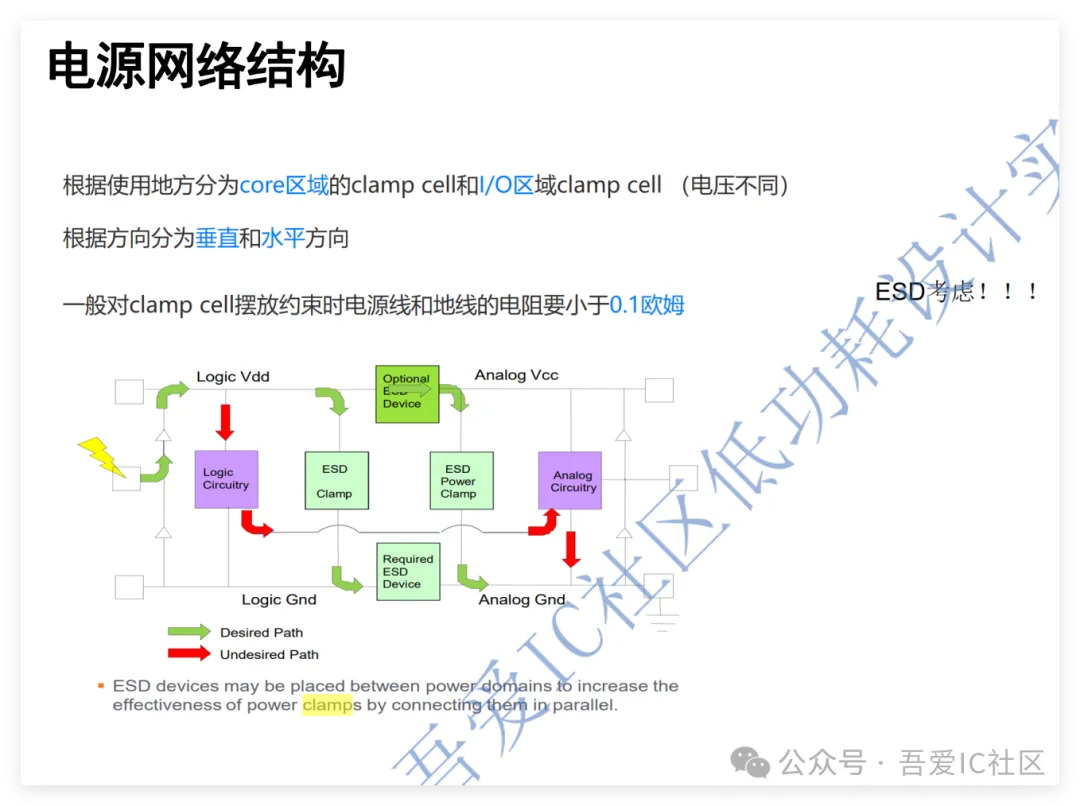
今天通过一个学员典型问题来解析下子系统Sub-System在做block partition,pin assignment和powerplan时应该注意的细节问题。
老师,我的问题是a7top的模块的partition和pin assignment是怎么做的,我了解过a7core的floorplan可以根据data flow或者arm官方推荐的floorplan进行摆放,但是我不太了解a7top的floorplan应该去怎么做,他也会有一个data flow可以参考吗?partition模块的大小的话可以通过钉钉上的面积估算公式去确定,我不太清楚top的partition需要从哪些方面去考虑?在pin assignment的时候要遵循min area的规则设置pin的长度和宽度,但是对于出pin 的层数不是很清楚要从哪些方面考虑?
数字IC设计实现之hierarchical flow系列(一)
首先,我们来看下华为海思麒麟这颗芯片的整体floorplan。其中整个GPU子系统位于芯片的左下角,而且它的整体形状其实也不是很规整的形状。之所以没那么规整的主要原因是它的边上还有其他模块和IP。
这个形状是芯片顶层owner来划分的,每个人切出来的形状都会不太一样,最终只要确保整体拼起来时序和物理上都是没问题的就可以。

整个GPU子系统的出pin 如下图红色所示。顶层实现负责人做完形状切分和出pin后就会release这个形状和出pin的floorplan def给到GPU子系统的负责人。

而我们知道这个GPU子系统里面还包含12个core和一个GPU shared logic逻辑。由于种种原因在物理设计实现时需要把12个core划分成如下情况:
1)左侧6个相同的core (只需要做一个模块core的harden,重复调用6次即可)
2)右上3个相同的core (只需要做一个模块core的harden,重复调用3次即可)
3)右下3个相同的core (这三个可以使用上面右上那个core的实现结果直接调用,也可以单独做一个模块core的harden,因为右下这3个core可能有low power需求,可能需要添加power switch cell)
这16个cpu做完后就可以在顶层直接例化调用,顶层的逻辑部分其实就是图中标注的GPU Shared Logic。
每个需要单独做harden的模块都需要在GPU 顶层规划好它们的形状和出pin。这时候GPU子系统负责人就会根据前面芯片顶层release的floorplan def来做当前子系统中的各个子模块的切分和出 pin。
回到我们社区低功耗四核A7 TOP Hierarchical Flow的项目,它的实现方式跟这个是一模一样的。
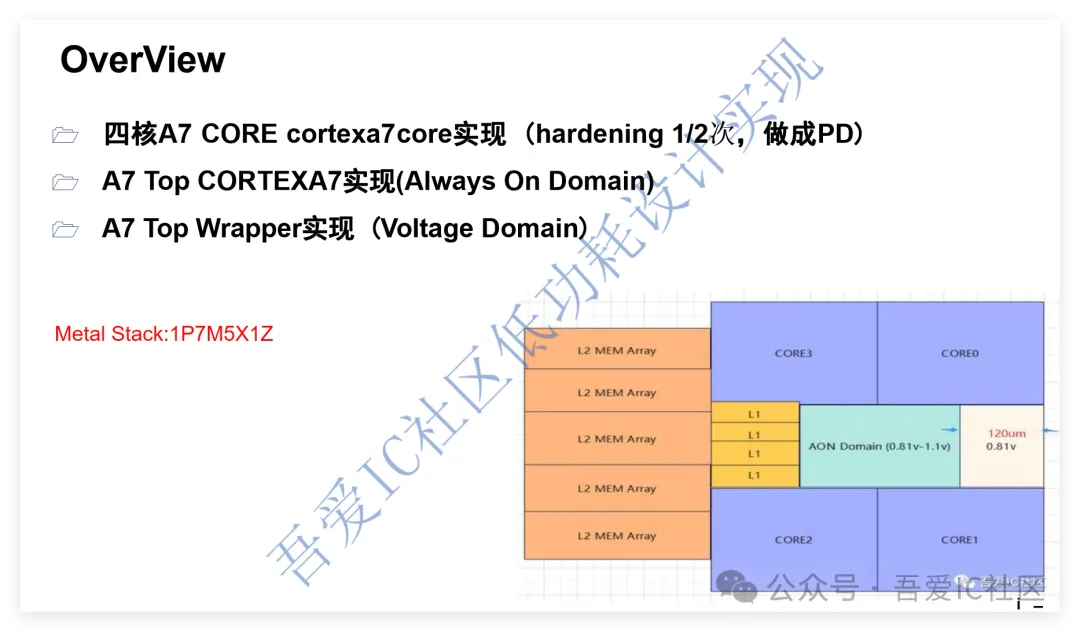
首先我们读取芯片顶层release的floorplan def,形状如下图所示。
有了这个形状后,我们就要开始切下面的子模块A7 TOP,我们特地挖出一个空间留给A7TOP_Wrapper。所以下图中的白色框框区域为A7 TOP的最终形状。

当然在切分的时候需要大概估算下A7TOP_Wrapper层需要的面积。这个面积的估算完全可以参照咱们钉钉上那份面积估算教程。
A7 Top形状有了后还需要给它摆放好IO port,具体给子模块partition摆放io port的操作如下图所示。
需要说明的是这个io port到底出在哪一层理论上都是可以的,只要后续绕线没问题就可以。当然还是要遵守这个工艺metal stack下的金属优先走线方向。
比如我们T28nm 工艺,这里的io port出的terminal必须是横向出pin,所以用来出这些io port的metal layer可以是M2,M4,M6(如果Power Rail用的是M1和M2 dual power rail,这里的出pin不要使用M2。因为很容易有short和drc violation)!
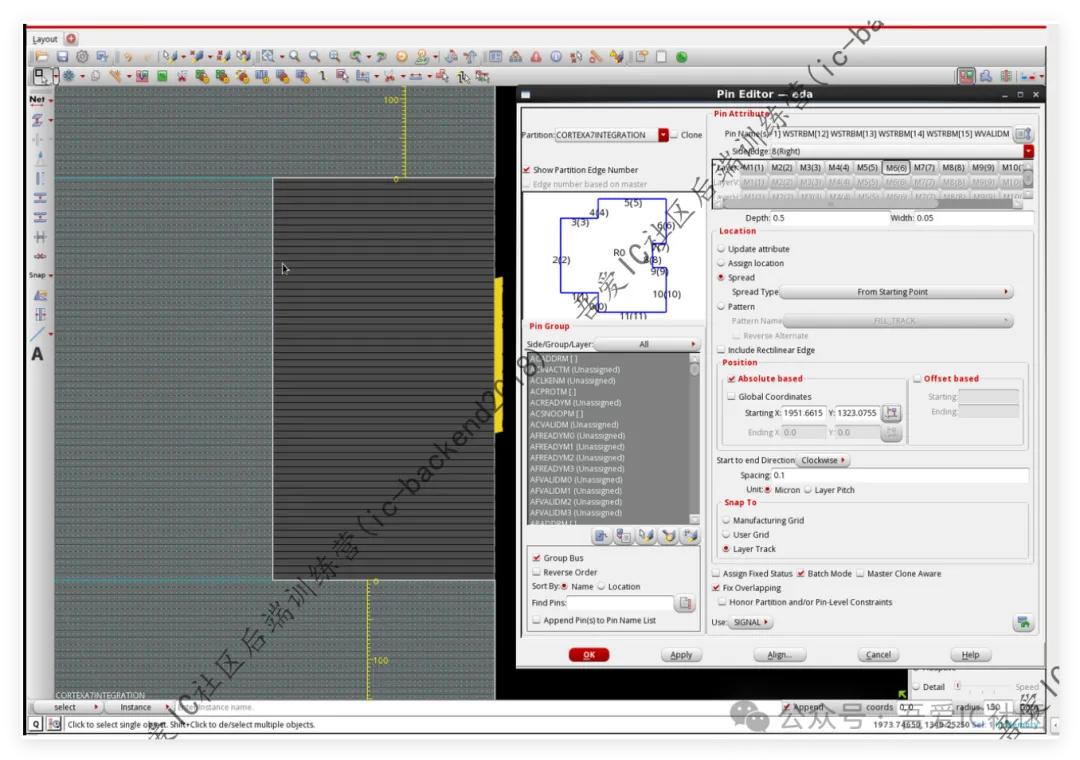
这里需要注意的是摆放io port的时候需要确保io port terminal的metal面积要满足工艺要求的最小面积min area的要求,即depth*width的数值要大于这层metal的最小面积要求(否则后续这根线不连的话会有min area的drc violation)。

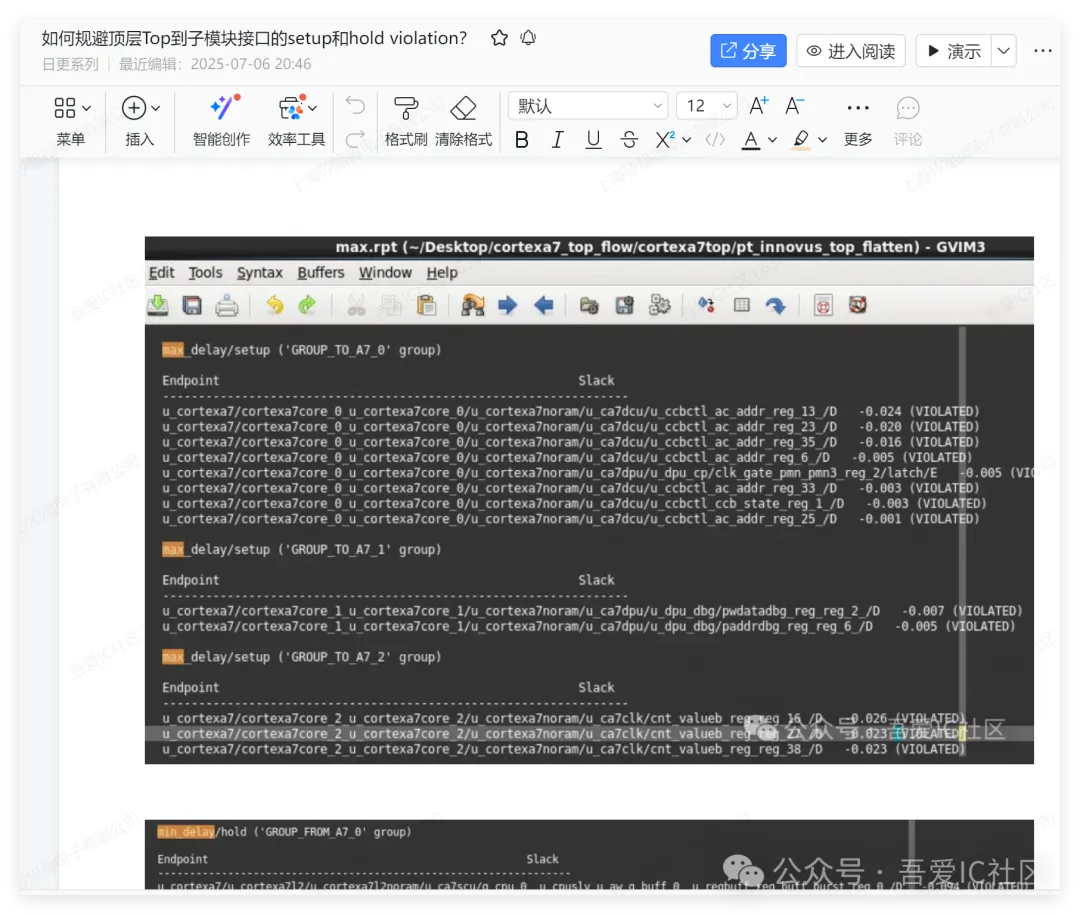
这个A7 TOP做完模块partition和pin assignment后,直接写出当前这个形状和出pin的a7 top floorplan def即可。
有了这个a7 top floorplan def后,我们可以开始切子模块cortexa7core。在这一层我们需要提前知道子模块cortexa7core的大概需要面积,然后根据A7TOP这层的data flow把相应的memory摆放好,确保4个cpu子模块和所有的memory都可以完全摆放得下。这个过程需要不断迭代直到调出一个自己满意的floorplan。
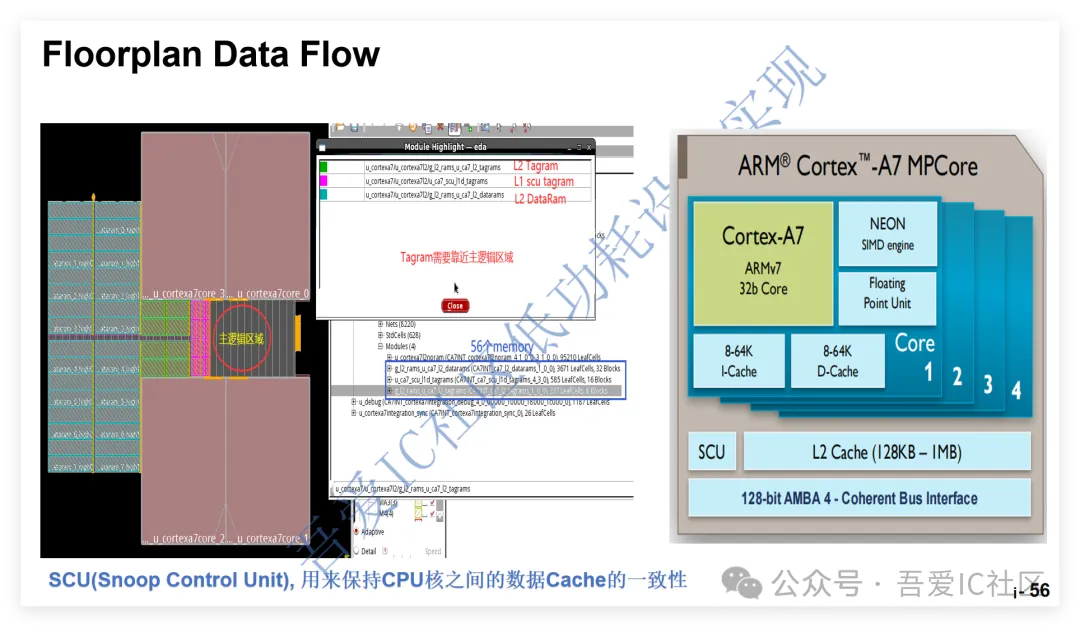
子模块切分的形状可以自己根据子模块实现难度自己调整形状。它的出pin位置和出pin的layer理论上也都可以子系统自己定,但由于四个cpu core之间的交互是通过一个共同的module SCU的,所以这四个cpu core的出pin尽量出在一起!
以下图咱们学员切出来的floorplan图,我们知道这时候我们需要给子模块cpu core出纵向的io terminal,所以它可以使用M3,M5来出pin(M7线宽和线间距太大,一般情况不用)。
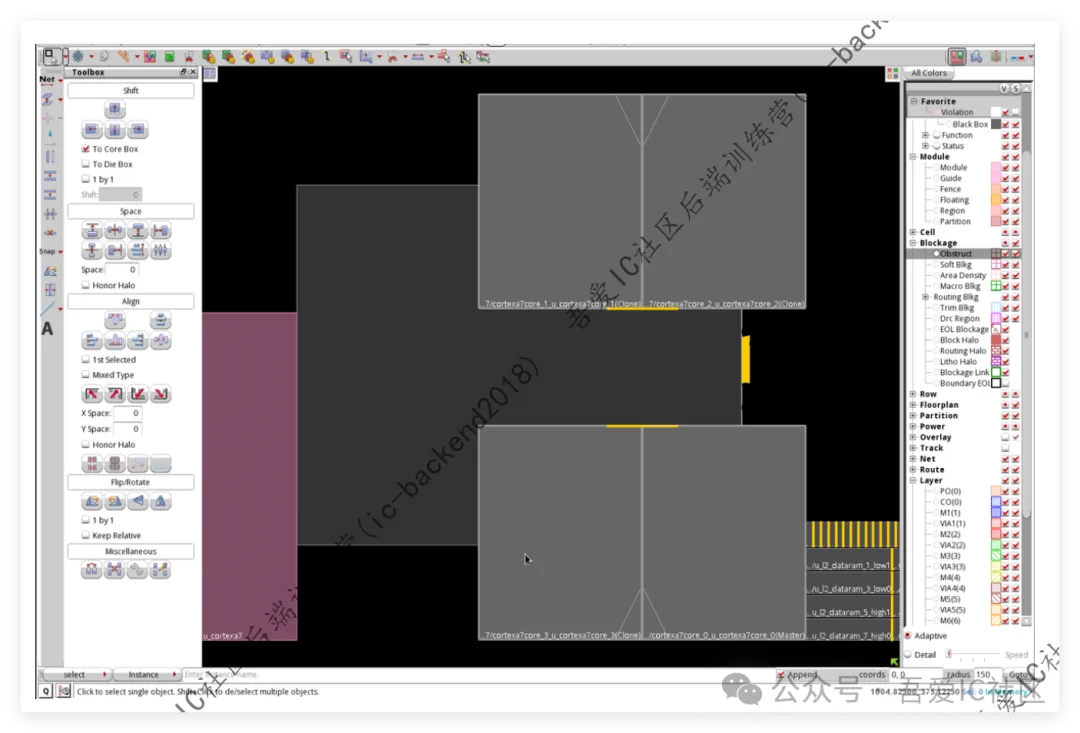
在面试的时候经常还会问到子系统是如何规划整体的powerplan的。以咱们社区低功耗四核A7Top 1P7M这层为例。子模块cpu core powerplan用到的最高层是M7,子模块直接尽量把PG对齐连通,比如上下两个cpu的M7尽量连通形成一个整体。
A7TOP这层调用四个cpu core后,我们会使用AP这一层去跟各个子模块cpu core的M7打孔形成一个power mesh(此时A7TOP顶层只需要管Global VDD和VSS,VDD_LOCAL是不需要连接的)。

最后再留一个面试题:
子系统Sub-System在做模块partition时你是如何规划ESD Clamp Cell和TCD Cell的?又是通过什么样的方式把这些要求release给各个子模块owner呢?