二叉树分解问题思路解题模式
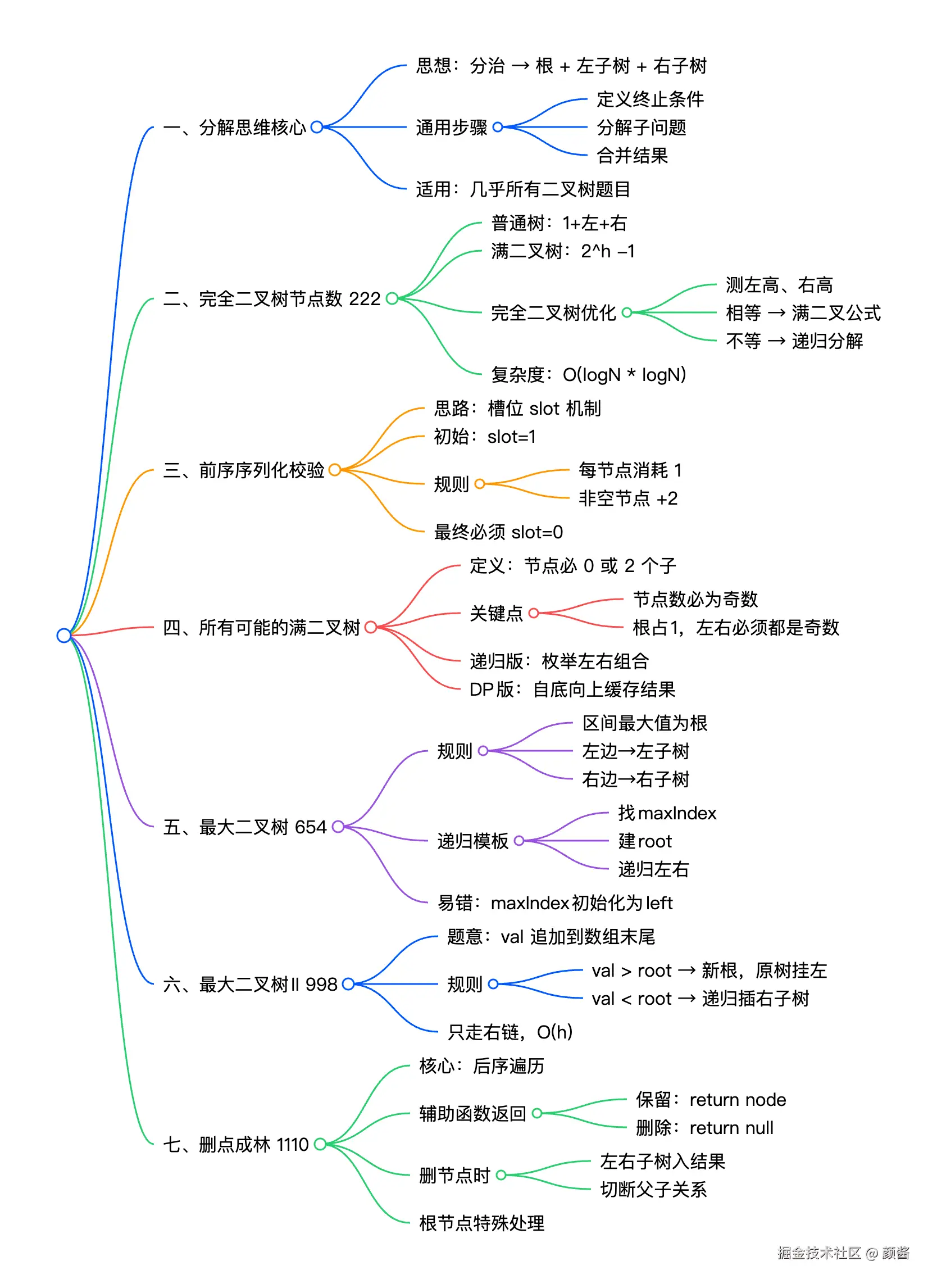
二叉树是算法面试的核心考点,而「分解问题」是解决二叉树类题目最通用、最高效的思维方式------将复杂的二叉树问题拆解为「根节点处理 + 左右子树递归求解」,再通过子问题的结果合并得到最终答案。本文将结合多个经典二叉树题目,详解分解思维的落地方法,覆盖普通二叉树、满二叉树、完全二叉树、最大二叉树等典型场景。
一、分解思维的核心逻辑
分解思维解决二叉树问题的通用框架:
-
终止条件:处理空节点等边界情况;
-
分解子问题:将当前问题拆分为「根节点处理」+「左子树问题」+「右子树问题」;
-
合并结果:用左右子树的求解结果,结合根节点的处理逻辑,得到当前问题的答案。
用公式总结:当前问题结果 = 根节点处理(左子树结果, 右子树结果)。
二、经典场景:分解思维的实战应用
1. 基础场景:二叉树节点数统计
节点数统计是分解思维最基础的应用,核心是「当前节点数 = 1(根) + 左子树节点数 + 右子树节点数」。
1.1 普通二叉树节点数
JavaScript
var countNodes = function (root) {
if (root === null) return 0;
return 1 + countNodes(root.left) + countNodes(root.right);
};思路解析:
-
终止条件:空节点节点数为0;
-
分解子问题:分别统计左、右子树节点数;
-
合并结果:根节点(1) + 左子树节点数 + 右子树节点数。
1.2 满二叉树节点数(优化版)
满二叉树的节点数与高度呈固定函数关系(2^h - 1),无需递归遍历:
JavaScript
var countNodes = function (root) {
var h = 0;
// 计算树的高度
while (root !== null) {
root = root.left;
h++;
}
// 节点总数就是 2^h - 1
return Math.pow(2, h) - 1;
};1.3 完全二叉树节点数(折中优化)
完全二叉树介于普通二叉树和满二叉树之间,利用「至少有一棵子树是满二叉树」的特性优化:
JavaScript
var countNodes = function (root) {
let l = root,
r = root;
// 沿最左侧和最右侧分别计算高度
let hl = 0,
hr = 0;
while (l !== null) {
l = l.left;
hl++;
}
while (r !== null) {
r = r.right;
hr++;
}
// 如果左右侧计算的高度相同,则是一棵满二叉树
if (hl === hr) {
return Math.pow(2, hl) - 1;
}
// 如果左右侧的高度不同,则按照普通二叉树的逻辑计算
return 1 + countNodes(root.left) + countNodes(root.right);
};复杂度分析:
时间复杂度 O(logN × logN)------每次递归仅需遍历一棵子树,另一棵子树通过公式直接计算,递归深度为 logN,每层遍历高度的时间也为 logN。
2. 进阶场景:生成所有满二叉树(真二叉树)
满二叉树要求每个节点要么0个孩子,要么2个孩子,核心是「根节点占1个,剩余节点拆分为左、右子树的奇数节点数」。
2.1 递归版
JavaScript
var allPossibleFBT = function (n) {
if (n % 2 === 0) return []; // 偶数直接返回空
if (n === 1) return [new TreeNode(0)]; // 1个节点返回数组(类型统一)
let res = [];
// 拆分逻辑:根占1个,剩余n-1个拆左i、右n-1-i(i步长2保证奇数)
for (let i = 1; i < n - 1; i += 2) {
let l = allPossibleFBT(i); // 左子树所有可能
let r = allPossibleFBT(n - 1 - i); // 右子树所有可能
// 笛卡尔积组合左右子树
for (let lItem of l) {
for (let rItem of r) {
const curRes = new TreeNode(0); // 每次新建节点,避免复用
curRes.left = lItem;
curRes.right = rItem;
res.push(curRes);
}
}
}
return res;
};2.2 动态规划优化版(自底向上)
JavaScript
/**
* 生成所有可能的满二叉树(动态规划迭代版)
* 题目要求:n个节点组成的满二叉树(每个节点要么0个孩子,要么2个孩子),返回所有根节点数组
* 核心思路:自底向上递推(动态规划),先计算小节点数的结果,再推导大节点数的结果
* @param {number} n 节点总数
* @returns {TreeNode[]} 所有满二叉树的根节点数组
*/
var allPossibleFBT = function (n) {
// 1. 初始化dp数组:dp[i] 表示i个节点能组成的所有满二叉树根节点数组
// 易错点1:dp数组长度要设为n+1,因为要访问dp[n],避免下标越界
const dp = new Array(n + 1);
// 2. 手动初始化已知结果(基础子问题)
dp[0] = []; // 0个节点:无任何树,返回空数组
// 易错点2:1个节点必须返回「包含单个节点的数组」,而非单个节点(保证类型统一)
dp[1] = [new TreeNode(0)];
// 3. 自底向上计算2~n的所有情况(动态规划核心:先算小问题,再算大问题)
for (let i = 2; i <= n; i++) {
// 3.1 满二叉树节点数必为奇数,偶数直接赋值为空数组
// 易错点3:偶数节点直接跳过后续计算,避免无效循环
if (i % 2 === 0) {
dp[i] = [];
continue;
}
// 存储当前i个节点能组成的所有满二叉树
const res = [];
// 3.2 拆分:根节点占1个,剩余i-1个拆分为左子树ln个、右子树rn=i-1-ln个
// 易错点4:ln步长必须为2(保证左子树节点数是奇数),否则dp[ln]为空数组,无法生成有效树
// 循环边界:ln <= i-2 → 保证右子树rn = i-1-ln ≥1(至少1个节点)
for (let ln = 1; ln <= i - 2; ln += 2) {
// 左子树的所有可能结构(已提前计算好,直接取缓存)
const leftTrees = dp[ln];
// 右子树节点数 = 总节点数 - 根节点 - 左子树节点数
const rn = i - 1 - ln;
// 右子树的所有可能结构(已提前计算好,直接取缓存)
const rightTrees = dp[rn];
// 3.3 笛卡尔积组合:左子树的每一种结构 搭配 右子树的每一种结构
// 易错点5:必须在双层循环内新建根节点,否则会复用同一个节点对象,导致所有结果引用相同的树
for (let left of leftTrees) {
for (let right of rightTrees) {
// 新建当前根节点(关键:每次组合都新建,避免引用复用)
const root = new TreeNode(0);
// 挂载左子树
root.left = left;
// 挂载右子树
root.right = right;
// 将当前组合的树加入结果集
res.push(root);
}
}
}
// 3.4 缓存当前i个节点的结果,供后续大节点数计算使用
dp[i] = res;
}
// 4. 返回n个节点的所有满二叉树
return dp[n];
};思路解析:
-
终止条件:偶数节点返回空,1个节点返回单节点数组;
-
分解子问题:将n拆分为「1(根) + 左子树节点数 + 右子树节点数」,且左右子树节点数均为奇数;
-
合并结果:笛卡尔积组合左右子树的所有可能,生成当前节点数的所有满二叉树。
3. 高频场景:最大二叉树的构建与扩展
3.1 构建最大二叉树
JavaScript
/**
* 构建最大二叉树(力扣654题)
* 规则:1. 数组最大值为根节点;2. 最大值左侧构建左子树;3. 最大值右侧构建右子树
* @param {number[]} nums 无重复整数数组
* @returns {TreeNode} 最大二叉树的根节点
*/
var constructMaximumBinaryTree = function (nums) {
// 边界条件:空数组直接返回null
if (nums.length === 0) return null;
// 初始调用:处理整个数组区间[0, nums.length-1]
return helper(nums, 0, nums.length - 1);
// 递归辅助函数:处理nums[left...right]区间,构建子树
function helper(nums, left, right) {
// 易错点1:终止条件是left > right(而非left>=right)
// left===right表示单节点区间,需要生成节点,不能返回null
if (left > right) return null;
// 步骤1:找到[left, right]区间内最大值的索引
let maxIndex = left; // 易错点2:初始化为left,而非0!
for (let i = left; i <= right; i++) {
if (nums[i] > nums[maxIndex]) {
maxIndex = i;
}
}
// 步骤2:以最大值为当前根节点(包括单节点区间的情况)
const root = new TreeNode(nums[maxIndex]);
// 步骤3:递归构建左子树(最大值左侧区间)
// 优化点:无需额外判断maxIndex===left,因为当maxIndex=left时,left>maxIndex-1,递归会返回null
root.left = helper(nums, left, maxIndex - 1);
// 步骤4:递归构建右子树(最大值右侧区间)
// 同理:无需额外判断maxIndex===right,递归终止条件会处理
root.right = helper(nums, maxIndex + 1, right);
return root;
}
};思路解析:
-
终止条件:数组区间无效(left > right)返回null;
-
分解子问题:找到区间最大值作为根,将数组拆分为「最大值左侧」和「最大值右侧」;
-
合并结果:递归构建左右子树,挂载到根节点上。
3.2 最大二叉树II(插入节点)
JavaScript
/**
* 插入节点到最大二叉树中(力扣998题)
* 题目规则:
* 1. 原树是由数组nums构建的最大二叉树;
* 2. 将val追加到nums末尾,构建新的最大二叉树,要求直接在原树上修改(递归方式);
* 核心逻辑:
* - val比根节点大 → 成为新根,原根作为新根的左子树(因为val是追加到数组末尾,原数组是新根的左子数组);
* - val比根节点小 → 递归插入到根节点的右子树(因为val在数组末尾,属于根节点的右子数组);
* @param {TreeNode} root 原最大二叉树的根节点
* @param {number} val 要插入的值
* @returns {TreeNode} 插入后的最大二叉树根节点
*/
var insertIntoMaxTree = function (root, val) {
// 终止条件1:原树为空,直接返回以val为值的新节点
if (root === null) return new TreeNode(val);
const rootVal = root.val;
// 核心条件1:val大于当前根节点值 → 成为新根
if (val > rootVal) {
const newRoot = new TreeNode(val);
// 易错点:新根的左子树是原根(而非右子树)!
// 原因:val是追加到数组末尾,原数组是新根的左子数组,对应左子树
newRoot.left = root;
return newRoot;
}
// 核心条件2:val小于当前根节点值 → 递归插入到右子树
// 原因:val在数组末尾,属于当前根节点的右子数组,只能出现在右子树中
root.right = insertIntoMaxTree(root.right, val);
// 插入完成后,返回当前根节点(未被替换)
return root;
};思路解析:
-
终止条件:空树直接返回新节点;
-
分解子问题:val大于根则成为新根,否则递归插入到右子树;
-
合并结果:挂载原根到新根的左子树,或返回更新后的原根。
4. 复杂场景:删点成林
JavaScript
/**
* 力扣 1110. 删点成林
* 功能:删除二叉树中指定值的节点,返回删除后所有独立子树(林)的根节点数组
* 核心思路:后序遍历 + Set快速判删 + 切断父子关系 + 收集新根节点
* @param {TreeNode} root 原始二叉树的根节点
* @param {number[]} to_delete 需要删除的节点值数组
* @returns {TreeNode[]} 删点后所有独立子树的根节点数组
*/
var delNodes = function (root, to_delete) {
// 1. 将待删除节点值存入Set,实现O(1)时间复杂度的存在性判断
// (二叉树节点值唯一,无需去重)
const deleteSet = new Set(to_delete);
// 2. 结果数组:存储最终"林"中的所有子树根节点
const forest = [];
// 6. 特殊处理根节点:根节点无父节点,需单独判断
// 调用processNode处理整棵树,获取处理后的根节点
const processedRoot = processNode(root);
// 若处理后的根节点非空(根节点保留)→ 根是林的一员,加入结果
if (processedRoot !== null) {
forest.push(processedRoot);
}
// 7. 返回最终的"林"
return forest;
/**
* 递归辅助函数:后序遍历处理单个节点,返回处理后的节点(控制父子关系)
* 入参:当前要处理的节点(可能为null)
* 出参:
* - TreeNode:当前节点保留,返回自身(父节点继续挂载该节点)
* - null:当前节点删除,返回null(父节点切断与该节点的关系)
* @param {TreeNode|null} node 当前处理的节点
* @returns {TreeNode|null} 处理后的节点(保留/删除)
*/
function processNode(node) {
// 终止条件:空节点直接返回null(无节点可处理)
if (node === null) return null;
// 3. 后序遍历核心:先处理左右子树,再处理当前节点
// (先搞定孩子,才能决定当前节点的去留,以及是否收集孩子为新根)
// 递归处理左子树,并用返回值更新当前节点的左指针:
// - 若左孩子删除,左指针置为null(切断关系)
// - 若左孩子保留,左指针仍指向原左孩子(更新后的值)
node.left = processNode(node.left);
// 同理,递归处理右子树,更新当前节点的右指针
node.right = processNode(node.right);
// 4. 处理当前节点:判断是否需要删除
if (deleteSet.has(node.val)) {
// 4.1 若当前节点删除:其左右子树(非空)成为新的独立子树,加入结果
// 左子树非空 → 左子树是新根,加入林
if (node.left !== null) {
forest.push(node.left);
}
// 右子树非空 → 右子树是新根,加入林
if (node.right !== null) {
forest.push(node.right);
}
// 4.2 返回null:告诉父节点"我要删除,你把指向我的指针置空"
return null;
}
// 5. 若当前节点保留:返回自身,父节点继续挂载该节点
return node;
}
};思路解析:
-
终止条件:空节点返回null;
-
分解子问题:后序遍历处理左右子树,更新父子关系;
-
合并结果:删除节点时收集其左右子树为新根,保留节点时返回自身维持父子关系。
三、分解思维的核心技巧
-
后序遍历优先:处理需要依赖左右子树结果的问题(如删点成林、节点数统计),优先用后序遍历,保证先处理子树再处理根;
-
利用树的特性优化:满二叉树、完全二叉树等特殊结构,可通过公式或特性减少递归/遍历次数;
-
边界条件精准:终止条件需区分「空节点」「单节点」「无效区间」等场景,避免漏节点或空指针;
-
缓存子问题结果:如满二叉树的动态规划版,缓存小节点数的结果,避免重复计算。
四、总结
二叉树的分解思维本质是「分治」------将大问题拆分为可独立解决的子问题,再合并结果。掌握这一思维后,无论是基础的节点统计,还是复杂的删点成林、构建最大二叉树,都能按「终止条件 → 分解子问题 → 合并结果」的步骤拆解,化繁为简。
核心口诀:先定终止边界,再拆左右子树,最后合并结果。吃透这一逻辑,二叉树类题目就能迎刃而解。