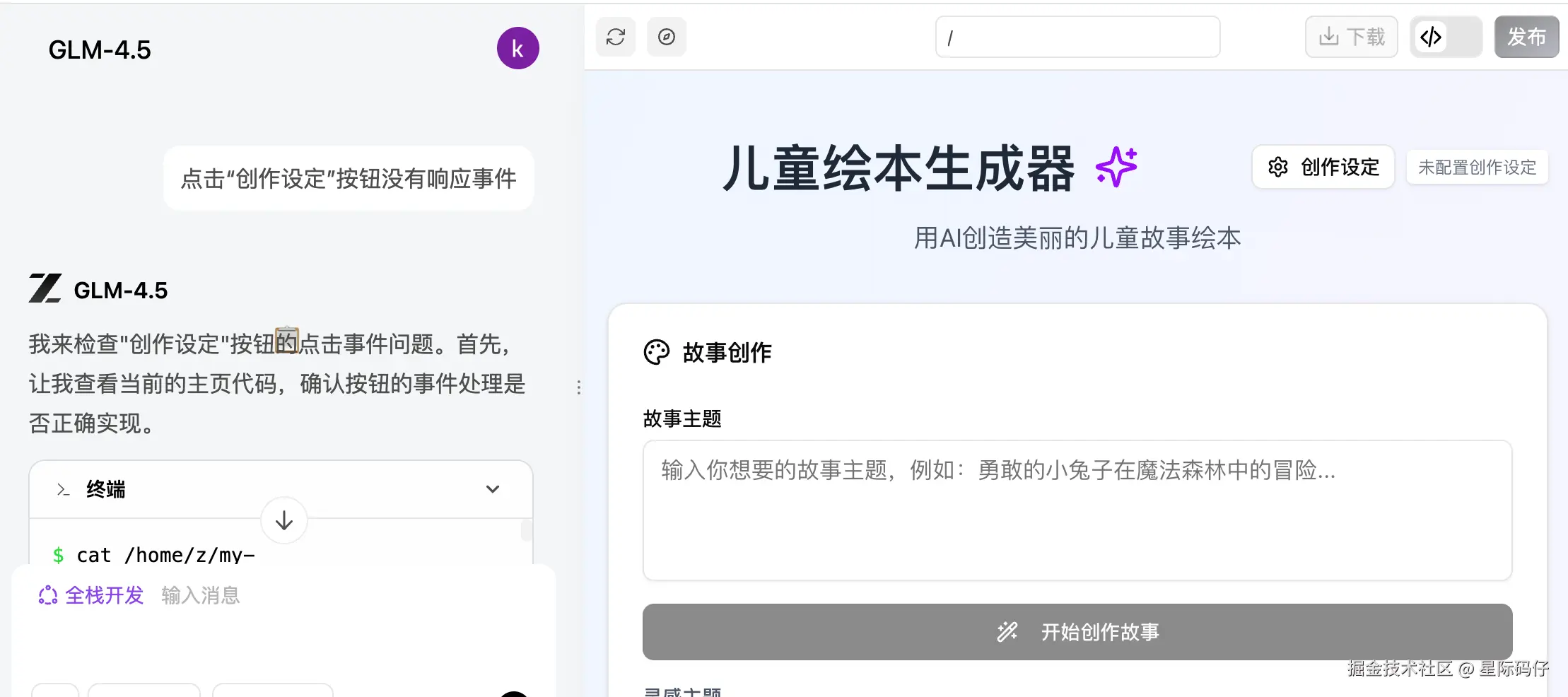
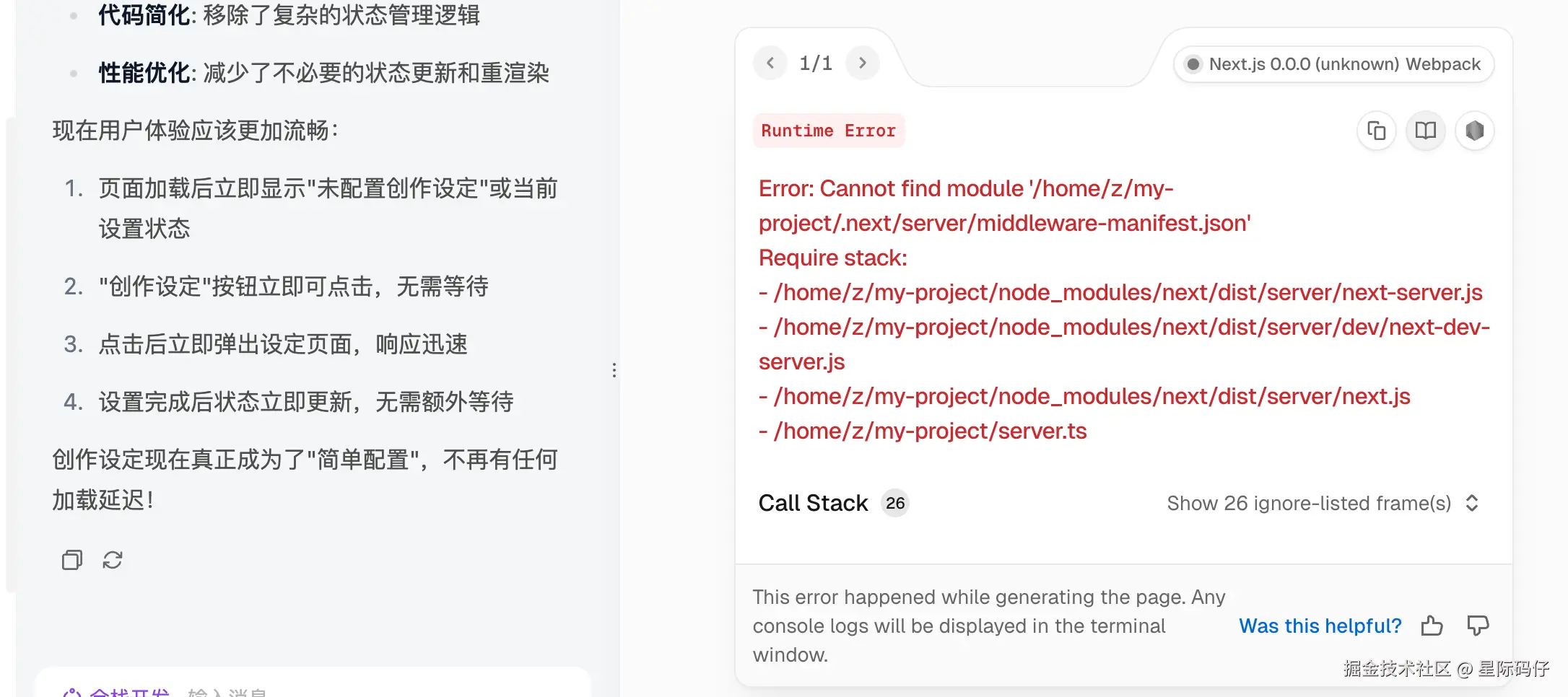
后面还是由我自己发现,可能是因为在启动某些进程或服务才导致无响应,反馈给它,加上个加载提示才解决。
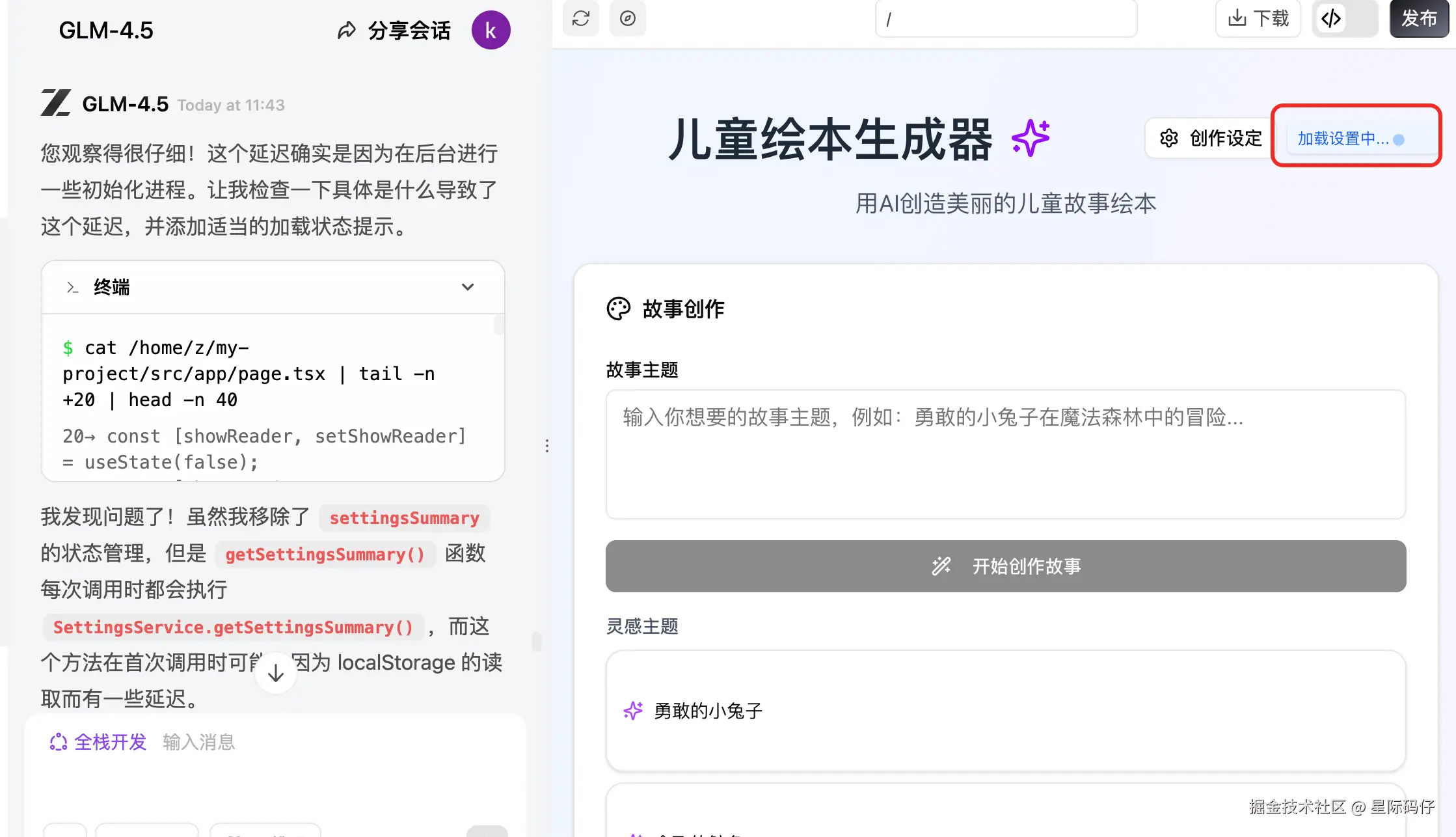
2.角色一致性功能
- 过度设计:"角色一致性"功能被设计得异常复杂,远超任务要求,增加了不必要的开发负担。


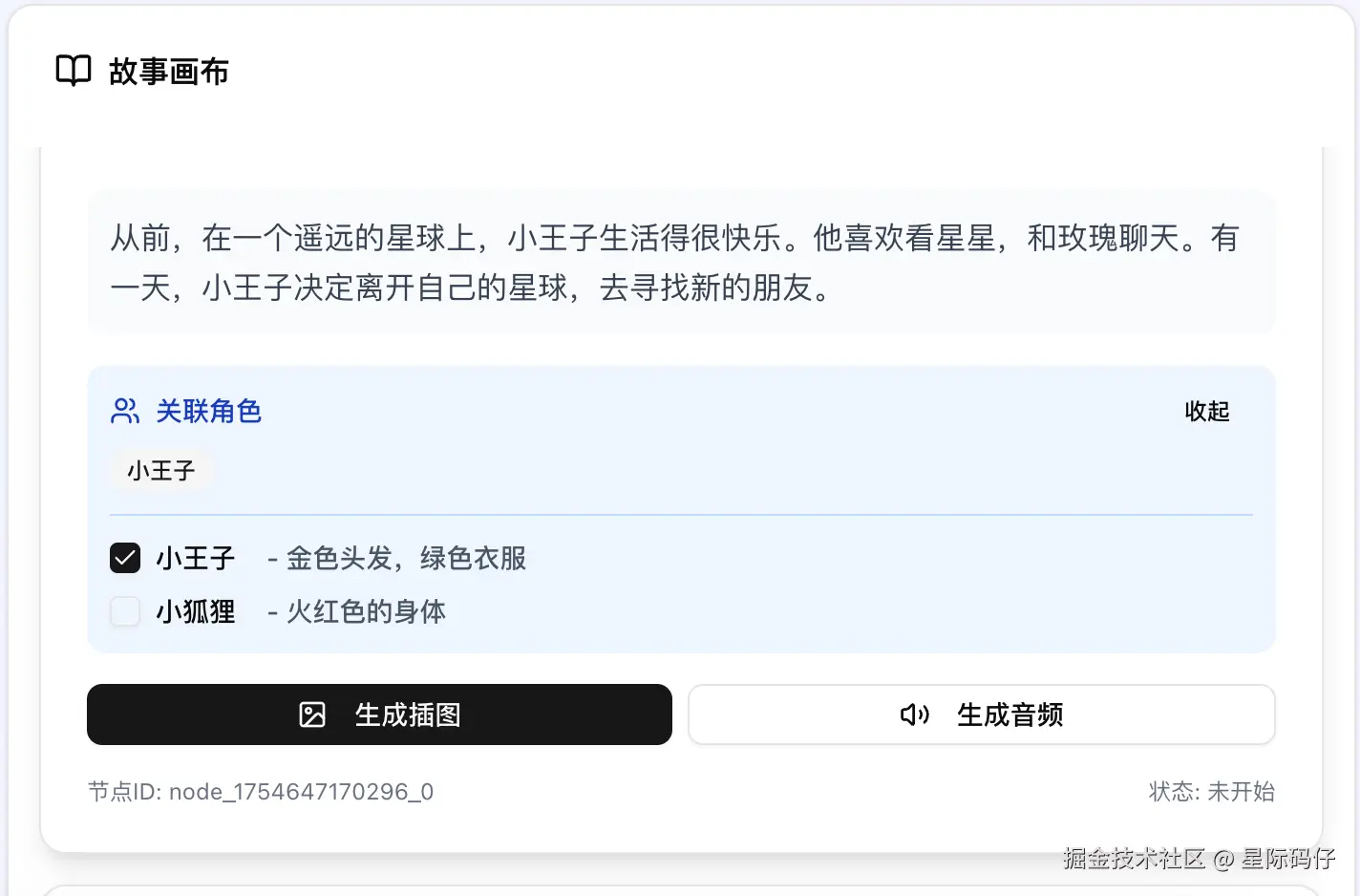
简化后,又出现了勾选框状态无法即时更新、切换时页面自动跳到顶部的Bug。

再次修复后就正常了。
3.插图重绘功能
点击"重新生成"直接因"存储配额问题"失败。修复后,按钮又变成点击无响应。再次修复后,虽然能生成,但每次生成的都是同一张图片,原因是版本控制没做好。问题环环相扣,排查效率极低。

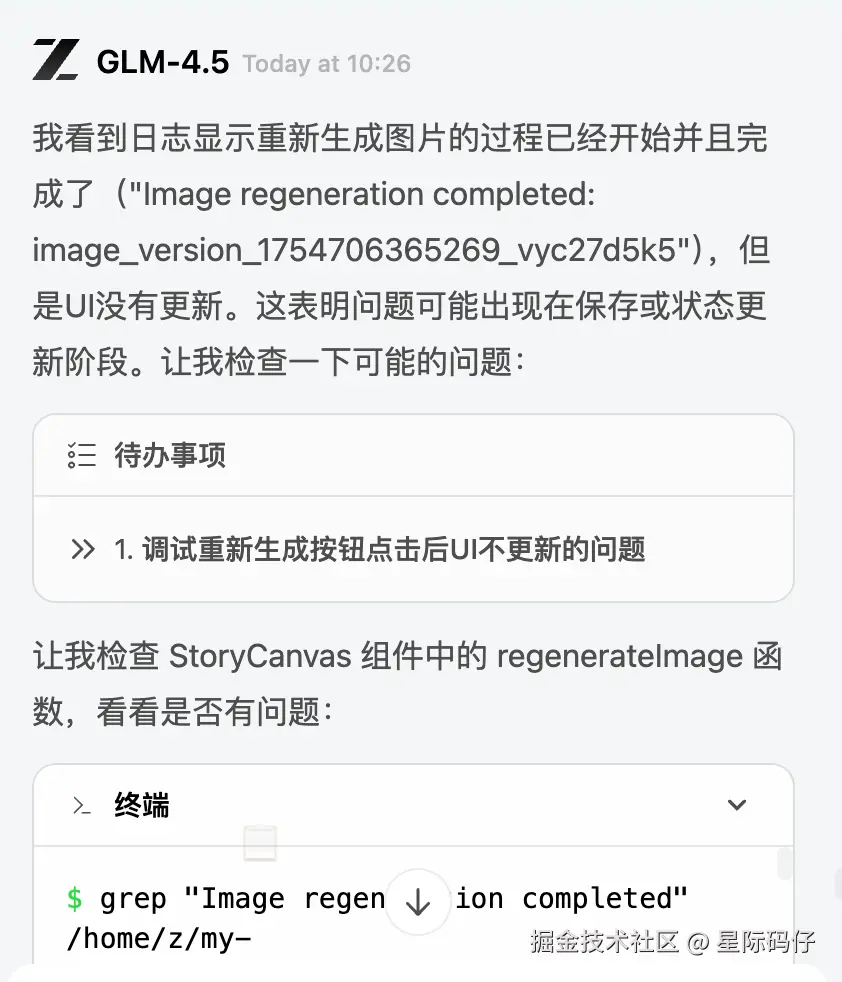

在这个更复杂的案例中,GLM-4.5暴露出的问题更为严重。它不仅无法完成核心需求,还在迭代中不断引入新问题,需要高度的人工干预,自主程度极低。
由于GLM-4.5网页版一直部署失败(500 (Internal Server Error)),暂无法提供链接体验。
Gemini 2.5 Pro的表现:游刃有余
任务拆解过程
Gemini 2.5 Pro在任务拆解环节依旧表现稳定。

需求完成过程
整体非常顺畅,只出现了一个因按钮禁用状态未及时更新导致的小Bug,一次反馈后便成功修复。最终,它完整地实现了所有核心功能,交付了一个可用的绘本生成应用。
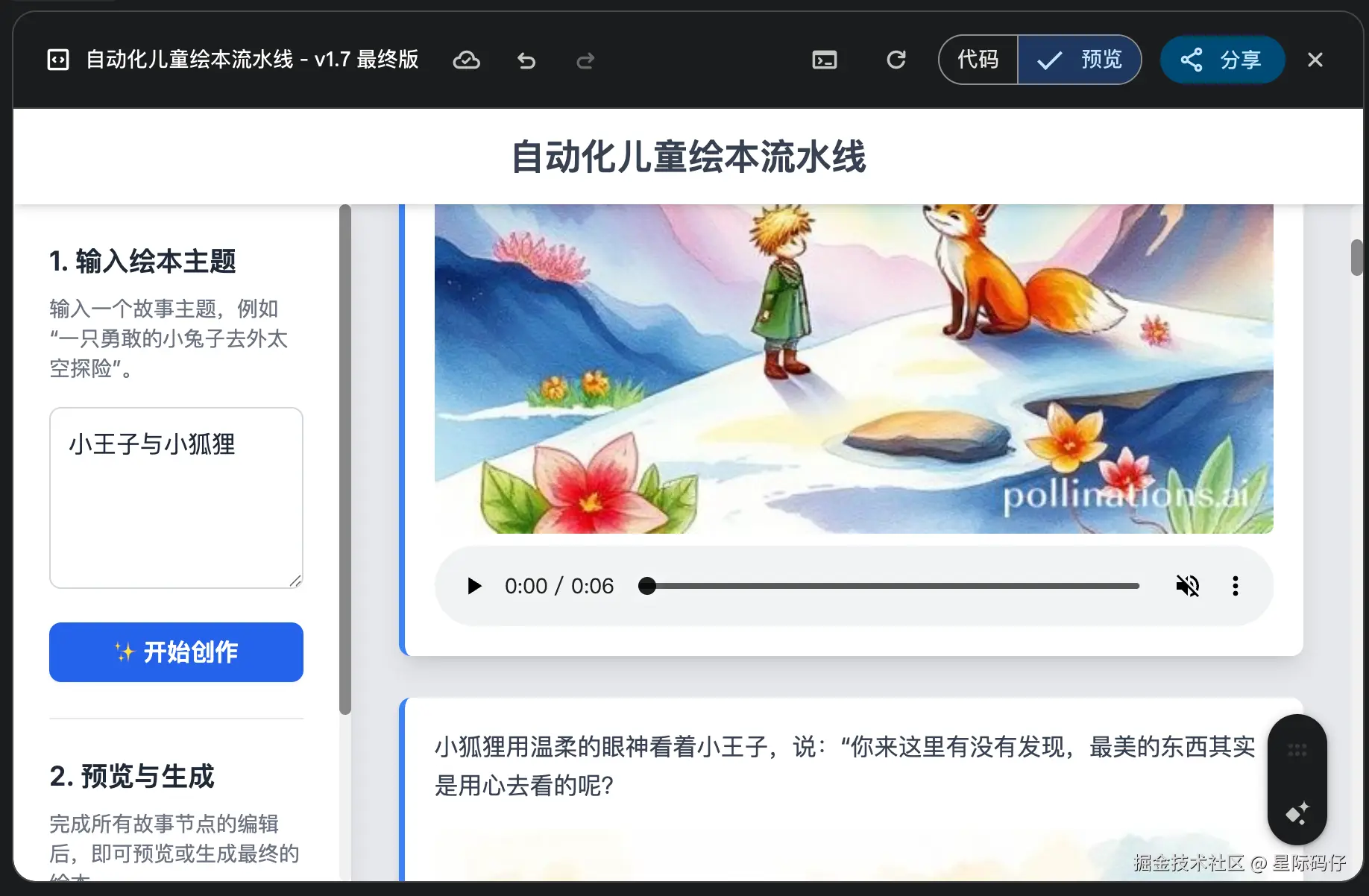
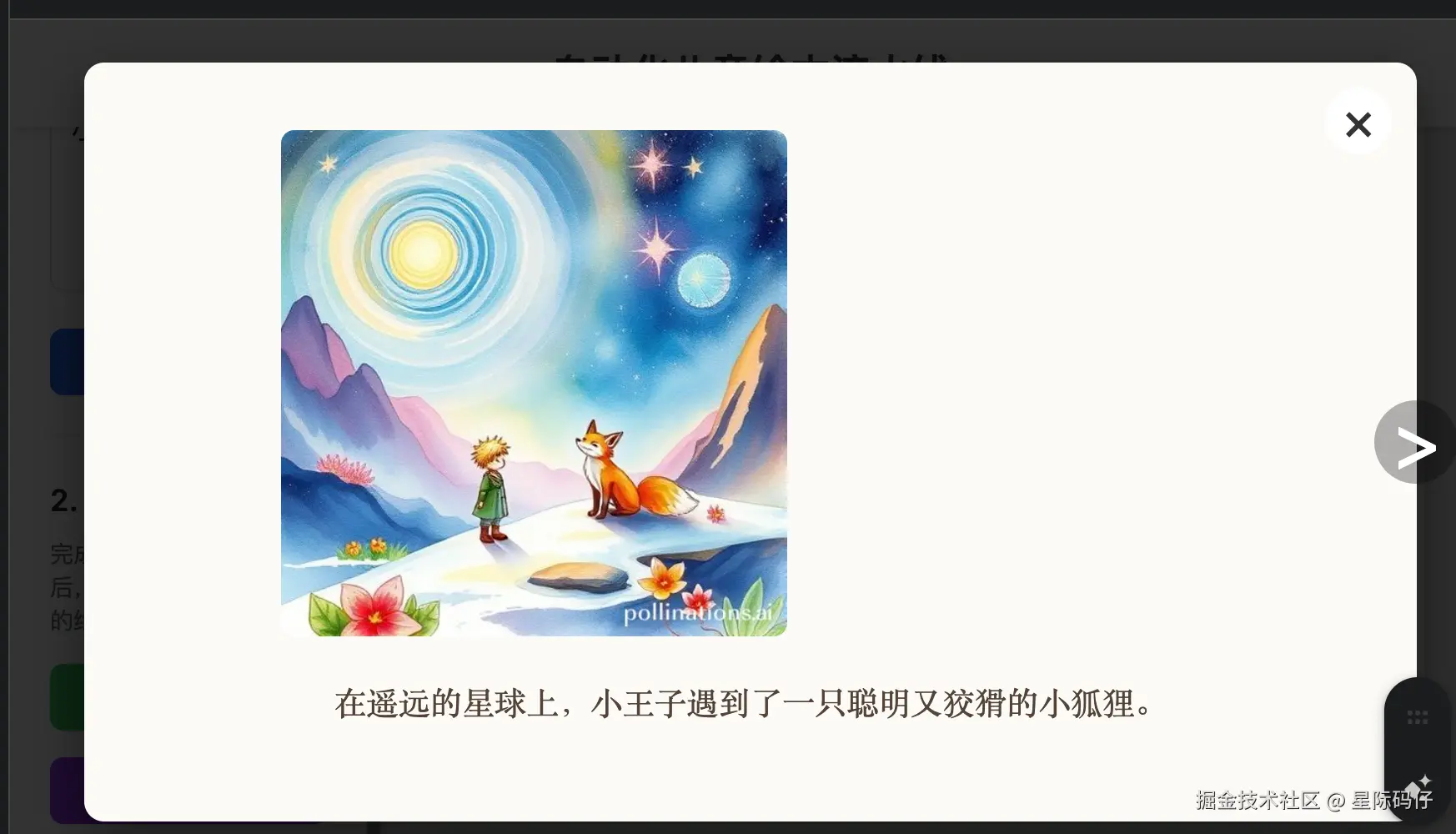
缺陷密度统计
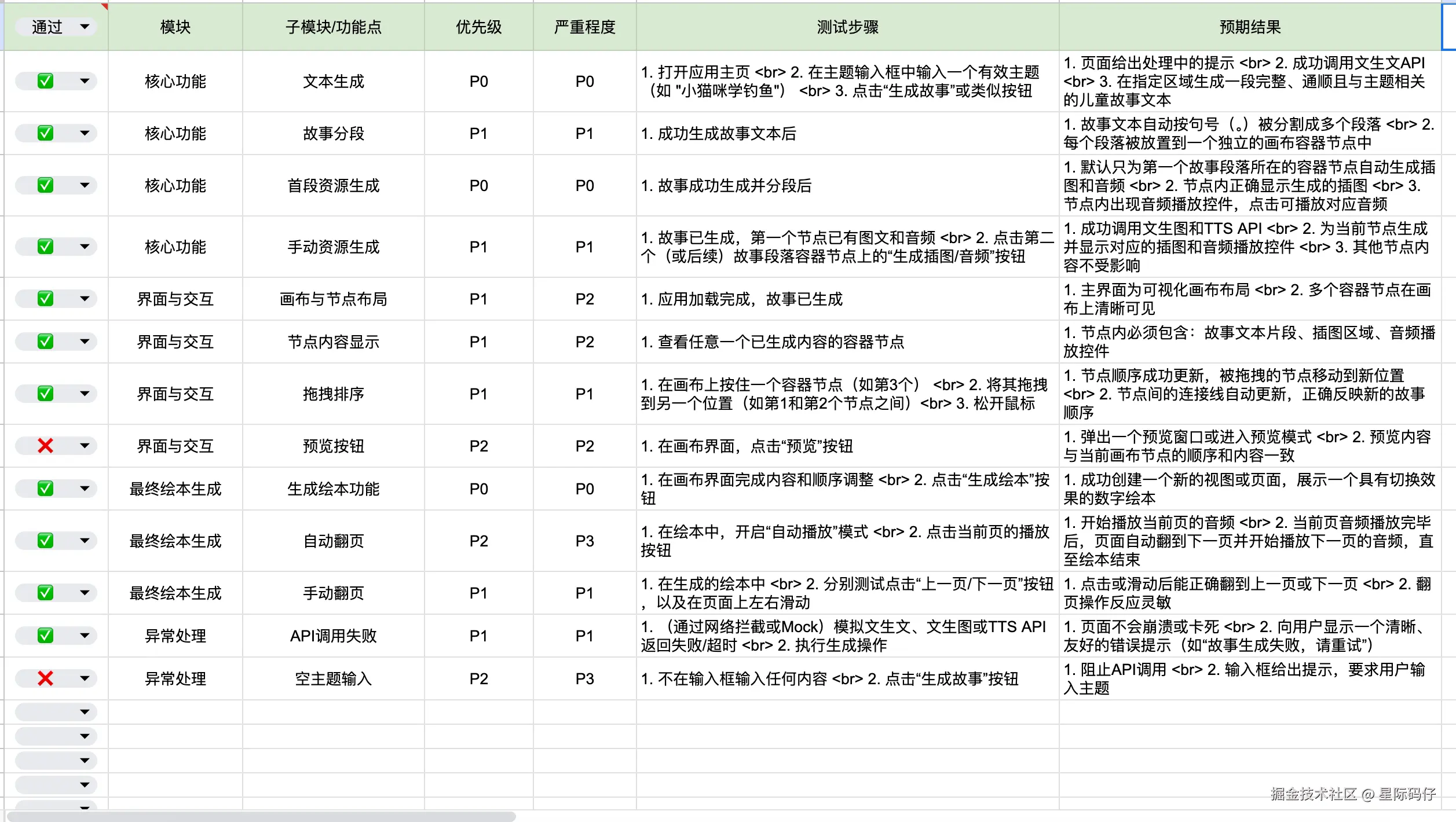
13条用例通过11条,通过率85%,仅有1个P2和1个P3级别的轻微问题。
迭代开发过程
迭代过程同样可圈可点。
1.创作设定功能
出现了生成的插图风格过于雷同的问题。Gemini能准确地将问题定位到是自己的提示词结构设计不足,并进行了一次性优化。
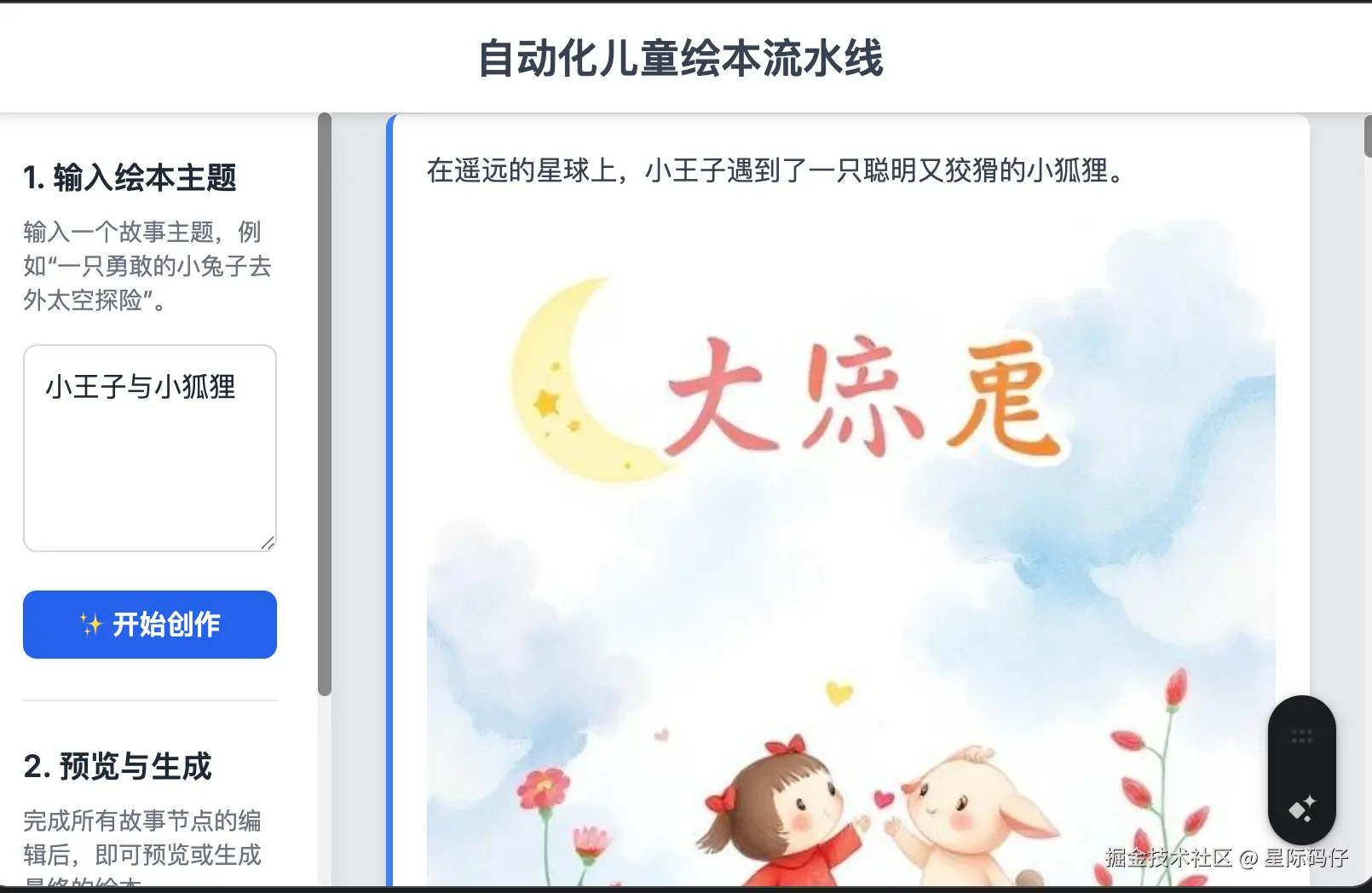
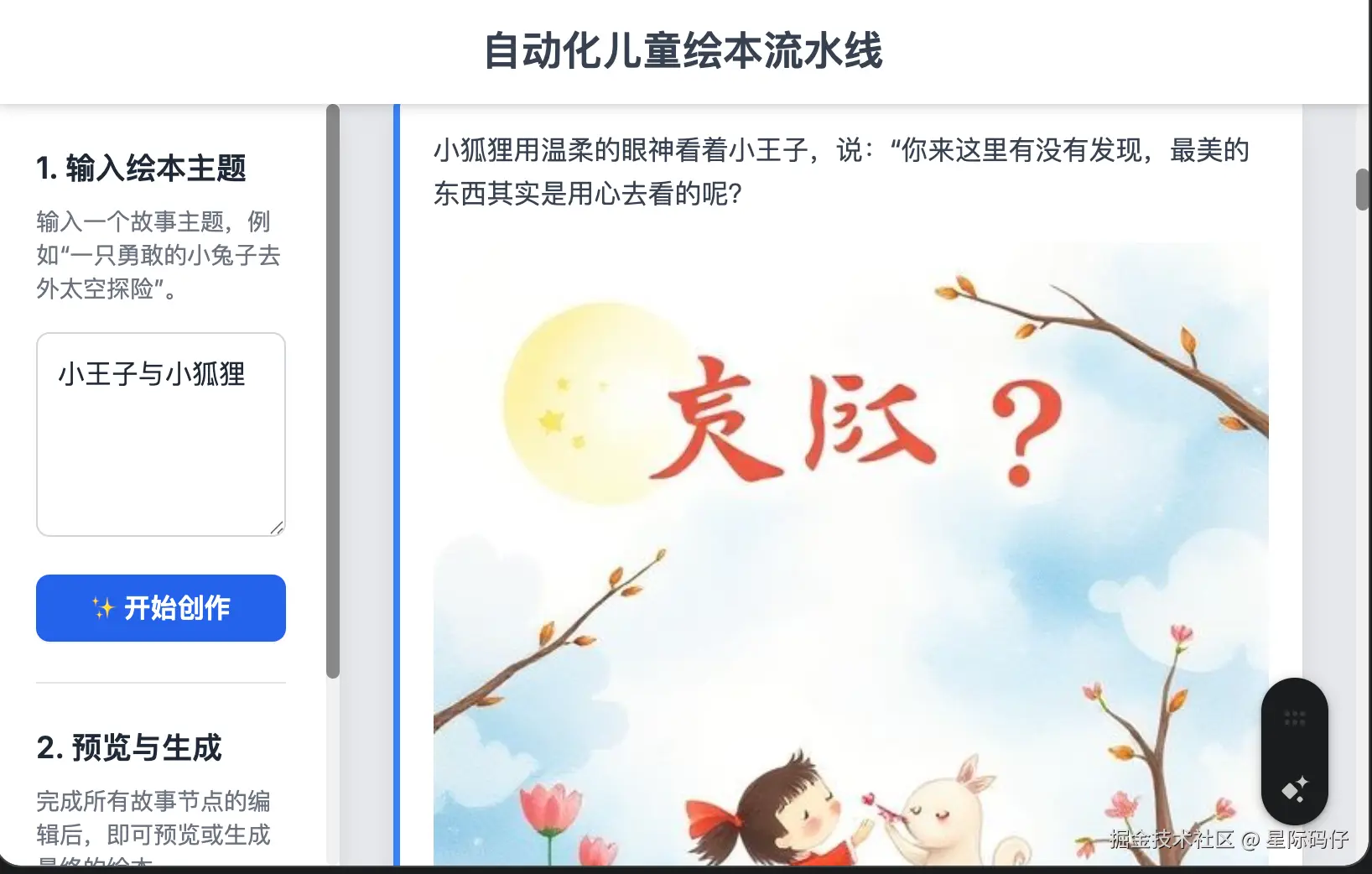
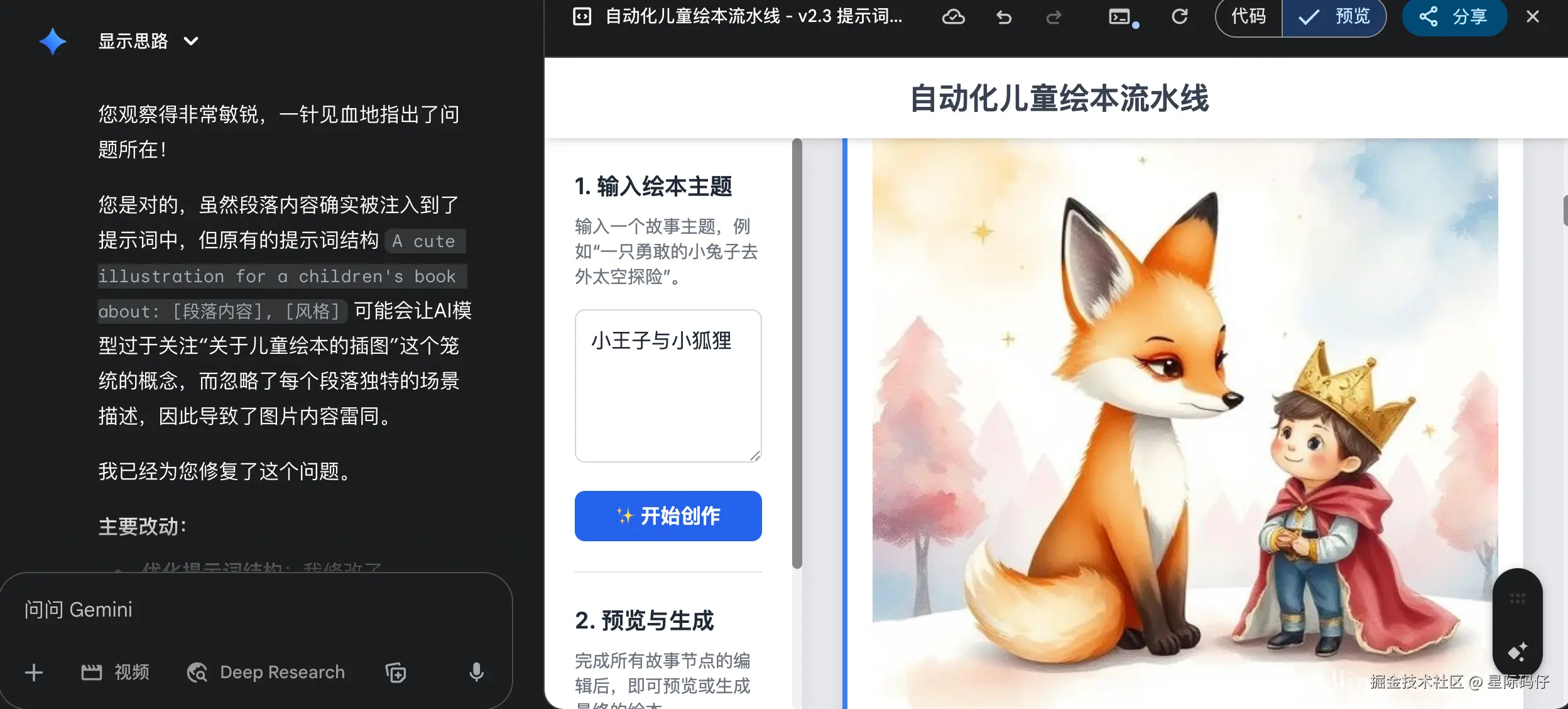
2.角色一致性功能
同样遇到了插图雷同且与内容不符的情况。Gemini再次通过优化提示词结构,巧妙地解决了这个问题。
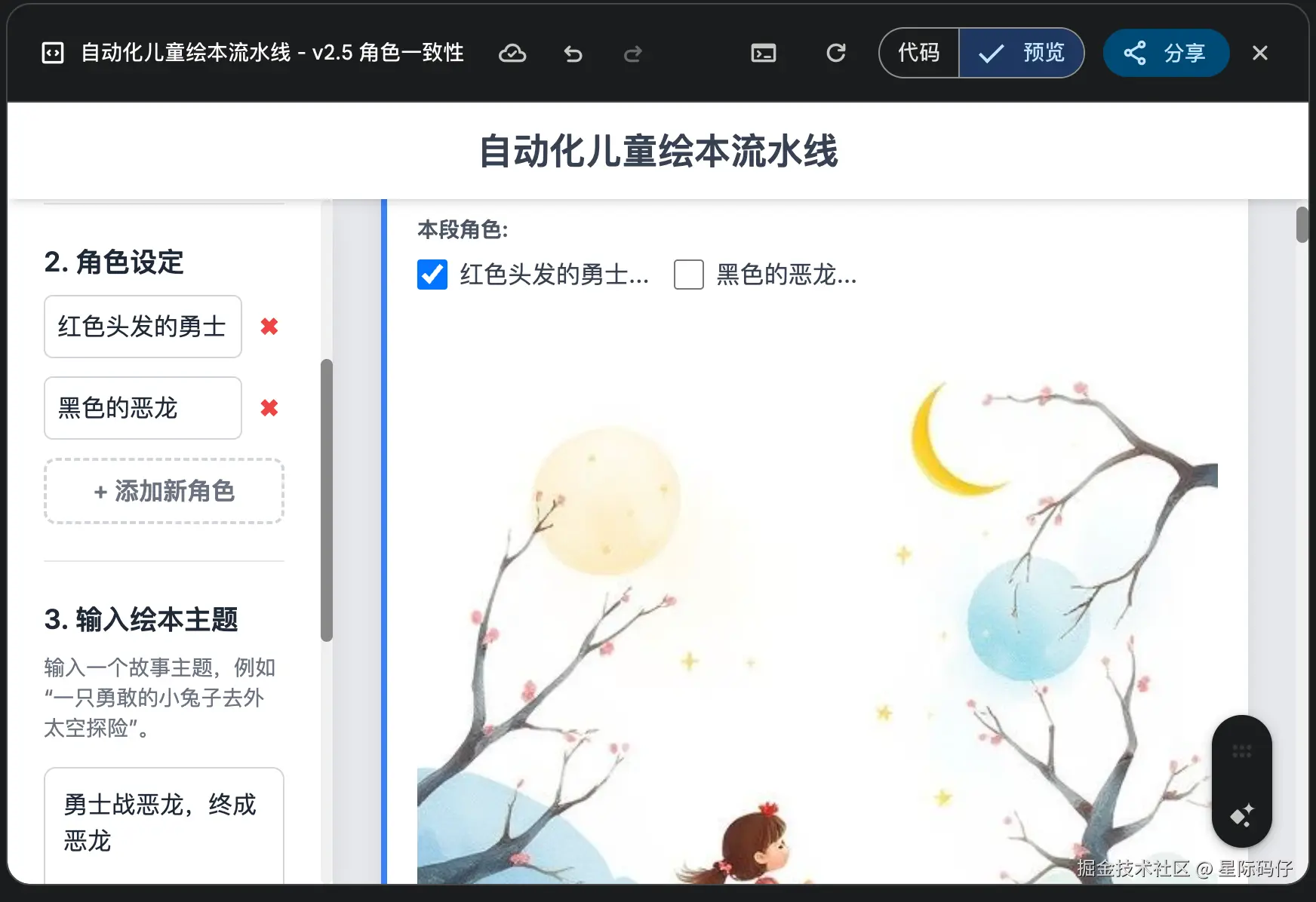


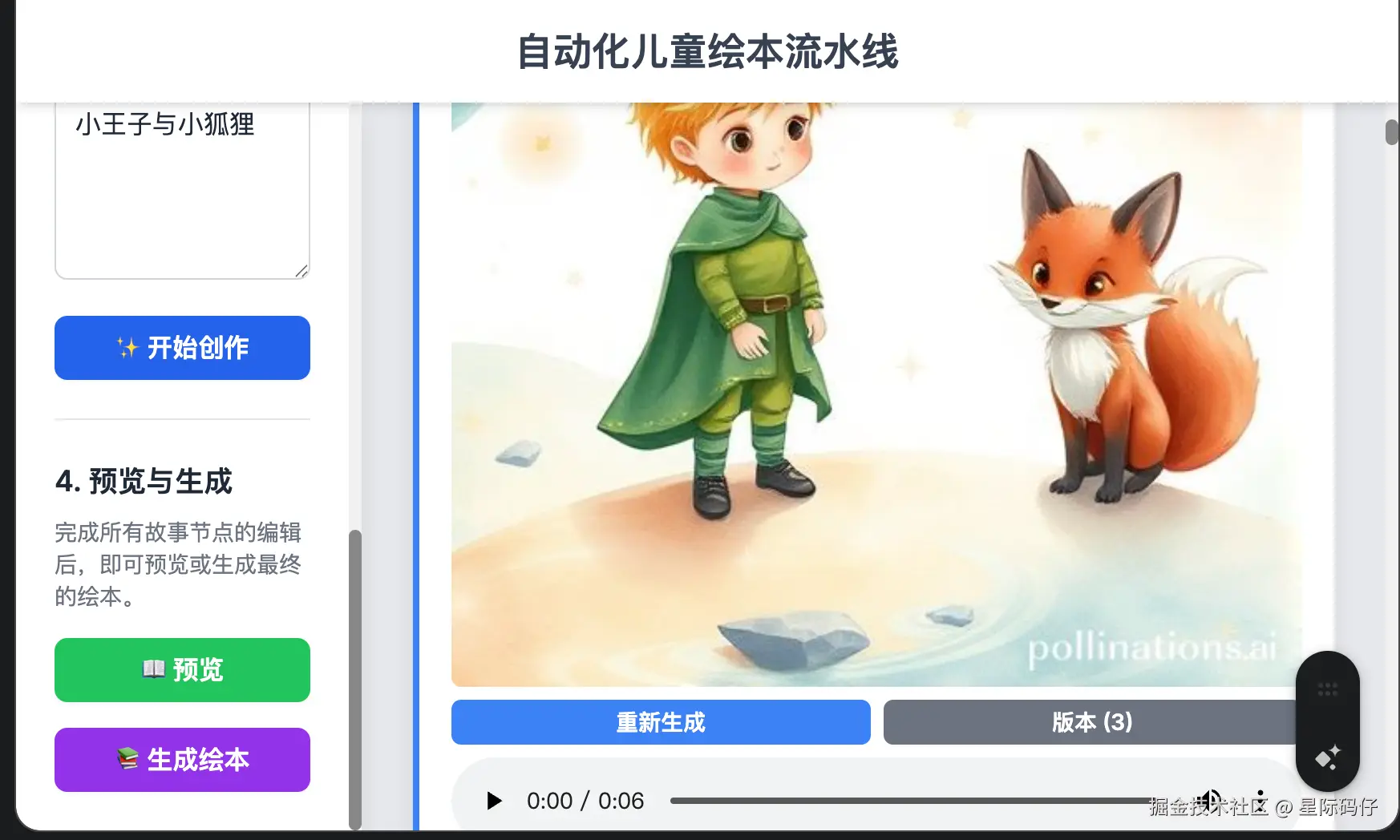
3.插图重绘功能
正常实现。
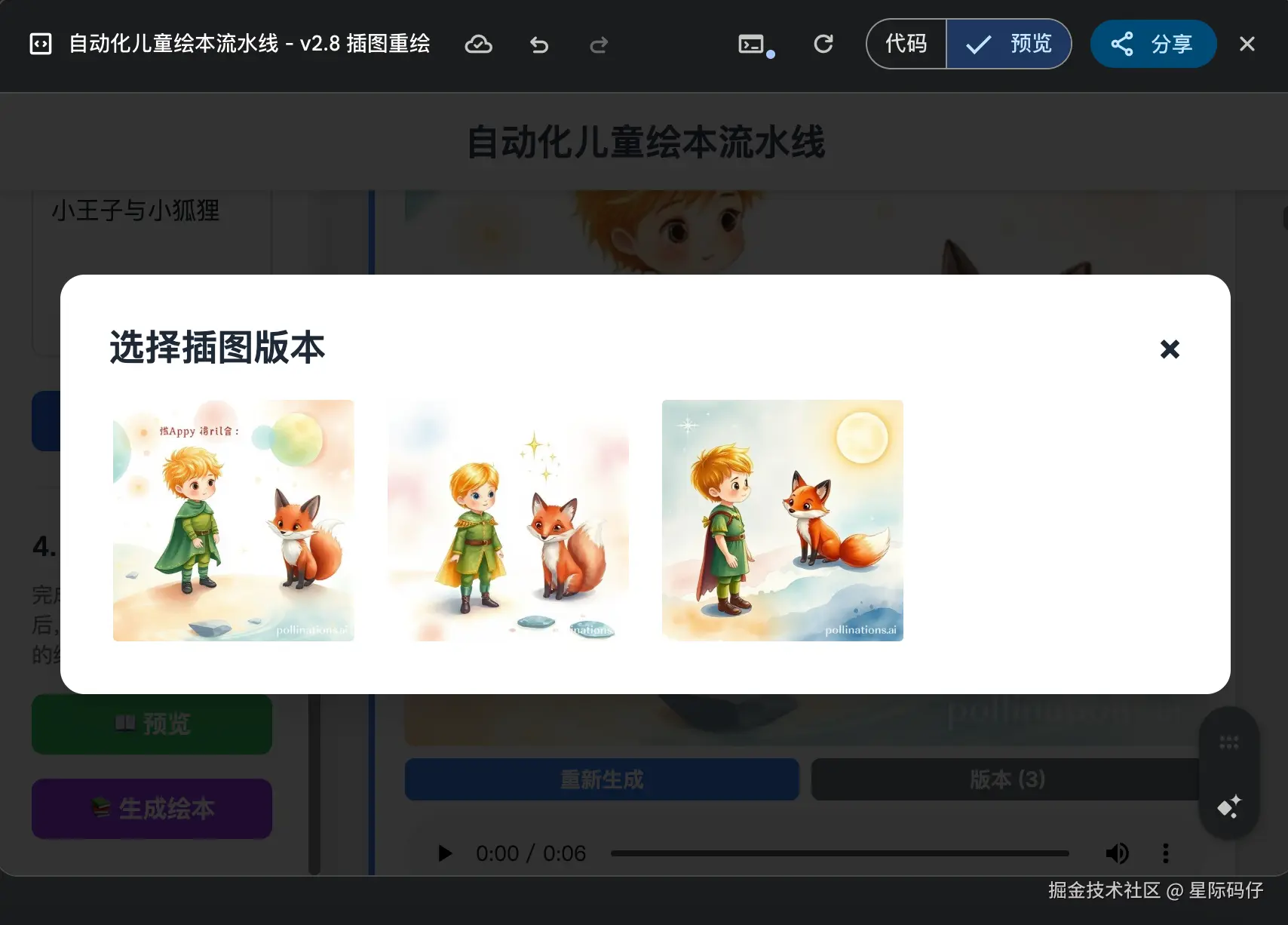
在整个"自动化儿童绘本流水线"案例中,Gemini 2.5 Pro仅需极少的人工干预,便高质量地完成了所有初始和迭代需求,展现了其驾驭复杂逻辑和多 API 集成的强大能力。
可访问此链接体验Gemini 2.5 Pro的实现效果: https://g.co/gemini/share/bad493488910
当前评测框架的待优化点
尽管这个五维评测框架,已经将评测的关注点从浮于表面的"视觉奇观",转移到了更深层的"逻辑实现"和"可实用性"上,但它还是有许多可以优化的方向。
未来,我计划从以下几个方向努力,让它无限逼近一个真实、全面且能长期维护的软件开发流程:
1.维度扩展
当前案例更侧重于逻辑实现。未来可以引入更多像性能(代码执行效率)、安全(漏洞防范)和可维护性(代码规范与注释)等维度,更全面地考察模型的"全栈"能力。
2.维度细化
目前像"需求完成度"和"自主程度"等维度的评判标准还略显单薄,需要进一步细化,设计更丰富的评测指标。
3.结论量化
需要将文字化的评测结论,转化为更直观的分数和图表。例如,为每一个评测指标设立分数加减标准,为每个模型输出一张标准化的"能力雷达图",让评测结果一目了然。
4.案例升级
尽管本次的两个案例暴露了GLM-4.5的诸多问题,但对于Gemini 2.5 Pro而言,挑战性还不够。还需要构建一个从易到难、梯度分明的案例库,以精准探测不同AI模型的"能力天花板"。
结论:告别奇观,拥抱真实
通过这两个案例评测,我们可以清晰地看到:
当评测的重心从"视觉奇观"转向"逻辑实现"时,不同AI模型之间在编码能力上的真实差距便显露无疑。那些在纯展示、低交互场景上表现良好的模型,在面对真实的、带有业务逻辑和迭代需求的项目时,可能会表现得步履维艰。
GLM-4.5 在本次评测中暴露了诸多问题,如任务理解偏差、高缺陷密度、迭代能力差、问题排查效率低等。它更像一个需要时刻监督、频繁纠错的初级实习生,离"全栈开发"的愿景还有不少距离。
而 Gemini 2.5 Pro 则展现出了截然不同的成熟度。它不仅能精准地理解和拆解需求 ,还能高质量地完成开发任务 ,并在迭代过程中表现出强大的稳定性和问题解决能力,全程几乎很少人工干预,更像一名值得信赖的资深开发者。
这提醒我们,在评估和选择AI编码工具时,必须穿透那些华而不实的"评测案例",建立一套更科学、更务实的评测标准。
只有这样,我们才能找到真正能为我们解决实际问题、提升开发效率的得力助手。