在一些 IDE 中,反汇编有啥用?
在日常写代码时,我们通常只会关注代码的本二审,毕竟它才是我们真正维护和修改的部分。
但是有时候如果想要了解一下底层原理,我们可能压根就不晓得怎么去了解。
可能就是上网搜搜博客,或者问一下AI。
实际上,在一些常见的IDE中,就有一个功能可以让你更快速地了解你所写代码地底层汇编逻辑,从而能够更深层次地了解你自己写的代码到底是些啥意思。
这个功能叫做------反汇编(Disassembly) 。
它能把编译器生成的机器码翻译成汇编指令,并让你直接在调试时查看这些指令。
在汇编语言中,像jmp、mov等,都是常见的指令,所以在使用这个功能之前,得先去学学汇编语言~
其实,反汇编是一个非常实用的底层调试工具,只是你平时不一定需要它。但一旦遇到某些场景,它的价值就会凸显出来。
1. 什么是"反汇编"?
简单来说:
- 汇编无需多言。
- 反汇编 就是把二进制的机器码翻译回汇编指令,即汇编的反向。

机器码是 CPU 能直接执行的内容(0 和 1),而汇编是一种一对一映射的符号化表示,例如:
B8 04 00 00 00 mov eax, 4这种信息对于 CPU 来说就是直接可执行的,对于人类来说则比纯二进制可读一些。
像 VS、CLion、Xcode等IDE里,在调试器里调用反汇编器,就能在源码缺失或无法匹配的情况下,把执行位置显示成汇编指令。
接下来,我列举几个场景,方便大家快速理解反汇编的用法。
2. 反汇编的使用场景
场景一:源码缺失时的调试
有时候你调试的程序会调用某些库(特别是闭源的第三方库),而你手头没有这些库的源代码。
当你单步执行到库内部时,IDE 会切换到反汇编视图,这样你就能看到:
- 函数调用的指令流程
- 寄存器的使用情况
- 参数传递与返回值的位置(遵循 ABI 约定)
使用反汇编,就能够更加简洁明了。
场景二:优化性能
性能优化的核心之一是确认编译器生成的机器指令是否高效。
反汇编可以帮你:
- 确认编译器是否启用了内联优化 、循环展开等。
- 检查是否产生了冗余指令(例如多余的寄存器保存/恢复)。
- 分析关键路径上的分支预测与指令流水情况。
你可以试试把源码和反汇编对照着看,其实有大量的代码冗余可以通过这个方式来进行清理~
场景三:调试 release 版本的 bug
在 release 模式下,编译器会进行大量优化,源码与实际执行指令可能会严重错位:
- 一行 C++ 代码可能被优化成多条指令,甚至被合并到其他地方。
- 局部变量可能被优化掉,只存在寄存器里。
- 代码顺序可能被重新排列。
这时候调试器的源码视图会变得"不可靠",而反汇编能直接显示 CPU 实际执行的指令,让你跟踪真实的执行流。就跟下面类似:

场景四:安全与逆向分析
虽然这是更偏向网安的领域,但还是可以了解一下的。 它可以帮你:
- 查看函数调用链
- 定位可疑的内存访问
- 分析输入数据是如何影响程序流程的
3. IDE 中反汇编的用法
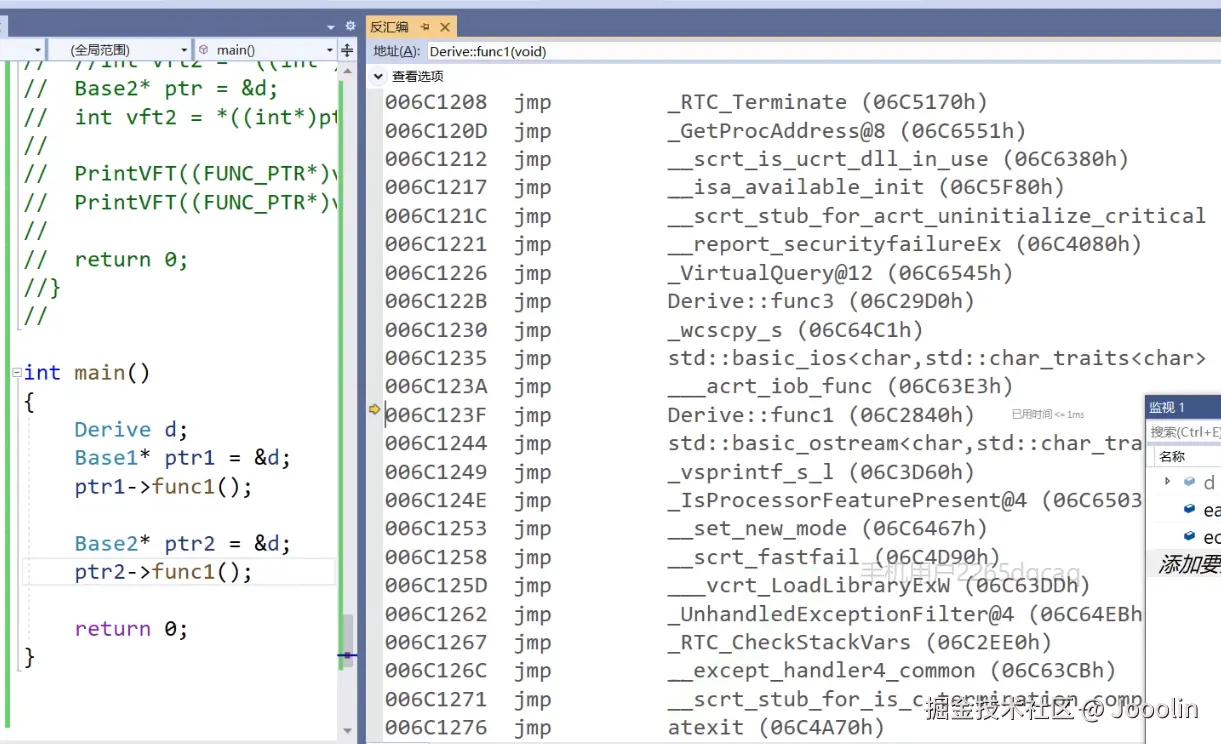
以 Visual Studio 为例:
- 1.先进入反汇编模式
- 2.源码 + 汇编结合着看:能同时看到源代码和对应的汇编,这对于学习编译器生成模式很有帮助。
- 3.你也可以开着寄存器窗口进行监视:反汇编配合寄存器窗口,可以实时观察数据如何在寄存器和内存之间流动。
- 4.单步执行汇编指令:调试器支持一步步执行机器指令,这在分析崩溃现场时尤其有用。
如下图:
4. 反汇编的局限性
虽然反汇编很强大,但也有一些限制:
- 反汇编出来的内容依赖编译器生成的二进制,缺少高层语义(比如类名、变量名)。
- 某些优化可能让汇编结构非常复杂,不易阅读。
- 它显示的是执行结果,而不是源代码的真实逻辑。
5. 小结~
反汇编,其实跟debug一样,就是一种调试代码的方式,你可用可不用,但是你要是会用,作用还是蛮大的。
想了解底层,就多用用咯~