LangChain结合SQL实现数据分析问答
引言
随着大语言模型(LLM)在各领域的应用不断深入,将LLM与结构化数据库结合已成为数据分析的重要趋势。本教程将介绍如何使用LangChain框架结合SQL数据库,构建一个能够通过自然语言查询和分析数据的问答系统。通过这个系统,用户可以使用自然语言或直接的SQL语句查询数据库,获得相关的数据分析结果。
1. 系统架构
我们将构建的数据分析问答系统包含以下几个核心组件:
- 数据库层:SQLite数据库存储结构化数据
- 语言模型层:使用OpenAI API进行自然语言处理和SQL生成
- 向量检索层:使用嵌入模型计算相似度,提高检索精度
- 应用层:使用Streamlit构建用户友好的交互界面
- 集成层:使用LangChain的SQLDatabaseChain连接数据库和语言模型

2. 环境准备
首先,我们需要安装必要的依赖库:
bash
# 安装主要依赖
pip install langchain langchain-openai langchain-experimental faiss-cpu streamlit==1.29.0 pandas sqlite3 python-dotenv
# 注意:streamlit版本需要<1.30,推荐使用1.29.0
# 使用更高版本可能会出现SCHEMAERROR错误3. 数据库准备
我们需要准建立SQLite数据库并导入数据:
python
import sqlite3
import pandas as pd
import os
def create_database():
"""创建SQLite数据库并导入CSV数据"""
# 创建数据库连接
conn = sqlite3.connect('offers.db')
# 读取CSV文件并导入到数据库
data_dir = 'data'
# 导入品牌类别表
brand_category_df = pd.read_csv(os.path.join(data_dir, 'brand_category.csv'))
brand_category_df.to_sql('brand_category', conn, if_exists='replace', index=False)
# 导入类别表
categories_df = pd.read_csv(os.path.join(data_dir, 'categories.csv'))
categories_df.to_sql('categories', conn, if_exists='replace', index=False)
# 导入offer零售商表
offer_retailer_df = pd.read_csv(os.path.join(data_dir, 'offer_retailer.csv'))
offer_retailer_df.to_sql('offer_retailer', conn, if_exists='replace', index=False)
# 关闭连接
conn.close()
print("数据库创建完成!")
# 执行数据库创建
if not os.path.exists('offers.db'):
create_database()4. 导入依赖库
接下来,我们导入所需的库:
python
import os
import sqlite3
import pandas as pd
import streamlit as st
from dotenv import load_dotenv
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain_experimental.sql import SQLDatabaseChain
from langchain.sql_database import SQLDatabase
from langchain.chains import create_sql_query_chain
from langchain.output_parsers import ResponseSchema, StructuredOutputParser
import numpy as np
from typing import List, Dict, Any
# 加载环境变量
load_dotenv()5. 构建数据库连接
创建SQLDatabase对象,用于LangChain与SQLite数据库的交互:
python
def get_db_connection():
"""获取数据库连接"""
db = SQLDatabase.from_uri("sqlite:///offers.db")
return db6. 实现LLM查询处理器
使用LangChain的SQLDatabaseChain实现自然语言到SQL的转换:
python
def create_sql_chain():
"""创建SQL查询链"""
# 初始化语言模型
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
# 获取数据库连接
db = get_db_connection()
# 创建SQL查询链
chain = create_sql_query_chain(llm, db)
return chain, db
def create_retrieval_chain():
"""创建检索链,用于处理自然语言查询"""
# 初始化语言模型
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
# 获取数据库连接
db = get_db_connection()
# 创建SQL数据库链
db_chain = SQLDatabaseChain.from_llm(
llm=llm,
db=db,
verbose=True,
return_intermediate_steps=True
)
return db_chain
class RetrievalLM:
"""检索语言模型类,用于处理查询和计算相似度"""
def __init__(self):
self.embeddings = OpenAIEmbeddings()
self.sql_chain, self.db = create_sql_chain()
self.db_chain = create_retrieval_chain()
def process_query(self, query: str) -> Dict[str, Any]:
"""处理用户查询"""
# 判断是否是SQL查询
if query.lower().startswith("select"):
# 直接执行SQL查询
try:
conn = sqlite3.connect('offers.db')
result_df = pd.read_sql_query(query, conn)
conn.close()
return {
"sql": query,
"result": result_df
}
except Exception as e:
return {
"error": f"SQL执行错误: {str(e)}"
}
else:
# 使用LLM处理自然语言查询
try:
# 生成SQL查询
sql_query = self.sql_chain.invoke(query)
# 执行SQL查询
conn = sqlite3.connect('offers.db')
result_df = pd.read_sql_query(sql_query, conn)
conn.close()
# 计算查询结果与原始查询的相似度
if not result_df.empty:
result_df = self.rank_by_relevance(query, result_df)
return {
"sql": sql_query,
"result": result_df
}
except Exception as e:
# 如果SQL生成失败,尝试使用数据库链
try:
result = self.db_chain(query)
# 解析结果
return {
"sql": result["intermediate_steps"][0],
"result": pd.DataFrame([eval(result["intermediate_steps"][1])])
}
except Exception as e2:
return {
"error": f"处理查询错误: {str(e2)}"
}
def rank_by_relevance(self, query: str, df: pd.DataFrame) -> pd.DataFrame:
"""根据相关性对结果进行排序"""
# 将查询转换为嵌入
query_embedding = self.embeddings.embed_query(query)
# 将DataFrame转换为文本列表
texts = df.astype(str).apply(lambda x: ' '.join(x), axis=1).tolist()
# 获取文本嵌入
doc_embeddings = self.embeddings.embed_documents(texts)
# 计算余弦相似度
similarities = []
for doc_embedding in doc_embeddings:
similarity = np.dot(query_embedding, doc_embedding) / (
np.linalg.norm(query_embedding) * np.linalg.norm(doc_embedding)
)
similarities.append(similarity)
# 添加相似度列并排序
df['relevance_score'] = similarities
df = df.sort_values(by='relevance_score', ascending=False).reset_index(drop=True)
return df7. 构建Streamlit用户界面
使用Streamlit创建用户友好的交互界面:
python
def main():
"""主函数,构建Streamlit应用"""
# 设置页面标题
st.title("基于SQL的数据分析问答系统")
# 侧边栏 - 输入OpenAI API密钥
with st.sidebar:
st.header("配置")
api_key = st.text_input("输入您的OpenAI API密钥", type="password")
if api_key:
os.environ["OPENAI_API_KEY"] = api_key
# 主界面
st.write("欢迎使用数据分析问答系统!您可以使用自然语言或SQL语句查询数据库。")
# 示例查询
st.subheader("示例查询")
st.write("1. `select * from categories` - 查看所有类别")
st.write("2. `select CATEGORY_ID from categories` - 查看所有类别ID")
st.write("3. `RED GOLD` - 查找与'RED GOLD'相关的offer")
# 查询输入
query = st.text_input("请输入您的查询(自然语言或SQL)")
# 处理查询
if st.button("搜索"):
if not query:
st.warning("请输入查询内容")
return
if not api_key:
st.warning("请先输入OpenAI API密钥")
return
with st.spinner("正在处理查询..."):
# 初始化检索模型
retrieval_lm = RetrievalLM()
# 处理查询
result = retrieval_lm.process_query(query)
# 显示结果
if "error" in result:
st.error(result["error"])
else:
# 显示生成的SQL
st.subheader("生成的SQL查询")
st.code(result["sql"], language="sql")
# 显示查询结果
st.subheader("查询结果")
st.dataframe(result["result"])8. 完整代码
下面是完整的应用程序代码:
python
import os
import sqlite3
import pandas as pd
import streamlit as st
import numpy as np
from dotenv import load_dotenv
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain_experimental.sql import SQLDatabaseChain
from langchain.sql_database import SQLDatabase
from langchain.chains import create_sql_query_chain
from typing import List, Dict, Any
# 加载环境变量
load_dotenv()
def create_database():
"""创建SQLite数据库并导入CSV数据"""
# 创建数据库连接
conn = sqlite3.connect('offers.db')
# 读取CSV文件并导入到数据库
data_dir = 'data'
# 导入品牌类别表
brand_category_df = pd.read_csv(os.path.join(data_dir, 'brand_category.csv'))
brand_category_df.to_sql('brand_category', conn, if_exists='replace', index=False)
# 导入类别表
categories_df = pd.read_csv(os.path.join(data_dir, 'categories.csv'))
categories_df.to_sql('categories', conn, if_exists='replace', index=False)
# 导入offer零售商表
offer_retailer_df = pd.read_csv(os.path.join(data_dir, 'offer_retailer.csv'))
offer_retailer_df.to_sql('offer_retailer', conn, if_exists='replace', index=False)
# 关闭连接
conn.close()
print("数据库创建完成!")
def get_db_connection():
"""获取数据库连接"""
db = SQLDatabase.from_uri("sqlite:///offers.db")
return db
def create_sql_chain():
"""创建SQL查询链"""
# 初始化语言模型
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
# 获取数据库连接
db = get_db_connection()
# 创建SQL查询链
chain = create_sql_query_chain(llm, db)
return chain, db
def create_retrieval_chain():
"""创建检索链,用于处理自然语言查询"""
# 初始化语言模型
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
# 获取数据库连接
db = get_db_connection()
# 创建SQL数据库链
db_chain = SQLDatabaseChain.from_llm(
llm=llm,
db=db,
verbose=True,
return_intermediate_steps=True
)
return db_chain
class RetrievalLM:
"""检索语言模型类,用于处理查询和计算相似度"""
def __init__(self):
self.embeddings = OpenAIEmbeddings()
self.sql_chain, self.db = create_sql_chain()
self.db_chain = create_retrieval_chain()
def process_query(self, query: str) -> Dict[str, Any]:
"""处理用户查询"""
# 判断是否是SQL查询
if query.lower().startswith("select"):
# 直接执行SQL查询
try:
conn = sqlite3.connect('offers.db')
result_df = pd.read_sql_query(query, conn)
conn.close()
return {
"sql": query,
"result": result_df
}
except Exception as e:
return {
"error": f"SQL执行错误: {str(e)}"
}
else:
# 使用LLM处理自然语言查询
try:
# 生成SQL查询
sql_query = self.sql_chain.invoke(query)
# 执行SQL查询
conn = sqlite3.connect('offers.db')
result_df = pd.read_sql_query(sql_query, conn)
conn.close()
# 计算查询结果与原始查询的相似度
if not result_df.empty:
result_df = self.rank_by_relevance(query, result_df)
return {
"sql": sql_query,
"result": result_df
}
except Exception as e:
# 如果SQL生成失败,尝试使用数据库链
try:
result = self.db_chain(query)
# 解析结果
return {
"sql": result["intermediate_steps"][0],
"result": pd.DataFrame([eval(result["intermediate_steps"][1])])
}
except Exception as e2:
return {
"error": f"处理查询错误: {str(e2)}"
}
def rank_by_relevance(self, query: str, df: pd.DataFrame) -> pd.DataFrame:
"""根据相关性对结果进行排序"""
# 将查询转换为嵌入
query_embedding = self.embeddings.embed_query(query)
# 将DataFrame转换为文本列表
texts = df.astype(str).apply(lambda x: ' '.join(x), axis=1).tolist()
# 获取文本嵌入
doc_embeddings = self.embeddings.embed_documents(texts)
# 计算余弦相似度
similarities = []
for doc_embedding in doc_embeddings:
similarity = np.dot(query_embedding, doc_embedding) / (
np.linalg.norm(query_embedding) * np.linalg.norm(doc_embedding)
)
similarities.append(similarity)
# 添加相似度列并排序
df['relevance_score'] = similarities
df = df.sort_values(by='relevance_score', ascending=False).reset_index(drop=True)
return df
def main():
"""主函数,构建Streamlit应用"""
# 设置页面标题
st.title("基于SQL的数据分析问答系统")
# 侧边栏 - 输入OpenAI API密钥
with st.sidebar:
st.header("配置")
api_key = st.text_input("输入您的OpenAI API密钥", type="password")
if api_key:
os.environ["OPENAI_API_KEY"] = api_key
# 主界面
st.write("欢迎使用数据分析问答系统!您可以使用自然语言或SQL语句查询数据库。")
# 示例查询
st.subheader("示例查询")
st.write("1. `select * from categories` - 查看所有类别")
st.write("2. `select CATEGORY_ID from categories` - 查看所有类别ID")
st.write("3. `RED GOLD` - 查找与'RED GOLD'相关的offer")
# 查询输入
query = st.text_input("请输入您的查询(自然语言或SQL)")
# 处理查询
if st.button("搜索"):
if not query:
st.warning("请输入查询内容")
return
if not api_key:
st.warning("请先输入OpenAI API密钥")
return
with st.spinner("正在处理查询..."):
# 初始化检索模型
retrieval_lm = RetrievalLM()
# 处理查询
result = retrieval_lm.process_query(query)
# 显示结果
if "error" in result:
st.error(result["error"])
else:
# 显示生成的SQL
st.subheader("生成的SQL查询")
st.code(result["sql"], language="sql")
# 显示查询结果
st.subheader("查询结果")
st.dataframe(result["result"])
# 检查并创建数据库
if not os.path.exists('offers.db'):
create_database()
# 运行应用
if __name__ == "__main__":
main()9. 运行应用
将上述代码保存为app.py,然后运行:
bash
streamlit run app.py应用运行后,打开浏览器并导航到 http://localhost:8501 访问数据分析问答界面。
10. 使用示例
示例1:直接SQL查询
输入SQL查询:select * from categories
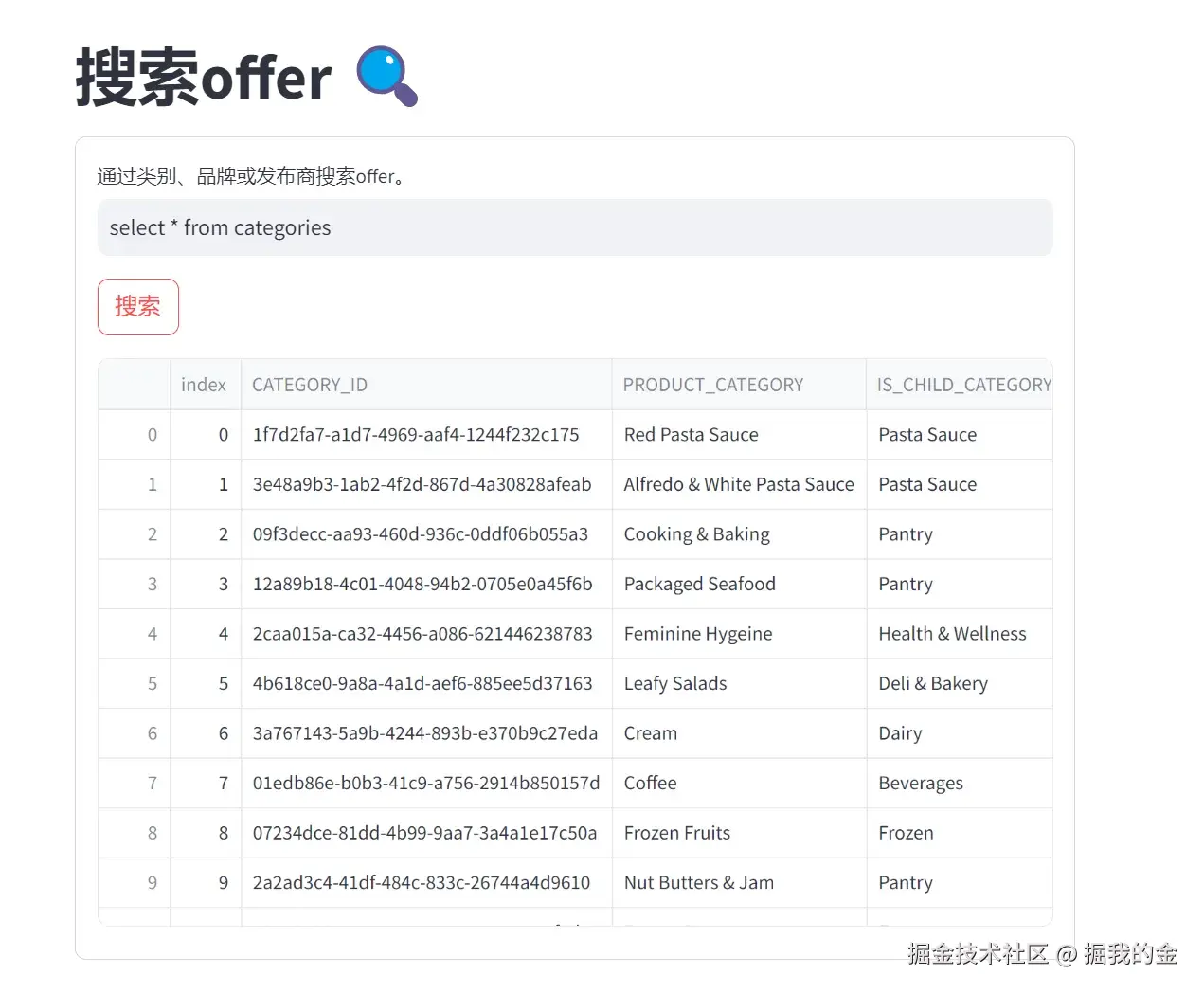
示例2:查询特定字段
输入SQL查询:select CATEGORY_ID from categories
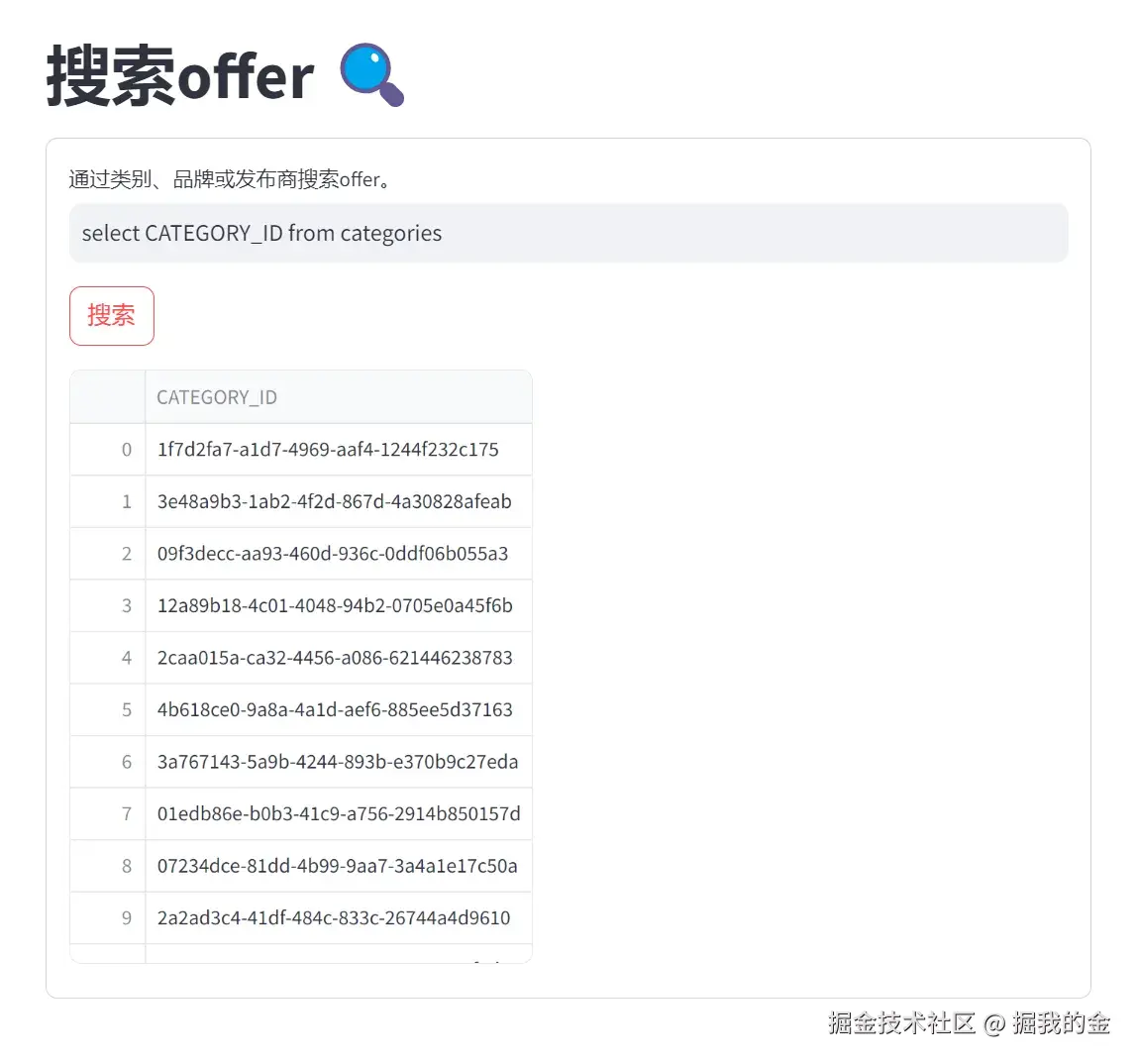
示例3:自然语言查询
输入自然语言查询:RED GOLD
系统会将自然语言查询转换为SQL查询,然后执行并返回结果。结果会根据相关性排序,最相关的结果显示在前面。
11. 系统优化
为了进一步提升系统性能,您可以考虑以下优化:
-
提示工程优化:
- 为LLM提供更详细的表结构信息
- 添加示例查询和期望的SQL输出
- 使用Few-shot learning提高SQL生成质量
-
性能优化:
- 使用缓存减少重复API调用
- 对频繁查询的结果进行预计算
- 使用异步处理提高响应速度
-
用户体验优化:
- 添加查询历史记录功能
- 提供可视化数据展示
- 实现查询建议功能
-
错误处理优化:
- 提供更友好的错误提示
- 添加SQL语法检查
- 实现自动纠错功能
12. 注意事项
-
版本兼容性:
- 确保使用Streamlit 1.29.0版本,避免出现SCHEMAERROR错误
- 如使用更高版本的Streamlit,可能需要调整代码以适应新的API
-
数据库结构:
- 确保数据库包含必要的表:brand_category,categories和offer_retailer
- 表结构应与示例代码中的假设一致
-
API密钥安全:
- 不要在代码中硬编码API密钥
- 使用环境变量或配置文件存储敏感信息