-
定义:以大量经验为基础处理特定任务,有评判标准,通过分析数据提升任务完成度;其过程可理解为从经验中归纳规律,用于对新问题进行预测;或通过历史数据训练模型,利用模型对未知新数据的属性进行预测。
-
应用领域:机器学习的应用领域有很多,涵盖模式识别、计算机视觉、数据挖掘等,如 Google Translate。
-
基本术语 :
数据集:数据记录的集合。
样本:数据集中每条关于事件或对象描述的记录。
特征(属性):反映事件或对象某方面表现或性质的事项,如"色泽"。
属性空间:属性张成的空间,也叫"样本空间"。
向量表示:在机器学习中,对于包含m个示例的数据集D={x1,x2,...,xm},当每个样本由d个属性描述时,每个样本xi可表示为d维向量(xi1,xi2,...,xid),该向量处于d维样本空间X中,其中d被称为样本xi的 "维数"。
训练集:用于训练模型,包含标记信息的数据集合。
测试集:用于测试模型的数据集合。
-
学习类型 :
- 监督学习:利用已知类别的样本调整分类器参数,数据集有"正确答案"(标记)。
分类:模型输出为有限的离散型数值。
回归:模型输出为某个范围内的连续型数值。
- 无监督学习:提供数据集合但不提供标记信息的学习过程,常见算法如"聚类",例如将样本分成若干类,或分析购买尿布的人是否会购买葡萄酒等关联问题。
监督学习与无监督学习的核心区别在于是否使用带标记数据:
监督学习:用含 "正确答案"(标记)的数据训练,目标是建立输入到输出的映射,用于分类(如判断好瓜)、回归(如预测房价)等任务,依赖标记数据质量。
无监督学习:仅用无标记数据,目标是挖掘数据潜在规律,用于聚类(如用户分群)、关联分析(如商品组合挖掘)等任务,无需标记但结果解释性较弱。
- 集成学习:通过构建并结合多个学习器来完成学习任务。
-
模型评估与选择 :
- 相关概念
错误率:分类错误的样本数占样本总数的比例。
精度:1减去错误率。
残差:学习器实际预测输出与样本真实输出的差异。
训练误差(经验误差):学习器在训练集上的误差。
泛化误差:学习器在新样本上的误差。
损失函数:衡量模型预测误差大小的函数,损失函数越小模型越好。
- 拟合问题
欠拟合:模型未很好捕捉数据特征、特征集过小,导致不能很好拟合数据,本质是对数据特征学习不够。处理方式有添加新特征、增加模型复杂度、减小正则化系数。(学渣) 案例:用 "是否绿色" 单一特征判断是否为树叶(绿色的可能是青蛙、草地),导致错误分类(把绿色青蛙归为树叶)。
处理:增加特征(如 "是否有叶脉""形状是否为叶片状")、使用更复杂的模型。
过拟合:过度学习训练数据,包括噪声特征,导致泛化能力差。处理方式有增加训练数据、降维、采用正则化技术、使用集成学习方法。(学霸) 案例:训练时用 "带锯齿的绿色物体" 定义树叶(训练集中树叶恰好都有锯齿),遇到圆形叶片的树叶(无锯齿)时,错误判定为 "不是树叶"。
处理:增加更多形状的树叶样本、忽略 "锯齿" 这类非关键特征、简化模型。
- 选择模型的基本原则
奥卡姆剃刀原理:选择能很好解释已知数据且简单的模型。
没有免费的午餐(NFL):不存在对所有问题都有效的算法,谈论算法优劣需针对具体问题。
- 模型评估方法
留出法:将数据集划分为训练集(通常70%)和测试集(通常30%),需注意保持数据分布一致性(如分类任务用分层采样)和多次随机划分。
场景:用 100 个 "好瓜 / 坏瓜" 样本训练模型,需划分训练集和测试集。
操作:按 7:3 比例,选取 70 个样本(保持 "好瓜占 60%、坏瓜占 40%" 的原始比例,即分层采样)作为训练集,30 个样本作为测试集;重复 3 次随机划分,取 3 次测试结果的平均值作为最终评估。
交叉验证法:将数据集划分为k个互斥子集,每次用k-1个子集为训练集,1个为测试集,进行k次训练和测试,返回均值,也叫"k折交叉验证"。
场景:用 100 个 "好瓜 / 坏瓜" 样本评估模型稳定性。
操作:将 100 个样本分成 10 个互斥子集(每个子集 10 个样本,保持类别比例一致);第 1 次用子集 1-9 训练、子集 10 测试,第 2 次用子集 1-8 和 10 训练、子集 9 测试...... 共进行 10 次,最终取 10 次测试结果的均值作为评估指标。
- 评估指标
TP(True positive,真正例)------将正类预测为正类数。
FP(False postive,假正例)------将反类预测为正类数。
TN(True negative,真反例)------将反类预测为反类数。
FN(False negative,假反例)------将正类预测为反类数。
以 "判断西瓜是否为好瓜" 为例(正类为 "好瓜",反类为 "坏瓜"):
TP(真正例):实际是好瓜,模型预测为好瓜。
FP(假正例):实际是坏瓜,模型错误预测为好瓜。
TN(真反例):实际是坏瓜,模型预测为坏瓜。
FN(假反例):实际是好瓜,模型错误预测为坏瓜。
查准率(精确率)P:\(P=\frac{TP}{TP + FP}\);查全率(召回率)R:\(R=\frac{TP}{TP + FN}\),两者通常呈反向关系。
P-R图:直观显示查全率和查准率,若一学习器P-R曲线被另一完全包住,则后者性能更优;曲线交叉时难分优劣。
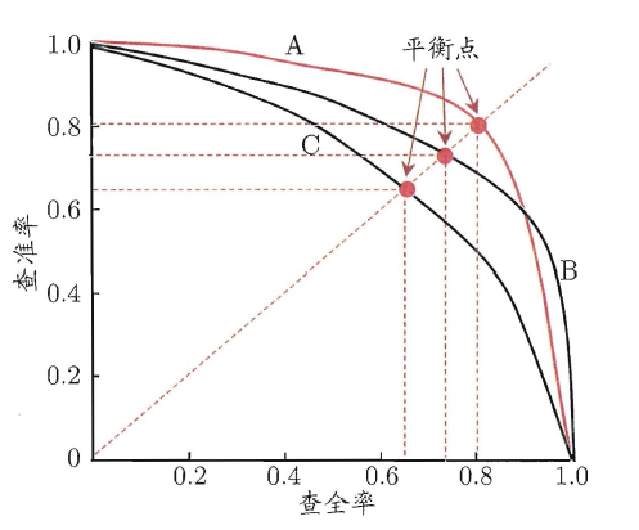 如图所示, 若一条曲线完全 "包裹" 另一条(如 A 包裹 B、C ),则被包裹的曲线性能更差。例如:相同查全率下,A 的查准率更高 → A 模型 "又准又全" 的能力优于 C , B的性能也优于C。若曲线交叉(如 A 和 B局部交叉),则需结合具体业务需求(更看重 "准" 还是 "全" )判断。
如图所示, 若一条曲线完全 "包裹" 另一条(如 A 包裹 B、C ),则被包裹的曲线性能更差。例如:相同查全率下,A 的查准率更高 → A 模型 "又准又全" 的能力优于 C , B的性能也优于C。若曲线交叉(如 A 和 B局部交叉),则需结合具体业务需求(更看重 "准" 还是 "全" )判断。
机器学习(1)
停停的茶2025-08-15 8:31
相关推荐
databook33 分钟前
用相关性分析消除“冗余特征”SomeB1oody1 小时前
【RustyML入门】1.0. 快速上手布鲁飞丝2 小时前
彩笔运维勇闯机器学习--cpu与qps的线性关系LayZhangStrive3 小时前
线性代数 - 第1章 行列式骊城英雄6 小时前
彩笔运维勇闯机器学习--逻辑回归ShallWeL8 小时前
【机器学习】(30)—— 嵌入空间问商十三载8 小时前
RAG 检索召回越多越好?2026 信噪比模型深度解析iiiiii119 小时前
【论文阅读笔记】Reparameterization Proximal Policy Optimization (RPO):将PPO的稳定性引入可微分强化学习知识分享小能手10 小时前
高等数学学习教程,从入门到精通,微分中值定理与导数的应用(5)西西弗Sisyphus11 小时前
部署模型的优化:图像标准化预处理从三步到一步乘加(2)