前言
自适应检索增强生成(Adaptive-RAG)是根据用户查询的复杂性来优化检索增强模型(比如LLM)。
传统的RAG方法往往没有考虑到查询复杂性的差异,结果要么是简单查询时计算开销过大,要么是复杂、多步骤的查询处理不够充分。Adaptive-RAG通过将查询分为三个复杂性级别,并应用相应的处理策略。
Adaptive-RAG中引入一个分类器,它会评估查询的复杂性,从而确定最适合的检索策略。这种分类旨在平衡计算效率和回答的准确性,具体策略如下:
- 简单查询不检索:对于LLM自己就能回答的简单查询,直接由LLM处理,不进行检索。
- 单步检索:对于需要额外上下文信息的中等复杂查询,进行单步检索。
- 多步检索:对于涉及跨多篇文档整合信息并进行推理的复杂查询,进行多步检索。
查询复杂性分类器
分类器用于评估查询的复杂性级别,分为"A"(简单,由LLM处理)、"B"(中等复杂,需要单步检索)和"C"(复杂,需要多步检索)。这个分类器通过分析每种检索方法的成功率,并利用现有数据集中的归纳偏差来创建训练数据。
实现代码
python
import os
from typing import List, Literal, TypedDict
from dotenv import load_dotenv
from langchain.schema import Document # Import the Document class
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
# pip install pypdf
from langchain_community.document_loaders import TextLoader
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# pip install beautifulsoup4
from langgraph.graph import StateGraph, START, END
from pydantic import BaseModel, Field
load_dotenv()
embeddings = DashScopeEmbeddings(
dashscope_api_key=os.getenv("OPENAI_API_KEY"),
model="text-embedding-v4",
)
model = ChatOpenAI(model="qwen-plus",
base_url=os.getenv("BASE_URL"),
api_key=os.getenv("OPENAI_API_KEY"),
temperature=0,
streaming=True)
docs_list = TextLoader(os.path.join(os.getcwd(), "crag_data.txt")).load()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(chunk_size=500, chunk_overlap=0)
doc_splits = text_splitter.split_documents(docs_list)
doc_splits = doc_splits[:3]
vectorstore = Chroma.from_documents(doc_splits, collection_name="adaptive-rag", embedding=embeddings)
retriever = vectorstore.as_retriever()
class RouteQuery(BaseModel):
datasource: Literal["vectorstore", "web_search"]
# 查询复杂的路由
route_prompt = ChatPromptTemplate.from_messages([
("system",
"""
您是将用户问题发送到矢量库或网络搜索的专家。
You must respond using JSON format with the following structure:
{{"datasource": "vectorstore"}}
or
{{"datasource": "web_search"}}
"""),
("human", "{question}")
])
question_router = route_prompt | model.with_structured_output(RouteQuery)
# 文档问题相关性
class GradeDocuments(BaseModel):
binary_score: str = Field(description="Documents are relevant to the question, 'yes' or 'no'")
grade_prompt = ChatPromptTemplate.from_messages([
("system", """
评估文档是否与问题相关。回答'yes' 或 'no'.
You must respond using JSON format with the following structure:
{{"binary_score": "yes or no"}}
"""),
("human", "Document: {document}\nQuestion: {question}")
])
retrieval_grader = grade_prompt | model.with_structured_output(GradeDocuments)
# web查询
web_search_tool = TavilySearchResults(k=3)
def web_search(state):
print("--网络查询--")
search_results = web_search_tool.invoke({"query": state["question"]})
print("search_results=", len(search_results))
web_documents = [Document(page_content=result["content"]) for result in search_results if "content" in result]
return {"documents": web_documents, "question": state["question"]}
class GraphState(TypedDict):
question: str
generation: str
documents: List[str]
# Define nodes for query handling
def retrieve(state):
print("--检索文档--")
documents = retriever.invoke(state["question"])
return {"documents": documents, "question": state["question"]}
def grade_documents(state):
print("--评估文档相关性--")
question = state["question"]
documents = state["documents"]
filtered_docs = []
web_search_needed = "No"
for doc in documents:
grade = retrieval_grader.invoke({"question": question, "document": doc.page_content}).binary_score
if grade == "yes":
print("--文档相关--")
filtered_docs.append(doc)
else:
print("--文档不相关--")
web_search_needed = "Yes"
return {"documents": filtered_docs, "question": question, "web_search": web_search_needed}
def generate(state):
print("--生成答案--")
prompt_template = """
使用以下上下文简洁准确地回答问题:
Question: {question}
Context: {context}
Answer:
"""
rag_prompt = ChatPromptTemplate.from_template(prompt_template)
rag_chain = rag_prompt | model | StrOutputParser()
generation = rag_chain.invoke({"context": state["documents"], "question": state["question"]})
return {"generation": generation}
# Route question based on source
def route_question(state):
print("--文档查询路由--")
source = question_router.invoke({"question": state["question"]}).datasource
print("source=", source)
return "web_search" if source == "web_search" else "retrieve"
# Compile and Run the Graph
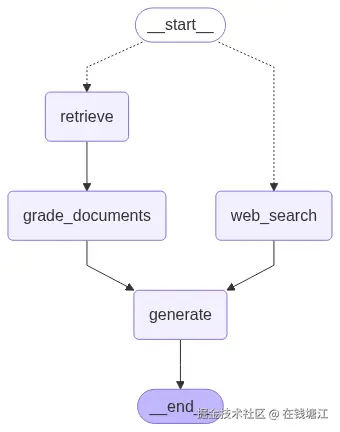
workflow = StateGraph(GraphState)
workflow.add_node("web_search", web_search)
workflow.add_node("retrieve", retrieve)
workflow.add_node("grade_documents", grade_documents)
workflow.add_node("generate", generate)
#
workflow.add_conditional_edges(
START,
route_question,
{
"web_search": "web_search",
"retrieve": "retrieve"
})
workflow.add_edge("web_search", "generate")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_edge("grade_documents", "generate")
workflow.add_edge("generate", END)
app = workflow.compile()
# inputs = {"question": "AiAgent记忆有哪些类型?"}
inputs = {"question": "地球的年龄?"}
for output in app.stream(inputs):
print(output)两种运行结果
csharp
"""
--文档查询路由--
source= vectorstore
--检索文档--
{'retrieve': {'documents': [Document(id='7fd76a6c-e5be-461c-ba54-48b6da684a37', metadata={'source': 'D:\code\support\LangGraphProjects\proj1\crag_data.txt'}, page_content='["...Several proof-of-concepts demos, such as AutoGPT, GPT-...')], 'question': 'AiAgent记忆有哪些类型?'}}
--评估文档相关性--
--文档相关--
--文档不相关--
--文档不相关--
{'grade_documents': {'documents': [Document(id='7fd76a6c-e5be-461c-ba54-48b6da684a37', metadata={'source': 'D:\code\support\LangGraphProjects\proj1\crag_data.txt'}, page_content='["...often by leveraging an external vector store...')], 'question': 'AiAgent记忆有哪些类型?'}}
--生成答案--
{'generate': {'generation': 'AiAgent的记忆类型包括:\n\n1. **短期记忆**(Short-term memory):通过上下文学习(如提示工程)实现,依赖模型的上下文窗口来临时存储和处理信息。\n\n2. **长期记忆**(Long-term memory):通过外部向量存储和快速检索机制实现,使代理能够长期保留和回忆大量信息。'}}
"""
css
"""
--文档查询路由--
source= web_search
--网络查询--
search_results= 5
{'web_search': {'documents': [Document(metadata={}, page_content='地球年龄是指自太阳系的形成与演化中吸积开始后至今所经历的地球历史时间,当今天文及地质学界理论和观测皆一致认为这个年龄介于45-46亿年之间。\n\n研究显示,该时间点落在距今45.4亿年前,误差小于1%。...'), Document(metadata={}, page_content='...'), Document(metadata={}, page_content='FARADAY PAPER 8 地球的年齡 ...')], 'question': '地球的年龄?'}}
--生成答案--
{'generate': {'generation': '地球的年龄约为45.4亿年,误差小于1%。这一数值是通过对陨石进行放射性测年得出的,同时也与地球上最古老的岩石和月球月岩的测定结果一致。'}}