
论文标题:THE LANGUAGE OF TIME : A LANGUAGE MODEL PER-SPECTIVE ON TIME SERIES FOUNDATION MODELS
论文链接:https://arxiv.org/abs/2412.17323
核心悖论
受大型语言模型的启发,时间序列基础模型通过大规模预训练和微调取得了显著成功,展现出较好的表达能力、泛化能力和跨域迁移能力。然而,这一实证成功与不断增多的批判性分析形成鲜明对比。
核心矛盾点在于:每个时间序列代表着具有独特时间模式的系统,因此在不同领域(如能源消耗与气候科学)之间迁移模型必然会引发显著的分布偏移。
这种模型实际表现与理论预期之间的矛盾,引发了关于模型安全性、可靠性及其理论基础的根本性问题。
核心理论:"时间的语言"假说
本文核心观点是:基于patch嵌入的时序基础模型可从形式上理解为大型语言模型的扩展,即可以将序列输入的基本单元理解为"token的分布"。
不难理解,在语言模型中,处理的是离散的token(词语),而时序模型将时序patch(短时间片段)作为基本单元。那么patch对应于模式族或重复出现的时序motifs,其嵌入在潜在空间中形成的是分布而非单点。下面两个图可以辅助佐证以上观点。
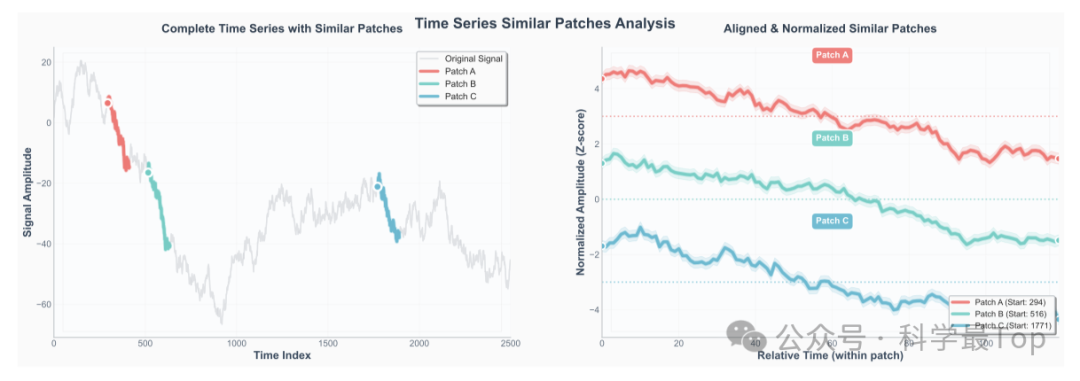
图1:相似时间序列片段及其对齐后的可视化。左图:完整信号中三个高亮显示的patch(Patch A/B/C)尽管振幅不同,但具有相同的趋势形状。右图:经过Z-Score归一化和时间对齐后,曲线几乎重叠,表明这些片段属于同一潜在b表示。
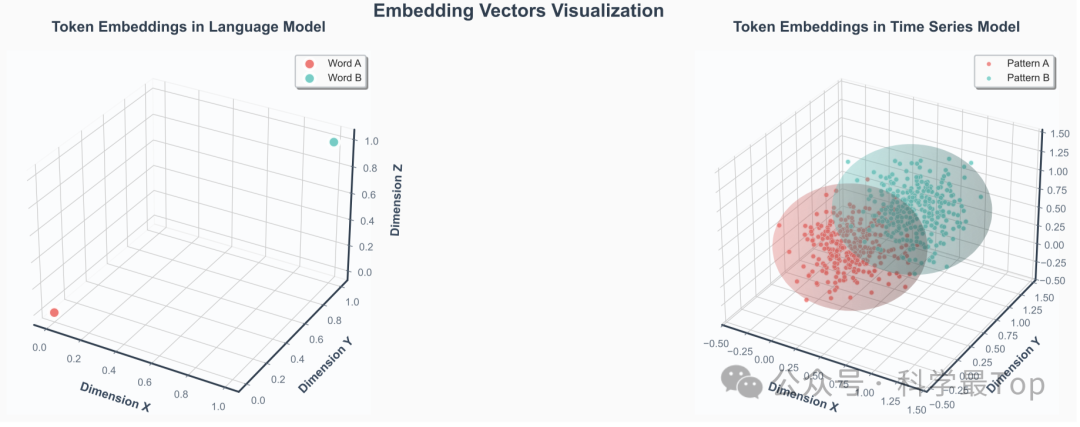
图2:语言token与时序patch嵌入的对比。左图:在语言模型中,token嵌入呈现为离散且稀疏分布的单点。右图:在时间序列模型中,patch嵌入形成具有有限厚度的概率云;同一 motifs(模式A/B)的patch聚集成可分离但内部连续的区域,阐释了"分布性token"的概念。
正是这种从点表示到分布表示的扩展,使模型能够继承大型语言模型强大的表示和迁移能力。
实证验证
目标: 验证时间序列数据蕴含与自然语言相似的深层统计结构,即通过将连续时间动态符号化为离散词汇表,观察其是否遵循类语言的统计规律。
01 词汇表构建
- 核心方法:
-
patch分割:将原始时间序列按长度P、步长S分割为连续片段(patch),作为分析基本单元。
-
向量量化:使用K-Means聚类算法对38k个跨领域时间序列patch进行量化,生成由K个质心组成的"时间词语"词汇表,每个质心代表一种从数据中学习到的基础动态模式。
-
离散映射:将每个patch映射到词汇表中最近的质心索引,将连续时间序列转换为离散token序列,实现数据压缩与去噪。
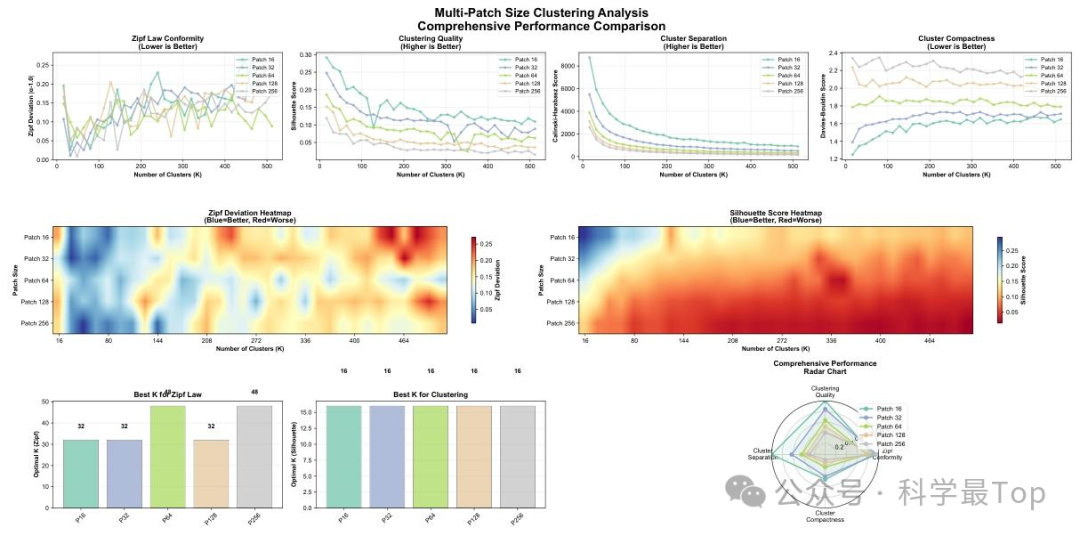
- 关键发现:patch大小的权衡
-
小patch(P=16):聚类质量高(轮廓系数高),对应简单"原子"模式,结构清晰但语义单一。
-
大patch(P≥64):更符合Zipf定律,捕捉复杂"时间motifs",语义丰富但聚类紧凑性较低。
-
结论:patch大小决定词汇表特性------小patch侧重结构,大patch侧重类语言统计特性。
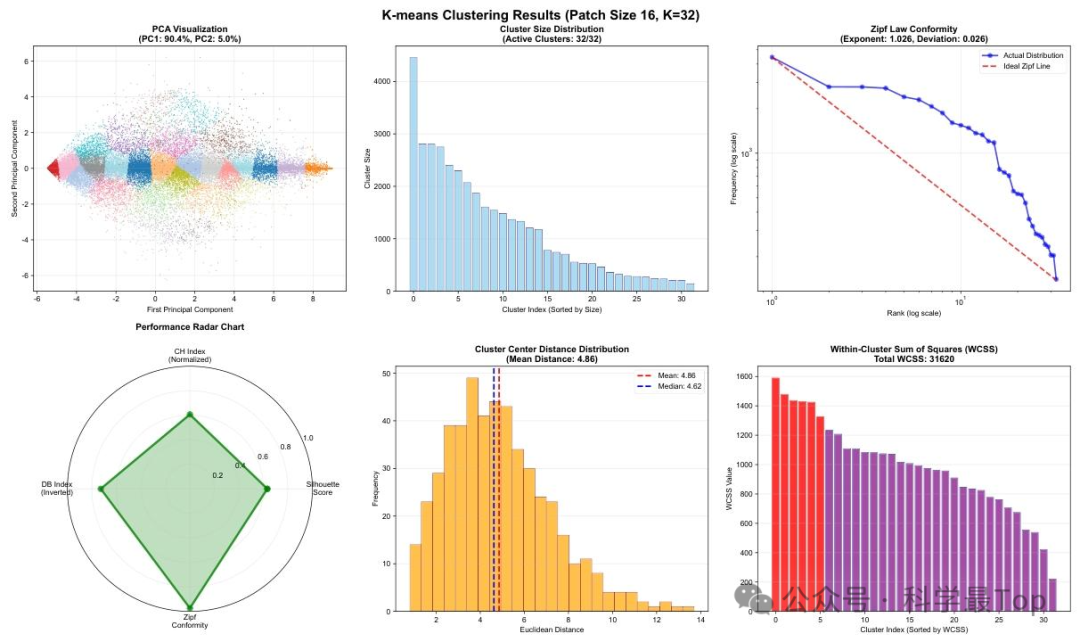
- 聚类与分布分析
-
PCA可视化:patch嵌入形成部分可分离但重叠的簇,验证"分布性token"假设,即时间motifs在潜在空间中为连续区域而非单点。
-
Zipf定律验证:簇大小分布呈典型长尾结构,log-log坐标下与理想Zipf分布偏差仅0.026,证明时间序列token遵循类语言的幂律分布。
-
簇内方差(WCSS):部分簇内平方和高,表明同一token对应多种相似但非identical的时间模式,支持"token代表模式族"的观点。
02 时间序列的类语言特性
- 时间词汇中的Zipf分布发现
-
不同词汇量K(16-256)下,token频率分布均严格遵循Zipf定律,元素的出现频率与其排名大致成反比,即第n名元素的频率约为第一名的1/n。
-
意义:时序由有限可重用"motifs"组合而成,类似语言"语法-词汇"结构。
2.词汇表结构的鲁棒性与动态适应性
- 稳定性验证:随K增大,token平均频率降低,但"少数高频motifs+大量低频motifs"的不平衡结构不变,高频outliers始终存在,证明聚类捕捉到数据中真实稳定的基础模式。
03 时时间序列的"语法"
核心发现:motif序列的组合规则
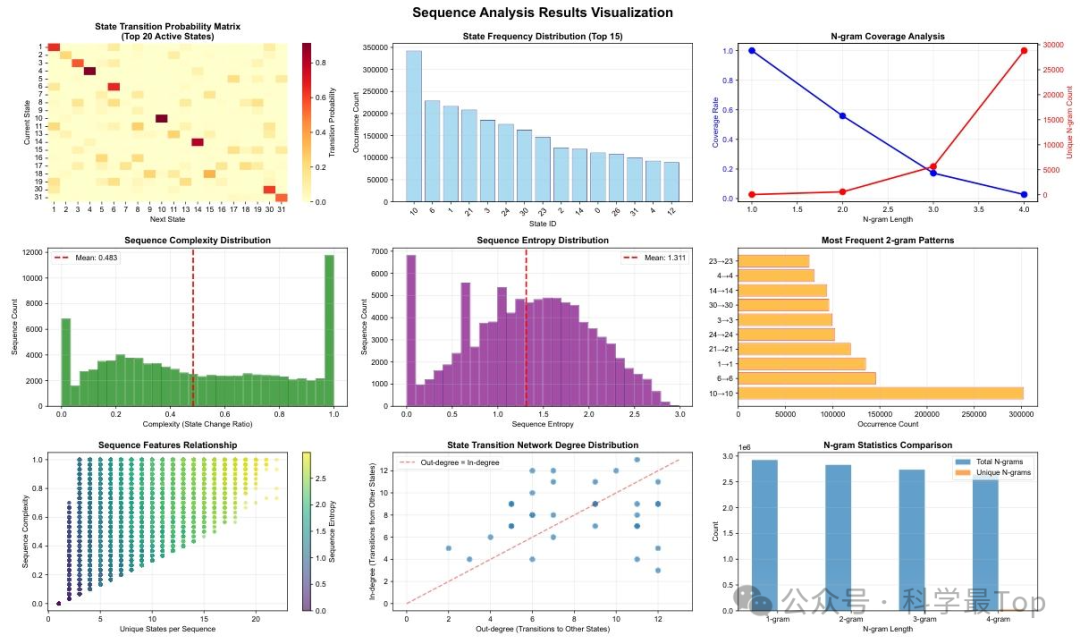
-
状态惯性原则:状态转移矩阵中自转移概率占主导(对角线高亮),2-gram统计显示"motif自循环"最常见,表明时间动态具有持续性。
-
稀疏语法结构:n-gram覆盖度随n增大指数衰减,仅少数motif组合"合法",类似自然语言的句法约束。
-
宏观多样性的微观分块机制:序列复杂度与熵分布广泛,由持续的"motif块"拼接形成,类似语言中短语组合成句的层次结构。
本文结论
通过构建时间序列词汇表并分析其统计特性与组合规则,证实时间序列数据在token化后呈现显著的类语言特征:遵循Zipf定律、具备状态转移"语法"、通过分块形成复杂模式。这些发现为时间序列基础模型的跨域迁移能力提供了实证支持,即模型通过学习"时间的语言"实现对动态模式的抽象表示。
**大家可以关注我【科学最top】,第一时间follow时序高水平论文解读!!!**获取时序论文合集
