在智能化应用爆发式增长的今天,构建高效的知识库与对话系统已成为企业提升服务效能的核心需求。本文将基于百度智能云向量数据库VectorDB与开源框架 FastGPT,详细演示从零搭建AI知识库及对话助手的全流程,实现外部知识的高效索引与精准问答,解决传统知识管理中的信息孤岛问题。接下来,我们将分四步完成系统搭建,分别是前期环境准备、千帆模型配置、知识库构建及对话应用部署。 一、前期准备 第一步:创建向量数据库实例 1、创建百度向量数据库实例,当前每个新用户都有免费试用实例的机会,抓紧申请吧,戳地址console.bce.baidu.com/vdb/#/vdb/i... 2、创建成功后,通过实例详情页查看访问的地址信息和账号信息,用于访问操作向量数据库。如例子截图,访问信息如下:
javascript
# 访问地址格式:http://${IP}:${PORT}
访问地址:http://192.168.20.4:5287
账号:root
密钥:xxxx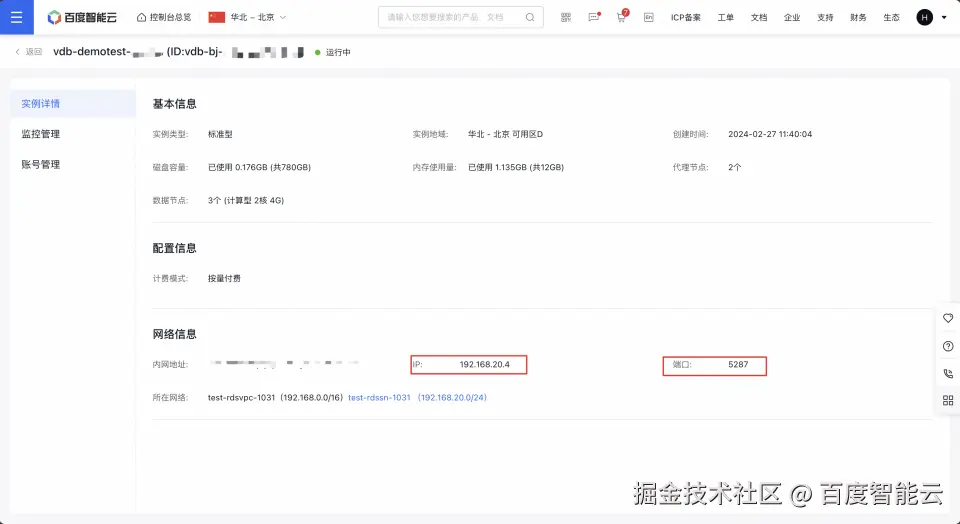
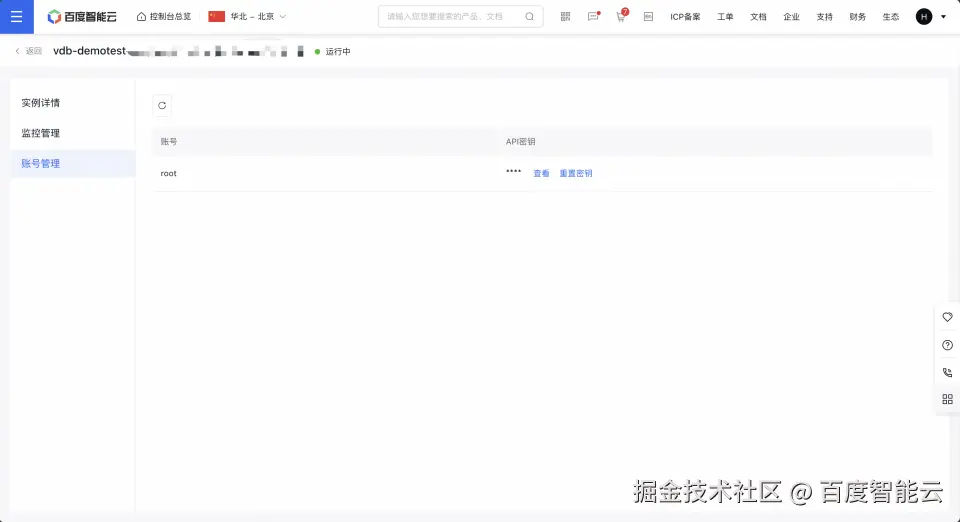
第二步:申请openai的api key 1、进入openai的api keys页面申请api key。platform.openai.com/settings/or... 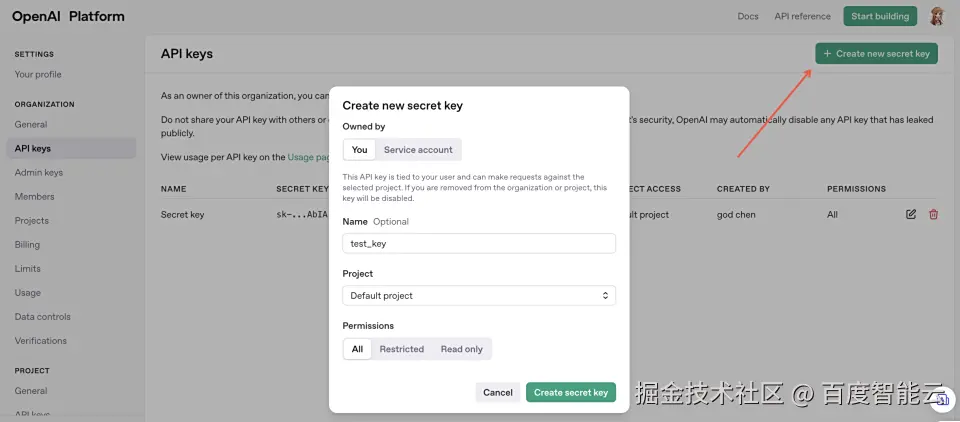
2、申请完之后需要保存api key,只显示这一次。使用前需要向openai缴费,否则无法使用 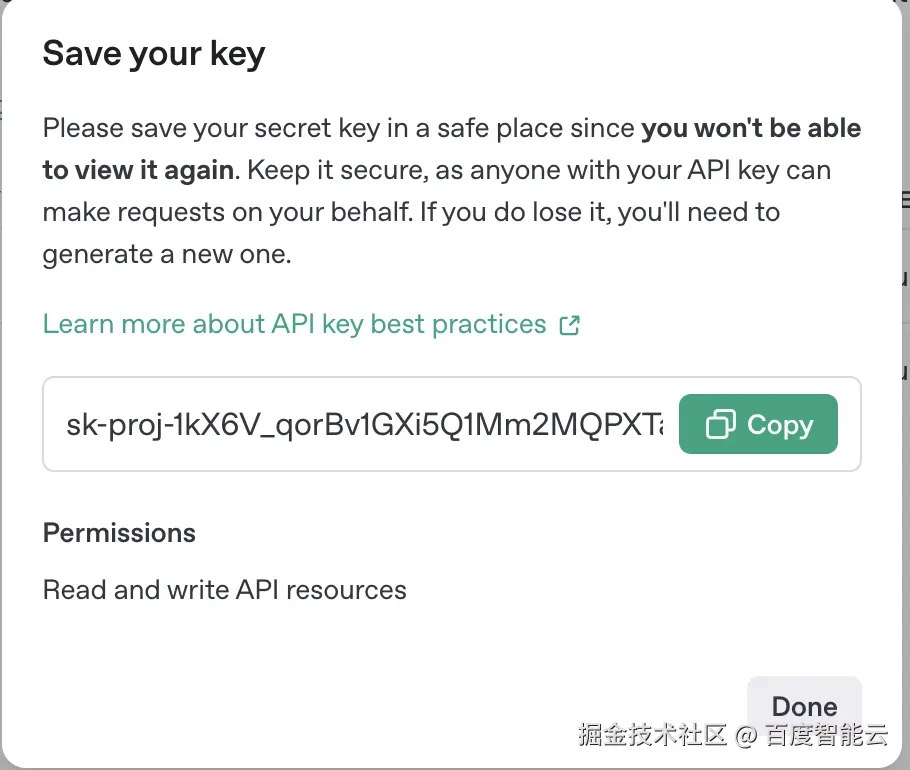
第三步:部署FastGPT 1、Fork FastGPT的github库 github.com/labring/Fas... GitHub 上 Fork 的存储库:git clone git@github.com:<github_username>/FastGPT.git 2、复制.env.template文件,在同级目录下生成一个.env.local 文件,修改.env.local 里内容才是有效的变量。 这里需要注意的是,变量说明见 .env.template,主要需要修改API_KEY和数据库的地址与端口以及数据库账号的用户名和密码,具体配置需要和docker配置文件相同,其中用户名和密码如需修改需要修改docker配置文件、数据库和.env.local文件,不能只改一处。 3、配置使用百度向量数据库 为了使用百度向量数据库,我们需要修改 Docker Compose 中api和worker的环境变量:
javascript
MOCHOW_ADDRESS=访问地址
MOCHOW_ACCOUNT=账号
MOCHOW_APIKEY=密钥
CHAT_API_KEY=openai获取到的密钥使用docker-compose -up -d启动环境,docker-compose.yml内容如下:
javascript
# 数据库的默认账号和密码仅首次运行时设置有效
# 如果修改了账号密码,记得改数据库和项目连接参数,别只改一处~
# 该配置文件只是给快速启动,测试使用。正式使用,记得务必修改账号密码,以及调整合适的知识库参数,共享内存等。
# 如何无法访问 dockerhub 和 git,可以用阿里云(阿里云没有arm包)
version: '3.3'
services:
# db
mongo:
image: mongo:5.0.18 # dockerhub
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mongo:5.0.18 # 阿里云
# image: mongo:4.4.29 # cpu不支持AVX时候使用
container_name: mongo
restart: always
ports:
- 27017:27017
networks:
- fastgpt
command: mongod --keyFile /data/mongodb.key --replSet rs0
environment:
- MONGO_INITDB_ROOT_USERNAME=myusername
- MONGO_INITDB_ROOT_PASSWORD=mypassword
volumes:
- ./mongo/data:/data/db
entrypoint:
- bash
- -c
- |
openssl rand -base64 128 > /data/mongodb.key
chmod 400 /data/mongodb.key
chown 999:999 /data/mongodb.key
echo 'const isInited = rs.status().ok === 1
if(!isInited){
rs.initiate({
_id: "rs0",
members: [
{ _id: 0, host: "mongo:27017" }
]
})
}' > /data/initReplicaSet.js
# 启动MongoDB服务
exec docker-entrypoint.sh "$$@" &
# 等待MongoDB服务启动
until mongo -u myusername -p mypassword --authenticationDatabase admin --eval "print('waited for connection')" > /dev/null 2>&1; do
echo "Waiting for MongoDB to start..."
sleep 2
done
# 执行初始化副本集的脚本
mongo -u myusername -p mypassword --authenticationDatabase admin /data/initReplicaSet.js
# 等待docker-entrypoint.sh脚本执行的MongoDB服务进程
wait $$!
# oneapi
mysql:
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mysql:8.0.36 # 阿里云
image: mysql:8.0.36
container_name: mysql
restart: always
ports:
- 3306:3306
networks:
- fastgpt
command: --default-authentication-plugin=mysql_native_password
environment:
# 默认root密码,仅首次运行有效
MYSQL_ROOT_PASSWORD: oneapimmysql
MYSQL_DATABASE: oneapi
volumes:
- ./mysql:/var/lib/mysql
oneapi:
container_name: oneapi
image: justsong/one-api:v0.6.10
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/one-api:v0.6.6 # 阿里云
ports:
- 3001:3000
depends_on:
- mysql
networks:
- fastgpt
restart: always
environment:
# mysql 连接参数
- SQL_DSN=root:oneapimmysql@tcp(mysql:3306)/oneapi
# 登录凭证加密密钥
- SESSION_SECRET=oneapikey
# 内存缓存
- MEMORY_CACHE_ENABLED=true
# 启动聚合更新,减少数据交互频率
- BATCH_UPDATE_ENABLED=true
# 聚合更新时长
- BATCH_UPDATE_INTERVAL=10
# 初始化的 root 密钥(建议部署完后更改,否则容易泄露)
- INITIAL_ROOT_TOKEN=fastgpt
volumes:
- ./oneapi:/data
networks:
fastgpt:修改完毕后,执行启动命令:
javascript
pnpm i
# 非 Make 运行
cd projects/app
pnpm dev
# Make 运行
make dev name=app4、部署成功后,在浏览器中输入 http://localhost:3000 即可访问 FastGPT。 5、进入FastGPT页面之后,默认账号位root,密码为1234 
第四步:开通千帆 Embedding 模型 千帆模型开通付费之后才能使用,开通不会产生费用,且有代金券赠送 1、开通千帆 Embedding 模型的收费 console.bce.baidu.com/qianfan/cha... 
2、创建应用,获取 API Key 和 Secret Key **console.bce.baidu.com/qianfan/ais...
javascript
$your_qianfan_ak = API Key
$your_qianfan_sk = Secret Key二、将千帆模型配置FastGPT 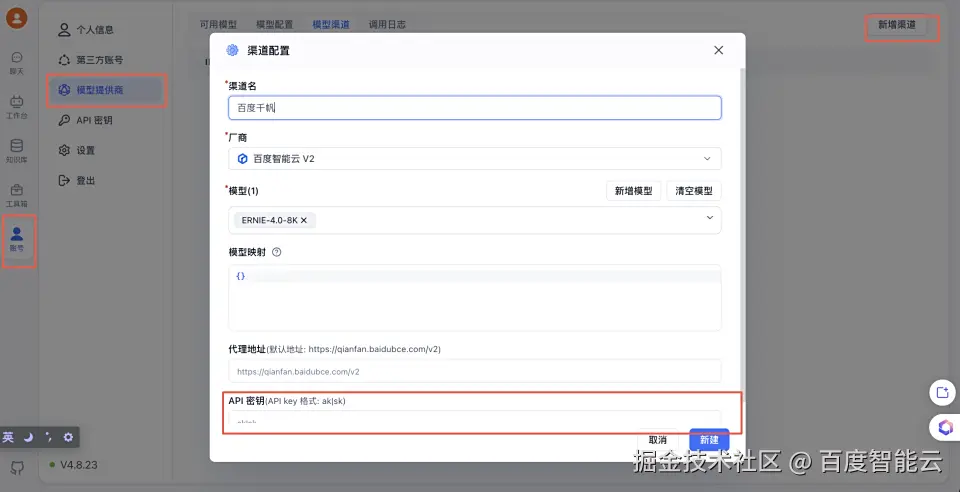
三、使用FastGPT创建知识库 1、创建知识库,选择对应的语言模型和索引模型 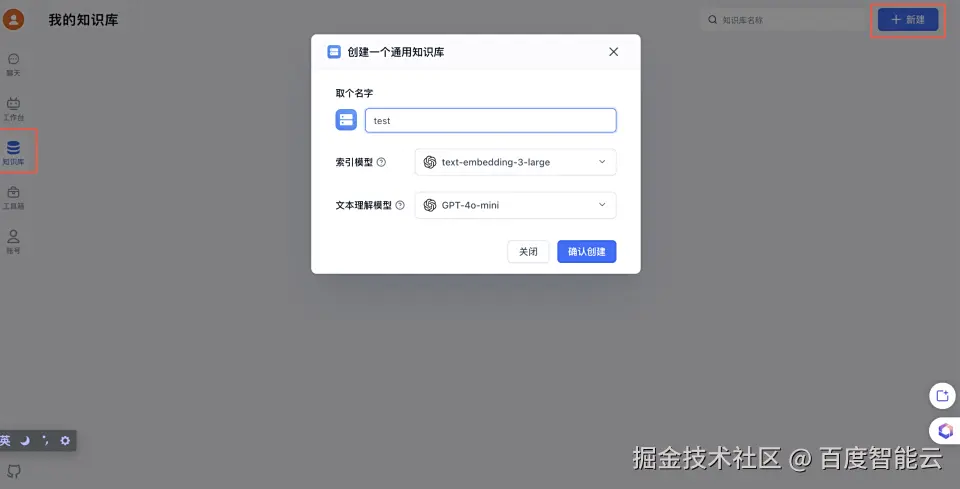
2、创建知识库并上传文档大致分为以下步骤:
- 导入文本数据
- 指定分段模式 以下就从这两个步骤介绍下如何快速从本地已有的pdf文档来创建知识库。
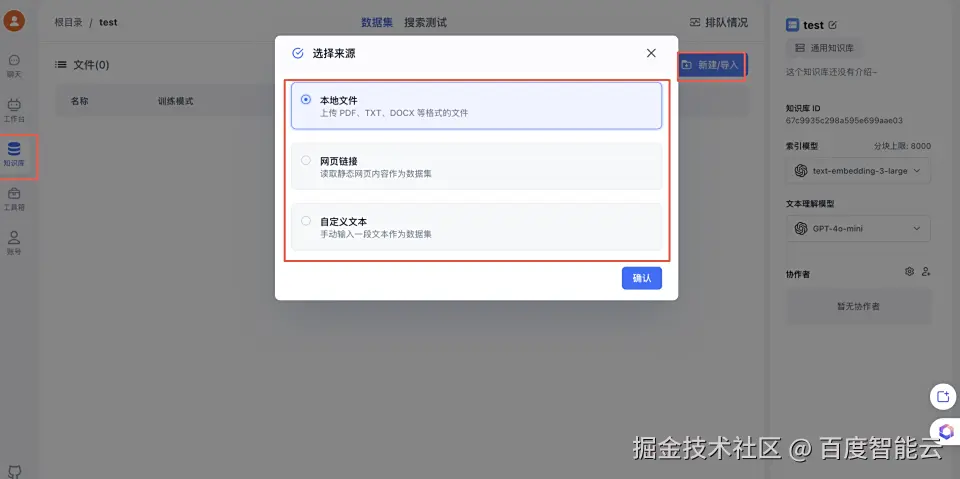
3、选择上传导入的pdf文档 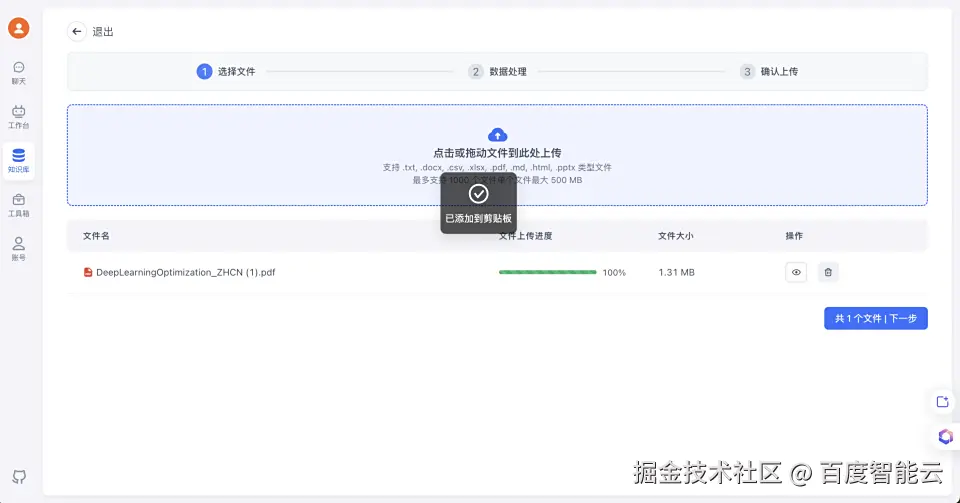
4、这里直接使用默认的分段配置 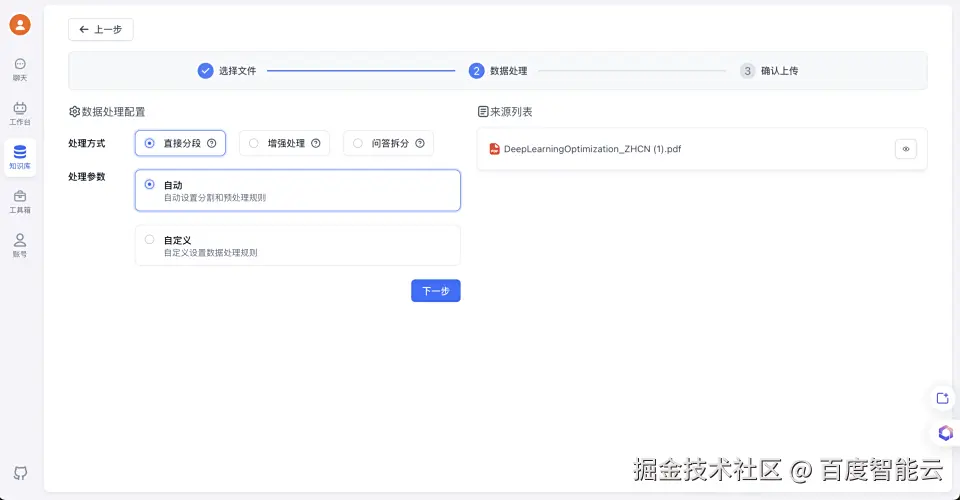
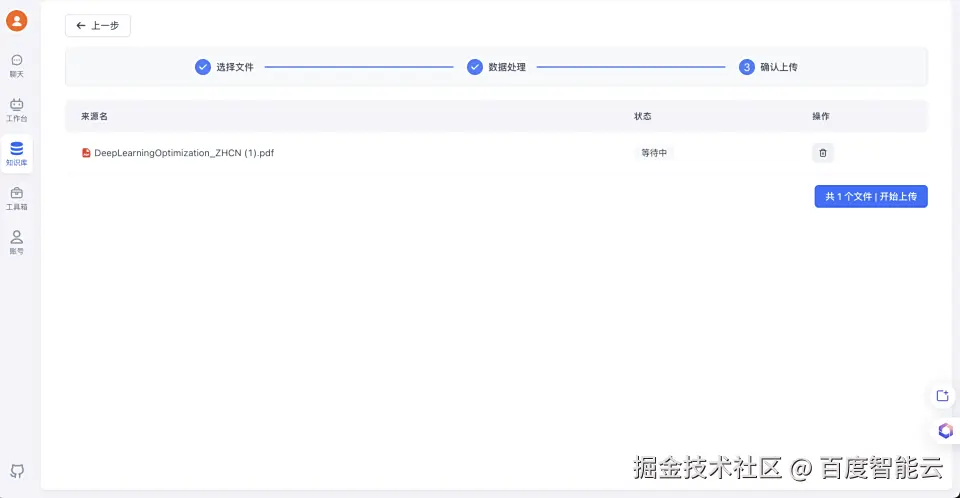
5、确认上传之后需要等待训练完成 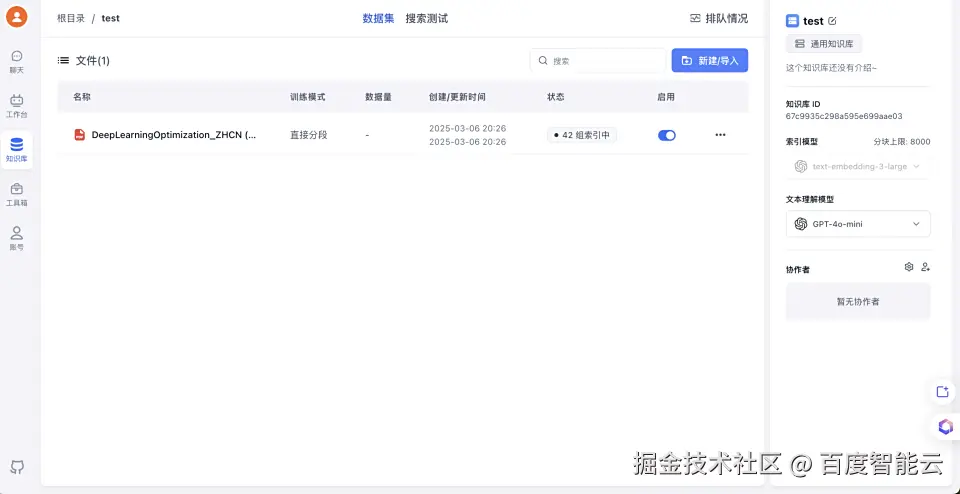
四、基于知识库创建应用 第一步:创建聊天助手 知识库可以作为外部知识提供给大语言模型用于精确回复用户问题,你可以在 FastGPT中关联已创建的知识库。这里也以聊天助手为例,来介绍如何运用上一章节中创建的知识库来快速搭建一个聊天助手应用。 FastGPT中,聊天助手应用的创建流程如下:
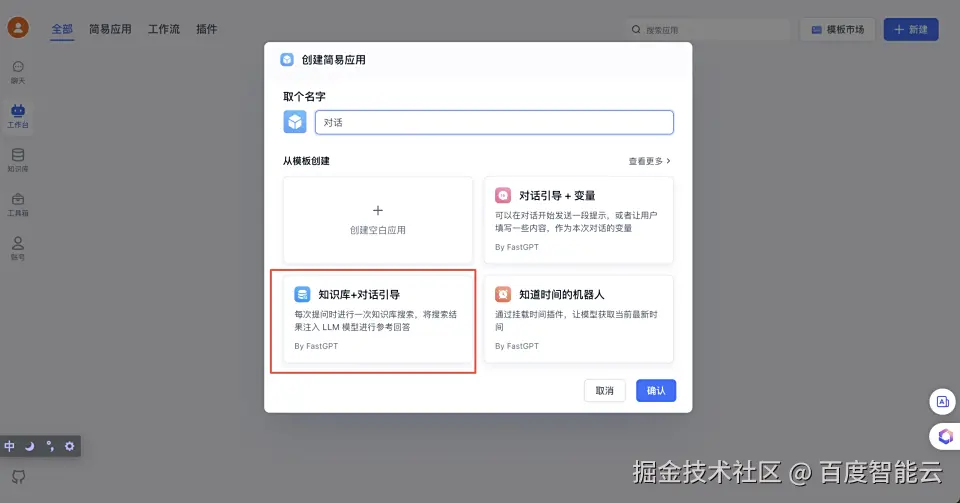
-
进入 工作台 -- 新建 --知识库+对话引导
-
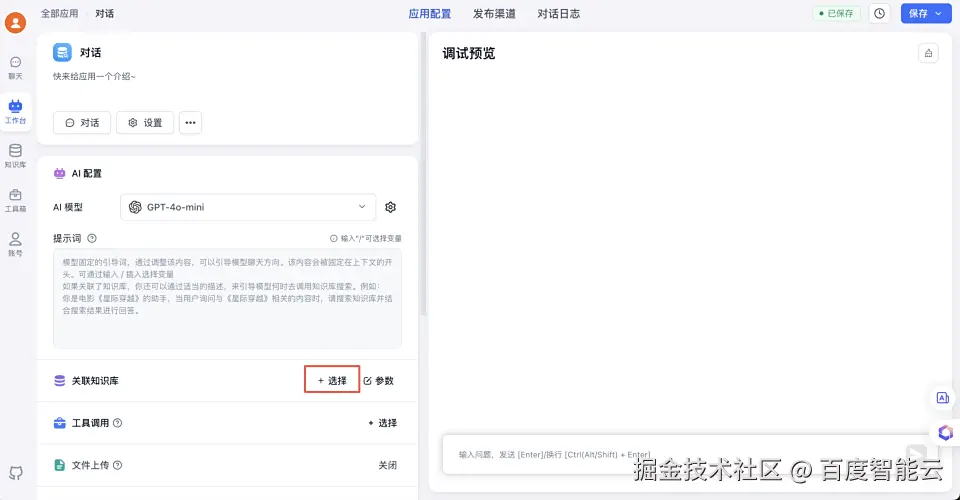
进入选择已创建的知识库,这里可以选择上文中创建的知识库;
-
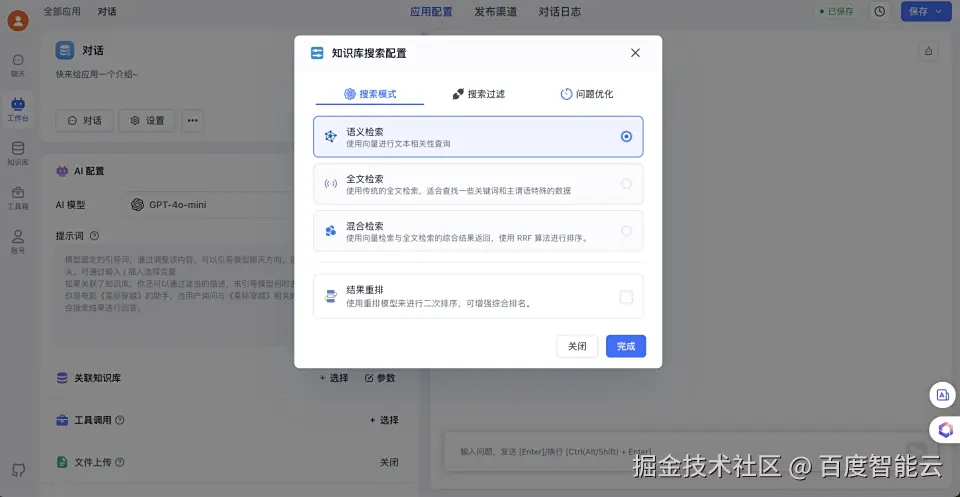
在参数中配置搜索过滤模式,可以直接使用默认的语义检索
-
在 AI模型相关属性中输入与知识库相关的用户问题进行调试,这里可以选择使用的模型种类并可以调试问答功能;
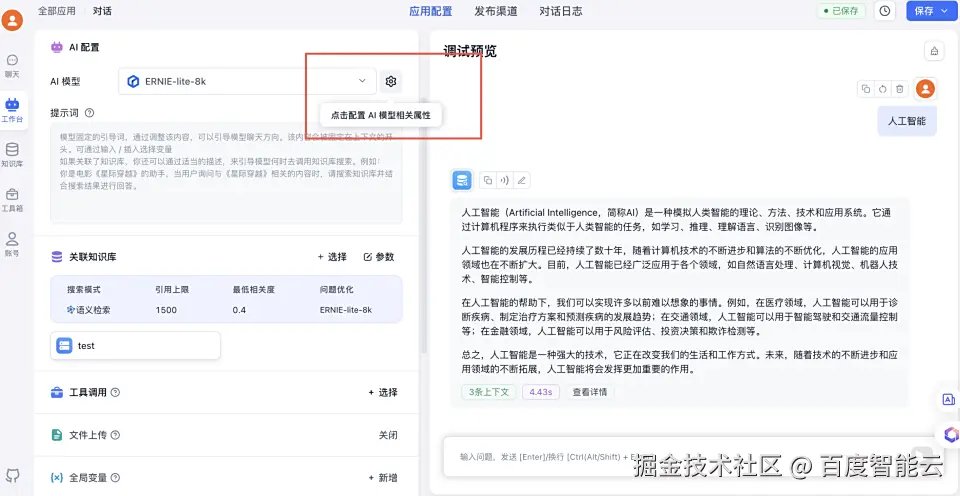
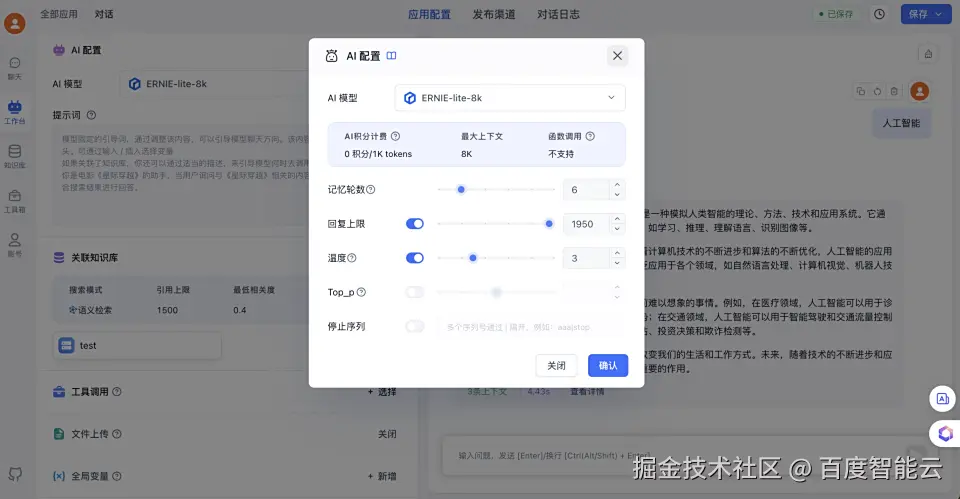
- 调试完成之后保存并发布为一个 AI 知识库问答类应用; 第二步:效果展示 完成应用创建后,就可以从工作室中进入创建好的聊天应用进行问答。
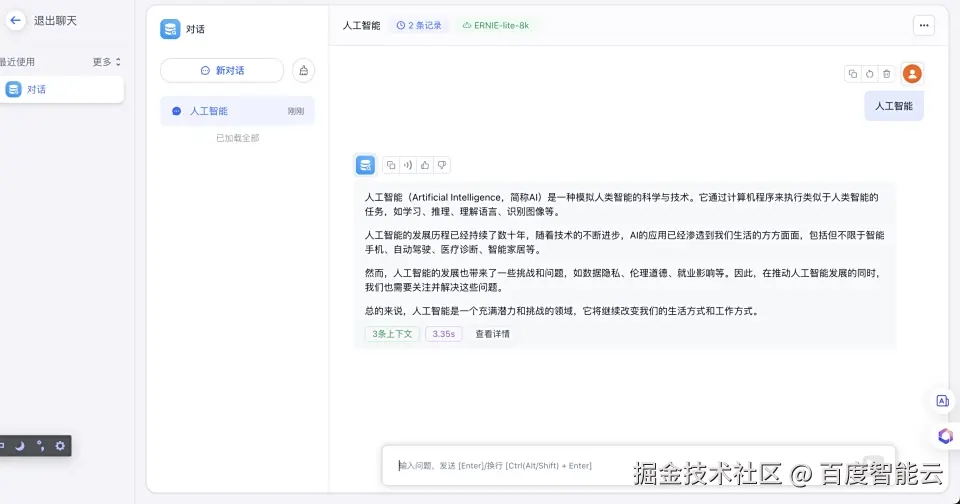
文章完整演示了基于VectorDB与FastGPT构建智能知识系统的全链路流程。从创建向量数据库实例、配置千帆Embedding模型,到知识库文档分段训练与AI应用发布,最终实现对话助手对专业知识的即时精准响应,成功打通了外部知识存储、语义索引与生成式问答的闭环,其模块化设计支持灵活扩展至客服、文档分析等场景。随着调试优化与知识库持续更新,这套轻量级架构将逐步演变为企业的智能信息枢纽,为业务决策提供强有力的认知支撑。