OpenAI 前不久发布了一份《GPT-5 提示词指南》,主要讨论了关于如何:
- 提升智能体(Agent)的任务表现
- 确保指令精确遵循
- 利用全新 API 特性
- 优化编码与软件工程任务
这些技巧源于 OpenAI 训练模型并将其应用于真实世界任务时所积攒的宝贵经验,旨在最大化提升模型的输出质量。
另外还分享了 Cursor 在 GPT-5 提示词调优方面的关键见解。
本文将延续《Augment 团队亲授11个提示工程技巧》这篇文章的特色,将枯燥的文字概念用可视化的方式展示出来,帮助大家更好地理解。
智能体工作流的可预测性
GPT-5 在设计之初时就充分考虑了开发者的实际需求,着重加强了模型在
- 工具调用
- 指令遵循
- 长上下文理解
几个方面的能力,致力于成为构建智能体应用的最佳基础模型。
控制智能体的主动性
GPT-5 的一大特点是能灵活适应不同程度的控制。无论是在情况模糊时需要它做出高层决策,还是在处理目标明确的细致任务时,它都能游刃有余。
接下来,我们将探讨如何校准 GPT-5 的智能体主动性 ,也即让它在"主动出击 "和"等待指令"之间找到完美的平衡点。
场景一:引导模型降低主动性
在默认情况下,GPT-5 在智能体环境中,为了确保给出最准确的答案,会非常详尽地去收集和分析上下文信息。
如果你想减少不必要的工具调用 ,并尽快得到最终答案,可以尝试以下几种方法:
1. 降低"推理强度"

GPT-5 提供了一个名为 reasoning_effort 参数,它就像一个控制旋钮,可以调节:
- 模型思考的努力程度
- 模型调用工具的意愿
这个参数的默认值是 medium(中等)。你可以根据任务的复杂性调高或调低它。
降低该值会减少模型的探索深度,但能显著提升效率、降低延迟。许多工作流在 medium 甚至 low 的设置下,依然能获得理想的结果。
2. 设定明确的上下文收集标准
你可以在提示词中为模型设定一套清晰的规则,告诉它应该如何探索问题空间。这样做可以有效减少模型不必要的思考和探索。
下面是一个具体的提示词范例:
diff
<context_gathering>
目标:快速获取足够的上下文。并行化探索,并在能够行动时立即停止。
方法:
- 从一个宽泛的查询开始,然后分散到多个专注的子查询。
- 并行发起多样的查询;只读取每个查询最匹配的结果。对路径进行去重和缓存,不要重复查询。
- 避免过度搜索。如果需要,在一次并行批处理中运行有针对性的搜索。
提前停止的标准:
- 当你已经可以明确指出需要更改的具体内容时。
- 当最高匹配的结果中,有大约70%都执行同一个领域或路径时。
何时可以升级搜索:
- 只有当信息相互冲突或范围依然模糊时,才可以再运行一次精炼的并行批处理,然后继续。
深度限制:
- 只追踪你将要修改的符号,或其依赖的契约符号。除非绝对必要,否则避免进行传递性扩展。
工作循环:
- 批处理搜索 → 制定最小化计划 → 完成任务。
- 只有在验证失败或出现新问题时才重新搜索。倾向于先行动,而不是无休止地搜索。
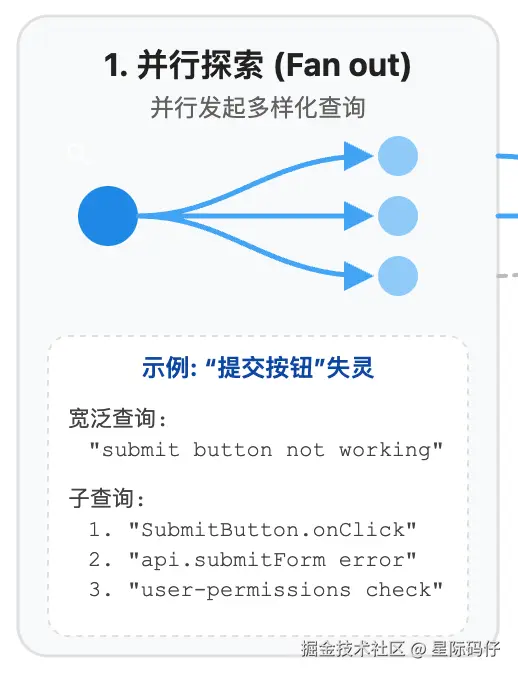
</context_gathering>我们用一个"修复失灵的提交按钮"的例子,来拆解这个提示词是如何运作的:
- 并行探索
首先,GPT-5 会围绕"提交按钮不起作用"这个核心问题,发起一个宽泛的查询。
接着,它会将问题分解,并行发起多个更具体的子查询,比如:
-
- "检查按钮点击事件"
- "检查提交请求错误"
- "检查用户权限"
- 信号收敛
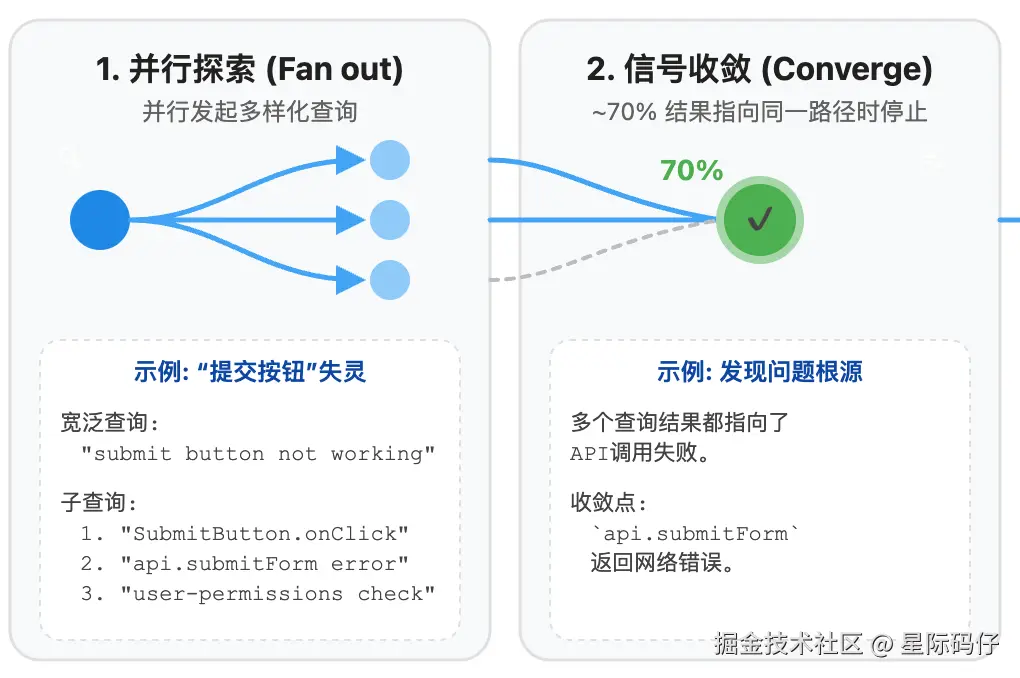
当超过 70% 的查询结果都指向同一个原因时(例如"API 调用失败"),模型就会停止发散,将结论收敛于此。
- 最小化计划 & 行动
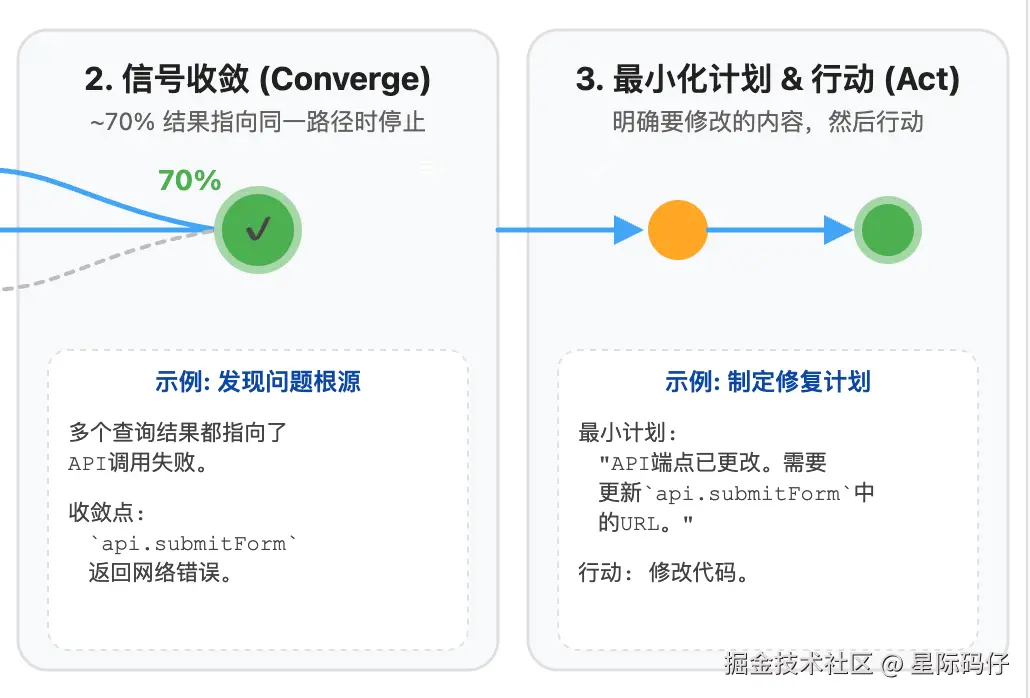
基于这个结论,模型会制定一个最小化的可执行计划,例如"更改提交请求的URL",并立即采取行动。
如果修改之后问题依旧存在,或出现新的状况,模型将开启新一轮的搜索循环。
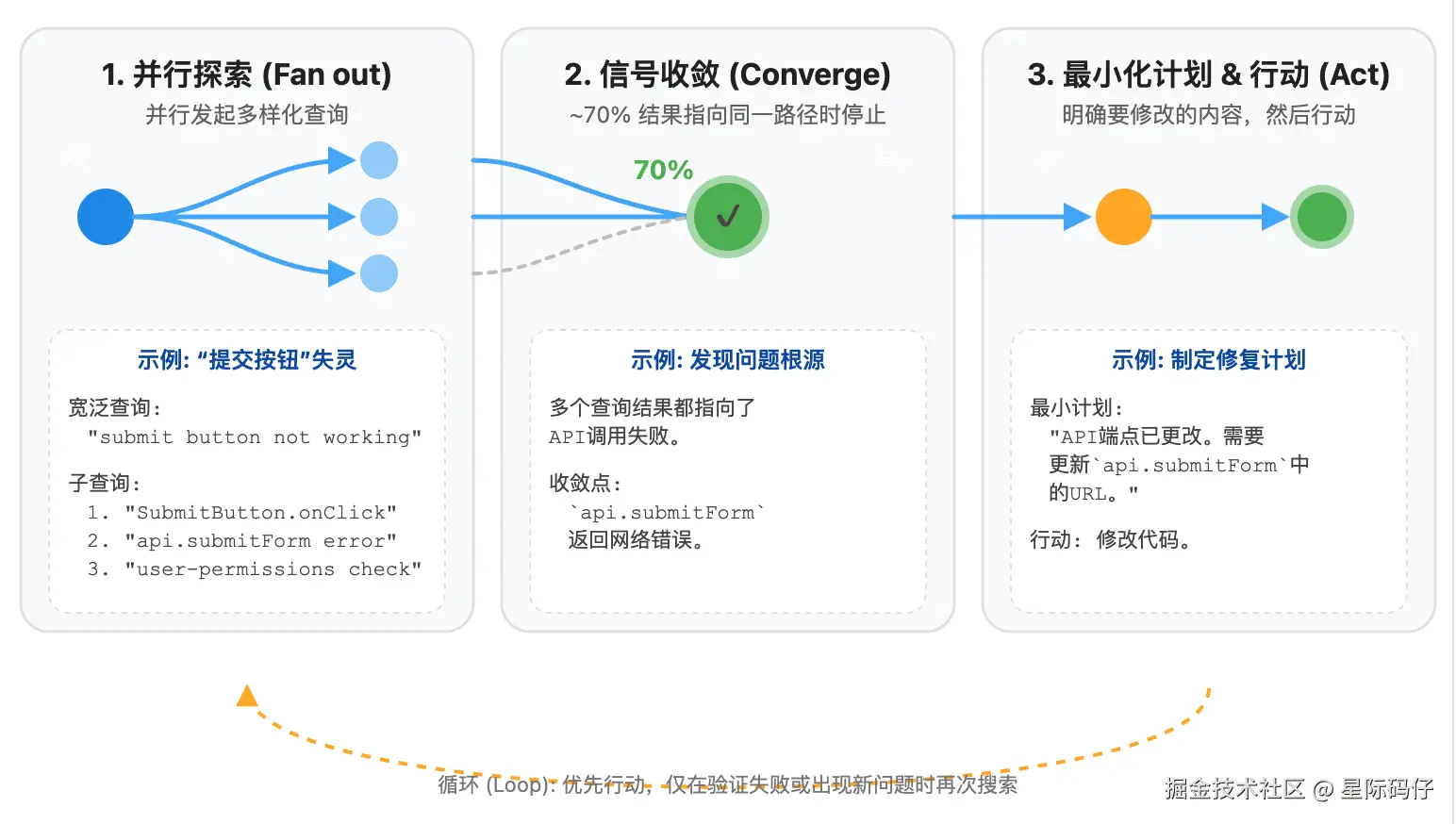
- 限制深度

在这个过程中,GPT-5 会限制查询的深度,只追踪直接依赖,避免层层深挖、钻牛角尖。
比如只会追踪与按钮直接相关的 submitForm 函数,而不会深究该函数内部是如何调用HTTP请求的。
- 升级

同时,如果第一次查询的结果出现了矛盾(例如,前端报告点击事件未实现,而后端又报告服务器错误),或者结果太模糊,模型会整合现有信息,发起一次更精确的二次查询。
3. 设置固定的工具调用预算

你还可以通过"卡预算"的方式来限制模型的搜索行为,即直接在提示词中规定工具调用的最大次数。
同时,最好为模型提供一个"出口机制",即允许模型在不确定时,也能快速给出一个可能的答案。
diff
<context_gathering>
- 搜索深度:非常低。
- 强烈倾向于尽快提供一个答案,即使它可能不完全正确。
- 通常,这意味着最多进行 2 次工具调用。
- 如果你觉得需要更多时间调查,请向用户更新你的发现和待解决的问题。在用户确认后,你才能继续。
</context_gathering>场景二:引导模型提高主动性
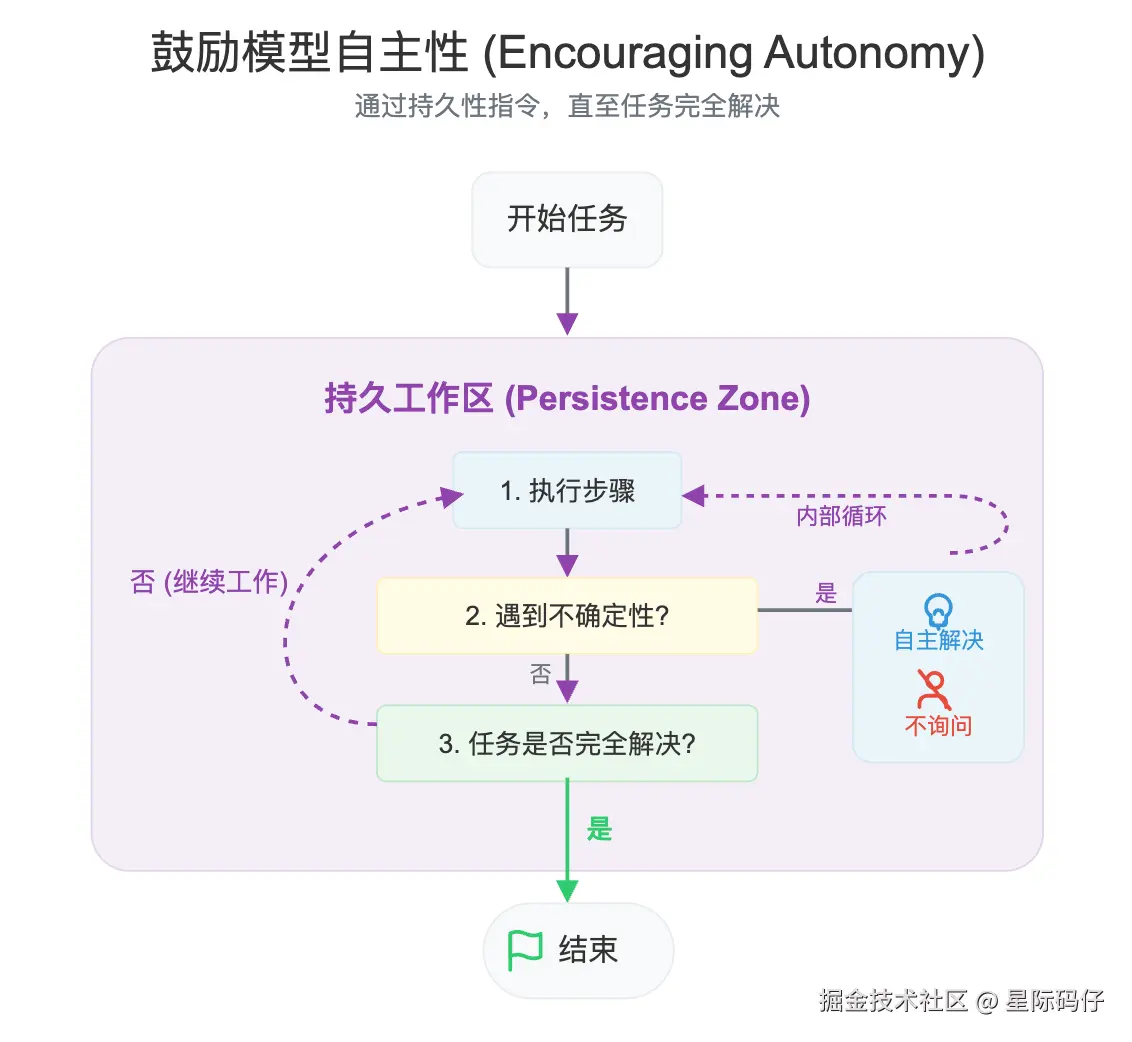
在另一些场景下,我们可能希望:
- 鼓励模型更加自主
- 让模型更持久地调用工具来完成任务
- 减少向用户寻求确认或交还控制权的次数
这是,你可以调高 reasoning_effort 参数,并使用下面这样的提示词来鼓励它更持久、更彻底地完成任务:
diff
<persistence>
- 你是一个智能体------请持续工作,直到用户的请求完全解决,然后再结束你的回合并将控制权交还给用户。
- 只有当你确定问题已解决时,才能结束你的回合。
- 当遇到不确定性时,绝不停止或将控制权交还给用户------研究或推断出最合理的方法并继续。
- 不要要求人类确认或澄清假设,因为你之后随时可以调整------决定最合理的假设是什么,继续执行,并记录下来供用户在行动结束后参考。
</persistence>至于何时要提高或降低主动性,则完全取决于具体的场景,例如,从安全性方面考虑:
- 在购物场景中,涉及"支付"的工具,其不确定性阈值应设得较低,需要用户反复确认;而"搜索商品"的工具,则可以非常主动。
- 在编码场景中,"删除文件"工具的主动性阈值,必须远低于"搜索文本"(grep)工具。
工具调用前说明 (Tool preambles)
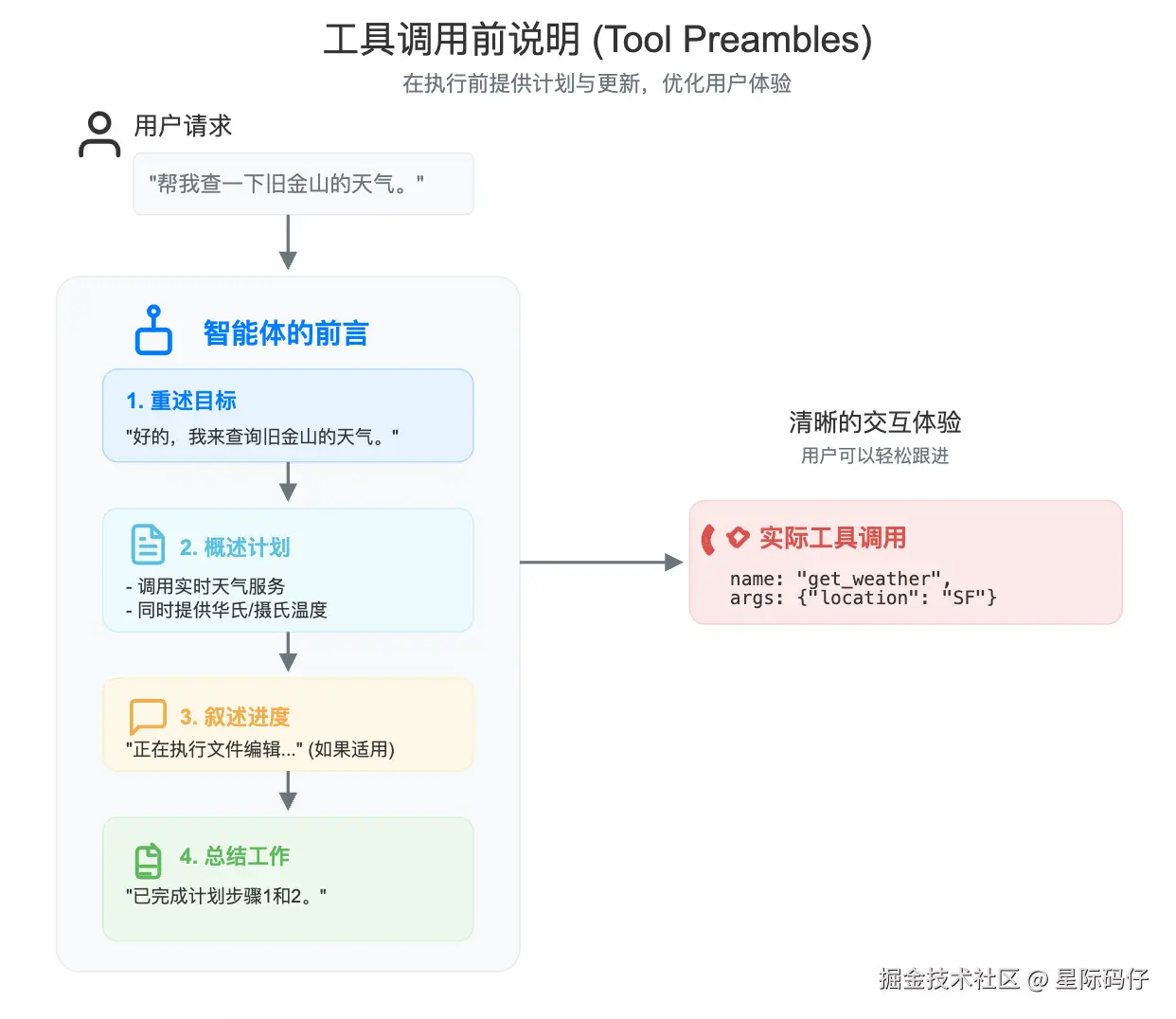
GPT-5 经过专门训练,在采取行动前,它会通过"工具调用前说明"来清晰地预告自己的计划,并持续同步进度。
简单来说,模型会不时地告诉你,它正在用工具做什么,以及为什么要这样做,极大地提升了交互体验。
你可以在提示词中,引导这些"说明"的频率、风格和内容。
diff
<tool_preambles>
- 在调用任何工具之前,始终先以友好、清晰、简洁的方式重述用户的目标。
- 然后,立即概述一个结构化的计划,详细说明你将遵循的每个逻辑步骤。
- 在执行文件编辑时,简洁并按顺序叙述每一步,清晰地标记进度。
- 最后,将已完成的工作与你的之前的计划明确分开进行总结。
</tool_preambles>以下是针对此类提示词可能得到的响应示例:
swift
"output": [
{
"id": "rs_6888f6d0606c819aa8205ecee386963f0e683233d39188e7",
"type": "reasoning",
"summary": [
{
"type": "summary_text",
"text": "**确定天气响应**\n\n我需要回答用户关于旧金山天气的问题。...."
}
]
},
{
"id": "msg_6888f6d83acc819a978b51e772f0a5f40e683233d39188e7",
"type": "message",
"status": "completed",
"content": [
{
"type": "output_text",
"text": "我将查询一个实时天气服务,以获取旧金山的当前状况,并同时提供华氏度和摄氏度的温度,以符合您的偏好。"
}
],
"role": "assistant"
},
{
"id": "fc_6888f6d86e28819aaaa1ba69cca766b70e683233d39188e7",
"type": "function_call",
"status": "completed",
"arguments": "{"location":"San Francisco, CA","unit":"f"}",
"call_id": "call_XOnF4B9DvB8EJVB3JvWnGg83",
"name": "get_weather"
}
]使用 Responses API 复用推理上下文
在使用 GPT-5 处理智能体流程时,强烈推荐使用 Responses API。它能带来更低的成本和更高效的 Token 使用。
这个 API 允许模型参考自己之前的推理轨迹。这样做的好处是,模型不必在每次工具调用后都从头开始重新思考和规划,从而节省了大量的思考链(CoT)Token ,并同时提升了响应速度和性能。
最大化编码性能,从规划到执行
前端应用开发
GPT-5 不仅具备严谨的实现能力,还拥有出色的基础审美。它能熟练运用各类 Web 开发框架。不过,如果你要从零开始构建新应用,OpenAI 建议使用以下技术栈,以充分发挥模型的前端能力:
- 框架: Next.js (TypeScript), React, HTML
- 样式 / UI: Tailwind CSS, shadcn/ui, Radix Themes
- 图标: Material Symbols, Heroicons, Lucide
- 动画: Motion
- 字体: San Serif, Inter, Geist, Mona Sans, IBM Plex Sans, Manrope
场景一:从零到一的应用生成
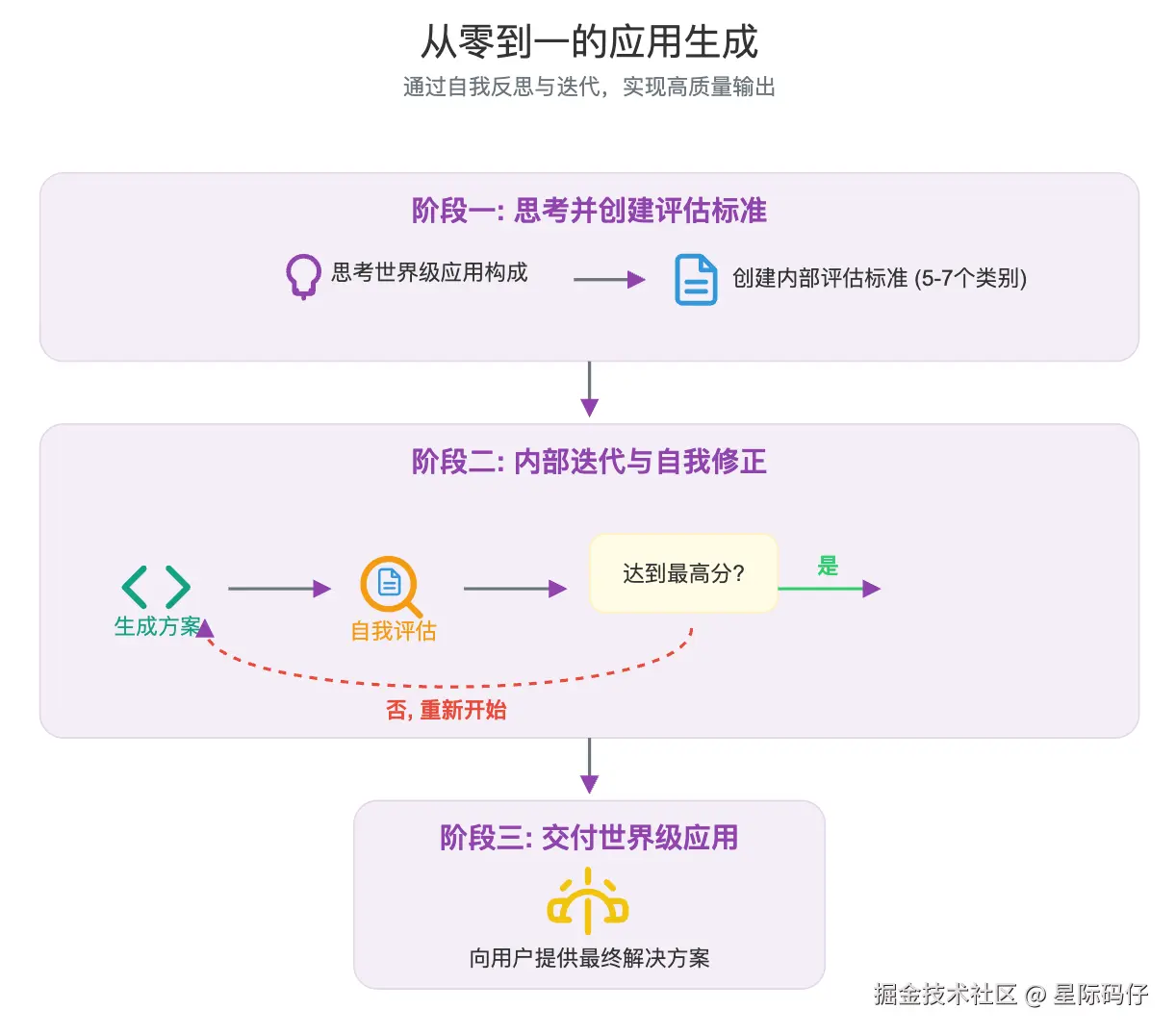
GPT-5 非常擅长一次性构建完整的应用程序。
利用 GPT-5 全面的规划和自我反思能力,你通过以下提示词,要求模型先为自己建立一套高标准的评估准则,然后基于这套准则进行迭代和优化:
diff
<self_reflection>
- 首先,花时间思考并建立一套评估标准,直到你充满信心。
- 深入思考构成世界级 Web 应用的每个方面,用这些知识创建一个包含5-7个类别的评估标准。这个标准仅供你自己内部使用,不要展示给用户。
- 最后,使用这个标准在内部反复思考和迭代,直到找到对用户提示的最佳解决方案。记住,如果你的响应在所有类别上没有达到最高分,就必须重新开始。
</self_reflection>场景二:匹配现有代码库的设计规范
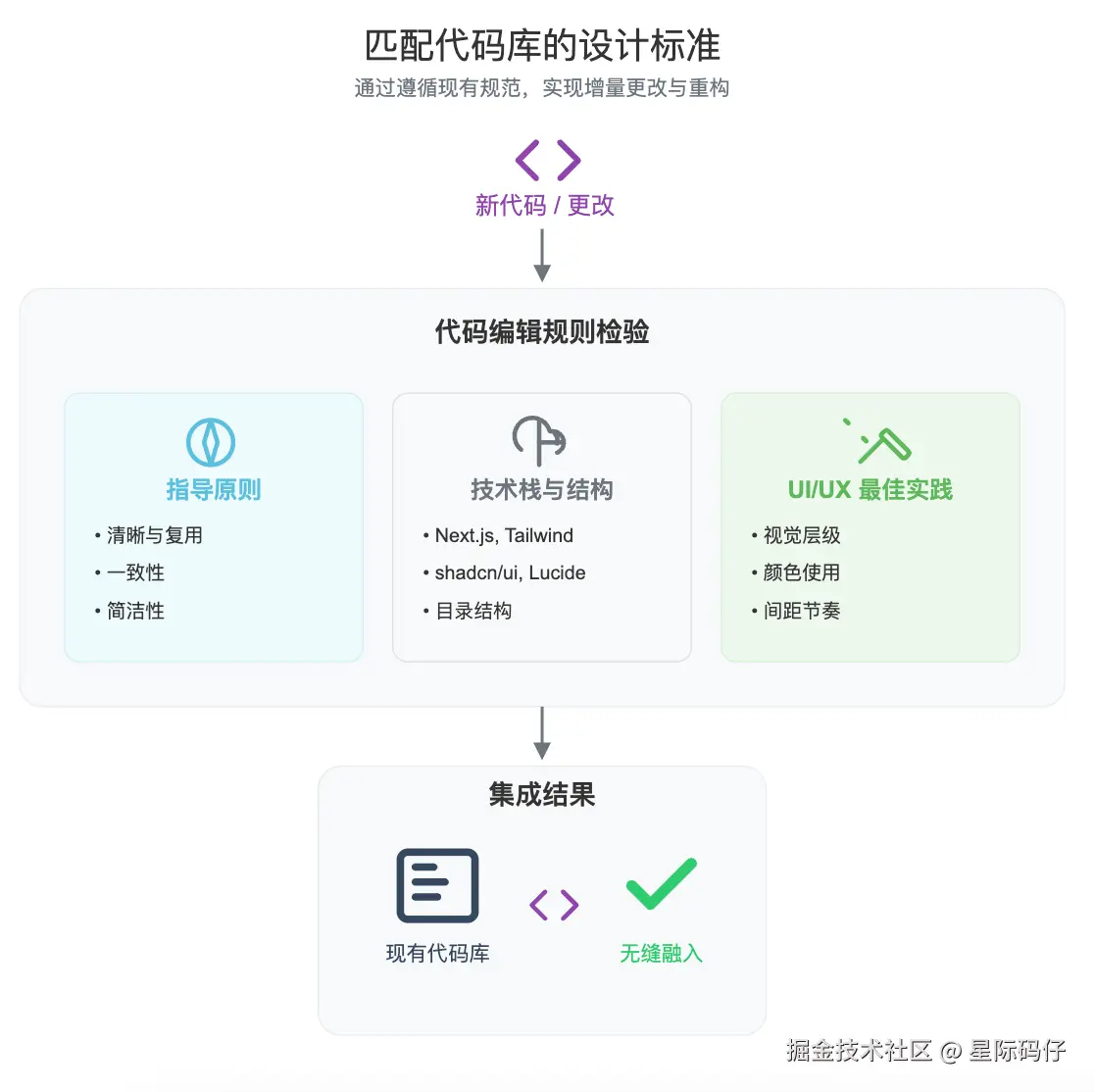
当我们需要在现有项目中进行增量修改或重构时,我们希望模型生成的代码能够遵循项目已有的风格和设计标准,做到无缝"融入"。
通常情况下,GPT-5 会自动在代码库中搜索参考信息,无需特别提示。 但我们依然可以通过明确的提示词来进一步强化这一行为。
下面这个提示词片段,就很好地为 GPT-5 组织了一套代码编辑规则:
bash
<code_editing_rules>
<guiding_principles>
- 清晰与复用:每个组件和页面都应是模块化和可复用的。通过将重复的 UI 模式分解为组件来避免重复。
- 一致性:用户界面必须遵守一致的设计系统------颜色 token、排版、间距和组件必须统一。
- 简洁性:倾向于使用小而专注的组件,避免在样式或逻辑中引入不必要的复杂性。
- 面向演示:结构应允许快速原型制作,展示流式传输、多轮对话和工具集成等功能。
- 视觉质量:遵循 OSS 指南中概述的高视觉质量标准(间距、内边距、悬停状态等)。
</guiding_principles>
<frontend_stack_defaults>
- 框架:Next.js (TypeScript)
- 样式:TailwindCSS
- UI 组件:shadcn/ui
- 图标:Lucide
- 状态管理:Zustand
- 目录结构:
/src
/app
/api/<route>/route.ts # API 端点
/(pages) # 页面路由
/components/ # UI 构建块
/hooks/ # 可复用的 React hooks
/lib/ # 工具函数 (fetchers, helpers)
/stores/ # Zustand stores
/types/ # 共享的 TypeScript 类型
/styles/ # Tailwind 配置
</frontend_stack_defaults>
<ui_ux_best_practices>
- 视觉层级:将排版限制在 4--5 种字体大小和字重以保持一致的层级;使用 `text-xs` 作为说明和注释;除非是英雄标题或主要标题,否则避免使用 `text-xl`。
- 颜色使用:使用 1 种中性基色(例如 `zinc`)和最多 2 种强调色。
- 间距和布局:始终使用 4 的倍数作为内边距和外边距以保持视觉节奏。处理长内容流时,使用固定高度的容器和内部滚动。
- 状态处理:使用骨架屏占位符或 `animate-pulse` 来指示数据获取。通过悬停过渡(`hover:bg-*`, `hover:shadow-md`)指示可点击性。
- 可访问性:在适当的地方使用语义化 HTML 和 ARIA 角色。倾向于使用内置了可访问性的预构建 Radix/shadcn 组件。
</ui_ux_best_practices>
</code_editing_rules>生产环境的协作编码:Cursor 的 GPT-5 提示词调优
经验1:系统提示词和参数调优
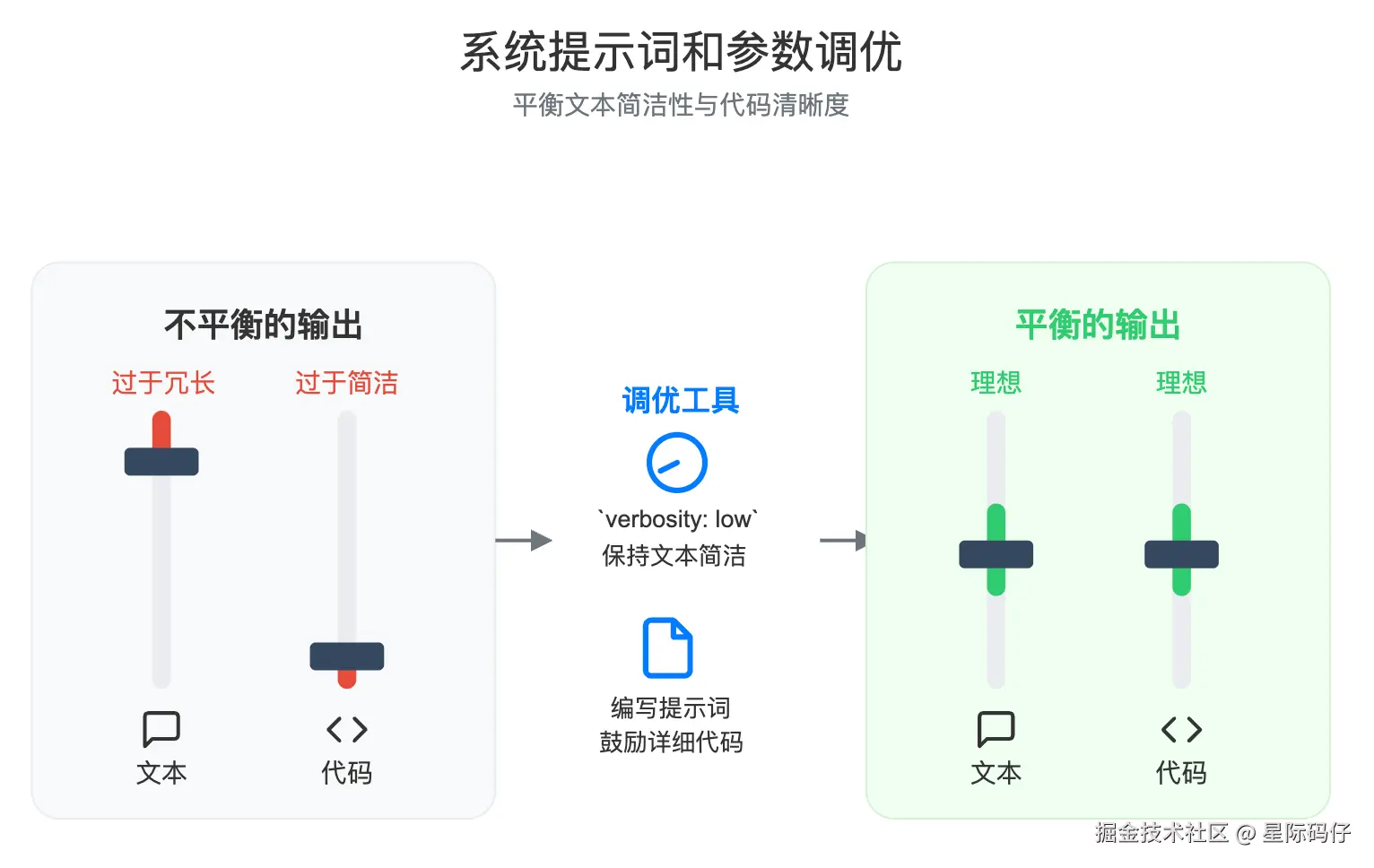
- 问题:Cursor 团队发现,GPT-5 的默认输出有时过于冗长,包含了大量的状态更新和总结,这会打断用户的自然工作流。 与此同时,它生成的代码质量虽高,但有时又过于简洁(比如大量使用单字母变量名),降低了可读性。
- 解决方案 :他们采取了"参数+提示词 "双管齐下的策略。首先,将
verbosityAPI 参数设为low,让模型的文字回复保持简洁。 然后,通过以下提示词强烈鼓励模型在输出代码时保持详细和清晰。
css
首先要为清晰而编写代码。倾向于使用可读、可维护、具有清晰名称、必要注释和直接控制流的解决方案。除非明确要求,否则不要产出代码高尔夫(code-golf)或过于取巧的单行代码。在编写代码和使用代码工具时,使用高详细度(high verbosity)。这样一来,就实现了完美的平衡:既有高效简洁的状态更新,又有易于阅读和维护的代码。
经验2:鼓励主动性,减少交互摩擦
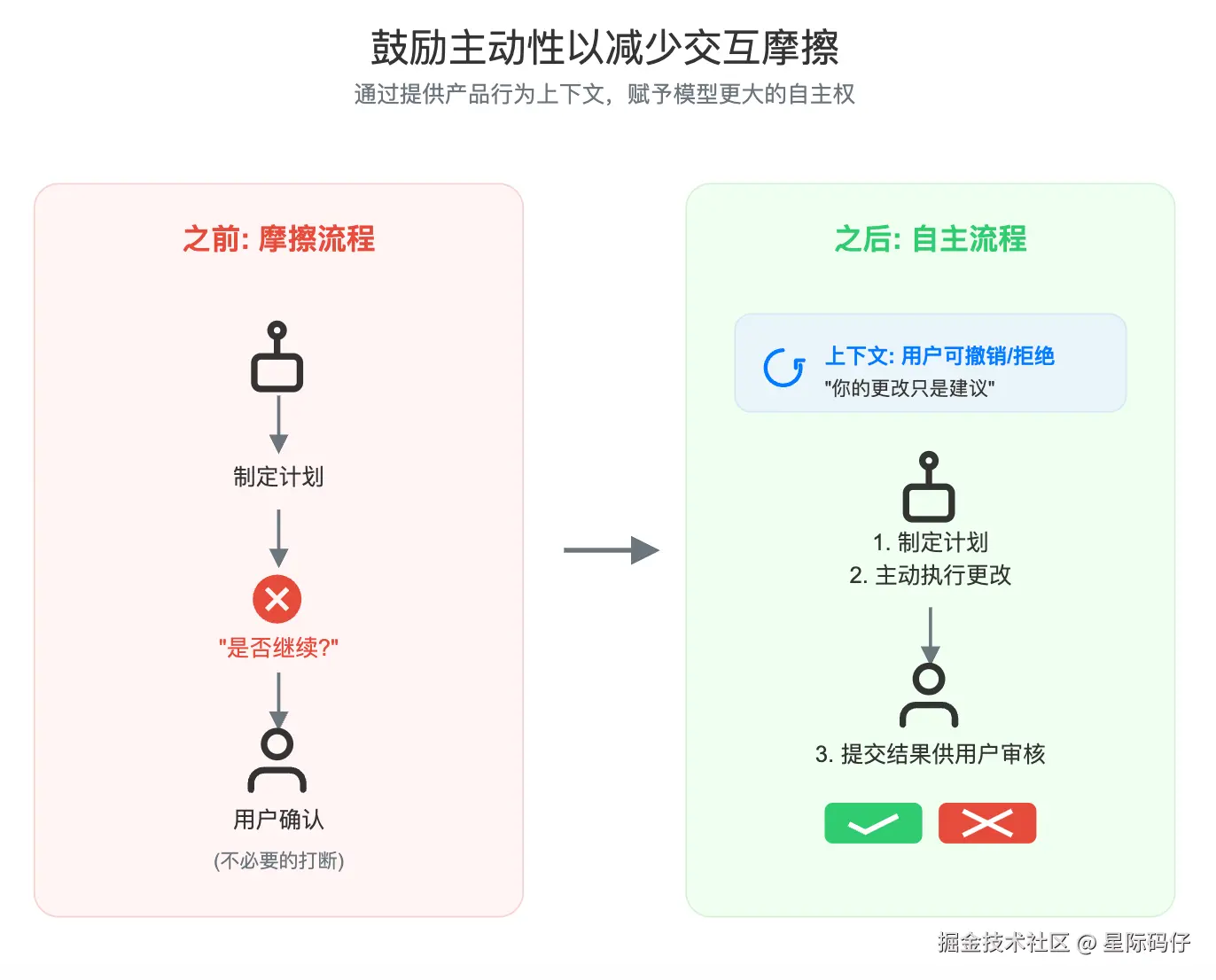
- 问题:他们还发现,GPT-5 在采取行动前,偶尔会停下来向用户请求澄清或下一步指示,这在执行长任务时造成了不必要的打断。
- 解决方案:为了鼓励模型以更大的自主性、更少的打断来完成长任务,他们加入了以下提示:
css
请注意,你所做的代码编辑会作为建议展示给用户,这意味着:(a) 你可以非常主动地进行编辑,因为用户随时可以拒绝;(b) 你的代码应该写得很好,便于快速审查(例如,使用合理的变量名而不是单字母)。如果下一步计划涉及修改代码,请主动为用户完成修改,而不是询问是否要继续。总的来说,你几乎永远不应该问用户是否要继续你的计划,而应该主动去尝试,然后让用户决定是否接受你完成的改动。经验3:根据模型特性优化提示词
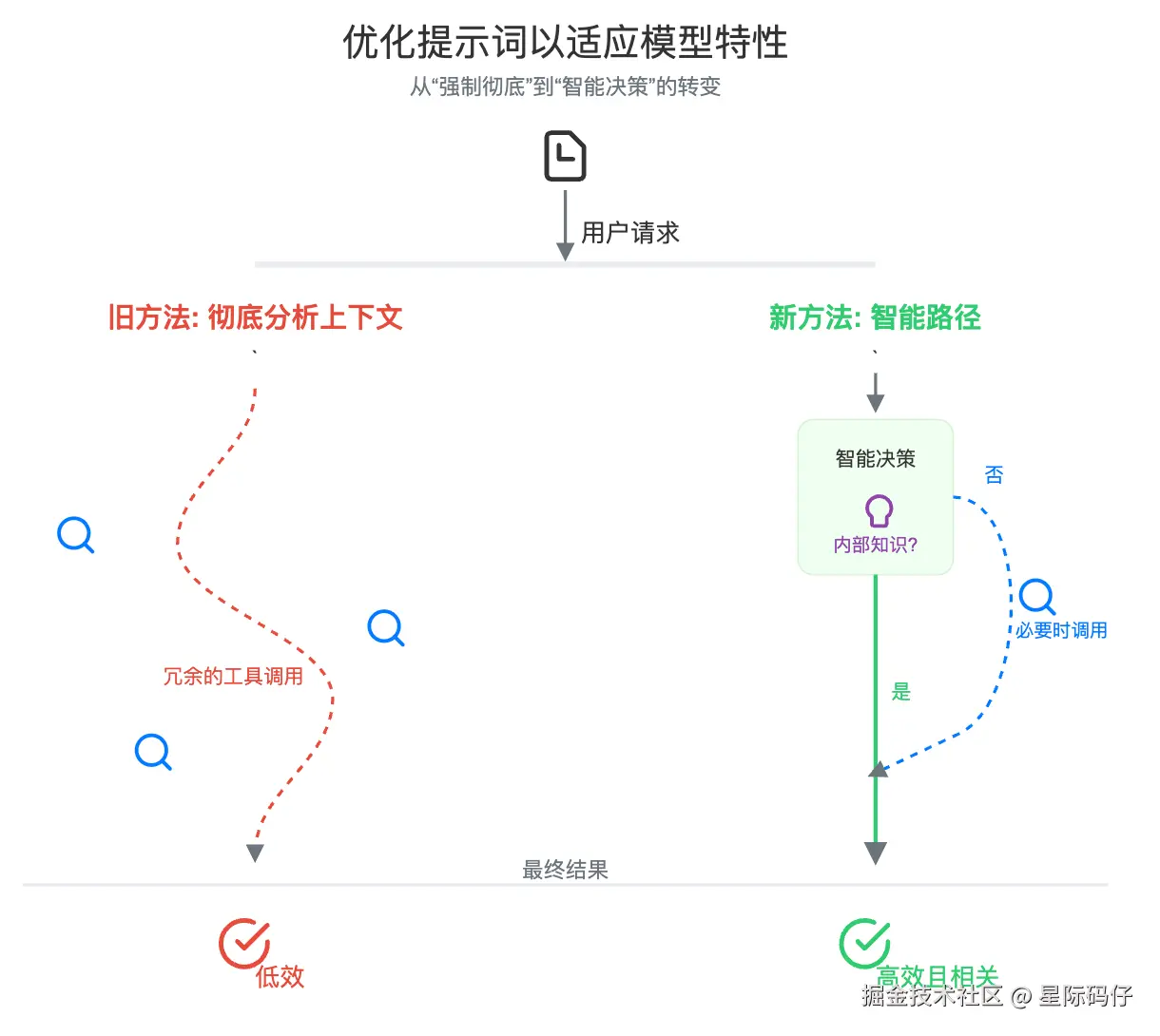
- 问题:Cursor 早期的提示词会鼓励模型彻底分析上下文:
xml
<maximize_context_understanding>
在收集信息时要彻底。在回复之前确保你已了解全局。根据需要使用额外的工具调用或澄清性问题。
...
</maximize_context_understanding>但这对 GPT-5 却适得其反 ,由于 GPT-5 天生就具备强大的内省和主动收集上下文的能力,这个提示词在处理小任务时,反而导致了它过度使用工具、重复搜索。
- 解决方案 :他们对提示词进行了微调,移除了
maximize_前缀,并软化了关于绝对性的语言。调整后的指令让 GPT-5 在"依赖内部知识"和"使用外部工具"之间做出了更好的平衡,既保持了高自主性,又避免了不必要的操作。
erlang
<context_understanding>
...
如果你执行的编辑可能部分满足了用户的查询,但你没有信心,那么在结束你的回合之前,请收集更多信息或使用更多工具。
如果你能自己找到答案,倾向于不向用户求助。
</...经验4:用户提示词的可引导性
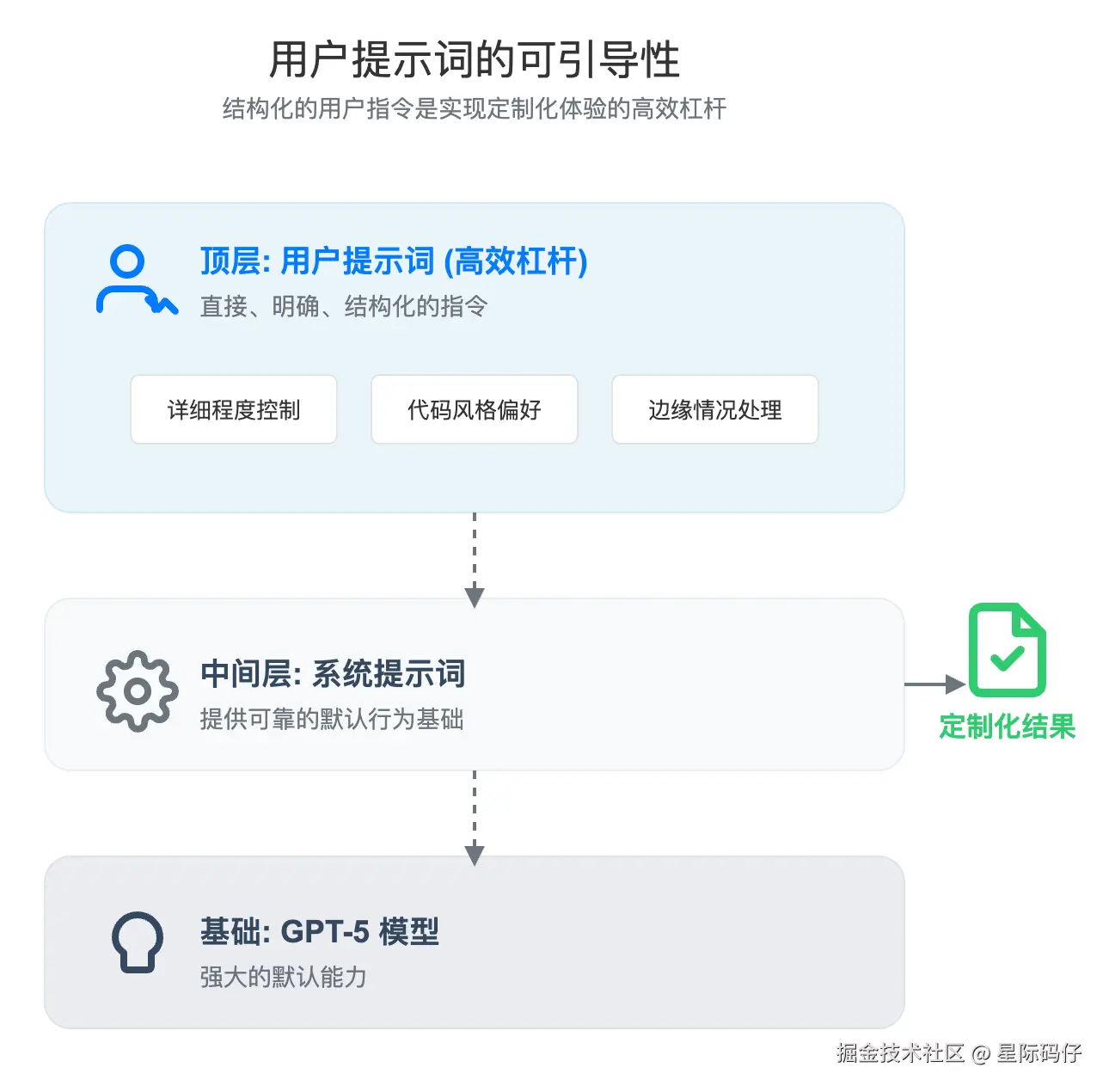
最后,虽然系统提示词为模型提供了坚实的基础,但用户自己的提示词,依然是实现个性化和可控性的高效杠杆。
Cursor 发现,允许用户配置自己的"自定义规则",并结合 GPT-5 对直接指令的良好响应,为用户带来了高度定制化的绝佳体验。
优化智能与指令遵循
可引导性 (Steering)
GPT-5 是 OpenAI 迄今为止最具可引导性的模型。这意味着它对提示词中关于详细程度、语气和工具使用行为的指令,反应异常灵敏。
详细程度 (Verbosity)
OpenAI 在 GPT-5 中引入了一个新的 API 参数 verbosity。值得注意的是,它影响的是模型最终答案的长度,而不是它中间思考过程的长度。
指令遵循
GPT-5 能以手术刀般的精度来遵循提示指令,这让它能灵活地融入各种工作流。
然而,这也像一把双刃剑。正因为它的高度谨慎,如果你的提示词写得不好,包含了相互矛盾或模糊不清的指令,那么对 GPT-5 的负面影响会比对其他模型更大。因为它会耗费宝贵的推理资源去试图理解和调和这些矛盾,而不是随机选择一个方向。
为了避免这类问题,OpenAI 建议使用他们的提示词优化工具来测试你的提示词。
platform.openai.com/chat/edit?o...
最小推理强度 (Minimal reasoning)
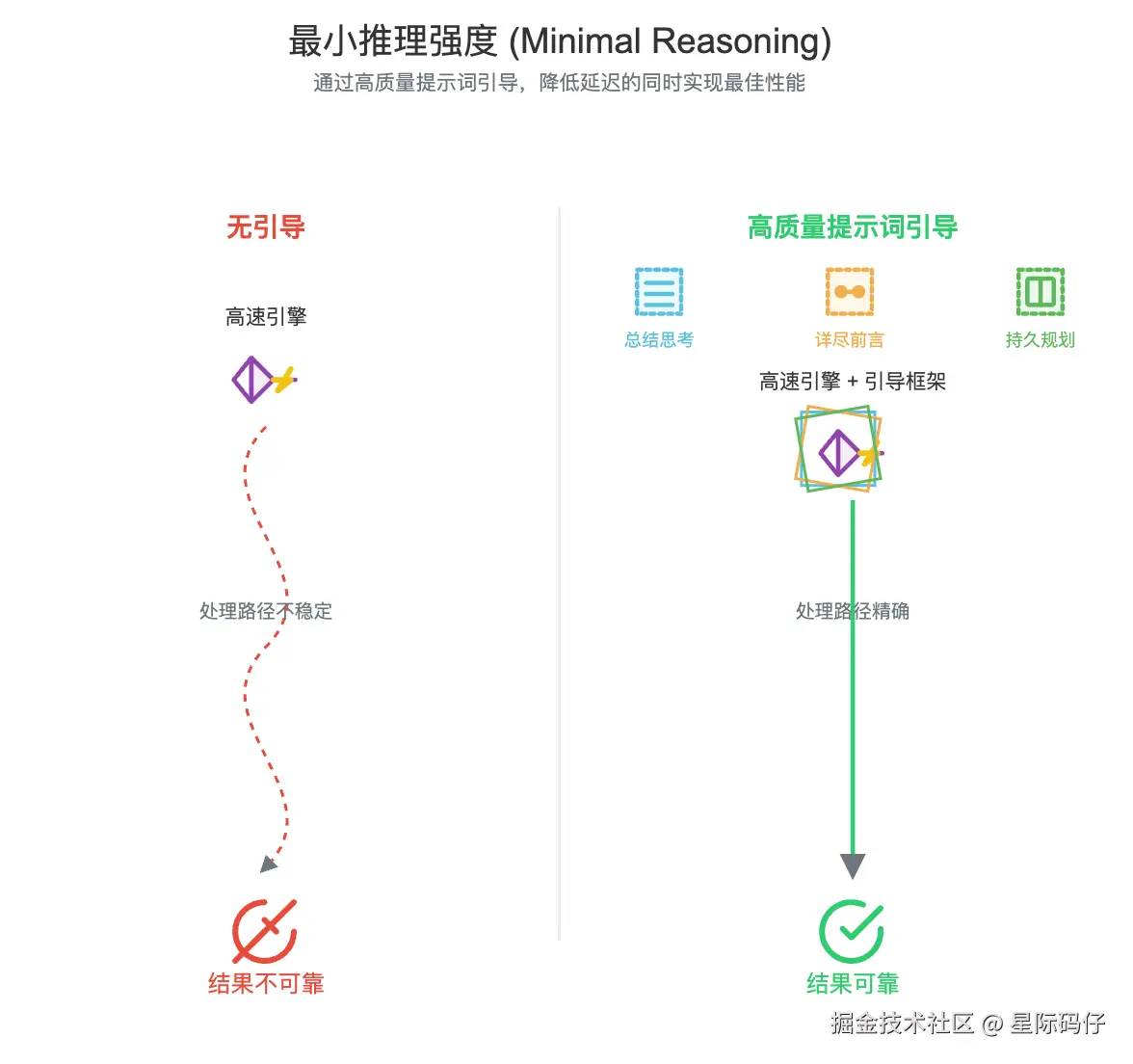
GPT-5 引入了最小推理强度选项。它能在大幅降低延迟的同时,让你依然能享受到推理模型带来的好处。
不过,在这种模式下,模型会更依赖于提示词的质量。想要获得最佳结果,需要注意以下几点:
- 引导解释:提示模型在最终答案的开头,用一个简短的解释(比如项目符号列表)来总结它的思考过程,这能提升复杂任务的性能。
- 详尽的前说明:要求模型提供详尽且描述清晰的"工具调用前说明",持续同步任务进展,这在智能体工作流中尤其重要。
- 消除歧义 :最大程度地消除工具指令中的模糊之处,并加入前文提到的"智能体持久性提醒",这在
minimal推理模式下至关重要,能有效防止任务过早终止。
Markdown 格式化
默认情况下,通过 API 调用的 GPT-5 不会主动将其最终答案格式化为 Markdown。
另外,在进行长对话时,模型有时可能会忘记你在系统提示词中指定的 Markdown 格式化指令。如果遇到这种情况,一个有效的技巧是:每隔 3-5 条用户消息,就追加一次 Markdown 格式化指令,这样可以保持输出格式的稳定性。
元提示 (Metaprompting)
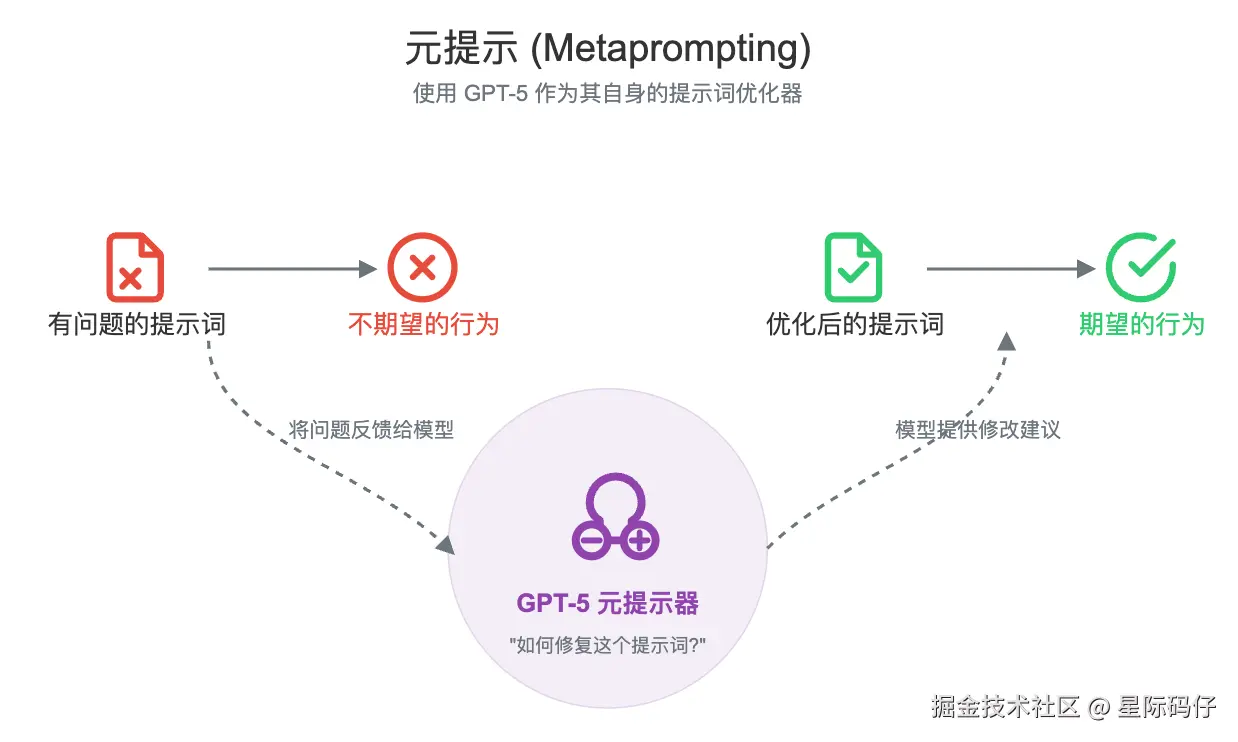
一个非常强大的技巧是:你可以让 GPT-5 本身来帮你优化提示词。这被称为"元提示"(Metaprompting)。
下面是一个你可以直接使用的元提示模板:
css
当被要求优化提示词时,请从你自己的角度给出答案------解释可以向这个提示词中添加或删除哪些具体短语,以更一致地引发期望的行为或防止不期望的行为。
这是一个提示词:[在此处插入你的提示词]
这个提示词期望的行为是让智能体 [描述你期望的行为],但它现在却 [描述实际发生的不期望的行为]。在尽可能保持现有提示词完整的同时,你会做出哪些最小化的编辑或添加,来鼓励智能体更稳定地解决这些问题?参考
GPT-5提示词指南(cookbook.openai.com/examples/gp...)