flume详解:分布式日志采集的核心原理与组件解析
在大数据体系中,日志采集是数据处理的第一步。Flume 作为 Apache 旗下的分布式日志采集工具,以高可用、高可靠、易扩展的特性,成为处理海量日志数据的首选方案。本文将从 Flume 的核心概念、组件架构到关键名词解析,带你全面掌握这款流式数据采集工具的工作原理。
Flume 简介
Flume 是一款开源的分布式数据采集系统,专注于从多种数据源实时采集、聚合并传输数据到存储系统(如 HDFS、Kafka、HBase 等)。其核心优势包括:
- 高可用:支持故障自动恢复,避免数据丢失;
- 高可靠:通过持久化通道确保数据不丢失;
- 分布式架构:可横向扩展,适应海量数据场景;
- 灵活扩展:支持自定义数据源、传输逻辑和存储目标。
本文基于 Flume 1.9.0 版本展开讲解(可通过官网或包管理工具安装,安装后需在 flume-env.sh 中配置 JAVA_HOME)。
shell
>flume-ng version
Flume 1.9.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: d4fcab4f501d41597bc616921329a4339f73585e
Compiled by fszabo on Mon Dec 17 20:45:25 CET 2018
From source with checksum 35db629a3bda49d23e9b3690c80737f9Flume 的核心架构
Flume 的最小工作单元是 Agent(代理) ,一个 Agent 由 Source(事件源)、Channel(通道)、Sink(接收器) 三个核心组件组成。多个 Agent 可串联或并联,形成复杂的数据流 pipeline,实现跨节点的数据传输。
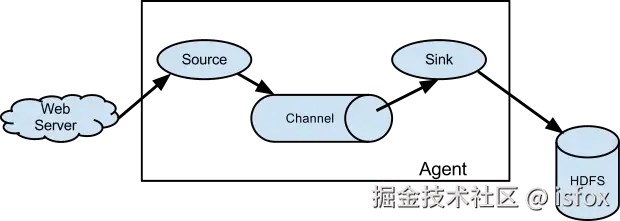
核心组件工作流程
- Source 从数据源(如日志文件、Kafka、网络端口)采集数据,封装为 Event(事件) 并发送到 Channel;
- Channel 作为临时缓冲区,暂存 Event 直到被 Sink 消费,确保数据不丢失;
- Sink 从 Channel 中读取 Event,将数据传输到目标存储系统(如 HDFS、Kafka)或下一个 Agent 的 Source。
关键名词解释
理解 Flume 的核心概念是掌握其工作原理的基础,以下是必须掌握的关键术语:
事件Event
Event 是 Flume 数据传输的最小单位,类似于数据的 "包裹"。每个 Event 由两部分组成:
- Header:可选的键值对属性集合(如时间戳、数据来源标识),用于描述 Event 的元信息,方便后续过滤或路由;
- Body:实际的业务数据,以字节数组(byte \[\])形式存储(例如一条日志的文本内容)。
例如,一条用户行为日志的 Event 结构可能为:
plaintext
Header: {timestamp=1620000000000, source=app-log}
Body: "user_id=123;action=click;page=home"(字节数组形式) 事件源Source
Source 是数据流入 Flume 的 "入口",负责从数据源采集数据并转换为 Event 发送到 Channel。Flume 支持丰富的内置 Source,覆盖大多数常见场景:
常用 Source 类型
| 类型 | 适用场景 | 示例配置场景 |
|---|---|---|
spooldir |
监控目录下的新增文件(如日志文件) | 采集应用服务器的本地日志文件 |
netcat |
监听网络端口接收数据 | 实时接收网络设备推送的日志 |
kafka |
从 Kafka 主题消费数据 | 对接 Kafka 进行数据中转 |
exec |
执行命令并采集输出(如 tail -F) |
实时跟踪日志文件新增内容 |
http |
通过 HTTP 请求接收数据 | 接收应用程序主动上报的事件 |
特点与扩展
- 支持多 Channel 输出:一个 Source 可将 Event 发送到多个 Channel(通过 Channel Selector 控制);
- 可自定义 Source:若内置类型不满足需求,可通过实现
org.apache.flume.Source接口开发自定义 Source。

通道Channel
Channel 是位于 Source 和 Sink 之间的 "缓冲区",负责暂存 Event 并保证数据可靠传递。它是 Flume 可靠性的核心保障,数据在 Channel 中停留时间较短,直到被 Sink 消费。
常用 Channel 类型
| 类型 | 存储方式 | 可靠性 | 性能 | 适用场景 |
|---|---|---|---|---|
Memory Channel |
内存 | 低(易丢失) | 高 | 非核心数据、对性能要求高的场景 |
File Channel |
本地磁盘 | 高(持久化) | 中 | 核心数据、需保证不丢失的场景 |
JDBC Channel |
关系型数据库 | 高 | 低 | 需事务支持或跨节点共享数据的场景 |
Channel Selector(通道选择器)
当 Source 对接多个 Channel 时,Selector 决定 Event 发送到哪些 Channel,内置两种策略:
- Replicating(默认):将 Event 复制到所有 Channel(广播模式);
- Multiplexing(多路复用):根据 Event Header 中的属性值,将 Event 路由到指定 Channel。
示例配置(Multiplexing):
properties
a1.sources = r1
# 多个channel
a1.channels = c1 c2 c3 c4
a1.sources.r1.selector.type = multiplexing
# 根据 Header 中的 "state" 属性路由
a1.sources.r1.selector.header = state
# state=CZ → 发送到 c1
a1.sources.r1.selector.mapping.CZ = c1
# state=US → 发送到 c2 和 c3
a1.sources.r1.selector.mapping.US = c2 c3
# 无匹配时默认发送到 c4
a1.sources.r1.selector.default = c4
接收器Sink
Sink 是数据流出 Flume 的 "出口",负责从 Channel 读取 Event 并传输到目标存储系统或下一个 Agent。与 Source 类似,Flume 提供多种内置 Sink 满足不同需求:
常用 Sink 类型
| 类型 | 目标存储 | 适用场景 |
|---|---|---|
hdfs |
HDFS 文件系统 | 海量日志数据持久化存储 |
kafka |
写入 Kafka 主题 | 对接 Kafka 供下游消费 |
logger |
输出到 Flume 日志(控制台) | 调试或临时数据查看 |
file_roll |
写入本地文件 | 小规模数据本地存储 |
hbase |
写入 HBase 表 | 需随机读写或实时查询的场景 |
avro |
发送到另一个 Flume Agent 的 Source | 跨节点数据传输(多级 Agent 串联) |
Sink Group(接收器组)
当需要提高数据输出吞吐量或实现负载均衡时,可将多个 Sink 组成 Sink Group,通过负载均衡器分配任务:
- 支持
round_robin(轮询)或failover(故障转移)策略; - 示例:多个
hdfsSink 组成 Group,并行写入 HDFS 提升效率。

Flume 的灵活性与扩展能力
Flume 的强大不仅在于内置组件,更在于其可扩展性:
- 拦截器(Interceptor):在 Event 从 Source 到 Channel 前修改或过滤数据(如添加时间戳、过滤无效日志);
- 序列化器(Serializer):自定义 Event 写入目标系统的格式(如将 Body 转换为 JSON 或 Parquet 格式);
- 自定义组件:通过接口开发自定义 Source、Channel、Sink,适配特殊业务场景。
总结
Flume 以 "Agent 为单元、组件化架构" 为核心,通过 Source 采集数据、Channel 暂存数据、Sink 输出数据,实现了分布式环境下的高效日志采集。其丰富的内置组件和灵活的扩展能力,使其能够轻松对接各种数据源和存储系统,成为大数据平台不可或缺的数据采集工具。
参考文献