方法一:指针的指针 (Pointer to Pointer)
ini
//1.
int **dp = new int*[n];
for(int i = 0;i < n; ++i){
dp[i] = new int [m];
}- 原理 :这是最基础的方法。先创建一个指针数组(每个元素都是一个 int* ),然后再循环为每个指针分配一块内存。
- 内存布局 : 不连续 。每一行都是一个独立的内存块,它们在内存中的位置是分散的。
- 优点 :非常灵活,可以创建"锯齿数组"(即每一行的长度 m 都可以不同)。
- 缺点 :释放内存繁琐且极易出错(必须先循环 delete\[\] 每一行,再 delete\[\] 指针数组),性能稍差(两次指针解引用,缓存不友好)。
- 释放 : for(...) { delete\[\] dpi; } delete\[\] dp;
方法二: malloc + new 混合使用 (严重不推荐)
go
//2.
int len = 100;
int **dp = (int **)malloc(sizeof
(int) *(len+1)); // 应该是 sizeof
(int*)
for(int i = 0;i <= len; ++i){
dp[i] = new int[4];
}- 原理 :用C语言的 malloc 来创建外层的指针数组,然后用C++的 new 来创建内层的每一个数据行。
- 内存布局 : 不连续 。
- 优点 : 没有任何优点 。
- 缺点 :这是 绝对应该避免 的"反模式"。它混合了两种不同的内存管理机制( malloc/free 和 new/delete ),是造成混乱和内存泄漏的根源。你必须记住用 free 释放外层,用 delete\[\] 释放内层,极度危险。
- 释放 : for(...) { delete\[\] dpi; } free(dp);
方法三: vector 两步法 (先创建行,再定义列)
ini
//3.
int n = 10,m=2;
vector<vector<int>> dp(n);
for(int i = 0;i < n; i++){
dp[i].resize(m);
}- 原理 :利用 vector 的构造函数,一次性创建一个包含 n 个元素的 vector ,并指定每个元素都是一个"模版"(即一个已经创建好的、包含 m 个元素的
vector<int>)。 - 内存布局 : 不连续 。
- 优点 : 现代C++的最佳实践 。代码最简洁、最安全、可读性最高。
- 缺点 :几乎没有。
- 释放 : 自动 ,无需任何操作。
方法四: vector 一步法 (构造函数直接初始化)
js
//4.
vector<vector<int>> dp(n,vector<int>
(m));- 原理 :利用 vector 的构造函数,一次性创建一个包含 n 个元素的 vector ,并指定每个元素都是一个"模版"(即一个已经创建好的、包含 m 个元素的
vector<int>)。 - 内存布局 : 不连续 。
- 优点 : 现代C++的最佳实践 。代码最简洁、最安全、可读性最高。
- 缺点 :几乎没有。
- 释放 : 自动 ,无需任何操作。
方法五:数组指针法 (Array Pointer)
scss
//5.
void Test(unsigned int n){
// ...
int(* array2D)[5] = new int[n][5];
// ...
delete[] array2D;
}- 原理 :直接 new 一个真正的二维数组。但为了接收它的地址,必须使用一个"数组指针" int(*)5 ,它表示"一个指向包含5个int的数组的指针"。
- 内存布局 : 完全连续 。这是它相比方法一最大的优势,缓存友好,性能高。
- 优点 :内存连续,性能好,申请和释放都只有一次操作,非常简单。
- 缺点 : 极不灵活 。除了第一维(行数 n )可以是变量,后续所有维度(这里是列数 5 )都 必须是编译时确定的常量 。语法也比较晦涩。
- 释放 : delete\[\] array2D;
五种方法的对比
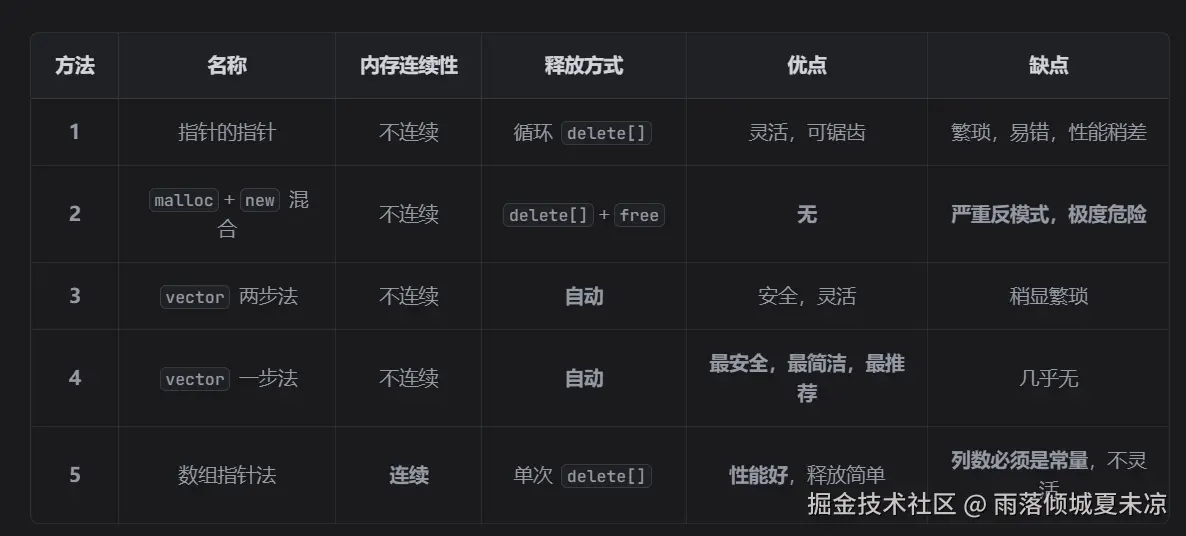
面试官回答策略
面试官: "请你谈谈在C++中,如果需要创建一个二维数组,有哪些方法?它们各有什么优缺点?"
你: "好的,面试官。在C++中创建二维数组,根据内存布局、安全性和灵活性的不同,主要可以分为三大类方法,我会逐一介绍它们的实现和权衡。"
(第一步,开篇点题,先说最佳实践)
"首先,在现代C++开发中,我 首选且强烈推荐 的方法是使用 std::vector ,也就是您给出的 方法四 和 方法三 。"
- " 最佳实现 是
vector<vector<int>> dp(n, vector<int>(m));。这行代码利用构造函数一次性创建了一个n行m列的二维数组。它的核心优势是 绝对安全 和 代码简洁 。 vector 内部通过RAII机制自动管理内存,我们完全不需要关心 new 和 delete ,从根本上杜绝了内存泄漏的风险。代码可读性也是最高的。" - "如果需要一个每行长度不固定的'锯齿数组',我会先
vector<vector<int>> dp(n);,然后通过循环 resize 每一行。这同样享受 vector 带来的所有安全便利。" - " 这类方法的唯一权衡 是,它的每一行内存是独立分配的,所以 物理内存不连续 。但在绝大多数业务场景下,它带来的安全性和开发效率远比微小的性能差异更重要。"
(第二步:展示基础功底,分析传统指针法)
"其次,是传统的C-style方法,也就是 方法一 ,使用'指针的指针'int** 。"
- "它的实现方式是先 new 一个指针数组,然后循环为每个指针 new 出一行。这种方法的优点是 非常灵活 ,可以轻松实现锯齿数组。"
- "但它的 缺点非常突出 :
- 内存管理复杂且危险 :你需要手动循环 delete 每一行,最后再 delete 指针数组,非常容易漏掉其中一步导致内存泄漏。
- 内存不连续 :和 vector 类似,它的行与行之间地址不连续,可能影响CPU缓存效率。
- 性能开销 :访问一个元素 dpij 需要两次解引用,理论上比连续内存要慢。"
(第三步:展现知识深度,讲解高性能但受限的方法)
"第三种,是一种追求极致性能的特殊方法,即 方法五 ,使用'数组指针'。"
- "它的写法是
int(*array2D)[M] = new int[N][M];。这种方法的核心优势是它能创建一块 真正的、物理上完全连续的二维数组内存 。这对于CPU缓存非常友好,因此在需要频繁遍历、对性能要求极高的场景(如图像处理、科学计算)下是最佳选择。同时,它的释放也只需要一次 delete\[\] ,非常干净。" - "然而,它的 限制性极强 :除了第一维(行数N)可以是变量,后续所有维度(列数M)都 必须是编译时确定的常量 。这使得它在动态场景下几乎无法使用。同时,它的指针语法 int(*)M 对初学者来说也比较晦涩。"
(第四步:指出反模式,体现良好的工程素养)
"最后,关于 方法二 ,也就是 malloc 和 new 混合使用的方式。我会明确指出这是一种 应该被严格禁止的'反模式' 。"
- "在同一个数据结构上混用 malloc/free 和 new/delete 这两套不同的内存管理机制,会严重破坏C++的内存模型。 new 会调用构造函数, delete 会调用析构函数,而 malloc/free 完全不知道这些。混用会导致资源管理混乱,是未定义行为和内存泄漏的重灾区。在任何工程项目中,都应该避免这种写法。"
(第五步:总结陈词,给出清晰的选用场景)
"所以,我的最终结论是:
- 日常开发,99%的情况 :我会毫不犹豫地使用 std::vector<std::vector> ,因为它最安全、最清晰。
- 性能压榨场景 :当性能是首要矛盾,且列数固定时,我会考虑使用'数组指针'法来获得连续内存的性能优势。
- 遗留代码维护 :如果遇到'指针的指针'法,我会非常小心地处理它的内存释放。
- 坚决不用 :我绝不会使用 malloc 和 new 的混合体。"