本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
随着大模型/LLM 与检索、工具调用、记忆、调度等组合使用成为主流,越来越多框架出现以降低构建"会思考、会规划、会调用工具"的智能体(agent)的门槛。下面我以一名 AI 大模型开发专家的视角,列出目前市面上比较受欢迎且成熟的开源框架,说明它们的定位、核心优势、局限,并给出选型建议与对比表,帮助你快速判断哪个最适合你的项目。

一、概览
- LangChain --- 以"组装链(chains)/agents/工具集成"著称,生态最广。
Microsoft AutoGen --- 面向多智能体协作与研究/工程结合的框架(微软开源)。

Microsoft Semantic Kernel (SK) --- 微软的 SDK,偏企业级、流程化 agent 与技能(skill)抽象
Haystack(deepset) --- 以 RAG(检索增强生成)与生产级管道/编排见长,适合文档型应用与问答

LlamaIndex(原 GPT-Index) --- 专注"数据接入 + 索引 + 查询"层,做知识增强与对接大规模数据源非常方便

二、几种框架的优缺点比较
1.LangChain
定位与特点 LangChain 是目前最被广泛采用的 agent / LLM 应用框架之一,提供预置 agent 模板、丰富的工具/连接器(向量数据库、API、记忆、工具调用),并在 Python/JS 双生态活跃。它强调"组件可组合性"与快速原型。1
优点
- 生态大、社区活跃、插件/示例非常多(向量 DB、工具、观察/评估平台等)。
- 上手快:有众多预置 agent 策略(反复思考、链式思考、工具选择器等)。
- 语言/平台覆盖(Python + JS/TS),适合前后端协作部署。
缺点
- 框架层抽象很多时会显得"重量级",复杂生产场景需要精心设计以控制成本/延迟。
- 由于插件多,版本/兼容性管理可能是工程负担。
典型场景:聊天机器人、任务型 agent、工具调用原型、SaaS 应用 POC。
2. Microsoft AutoGen
定位与特点 AutoGen 是微软推出的面向多智能体协同与"agent 编程" 的框架,强调 agent 之间协作、角色分工与分布式执行,适合需要多个 agent 协作/模拟的复杂工作流。微软也在将其与其它 SDK(如 Semantic Kernel)整合或并行发展。
优点
- 原生支持多 agent 协作、对话式任务分解、基于角色的任务分配。
- 注重工程化(日志、测试、调度)与研究(multi-agent behavior)结合。
缺点
- 生态与模板相对较新(但增长快),上手曲线对工程化/分布式部署要求高。
- 重点偏向"多 agent 协作范式",若只是做单体 RAG agent,可能显得过度。
典型场景:复杂业务流程自动化、多角色协作(如模拟客服+专家+检索员)、研究型多 agent 系统。
3. Microsoft Semantic Kernel(SK)
定位与特点 Semantic Kernel 是微软提供的一个模型无关(model-agnostic)SDK,强调技能(skill)/插件化、流程化的 agent 架构(适配 .NET / Python),对企业级、生产化集成友好。它更像是把"业务技能、计划、记忆"做成可注册、可复用的模块。
优点
- 结构化思路:技能(functions/skills)抽象清晰,便于企业治理与复用。
- 支持多语言栈(.NET、Python),与微软生态(Azure)整合度高。
- 企业级关注点(安全、扩展、运维)较好。
缺点
- 对偏实验/快速迭代的团队,初始学习成本和工程化投入可能较高。
- 目前生态仍偏微软/企业方向,社区示例不如 LangChain 丰富。
典型场景:企业级流程自动化、与现有 .NET 系统结合的智能工作流、需要技能治理的场景。
4.Haystack(deepset)
定位与特点 Haystack 是面向**RAG(检索增强生成)**与生产级管道的开源框架,擅长把检索、向量数据库、转换器(PDF/Office 等)、生成器拼成可部署的流水线(pipelines / agents)。它定位是"把研究级方法做成工程可用的堆栈"。
优点
- 在检索、索引、QA、文档理解等场景非常成熟(内建多种检索策略与向量 DB 适配)。
- 支持可序列化的 Pipeline,便于在 Kubernetes 等生产环境部署与监控。
- 文档处理与企业搜索场景的最佳实践多。
缺点
- 如果你的目标是"多 agent 协作"或高度自定义的 agent 策略,Haystack 更关注 RAG/管道而非 agent 策略语言。
- 学习曲线在于理解 Pipeline 与组件契约(但文档较好)。
典型场景:企业知识库问答、文档检索+生成的客服/搜索、需要稳定生产部署的 RAG 服务。
5. LlamaIndex
定位与特点 LlamaIndex 专注把"各种数据源(API、文件、DB、表格)"转成索引/向量/结构化提示,让 LLM 可以高效查询与生成。它更像是"知识接入层"(data framework),常与 LangChain、Haystack 等配合使用。
优点
- 提供丰富的数据接入器与索引结构(树/图/混合索引),便于快速把公司数据"喂给"LLM。
- 非常适合需要复杂检索策略或自定义索引结构的场景。
- 与其它 agent 框架兼容(可作为知识层独立使用)。
缺点
- 它不是完整的 agent 编排框架(不提供大量预置 agent 策略),需要和 LangChain/Haystack 等配合。
- 在纯工具编排/多 agent 协作方面需额外实现。
典型场景:大规模文档/数据库接入、企业知识增强、需要自定义索引结构的查询型应用。
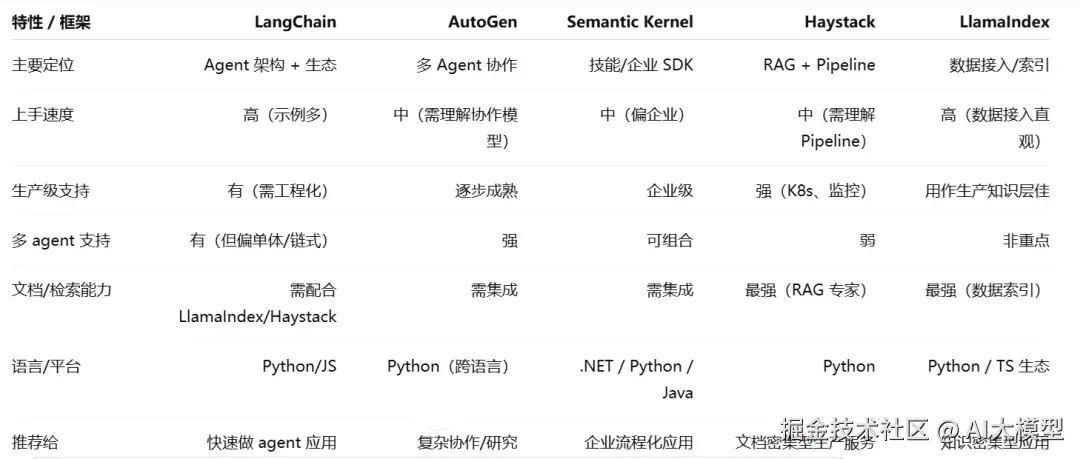
对比速览表
三、选型建议(实战向)
- 想快速做 PoC 或产品原型 :优先选 LangChain(丰富模板、示例、工具)。
- 需要把公司文档/知识库接入并做问答/客服 :先用 LlamaIndex 做数据接入/索引,再把它和 Haystack 或 LangChain 组合部署。
- 企业级流程、需要技能管理或与 .NET 深度整合 :优先 Semantic Kernel。
- 场景需要多个"角色"智能体协同(复杂任务分工/仿真) :看 AutoGen。
落地注意点
- 指标/可观测:从一开始把调用延迟、token 消耗、工具调用失败率纳入监控(LangChain/AutoGen 都支持接入监控/评估)。
- 成本控制:将复杂推理拆成检索 + 缩短上下文 + 精简提示,优先用 RAG(Haystack/LlamaIndex)。
- 安全/工具隔离:任何 agent 调用外部工具(写文件、执行命令)时务必做权限与输入校验。
- 组合使用 :实际产品里常见组合:LlamaIndex(数据层)+ LangChain(agent 层)+ Haystack(检索管道或替代) 。这三者经常互补。
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。