主题:LangServe、FastAPI、流式返回
目标:学会把任意
Runnable(链 / Agent / 检索链)一键发布为可调用的 HTTP API,并掌握同步、流式、批量等调用方式。
一、为什么用 LangServe?
- 零胶水 :任何
Runnable(PromptTemplate | LLM | Parser | ...)都能一行路由发布。 - 统一协议 :
invoke/stream/batch等语义在客户端完全一致。 - 兼容生态:FastAPI / Uvicorn / Docker / Kubernetes 生产级部署。
- 端到端链路 :本地调试 → 远程部署 →
RemoteRunnable远程调用,代码无缝迁移。
二、环境准备
bash
# 基础依赖(按需)
pip install -U "langchain>=0.2" "langchain-openai>=0.1" "langserve>=0.2" fastapi uvicorn
# 如果要做检索或解析,可按需安装
# pip install -U faiss-cpu chromadb unstructured若使用 OpenAI 等云端模型,请在运行前设置环境变量:
- Windows PowerShell:
setx OPENAI_API_KEY "your-key"- Linux/macOS:
export OPENAI_API_KEY=your-key
三、把链发布为 REST API
1)定义一条最简单的链(Runnable)
python
# file: chain_def.py
import os
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
def build_chain():
prompt = ChatPromptTemplate.from_messages([
("system", "你是简洁、有逻辑的中文助理。"),
("human", "请简要回答:{question}")
])
llm = ChatOpenAI(
temperature=0,
model="glm-4.5",
openai_api_key=os.getenv("ZAI_API_KEY"),
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
return prompt | llm | StrOutputParser()2)用 LangServe + FastAPI 暴露这条链
python
# file: server.py
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
from langserve import add_routes
from chain_def import build_chain
app = FastAPI(title="LangServe Demo", version="1.0")
# 可按需开放跨域(本地前端调试很有用)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # 生产环境请按需收紧
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 将 Runnable 发布到 /qa 路径
qa_chain = build_chain()
add_routes(app, qa_chain, path="/qa")
# 也可以挂多个链:
# add_routes(app, another_chain, path="/summarize")
# 启动:uvicorn server:app --reload --port 8000启动服务:
bash
uvicorn server:app --reload --port 80003)快速测试
- 同步调用(invoke):
bash
curl -X POST http://localhost:8000/qa/invoke \
-H "Content-Type: application/json;charset=utf-8" \
-d '{"input": {"question": "什么是LangServe?"}}'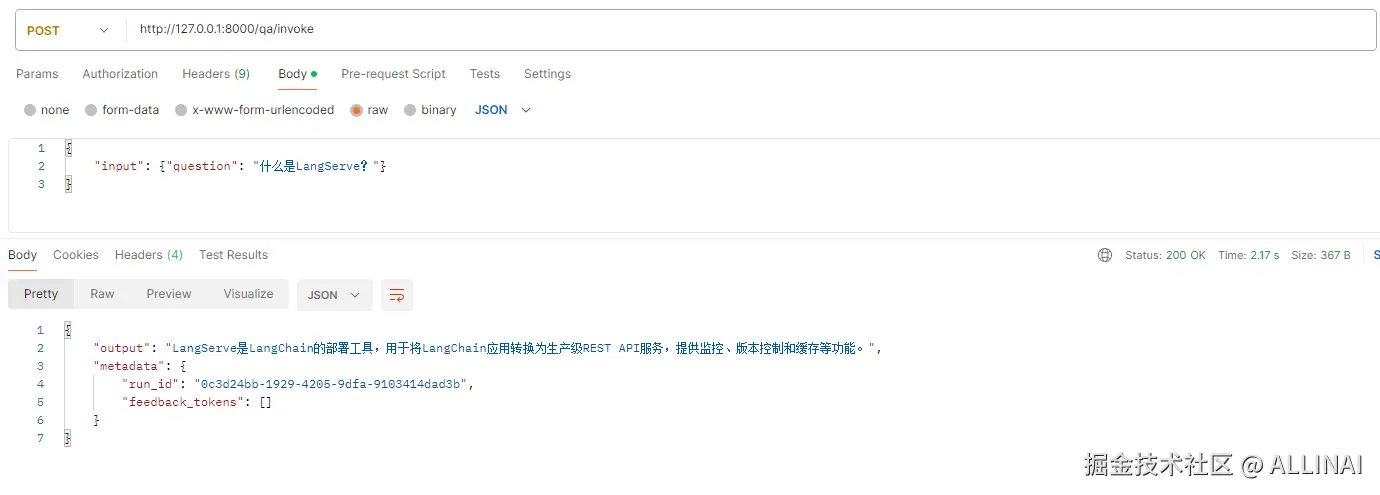
- 流式返回(Server-Sent Events):
bash
curl -N -X POST http://localhost:8000/qa/stream \
-H "Content-Type: application/json" \
-d '{"input": {"question": "用一句话科普黑洞"}}'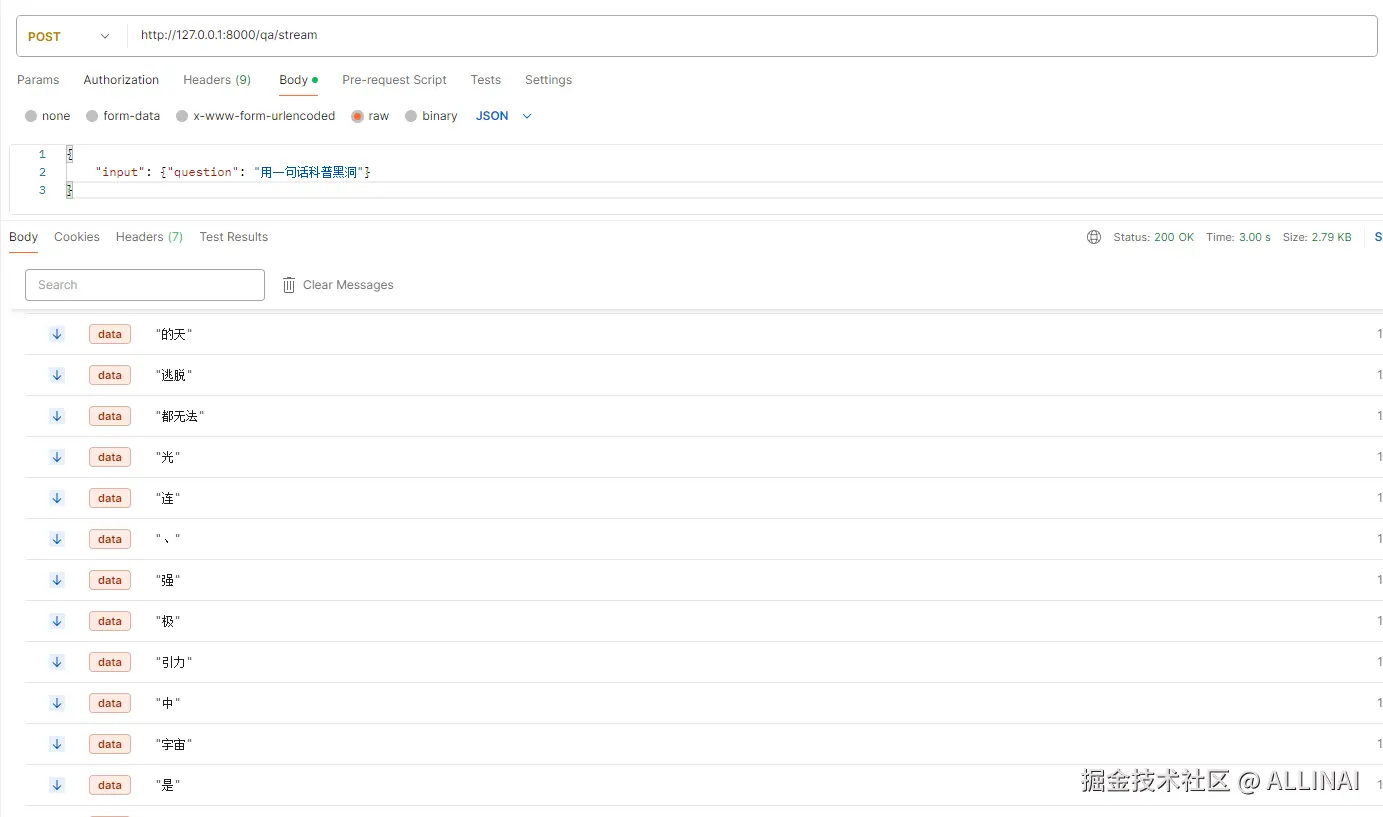
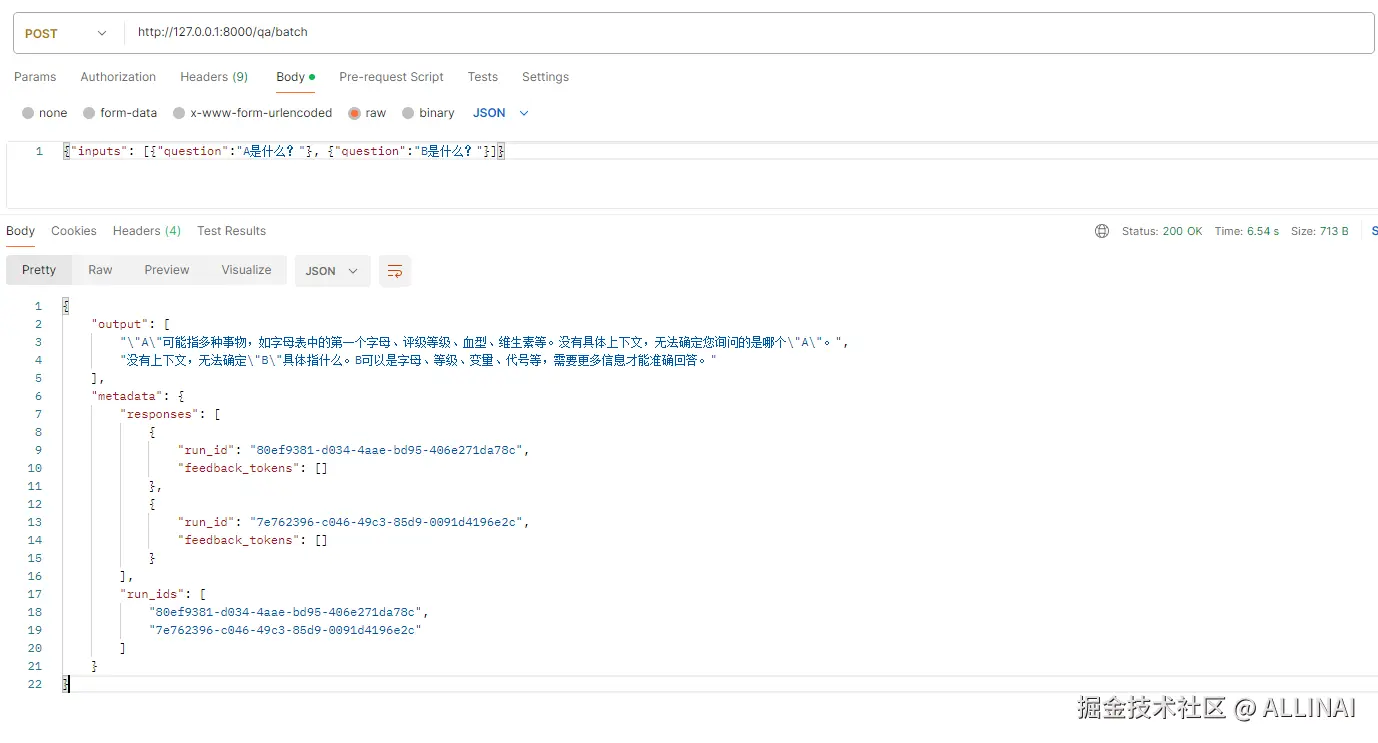
- 批量调用(batch):
bash
curl -X POST http://localhost:8000/qa/batch \
-H "Content-Type: application/json" \
-d '{"inputs": [{"question":"A是什么?"}, {"question":"B是什么?"}]}'返回结果会是结构化 JSON(invoke/batch)或一系列 SSE 数据块(stream)。
四、远程客户端:像本地一样使用远程链
RemoteRunnable 让你像使用本地链一样调用远端服务,无需手写 HTTP。
python
# file: client.py
from langserve import RemoteRunnable
remote = RemoteRunnable("http://localhost:8000/qa")
# 1) 同步调用
out = remote.invoke({"question": "给我一句激励语"})
print("INVOKE:", out)
# 2) 流式返回
print("STREAM:", end=" ")
for chunk in remote.stream({"question": "简述量子纠缠"}):
print(chunk, end="")
print()
# 3) 批量调用
res = remote.batch([
{"question": "牛顿第一定律是什么?"},
{"question": "相对论的核心观点?"},
])
print("BATCH:", res)
五、给链定义输入/输出 Schema(更稳、更可维护)
如果你的链需要严格的字段校验(例如对外开放 API),可以加 Pydantic Schema。
python
# file: chain_def_schema.py
import os
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableLambda
class QAInput(BaseModel):
question: str = Field(..., description="用户问题")
class QAOutput(BaseModel):
answer: str
def build_typed_chain():
prompt = ChatPromptTemplate.from_template("用三句话回答:{question}")
llm = ChatOpenAI(
temperature=0,
model="glm-4.5",
openai_api_key=os.getenv("ZAI_API_KEY"),
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
# 将 llm 输出封装到结构化输出
def wrap(d: dict) -> QAOutput:
return QAOutput(answer=d["answer"])
# 把字符串输出映射成 {"answer": text}
chain = prompt | llm | (lambda msg: {"answer": msg.content})
return RunnableLambda(lambda x: QAInput(**x)) | chain | RunnableLambda(wrap)在 server.py 中挂载:
python
# ...
from chain_def_schema import build_typed_chain
typed_chain = build_typed_chain()
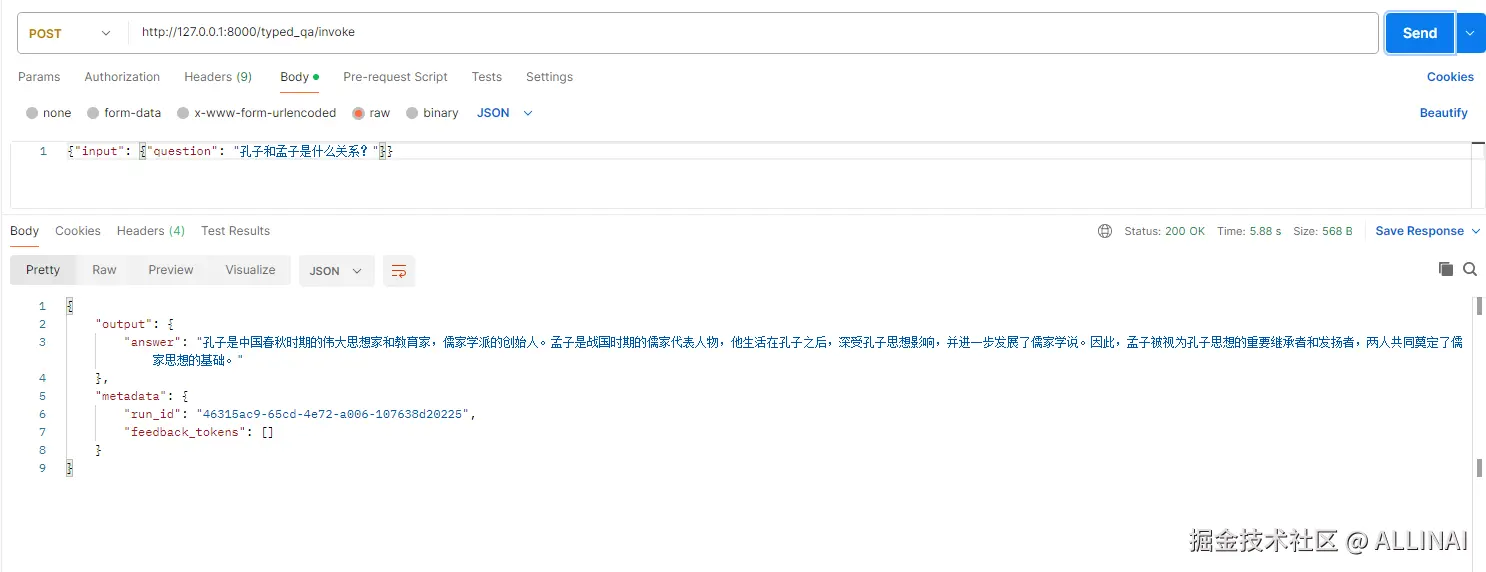
add_routes(app, typed_chain, path="/typed_qa")此时 /typed_qa 的输入输出将遵循你定义的 Pydantic 模型,OpenAPI 文档也会更清晰。
六、把 Agent / 检索链 也一把梭:任何 Runnable 都能 Serve
Agent / RAG 只要最终是 Runnable,一律可 add_routes:
python
# file: my_rag_module.py
import os
from langchain.chains.retrieval import create_retrieval_chain
from langchain_community.embeddings import XinferenceEmbeddings
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableLambda
from langchain_openai import ChatOpenAI
from langchain_community.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_core.documents import Document
from langchain.prompts import ChatPromptTemplate
def build_rag_chain():
docs = [Document(
page_content="孔子是儒家学派的创始人,《论语》是记述他思想言论的著作。"
"曾子是孔子的弟子,儒家四书之一《大学》是他所作。"
"子思是孔子的孙子,曾子是他的老师,《中庸》是其所作。"
"孟子是子思门人的学生,深受《中庸》影响,《孟子》是其思想的凝聚。"
"王阳明在孔孟学说的基础之上吸收了道家和禅宗的思想精华,开辟了儒学新境界,是近五百年内儒家第一人。"
)]
splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=20)
chunks = splitter.split_documents(docs)
embedding = XinferenceEmbeddings(
server_url="http://127.0.0.1:9997",
model_uid="bge-large-zh-v1.5"
)
vs = FAISS.from_documents(chunks, embedding)
retriever = vs.as_retriever(search_kwargs={"k": 1})
prompt = ChatPromptTemplate.from_messages([
("system", "你是检索增强问答助手。基于上下文回答:\n{context}"),
("human", "{question}")
])
llm = ChatOpenAI(
temperature=0,
model="glm-4.5",
openai_api_key=os.getenv("ZAI_API_KEY"),
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
rag_chain = (
RunnableLambda(lambda x: {
"question": x["question"],
"context": retriever.invoke(x["question"])
})
| prompt
| llm
| StrOutputParser()
)
return rag_chain在 server.py 中:
python
# ...
from my_rag_module import build_rag_chain
rag_chain = build_rag_chain()
add_routes(app, rag_chain, path="/rag")现在你已经把 RAG 对外暴露成 API(支持 invoke/stream/batch 三种调用)。
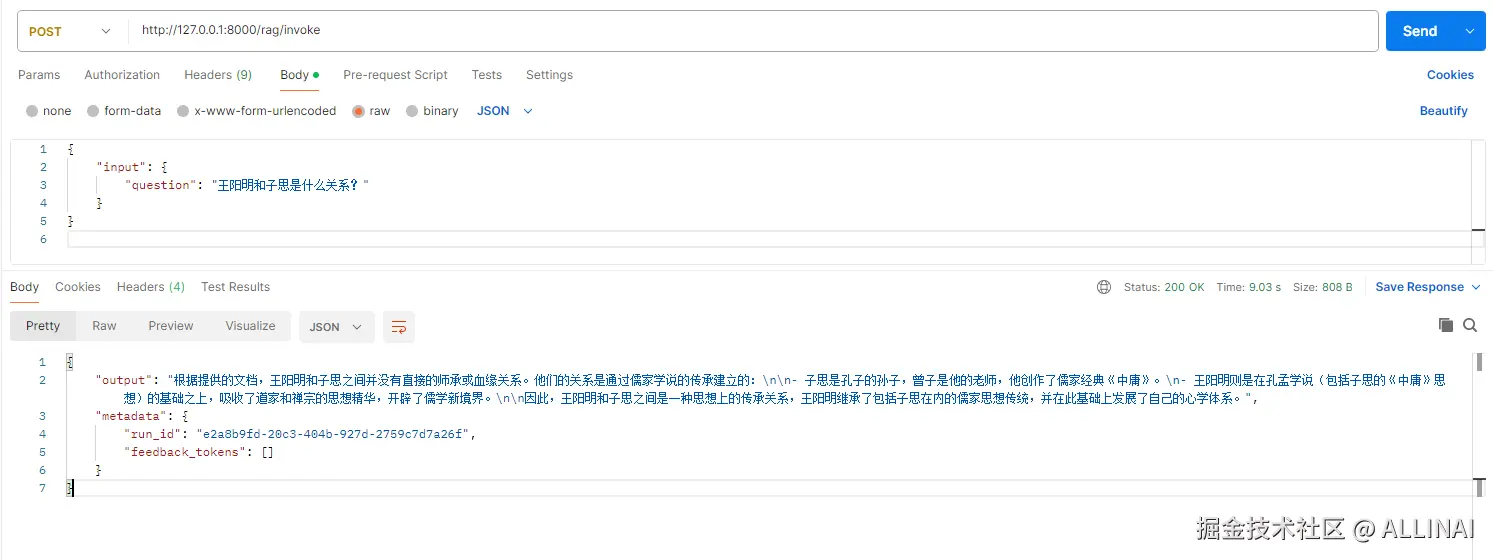
七、流式返回的实现要点与坑位
- 客户端 :SSE(Server-Sent Events)逐 token/片段接收。
RemoteRunnable.stream()已封装好。 - 服务端 :
add_routes自动提供/stream端点,不用你手写生成器。 - 观察到空字符串:部分模型或中间解析会抛空段,属于正常分包;只要最终能正确拼接即可。
- 生产中建议 :对流式输出做超时控制 和输出清洗(去除重复空白、异常分隔)。
八、生产部署清单
1)Gunicorn + Uvicorn Workers(多进程/多协程)
bash
pip install "uvicorn[standard]" gunicorn
# Linux/macOS 示例
gunicorn -k uvicorn.workers.UvicornWorker \
-w 2 \
-b 0.0.0.0:8000 \
server:app-w工作者数量:按 CPU/内存调优- I/O 密集型链路可考虑
--threads或更多协程
2)Dockerfile(简洁版)
dockerfile
FROM python:3.11-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install -U pip && pip install -r requirements.txt
COPY . .
EXPOSE 8000
CMD ["uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8000"]requirements.txt 示例:
shell
langchain>=0.2
langchain-openai>=0.1
langserve>=0.2
fastapi
uvicorn3)安全与限流
- 密钥管理:用环境变量 + KMS/Secrets Manager,避免写死在代码里。
- CORS 与鉴权 :生产环境务必收紧
allow_origins,并在网关或路由层加签名校验或 JWT。 - 速率限制:建议配合 API 网关或反向代理(如 Nginx/Envoy/Cloudflare)。
九、进阶技巧
- 多路由多链 :一个服务挂多个
Runnable,分不同路径管理(如/qa、/rag、/agent)。 - 版本化 :为重要链做
/v1/qa、/v2/qa路径,灰度升级。 - 请求透传 :LangServe 会把
config透传到底层,可用于打标签、LangSmith 追踪、超参数设置。 - 客户端复用 :
RemoteRunnable与本地RunnableAPI 一致,迁移成本几乎为零。
🔚 小结
add_routes(app, runnable, path="/...")是发布 API 的核心一招。RemoteRunnable让你"像本地链一样"使用远端链。- LangServe 原生提供
invoke/stream/batch三态调用,配合 FastAPI / Uvicorn,既能本地开发又能生产部署。 - 通过 Pydantic 模型约束输入输出、CORS/鉴权/限流保障安全性,轻松做到工程级上线。
接下来我们将从零搭建一个迷你框架:定义
Runnable协议、实现链式组合与配置流转,再做一个最小可用的 Agent 决策循环,帮助你把"原理级理解"变成"可落地工程"。