「【新智元导读】英伟达发布全新架构 9B 模型,以 Mamba-Transformer 混合架构实现推理吞吐量最高提升 6 倍,对标 Qwen3-8B 并在数学、代码、推理与长上下文任务中表现持平或更优。」
万万没想到,现在还紧跟我们的开源模型竟然是英伟达。
刚刚,英伟达发布了一个只有 9B 大小的 「NVIDIA Nemotron Nano 2 模型。」
对标的是业界标杆,千问的 Qwen3-8B,但这个模型是一个完全不同的混合架构。
用英伟达的说法,这是一款革命性的 「Mamba-Transformer」 混合架构语言模型。
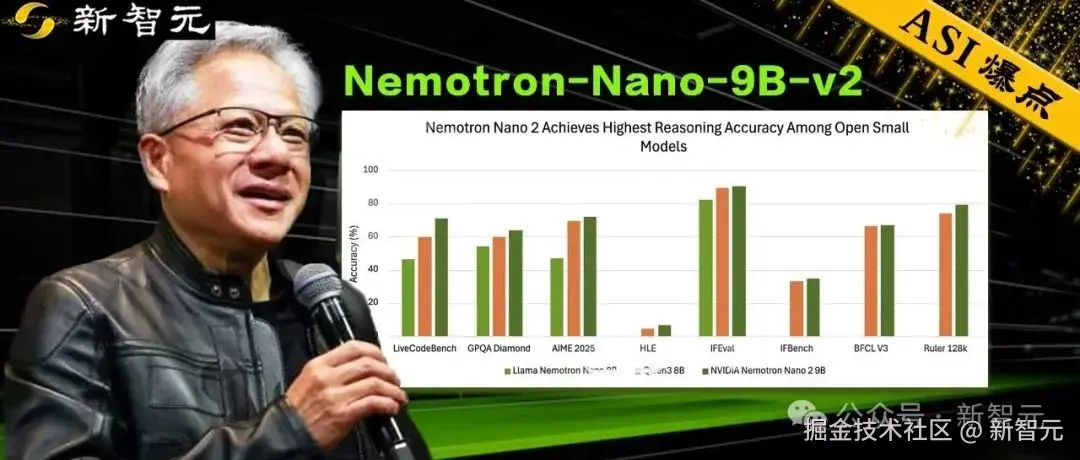
在复杂推理基准测试中实现了和 Qwen3-8B 相当或更优的准确率,并且吞吐量最高可达其 「6 倍。」
它的诞生只有一个目标:「在复杂的推理任务中,实现无与伦比的 「「吞吐量」 」,同时保持同级别模型中顶尖的精度!」
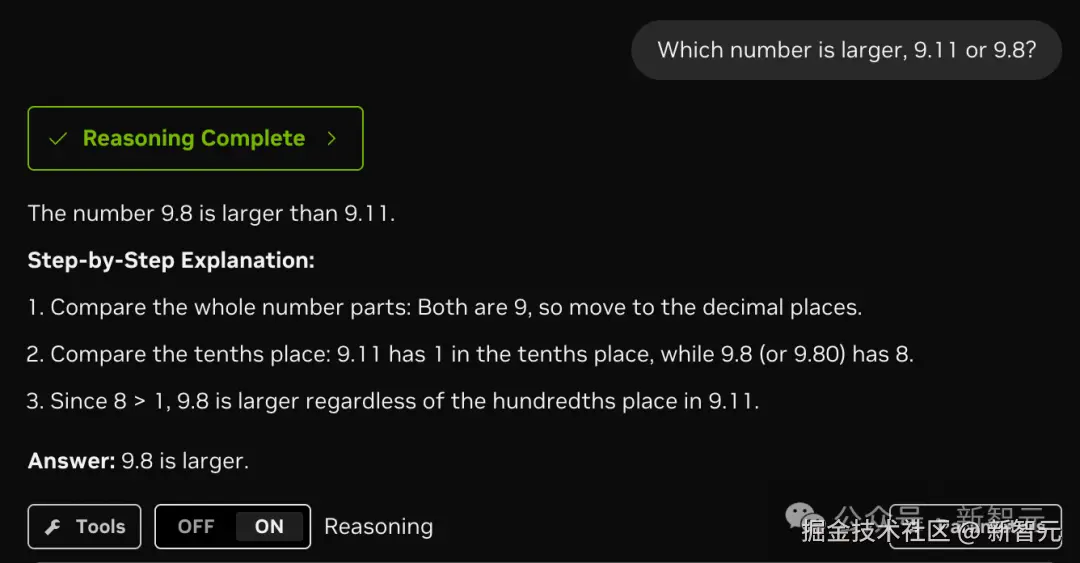
在官网简单测试一下,一些经典问题,都能答对。
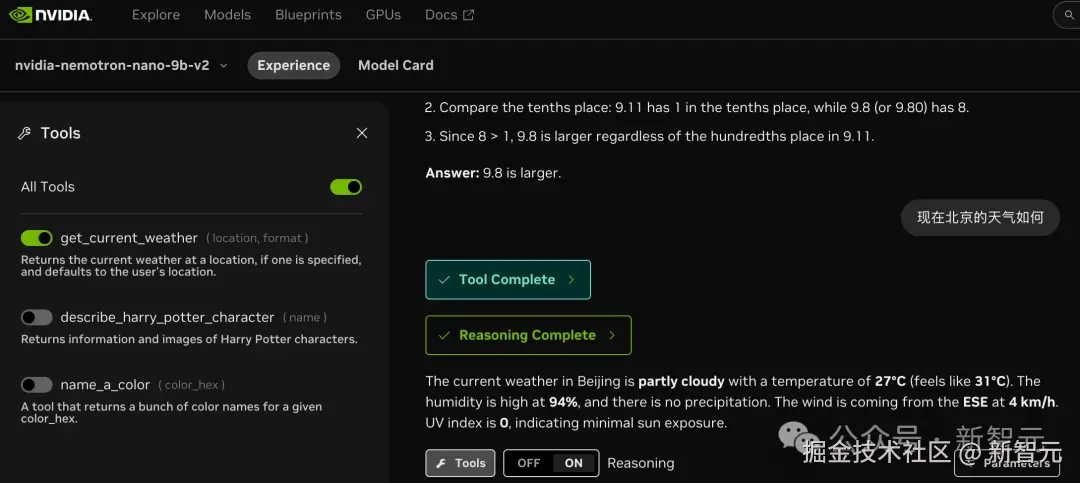
英伟达还做了 3 个小工具,可以实时查天气、描述哈利波特里的角色和帮你想颜色。
不过 9B 模型还是小了点,当你问「SamAltman、马斯克和黄仁勋谁更值得信任」时,模型会犯蠢把马斯克翻译成麻克,哈哈哈。
而且,也不愧是亲儿子,模型认为黄仁勋最值得信任。



「速度的奥秘」
「Mamba-2 架构加持!」
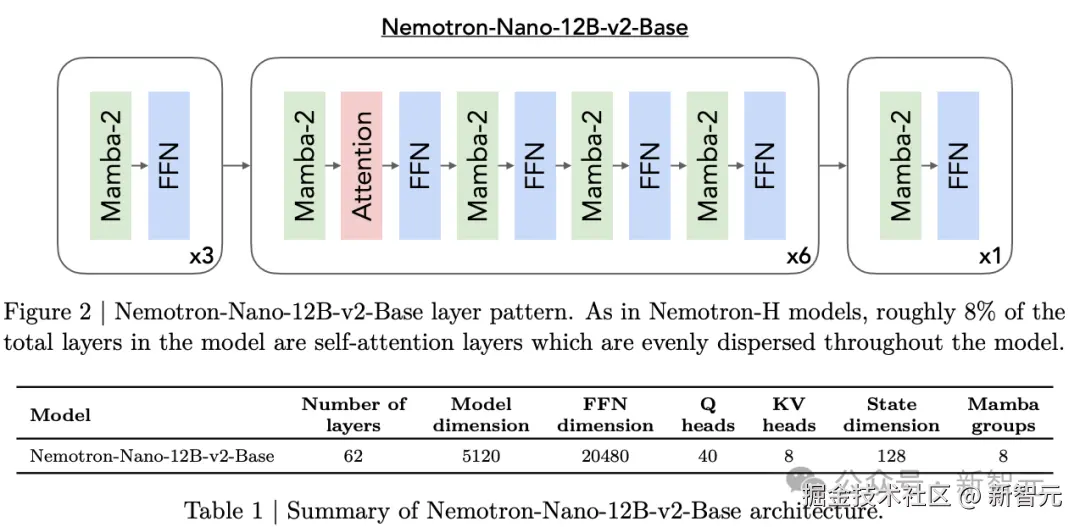
Nemotron-Nano-9B-v2 的强大,源于其创新的 「Nemotron-H」 架构。
用闪电般快速的 「Mamba-2」 层,替换了传统 「Transformer」 架构中绝大多数的自注意力层。
当模型需要进行长篇大论的思考、生成复杂的长思维链时,它的推理速度得到了史诗级的提升!
「 」
」
「简单介绍下 Mamba 架构」
我们都知道 Transformer 架构,但是这么年过去,有没有新架构出现?
有的。
比如 Meta 公开推进 JEPA(联合嵌入预测架构)和大概念模型(LCMs)、状态空间模型(就是 Mamba)、记忆模型或扩散语言模型等。

谷歌 DeepMind 在 Titans、Atlas、Genie3 以及 diffusion-based 模型等方向投入了约 50% 研究力量。
OpenAI 虽然嘴上说着有信心训练到 GPT-8,但很可能也在储备新架构。
而根据 Reddit 社区的讨论,Ilya 的 SSI 最可能就是用全新的架构,但是什么,还没人知道。
Mamba 是一种完全无注意力机制的序列建模架构,基于结构化状态空间模型(SSMs)。
通过「选择性机制」根据当前输入动态调整参数,从而专注于保留相关信息并忽略无关信息。
在处理超长序列时,Mamba 的推理速度据称可比 Transformer 快 3--5 倍,且其复杂度为线性级别,支持极长的上下文(甚至达到百万级 token)。
「」
「为什么要混合 Mamba 与 Transformer?」
Transformer 虽然效果出众,但在处理长序列时存在显著的计算和内存瓶颈(自注意力机制导致的 O(n^2) 规模)。
而 Mamba 擅长在长上下文中高效建模,但在「记忆复制(copying)」或「上下文学习(in‑contextlearning)」等任务上可能稍显不足。
「从 120 亿到 90 亿的极限淬炼」
NemotronNanov2 的训练按照下面几个步骤:
「· 「暴力」预训练」
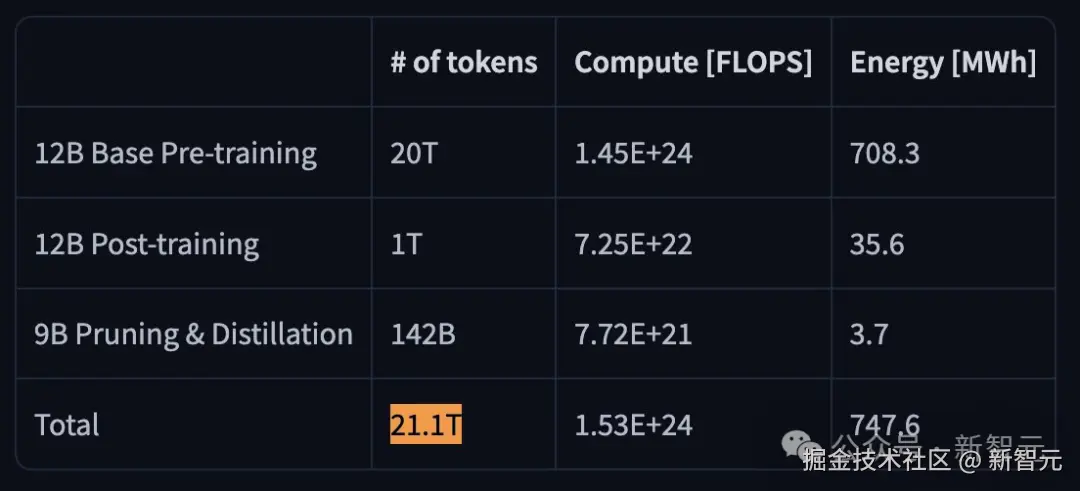
首先在一个拥有 「20 万亿 Token」 的海量数据集上,利用先进的 「FP8」 训练方案,锻造出一个 120 亿参数基础模型------「Nemotron-Nano-12B-v2-Base」。
这听着就非常像 DeepSeek-R1:DeepSeek‑R1-Zero 是直接基于 DeepSeek‑V3-Base 进行纯强化学习训练的初始模型。
而 DeepSeek‑R1 则在此基础上加入了监督微调作为冷启动,再用强化学习精炼,从而获得更好的可读性与性能。
**「Nemotron-Nano-12B-v2-Base 的」**预训练,涵盖高质量网页、多语言、数学、代码、学术等数据,重点构建了高保真的数学和代码数据集。
「· 极限压缩与蒸馏」
结合 「SFT、DPO、GRPO、RLHF」 等多阶段对齐方法,提升了推理、对话、工具调用与安全性。
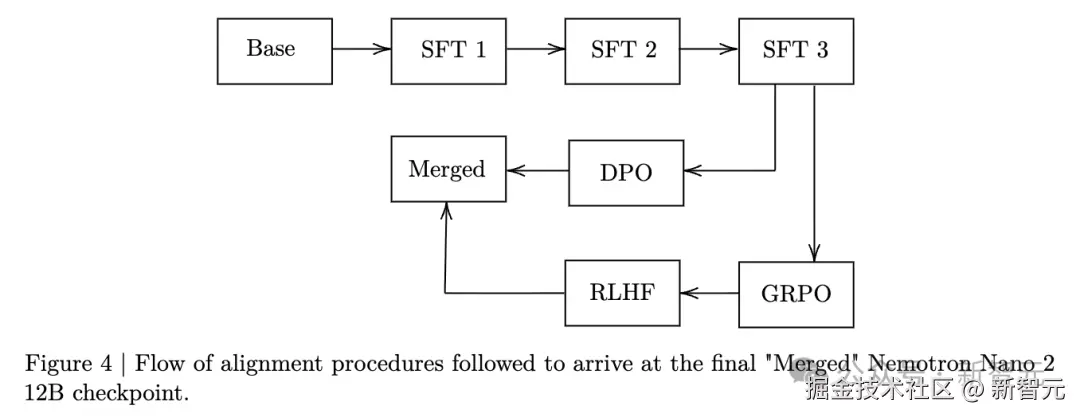
完成对齐后,祭出 「Minitron」 策略,对这个 120B 参数的模型进行极限压缩与蒸馏。
Minitron 策略是一种由 NVIDIA 提出的**「模型压缩方法」**,主要通过结构化剪枝(pruning)与知识蒸馏(distillation)来实现对大型语言模型的高效压缩与性能保持。
「· 最终目标」
通过 「Minitron 剪枝与蒸馏」,将 12B 基础模型压缩为 9B 参数,确保单张 A10GGPU(22GiB)即可支持 128k 上下文。
「性能碾压,精度与速度全都要!」
是骡子是马,拉出来遛遛!
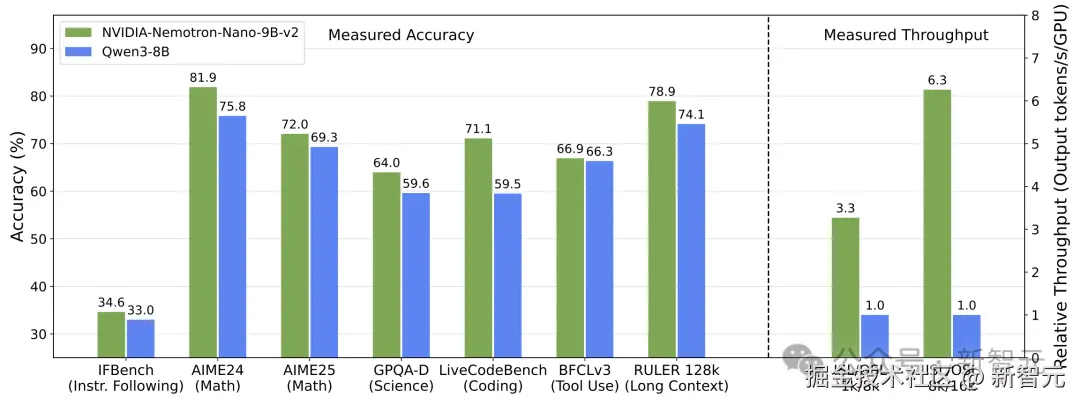
与 「Qwen3-8B」 等同级别强手相比,「Nemotron-Nano-9B-v2」 在各大推理基准测试中,精度平起平坐,甚至更胜一筹!
在数学(GSM8K、MATH)、代码(HumanEval+、MBPP+)、通用推理(MMLU-Pro)、长上下文(RULER128k)等基准测试中表现优于或持平同类开源模型(如 Qwen3-8B、Gemma3-12B).
并在 8k 输入 / 16k 输出场景下实现 「6.3×」 「吞吐量****提升」。

「」
「全面开源」
英伟达宣布在 「HuggingFace」 平台上,**「全面开放」**以下资源:
正在 HuggingFace 上发布以下三个模型,它们均支持 128K 的上下文长度:
- 「NVIDIA-Nemotron-Nano-9B-v2」:对齐并剪枝的推理模型
- 「NVIDIA-Nemotron-Nano-9B-v2-Base」:一个经过剪枝的基础模型
- 「NVIDIA-Nemotron-Nano-12B-v2-Base」:对齐或剪枝之前的基模型
除了模型,英伟达表示我们的数据集也很强,并开源了用于预训练的大部分数据。
「Nemotron-Pre-Training-Dataset-v1」 数据集集合包含 「6.6」 万亿个高质量网页爬取、数学、代码、SFT 和多语言问答数据的 token,该数据集被组织为四个类别:
- 「Nemotron-CC-v2: 「Nemotron-CC(Su 等,2025)的后续版本,新增了」八组 CommonCrawl 快照(2024--2025)」。该数据经过全局去重,并使用 Qwen3-30B-A3B 进行了合成改写。此外,它还包含**「以 15 种语言翻译的合成多样化问答对」**,支持强大的多语言推理和通用知识预训练。
- **Nemotron-CC-Math-v1:**一个专注于数学的 「1330 亿 Tokens 数据集」 ,源自 NVIDIA 的 「Lynx+LLM」 **「流水线」**对 CommonCrawl 的处理结果,该方法在将数学内容标准化为 LaTeX 的同时保留了公式和代码格式。这确保了关键的数学内容和代码片段保持完整,从而生成出在基准测试中优于以往数学数据集的高质量预训练数据。
- 「Nemotron-Pretraining-Code-v1: 「一个大规模的精选代码数据集,来源为 GitHub,经过」多阶段去重、许可证执行和 「「启发式」 」**质量检查」**筛选。该数据集还包含 「11 种编程语言的 LLM 生成代码问答对」。
- **Nemotron-Pretraining-SFT-v1:**一个合成生成的数据集,涵盖 「STEM(科学、技术、工程和数学)、学术、推理及多语言领域」。其中包括从高质量的数学和科学原始数据中生成的复杂选择题和分析型问题、研究生水平的学术文本,以及涵盖数学、编程、通用问答和推理任务的指令调优 SFT 数据。
- **Nemotron-Pretraining-Dataset-sample:**数据集的一个小规模采样版本提供了 「10 个具有代表性的子集」,展示了高质量的问答数据、面向数学的抽取内容、代码元数据以及 SFT 风格的指令数据。
最后是感慨下,Meta 作为一开始的开源旗帜,现在也逐渐开始转向闭源,或者起码是在 Llama 上的策略已经被调整。
目前真正在开源领域努力还是以国内的模型为主,虽然 OpenAI 前不久也开源了两个,不过雷声大雨点小。
英伟达虽然一直卖铲子,但也静悄悄的发布了不少开源。
感兴趣可以在如下网址体验,除了英伟达自家的,很多开源模型都能找到。
模型体验网址:
build.nvidia.com/nvidia/nvid...
参考资料: