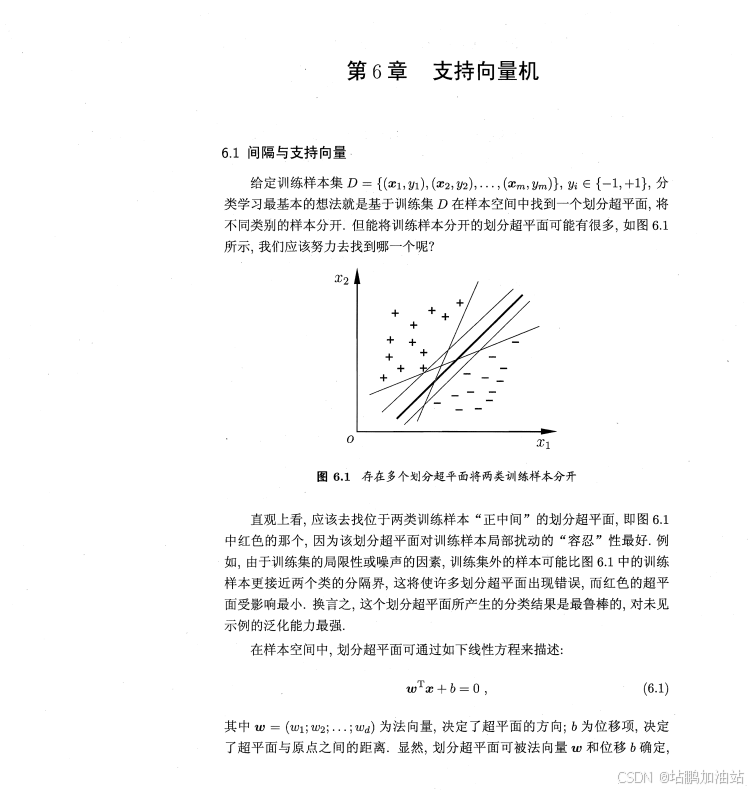
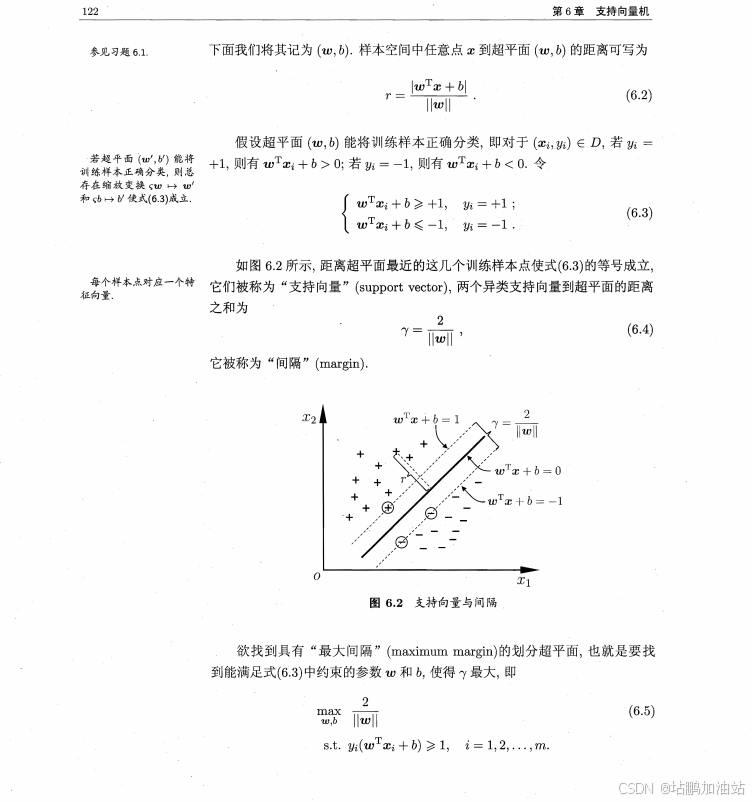



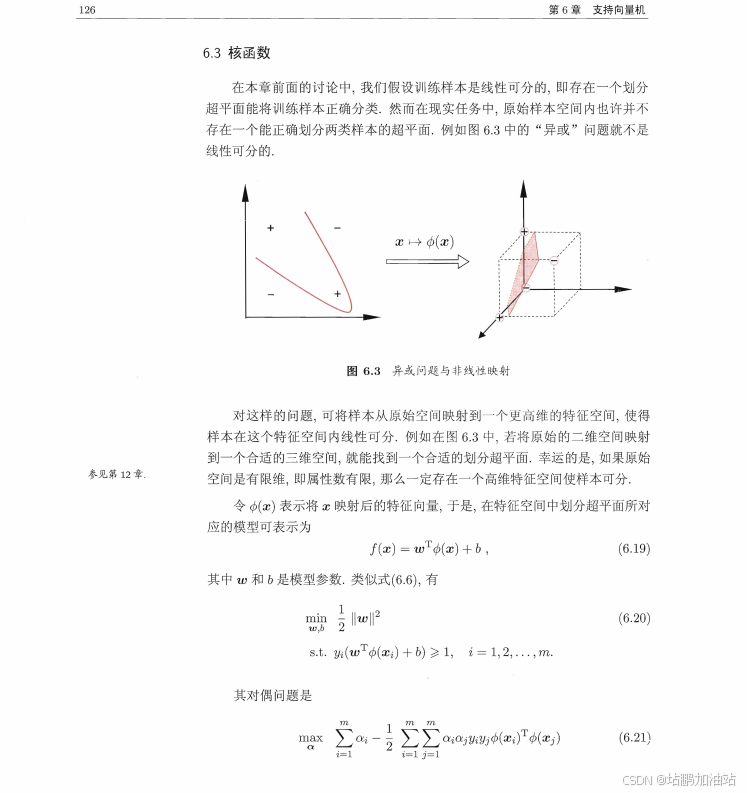


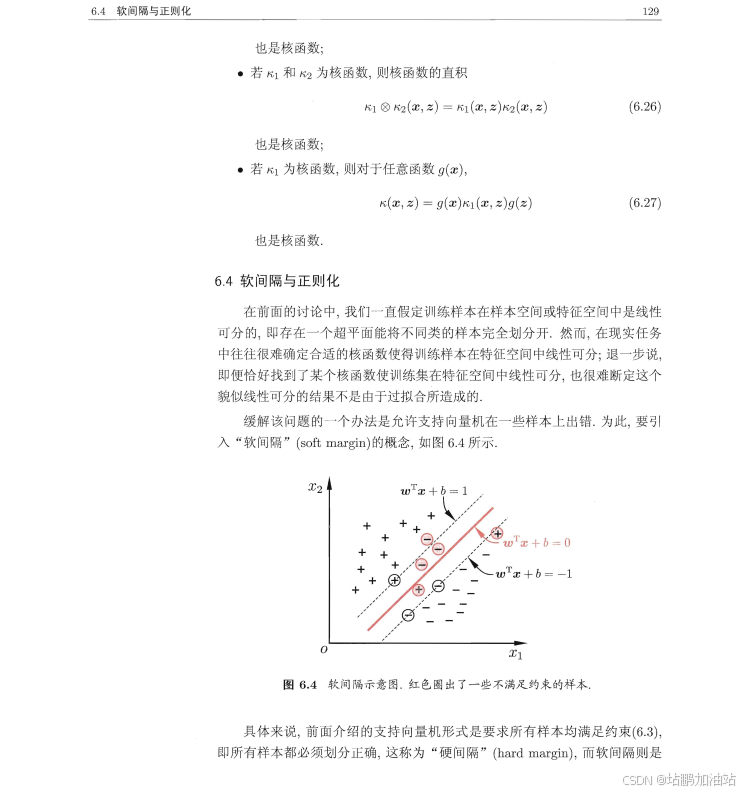




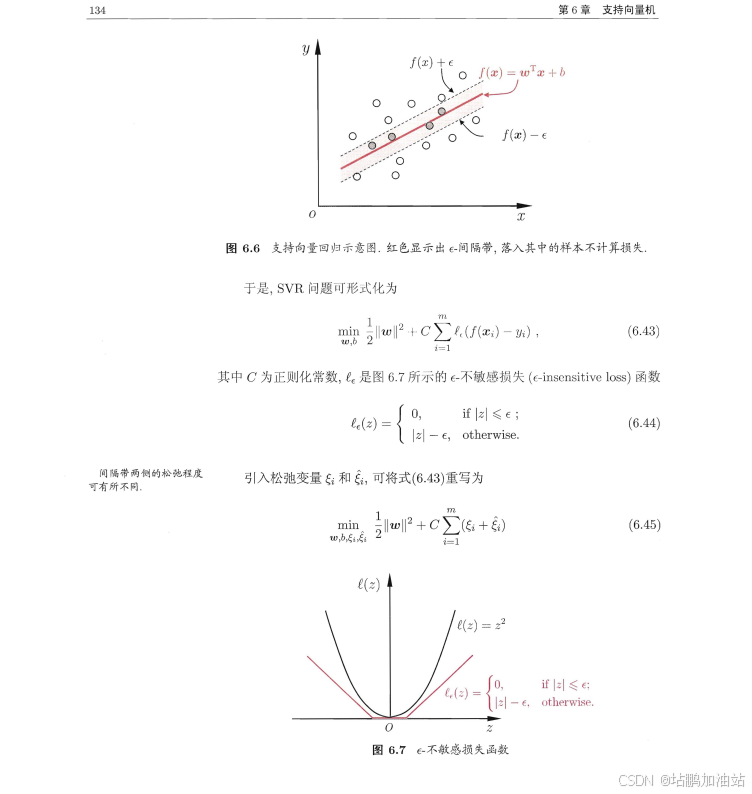






示例代码:
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'KaiTi', 'SimSun'] # 使用系统自带字体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 1. 生成模拟数据
X, y = make_blobs(n_samples=100, centers=2,
random_state=6, cluster_std=1.2)
print("这是X")
print(X)
print("这是y")
print(y)
# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42)
# 3. 创建SVM分类器(使用线性核)
clf = svm.SVC(kernel='linear', C=1.0)
clf.fit(X_train, y_train)
# 4. 预测测试集
y_pred = clf.predict(X_test)
print(y_pred)
print(y_test)
# 5. 评估模型性能
print(f"测试集准确率: {accuracy_score(y_test, y_pred):.2f}")
print("\n分类报告:")
print(classification_report(y_test, y_pred))
# 6. 可视化结果
plt.figure(figsize=(10, 6))
# 绘制训练数据
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train,
cmap='coolwarm', edgecolors='k', label='训练数据')
# 绘制测试数据
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test,
cmap='coolwarm', marker='s', s=100,
edgecolors='k', alpha=0.7, label='测试数据')
# 绘制决策边界
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
# 创建网格评估模型
xx = np.linspace(xlim[0], xlim[1], 30)
yy = np.linspace(ylim[0], ylim[1], 30)
YY, XX = np.meshgrid(yy, xx)
xy = np.vstack([XX.ravel(), YY.ravel()]).T
Z = clf.decision_function(xy).reshape(XX.shape)
# 绘制决策边界和间隔
ax.contour(XX, YY, Z, colors='k', levels=[-1, 0, 1],
alpha=0.5, linestyles=['--', '-', '--'])
ax.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1],
s=100, linewidth=1, facecolors='none',
edgecolors='k', label='支持向量')
plt.title('SVM分类结果可视化')
plt.xlabel('特征1')
plt.ylabel('特征2')
plt.legend()
plt.grid(True, linestyle='--', alpha=0.7)
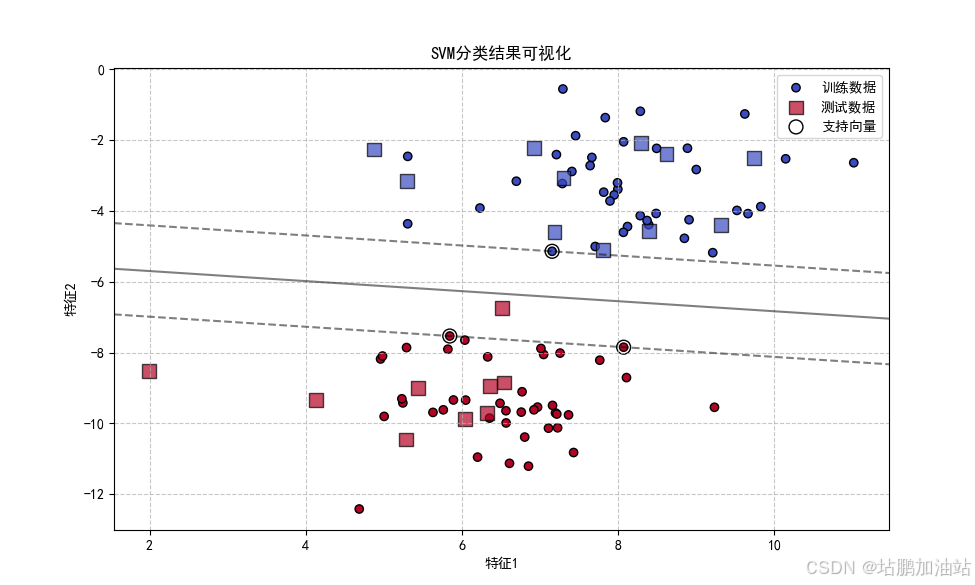
plt.show()可视化结果:
资料来源于:周志华-机器学习,如有侵权请联系删除