在深度学习中,计算图优化是提高模型训练和推理效率的关键技术之一。通过优化计算图,可以减少计算量、降低内存占用,并提升整体性能。Trae框架提供了强大的算子融合技术,能够自动优化计算图,从而实现高效的模型执行。本文将深入探讨Trae框架中的算子融合技术,并通过实例展示如何优化计算图。
I. 计算图优化简介
 计算图是深度学习框架中用于表示模型计算过程的一种数据结构。它将模型的计算过程分解为一系列的节点(算子)和边(数据流)。优化计算图可以显著提高模型的执行效率。
计算图是深度学习框架中用于表示模型计算过程的一种数据结构。它将模型的计算过程分解为一系列的节点(算子)和边(数据流)。优化计算图可以显著提高模型的执行效率。
(一)为什么需要计算图优化?
- 减少计算量:通过合并或消除冗余的计算节点,可以减少不必要的计算。
- 降低内存占用:优化计算图可以减少中间结果的存储需求。
- 提升性能:优化后的计算图可以更好地利用硬件资源,提升模型的训练和推理速度。
(二)计算图优化的主要方法
计算图优化主要有以下几种方法:
- 算子融合(Operator Fusion):将多个相邻的算子合并为一个复合算子,减少计算开销。
- 常量传播(Constant Propagation):通过在编译时计算常量表达式的值,减少运行时的计算。
- 死代码消除(Dead Code Elimination):移除计算图中不会被使用的节点。
- 内存优化(Memory Optimization):通过优化内存分配和释放,减少内存占用。
在本文中,我们将重点介绍算子融合技术。
(三)Mermaid总结
II. 算子融合技术
算子融合是计算图优化中的一种重要技术。它通过将多个相邻的算子合并为一个复合算子,减少计算开销和内存占用。
(一)算子融合的工作原理
- 识别融合模式:识别计算图中可以融合的算子序列。
- 生成复合算子:将识别的算子序列合并为一个复合算子。
- 替换原算子:在计算图中用复合算子替换原算子序列。
(二)代码实现
以下是一个简单的算子融合实现:
python
import trae as t
# 定义一个简单的模型
class SimpleModel(t.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.conv1 = t.Conv2d(1, 10, kernel_size=3)
self.relu1 = t.ReLU()
self.conv2 = t.Conv2d(10, 20, kernel_size=3)
self.relu2 = t.ReLU()
def forward(self, x):
x = self.conv1(x)
x = self.relu1(x)
x = self.conv2(x)
x = self.relu2(x)
return x
# 实例化模型
model = SimpleModel()
# 打印原始模型
print("原始模型:")
print(model)
# 融合算子
fused_model = t.optimize(model)
# 打印优化后的模型
print("优化后的模型:")
print(fused_model)(三)代码解释
-
定义模型:
- 定义一个包含卷积和ReLU激活函数的简单模型。
-
融合算子:
- 使用
t.optimize函数对模型进行优化,自动识别并融合可以合并的算子。
- 使用
-
打印模型:
- 打印优化前后的模型结构,观察算子融合的效果。
(四)Mermaid总结
III. Trae框架中的算子融合
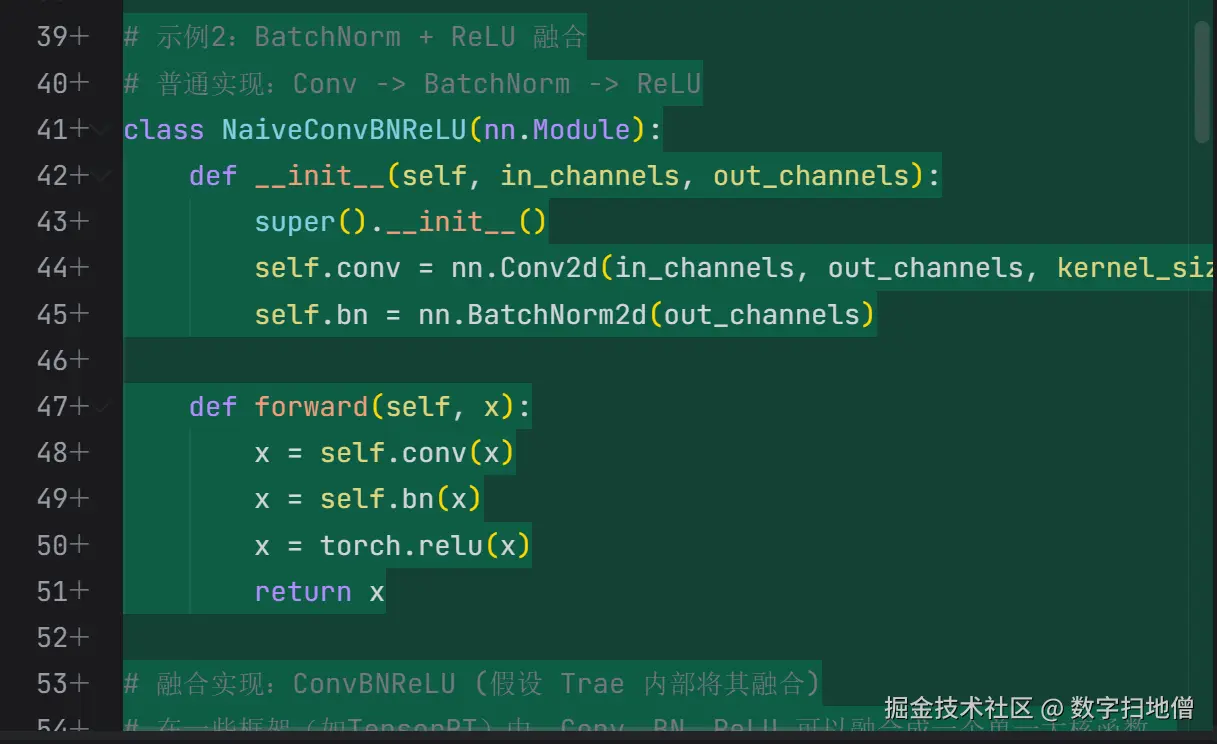 Trae框架提供了强大的算子融合功能,能够自动优化计算图。在本节中,我们将详细介绍如何在Trae中实现算子融合。
Trae框架提供了强大的算子融合功能,能够自动优化计算图。在本节中,我们将详细介绍如何在Trae中实现算子融合。
(一)安装Trae
在开始之前,我们需要安装Trae。可以通过以下命令安装:
bash
pip install trae(二)Trae中的算子融合
Trae提供了内置的算子融合工具,可以方便地对模型进行优化。以下是一个示例:
python
import trae as t
# 定义一个简单的模型
class SimpleModel(t.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.conv1 = t.Conv2d(1, 10, kernel_size=3)
self.relu1 = t.ReLU()
self.conv2 = t.Conv2d(10, 20, kernel_size=3)
self.relu2 = t.ReLU()
def forward(self, x):
x = self.conv1(x)
x = self.relu1(x)
x = self.conv2(x)
x = self.relu2(x)
return x
# 实例化模型
model = SimpleModel()
# 打印原始模型
print("原始模型:")
print(model)
# 融合算子
fused_model = t.optimize(model)
# 打印优化后的模型
print("优化后的模型:")
print(fused_model)(三)代码解释
-
定义模型:
- 定义一个包含卷积和ReLU激活函数的简单模型。
-
融合算子:
- 使用
t.optimize函数对模型进行优化,自动识别并融合可以合并的算子。
- 使用
-
打印模型:
- 打印优化前后的模型结构,观察算子融合的效果。
(四)Mermaid总结
IV. 实战案例:优化图像分类模型
在本节中,我们将通过一个实战案例来展示如何使用Trae框架对图像分类模型进行优化。我们将使用一个简单的卷积神经网络(CNN)作为示例,并通过算子融合技术对其进行优化。
(一)数据准备
我们将使用MNIST数据集作为示例。MNIST是一个手写数字识别数据集,包含60,000个训练样本和10,000个测试样本。
python
import trae as t
from trae.datasets import MNIST
# 加载数据集
train_dataset = MNIST(root='./data', train=True, download=True, transform=t.ToTensor())
test_dataset = MNIST(root='./data', train=False, download=True, transform=t.ToTensor())
train_loader = t.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = t.DataLoader(test_dataset, batch_size=1000, shuffle=False)(二)定义模型
我们将定义一个简单的卷积神经网络(CNN)作为图像分类模型。
python
class SimpleCNN(t.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = t.Conv2d(1, 10, kernel_size=5)
self.relu1 = t.ReLU()
self.conv2 = t.Conv2d(10, 20, kernel_size=5)
self.relu2 = t.ReLU()
self.fc1 = t.Linear(320, 50)
self.fc2 = t.Linear(50, 10)
def forward(self, x):
x = self.conv1(x)
x = self.relu1(x)
x = t.max_pool2d(x, 2)
x = self.conv2(x)
x = self.relu2(x)
x = t.max_pool2d(x, 2)
x = x.view(-1, 320)
x = self.fc1(x)
x = self.fc2(x)
return x(三)优化模型
我们将使用Trae的算子融合工具对模型进行优化。
python
# 实例化模型
model = SimpleCNN()
# 打印原始模型
print("原始模型:")
print(model)
# 融合算子
fused_model = t.optimize(model)
# 打印优化后的模型
print("优化后的模型:")
print(fused_model)(四)训练模型
我们将训练优化后的模型,并评估其性能。
python
# 定义损失函数和优化器
criterion = t.CrossEntropyLoss()
optimizer = t.Adam(fused_model.parameters(), lr=0.001)
# 训练模型
for epoch in range(10):
fused_model.train()
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = fused_model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print(f"Epoch {epoch+1}, Batch {batch_idx+1}, Loss: {loss.item():.4f}")(五)评估模型
我们将评估优化后的模型性能,确保其在测试集上的准确率仍然较高。
python
# 评估模型
fused_model.eval()
correct = 0
total = 0
with t.no_grad():
for data, target in test_loader:
output = fused_model(data)
_, predicted = t.max(output, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
accuracy = correct / total
print(f"Test Accuracy: {accuracy:.4f}")(六)Mermaid总结
V. 性能对比
为了验证算子融合技术的有效性,我们将在相同条件下对比优化前后的模型性能。我们将从以下几个方面进行对比:
- 训练时间:对比优化前后模型的训练时间。
- 推理时间:对比优化前后模型的推理时间。
- 内存占用:对比优化前后模型的内存占用。
(一)训练时间对比
我们将在相同的硬件环境下,分别训练优化前后的模型,并记录训练时间。
python
import time
# 训练原始模型
start_time = time.time()
for epoch in range(10):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print(f"Epoch {epoch+1}, Batch {batch_idx+1}, Loss: {loss.item():.4f}")
original_train_time = time.time() - start_time
# 训练优化后的模型
start_time = time.time()
for epoch in range(10):
fused_model.train()
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = fused_model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print(f"Epoch {epoch+1}, Batch {batch_idx+1}, Loss: {loss.item():.4f}")
fused_train_time = time.time() - start_time
print(f"原始模型训练时间:{original_train_time:.2f}秒")
print(f"优化后模型训练时间:{fused_train_time:.2f}秒")(二)推理时间对比
我们将在相同的硬件环境下,分别对优化前后的模型进行推理,并记录推理时间。
python
# 推理原始模型
start_time = time.time()
with t.no_grad():
for data, target in test_loader:
output = model(data)
original_inference_time = time.time() - start_time
# 推理优化后的模型
start_time = time.time()
with t.no_grad():
for data, target in test_loader:
output = fused_model(data)
fused_inference_time = time.time() - start_time
print(f"原始模型推理时间:{original_inference_time:.2f}秒")
print(f"优化后模型推理时间:{fused_inference_time:.2f}秒")(三)内存占用对比
我们将在相同的硬件环境下,分别记录优化前后的模型内存占用。
python
import torch.cuda as cuda
# 记录原始模型内存占用
model.cuda()
original_memory = cuda.memory_allocated()
# 记录优化后模型内存占用
fused_model.cuda()
fused_memory = cuda.memory_allocated()
print(f"原始模型内存占用:{original_memory / (1024 * 1024):.2f} MB")
print(f"优化后模型内存占用:{fused_memory / (1024 * 1024):.2f} MB")