目录
- [一. 栈的认识](#一. 栈的认识)
-
- [1. 栈的基本概念](#1. 栈的基本概念)
- 2.栈的基本操作
- [二. 栈的核心优势](#二. 栈的核心优势)
-
- [1. 高效的时间复杂度](#1. 高效的时间复杂度)
- [2. 简洁的逻辑设计](#2. 简洁的逻辑设计)
- [3. 内存管理优化](#3. 内存管理优化)
- [三. 栈的代码实现](#三. 栈的代码实现)
- 总结
一. 栈的认识
1. 栈的基本概念
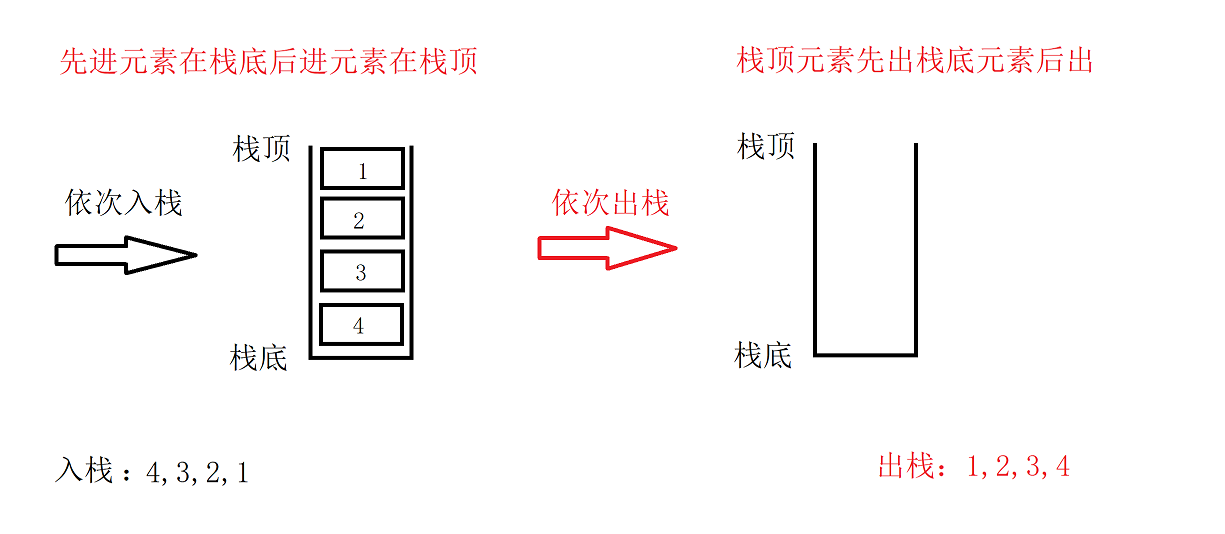
栈是一种特殊的线性表,只允许在固定的一端进行插入和删除元素的操作。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。栈中的数据元素遵循后进先出的原则。
- 压栈: 栈的插入操作叫做进栈/压栈/入栈,入数据的元素在栈顶。
- 出栈: 栈的出栈也叫删除操作,出数据也在栈顶。
2.栈的基本操作
| 操作 | 描述 | 时间复杂度 |
|---|---|---|
| Push(x) | 将元素x压入栈顶 | O(1) |
| Pop() | 出栈弹出元素 | O(1) |
| Top() | 返回栈顶元素不出栈 | O(1) |
| Empty() | 检查栈是否为空 | O(1) |
| Size() | 返回栈中元素数量 | O(1) |
二. 栈的核心优势
1. 高效的时间复杂度
- 入栈、出栈、取栈顶均为常数时间O(1)操作,适合高频调用场景。
- 专注"顶部"操作,避免不必要的复杂度。
- 对比其他数据结构:
数组:随机访问快O(1),但插入删除中间元素移动数据O(n);
链表:插入删除中间元素快O(1),但随机访问慢O(n);
2. 简洁的逻辑设计
- 减少代码的复杂度,设计更简单。
- 通过压栈和出栈自动维护操作顺序,无需手动跟踪索引指针。
3. 内存管理优化
- 局部性原理:栈操作集中在顶部,数据访问具有空间局部性,利用CPU缓存命中。
- 动态扩容策略:栈实现如动态数组通过按需扩容平衡时间和空间效率。
三. 栈的代码实现
1.栈的结构定义
c
typedef struct Stack
{
STDataType* a; // 动态数组,存储栈里的元素
int top; // 栈顶指针(初始为0,表示空栈)
int capacity; // 栈的最大容量
}ST;- a:用指针指向一块内存。
- top:指向当前栈顶的元素初始为0,表示空栈
- capacity:栈的最大容量
2. 栈的初始化
c
//初始化
void STInit(ST* pst)
{
pst->a = NULL;
//top指向栈顶数据的下一个位置
pst->capacity = pst->top = 0;
}- 初始化指针赋值为NULL,capacity和top赋值为0。
3. 入栈 (动态扩容)
c
//入栈
void STPush(ST* pst, STDataType x)
{
assert(pst);
if (pst->capacity == pst->top)
{
int newcapacity = pst->top == 0 ? 4 : 2 * pst->capacity;
STDataType* newnode = (STDataType*)realloc(pst->a, newcapacity * sizeof(STDataType));
if (newnode == NULL)
{
perror("realloc fail");
exit(-1);
}
pst->a = newnode;
pst->capacity = newcapacity;
}
pst->a[pst->top] = x;
pst->top++;
}- 当capacity等于top时,如果为空则开辟4个空间,不为空时开辟当前空间的二倍。
- 将插入的值先存放在top下标位置再top++。
4. 出栈
c
//出栈
void STPop(ST* pst)
{
assert(pst && pst->top>0);
pst->top--;
}- 直接top- - 限制访问完成出栈。
5. 取栈顶数据
c
//取栈顶数据
STDataType STTop(ST* pst)
{
assert(pst && pst->top>0);
return pst->a[pst->top - 1];
}- top的位置是在最后一个元素的下一个位置,所以取栈顶数据直接取top减1的下标。
6. 判断栈是否为空
c
//判空
bool STEmpty(ST* pst)
{
assert(pst);
return pst->top == 0;
}- 返回值是bool类型,如果top == 0则返回true。
7. 获取栈的数据个数
c
//获取数据个数
int STSize(ST* pst)
{
assert(pst);
return pst->top;
}- 因为栈的位置是从0开始的,所以直接返回top就是栈内部的数据个数。
8.销毁
c
//销毁
void STDestroy(ST* pst)
{
assert(pst);
free(pst->a);
pst->a = NULL;
pst->top = pst->capacity = 0;
}- 释放掉开辟的空间,将开辟的空间置为NULL,把top和capacity也置为空。
9.完整代码展示
- Stack.h
c
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include<stdbool.h>
typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top;
int capacity;
}ST;
//初始化
void STInit(ST* pst);
//销毁
void STDestroy(ST* pst);
//入栈
void STPush(ST* pst, STDataType x);
//出栈
void STPop(ST* pst);
//取栈顶数据
STDataType STTop(ST* pst);
//判空
bool STEmpty(ST* pst);
//获取数据个数
int STSize(ST* pst);- Stack.c
c
#include "Stack.h"
//初始化
void STInit(ST* pst)
{
pst->a = NULL;
//top指向栈顶数据的下一个位置
pst->capacity = pst->top = 0;
}
//销毁
void STDestroy(ST* pst)
{
assert(pst);
free(pst->a);
pst->a = NULL;
pst->top = pst->capacity = 0;
}
//入栈
void STPush(ST* pst, STDataType x)
{
assert(pst);
if (pst->capacity == pst->top)
{
int newcapacity = pst->top == 0 ? 4 : 2 * pst->capacity;
STDataType* newnode = (STDataType*)realloc(pst->a, newcapacity * sizeof(STDataType));
if (newnode == NULL)
{
perror("realloc fail");
exit(-1);
}
pst->a = newnode;
pst->capacity = newcapacity;
}
pst->a[pst->top] = x;
pst->top++;
}
//出栈
void STPop(ST* pst)
{
assert(pst && pst->top>0);
pst->top--;
}
//取栈顶数据
STDataType STTop(ST* pst)
{
assert(pst && pst->top>0);
return pst->a[pst->top - 1];
}
//判空 等于0就为真
bool STEmpty(ST* pst)
{
assert(pst);
return pst->top == 0;
}
//获取数据个数
int STSize(ST* pst)
{
assert(pst);
return pst->top;
}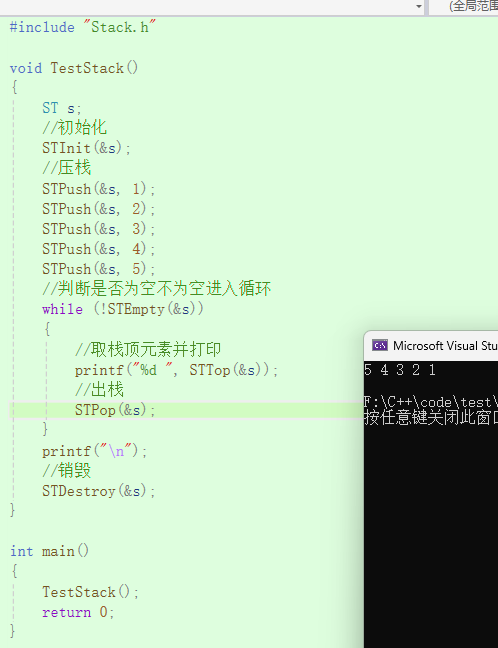
入栈顺序为:1 2 3 4 5
出栈顺序为:5 4 3 2 1
总结
根据上述讲解,相信大家对栈有更深层的理解了。栈是程序运行时内存管理的核心区域之一,遵循后进先出原则,由操作系统或运行时环境自动分配和释放,无需显式干预。其设计目标是高效管理函数调用和局部变量,但受限于固定大小,需谨慎使用以避免溢出。合理的使用栈能让程序又快又稳,滥用则容易崩溃。 本篇文章到这里就结束了,感谢大家的阅读,你们的点赞收藏加关注就是博主最大的动力。
《前期回顾》
【数据结构】------顺序表链表(超详细解析!!!)
C语言------结构体指南(小白一看就懂!!!)
力扣(LeetCode) ------移除链表元素(C语言)