起心动念
上周开发完 sheetex 后,发了条朋友圈。有小伙伴建议搞个 MCP 玩,正好我本来也想学,于是这周就花了一天完成了 sheetex-mcp-server,一个将对话中生成的表格保存成 Excel 的 MCP 服务。
做之前快速调查了一下 smithery 和 modelscope ,发现已经有好几个 Excel 相关的:实现上既有调用本机上的 Office 软件进行操作的,也有用库读写文件的;功能就更加眼花缭乱,从简单读写数据,到插入图表,甚至可以截图保存。
看来是打不过了,好在只是做个练习,开搞。
一天下来,学到不少东西,也填了好几个坑,本文以坑为主。
那么下面就按顺序来了。
新手上路
Build an MCP Server 是官方的教程,新手入门刚刚好,它通过调用天气相关的接口演示了 MCP Server 的开发过程。
第1个知识点:MCP有两个模式,基于 stdio 或 http,基于 stdio 时不能使用 console.log 等向标准输出输出内容的方法,会扰乱 JSON-RPC 消息
紧接着,第1个坑:
文档中用下面这段代码引导读者创建项目目录、初始化、安装依赖
html
# Create a new directory for our project
mkdir weather
cd weather
# Initialize a new npm project
npm init -y
# Install dependencies
npm install @modelcontextprotocol/sdk zod
npm install -D @types/node typescript
# Create our files
mkdir src
touch src/index.ts问题出在第9行,安装时没有指定版本,目前运行这行命令,安装的 zod 是最新版本4.x.x,写文档时应该还是 3.x.x,两者存在兼容问题,最终表现就是接入 MCP 客户端后,客户端无法识别工具需要的参数,以这个项目为例,正常情况下,参数长这个样子
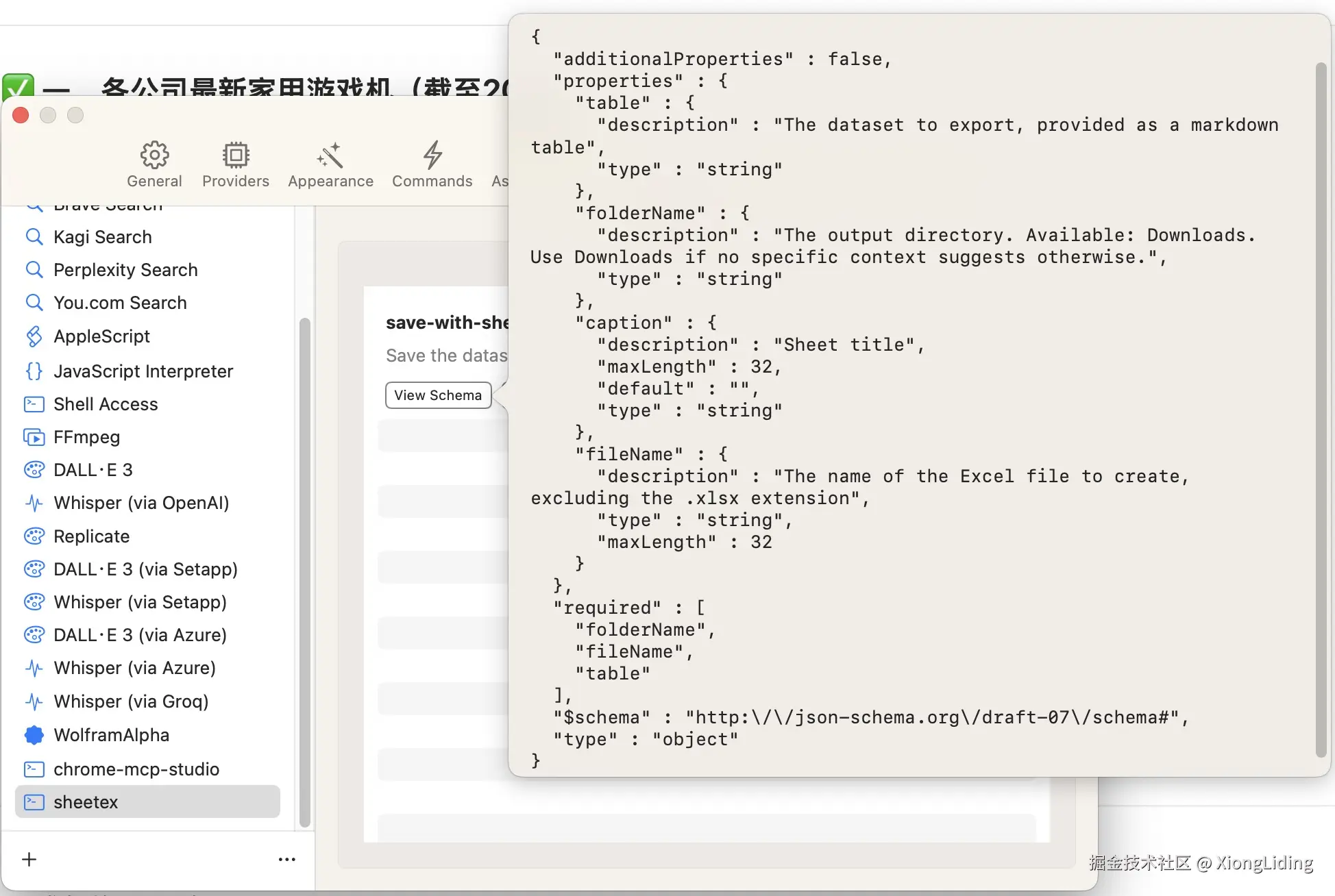
误装 zod@4.x.x 后,properties 是空的,required 也没了,这样模型就不知道该传什么参数,导致完全无法使用。
实际开发中,很可能把功能写完了,要测试才发现问题,很容易怀疑是不是自己代码写错了,比如参数定义是不是出了问题。第1个提示:建议第一次尝试的开发者,先写一个最基础的工具进行测试 ,类似输入参数只有 name,输出则是 hello, ${name} 这样的,确保环境以及基本的语法没有问题。
剩下的就比较简单,只要按照文档中的指引操作,并把其中天气相关的逻辑,改成导出 Excel 就好了。
模型能力
接下来是第2个坑:模型规模导致能力有限,无法很好的调用工具
第一个测试能跑通后,我换着模型进行了测试,看看会不会由于模型的能力导致调用发生意外。刚开始,我的接口参数是这样定义的(部分描述进行了简化)。
javascript
{
folderName: z.string().describe(`The output directory.`),
fileName: z.string().max(32).describe('The name of the Excel file to create, excluding the .xlsx extension'),
caption: z.string().max(32).optional().default('').describe('Sheet title'),
headers: z.array(z.string()).describe('Column headers for the sheet'),
data: z.array(
z.array(
z.string().or(z.number()).describe('Each value can be a string or a number.')
).describe('Each inner array represents one row of the sheet.')
).describe('The full dataset to export, provided as a two-dimensional array.'),
}其中最复杂的是 data 这参数,用 TypeScript 来描述是 (string | number)[][] ,就是让大模型用二维数组来表达单元格中的数据。
我一开始担心的是小规模模型无法正确理解和组织复杂的参数,结果证明这并不是问题,本地跑 Qwen3:7B 也能很正确的理解并输出这个结构,并且在大多数时候还能正确的区分文本和数字,比如让它模拟一份成绩单,他会用文本表示姓名,用数字表示成绩,大概就是这样:
javascript
{
"caption":"学生成绩单",
"data":[
["张三",85,90,88,82,95,80,78,85,92,700],
["李四",78,85,92,88,80,95,82,85,78,800],
["王五",92,88,76,90,85,88,92,80,85,756],
["赵六",80,85,90,82,88,95,76,88,85,734],
["陈七",88,92,85,90,82,88,95,80,85,735],
["周八",76,80,85,88,92,80,85,90,82,716],
["吴九",90,85,88,82,80,92,85,88,80,700],
["郑十",82,88,90,85,92,80,88,85,76,716],
["孙十一",85,80,82,90,88,95,82,85,80,707],
["李十二",88,90,85,82,80,88,92,85,76,716]
],
"fileName":"学生成绩单",
"folderName":"Downloads",
"headers":["姓名","语文","数学","英语","物理","化学","生物","历史","地理","政治","总分"]
}刚想说自己的担心是多余的,结果却在其他问题上翻了车,比如当要求它把前面对话中出现过的表格保存成文件时,会把表头当作数据传进来(headers里传了表头,但是数据第一行也是表头),导致表头重复,如:
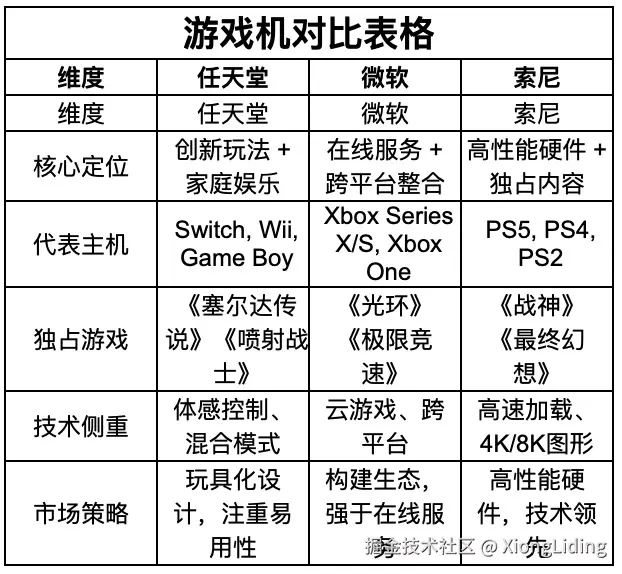
甚至在我要求合并三份数据时,出现了表头和内容不一致的情况,表头是想并列展示,内容却想按列表展示。
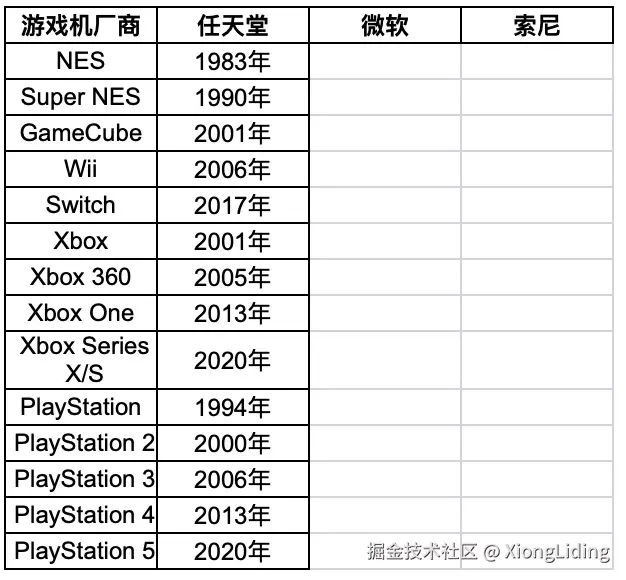
基本上可以确定,在模型能力较弱的时候,将表头和数据分成两个参数是错误的决定。
紧接着,接下来的一个测试让我彻底放弃了二维数组。我用的客户端是 BoltAI,是 Setapp 里的,有一定的免费额度可以通过 Setapp 间接调用 ChatGPT 的模型,结果直接报错,无法识别这个参数。第3个坑:MCP需要客户端、服务端以及模型接口三方配合,但支持并不是简单的 yes or no,在参数的实现上还有更细粒度的差异。
问题遇到不少,但乐观一点想,卖点不就来了,可以把 sheetex-mcp-server 搞成兼容性最好,对模型要求最低的。
于是我直接把 headers 和 data 两个参数废了,换成 table ,让模型用 markdown 格式把表格传进来,我还真没见过AI能在对话里把表格给画歪了。
javascript
{
folderName: z.string().describe(`...`),
fileName: z.string().max(32).describe('The name of the Excel file to create, excluding the .xlsx extension'),
caption: z.string().max(32).optional().default('').describe('Sheet title'),
table: z.string().describe('The dataset to export, provided as a markdown table'),
}一下子清爽了很多。
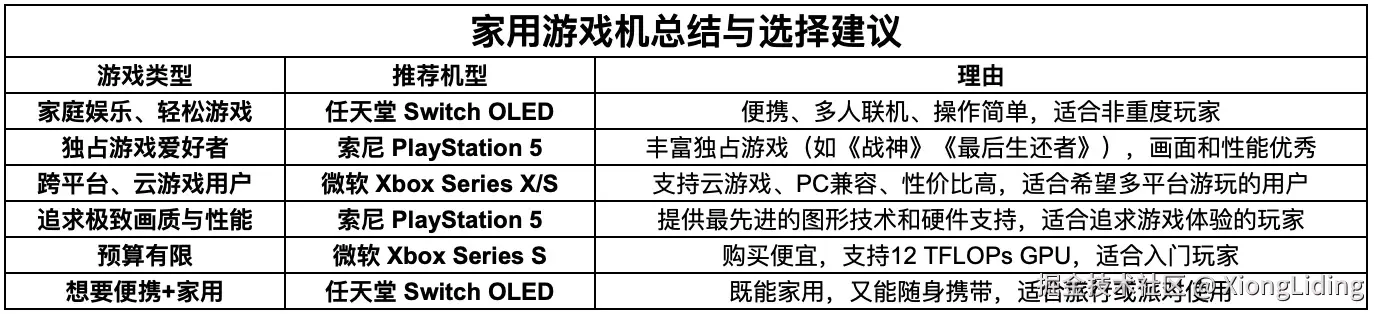
既然用了 markdown,额外的信息也不要浪费,大模型很喜欢在表格里加些小小的样式,比如加粗啥的,用二维数组这些信息就无法表达,而 markdown 格式能传达。虽然 sheetex 搞不了富文本,但是整个单元格的加粗、斜体、删除线还是可以胜任的,配合 remove-markdown 把多余样式擦除,就成了。
再进一步,把列宽也整一整,根据全角和半角字符的数量估算一下宽度,设置好上限,再配合自动换行。
又顺手解决了一个 gpt-oss:20b 会漏掉结尾 | 符号的问题,效果就出来:
讲完输入参数,再讲讲输出。MCP 工具调用完毕后,需要给大模型反馈一个结果:
javascript
return {
content: [
{
type: 'text',
text: `Operation successful, the file has been saved to: ${dist}`,
},
],
};这里的提示也不能写的太随意,我第一稿写成 Save to ${dist} ,想表达文件最终是保存到这个位置了,但大模型可能是误解成我给了它一个新的指令,让它将文件保存到这个位置,结果又调用一遍工具进行保存,陷入了循环。所以,提示2:MCP工具返回的信息要明确,大模型是可能将它当作新的指令来执行的。 我想这应该也能让多个MCP工具的配合更加灵活,让一个工具主动要求使用其他工具变得更加方便,而不像传统的接口调用,只能由主程序根据上一个接口返回的结果做基于 if else 的简单判定。
模型偏好
接下来这个问题,与其说是模型的能力补足,更像是某种偏好。
第4个坑:模型倾向于过度或过早调用 MCP 工具。
特别是非思考模式的模型。
当你让他帮你"模拟一张学生成绩单,提供10条数据时",你可能是想先让它先输出出来,看一眼,然后决定要不要保存到文件,但是模型经常过于积极,直接就保存成文件了。
第二个场景,就是当你让他将前文中出现的数据整理成表格并保存成文件时(前文中还不是表格形式),会出现模型将没有完全思考完的结果保存成文件,然后继续进行思考,返回给你一个更加完善的版本,在对话框里呈现出来。把我给看懵了,还能这么搞的。
目前对于这个问题,我还没有太好的解决方法,只能先把 mcp-server 给关了,等跟模型聊透了,对话中已经有了我想要的表格,然后再打开对应的 mcp-server,再明确的让它对上文的指定部分进行保存。
尾声
本文总结了我在第一次开发 MCP Server 时遇到的问题和几点心得,碍于篇幅与时间,并没有将发布阶段以及尝试接入 smithery 平台时遇到的相关的内容纳入,有机会再单开一篇吧,再见!