前言
我们在开发一些远程过程调用(RPC)的程序时通常会涉及对象的序列化/反序列化问题,例如一个Person对象从客户端通过TCP方式发送到服务端。由于TCP(或者UDP等类似低层协议)只能发送字节流,因此需要应用层将Java POJO对象"序列化"成字节流,发送过去之后,数据接收端再将字节流"反序列化"成Java POJO对象即可。
序列化"和"反序列化"一定会涉及POJO的编码和格式化(Encoding & Format),目前我们可选择的编码方式有:
- 使用JSON;
- 基于XML;
- 使用Java内置的编码和序列化机制;
- 开源的二进制的序列化/反序列化框架,例如Apache Avro、Apache Thrift、Protobuf等。
评价一个序列化框架的优缺点大概从两方面着手:
(1)结果数据大小:原则上说,序列化后的数据尺寸越小,传输效率越高。
(2)结构复杂度:会影响序列化/反序列化的效率,结构越复杂越耗时。
理论上来说,对于对性能要求不是太高的服务器程序,可以选择JSON文本格式的序列化框架;对于性能要求比较高的服务器程序,应该选择传输效率更高的二进制序列化框架,建议是Protobuf。
Protobuf是一个高性能、易扩展的序列化框架,性能比较高。Protobuf本身非常简单,易于开发,而且结合Netty框架,可以非常便捷地实现一个通信应用程序。反过来,Netty也提供了相应的编解码器,为Protobuf解决了有关Socket通信中"半包、粘包"等问题。
详解粘包和拆包
最为理想的情况是:发送端每发送一个ByteBuf缓冲区,接收端就能接收到一个ByteBuf,并且发送端和接收端的ByteBuf内容一模一样。然而,在实际的通信过程中并没有大家预料的那么完美。
半包问题的实战案例
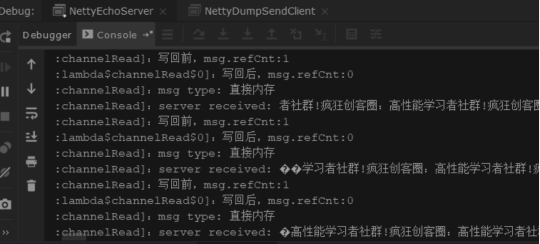
仔细观察服务端的控制台输出,可以看出存在三种类型的输出:
(1)读到一个完整的客户端输入ByteBuf。
(2)读到多个客户端的ByteBuf输入,但是"粘"在了一起。
(3)读到部分ByteBuf的内容,并且有乱码。
什么是半包问题
半包问题包含了"粘包"和"半包"两种情况:
(1)粘包:接收端(Receiver)收到一个ByteBuf,包含了发送端(Sender)的多个ByteBuf,发送端的多个ByteBuf在接收端"粘"在了一起。
(2)半包:Receiver将Sender的一个ByteBuf"拆"开了收,收到多个破碎的包。换句话说,Receiver收到了Sender的一个ByteBuf的一小部分。
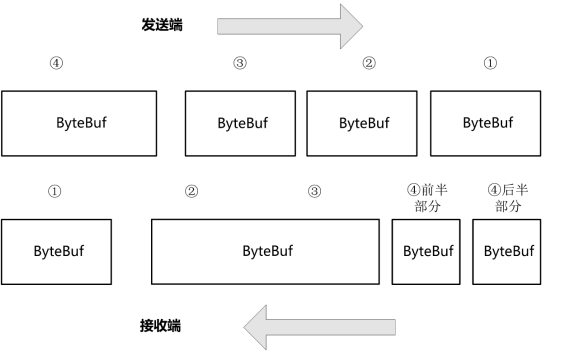
粘包和半包现象(②和③为粘包,④为半包)
半包问题的根因分析
粘包和半包的来源得从操作系统底层说起。
底层网络是以二进制字节报文的形式来传输数据的。读数据的过程大致为:当IO可读时,Netty会从底层网络将二进制数据读到ByteBuf缓冲区中,再交给Netty程序转成Java POJO对象。写数据的过程大致为:编码器将一个Java类型的数据转换成底层能够传输的二进制ByteBuf缓冲数据。
在发送端Netty的应用层进程缓冲区中,程序以ByteBuf为单位来发送数据,但是到了底层操作系统内核缓冲区,底层会按照协议的规范对数据包进行二次封装,封装成传输层的协议报文,再进行发送。在接收端收到传输层的二进制包后,首先复制到内核缓冲区,Netty读取ByteBuf时才复制到应用的用户缓冲区。
在接收端,当Netty程序将数据从内核缓冲区复制到用户缓冲区的ByteBuf时,问题来了:
(1)每次读取底层缓冲的数据容量是有限制的,当TCP内核缓冲区的数据包比较大时,可能会将一个底层包分成多次ByteBuf进行复制,进而造成用户缓冲区读到的是半包。
(2)当TCP内核缓冲区的数据包比较小时,一次复制的是不止一个内核缓冲区包,进而会造成用户缓冲区读到粘包。
如何解决呢?基本思路是,在接收端,Netty程序需要根据自定义协议将读取到的进程缓冲区ByteBuf在应用层进行二次组装,重新组装应用层的数据包。接收端的这个过程通常也称为分包或者拆包。
在Netty中分包的方法主要有以下两种:
(1)可以自定义解码器分包器:基于ByteToMessageDecoder或者ReplayingDecoder,定义自己的用户缓冲区分包器。
(2)使用Netty内置的解码器。例如,可以使用Netty内置的LengthFieldBasedFrameDecoder自定义长度数据包解码器对用户缓冲区ByteBuf进行正确的分包。
使用JSON协议通信
JSON协议是一种文本协议,易于人阅读和编写,同时也易于机器解析和生成,并能有效地提升网络传输效率。
JSON的核心优势
JSON的语法格式和清晰的层次结构非常简单,明显要比XML容易阅读,并且在数据交换方面JSON所使用的字符要比XML少得多,可以大大节约传输数据所占用的带宽。
JSON序列化与反序列化开源库
Java处理JSON数据有三个比较流行的开源类库:阿里巴巴的FastJson、谷歌的Gson和开源社区的Jackson。
在实际开发中,目前主流的策略是Gson和FastJson结合使用。
- 在POJO序列化成JSON字符串的应用场景下,使用谷歌的Gson库;
- 在JSON字符串反序列化成POJO的应用场景下,使用阿里巴巴的FastJson库。
JSON序列化与反序列化的实战案例
JSON传输的编码器和解码器
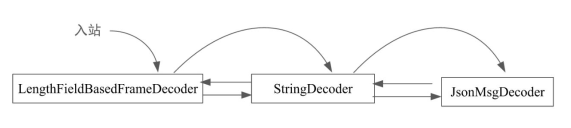
JSON格式Head-Context数据包的解码过程:
JSON格式Head-Content数据包的编码过程:
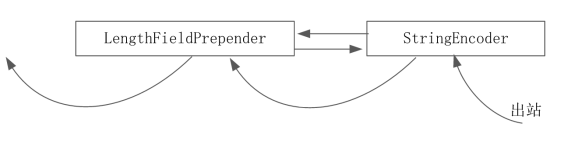
Netty内置LengthFieldPrepender编码器的作用是在数据包的前面加上内容的二进制字节数组的长度。这个编码器和LengthFieldBasedFrameDecoder解码器是天生的一对,常常配套使用。这组"天仙配"属于Netty所提供的一组非常重要的编码器和解码器,常常用于Head-Content数据包的传输。
JSON传输的服务端的实战案例
JSON传输的客户端的实战案例
使用Protobuf协议通信
Protobuf(Protocol Buffer)是Google提出的一种数据交换格式,是一套类似JSON或者XML的数据传输格式和规范,用于不同应用或进程之间的通信。Protobuf具有以下特点:
(1)语言无关,平台无关
(2)高效
(3)扩展性、兼容性好
Protobuf既独立于语言又独立于平台。Google官方提供了多种语言的实现:Java、C#、C++、GO、JavaScript和Python。
Protobuf的编码过程为:使用预先定义的Message数据结构将实际的传输数据进行打包,然后编码成二进制的码流进行传输或者存储。Protobuf的解码过程刚好与编码过程相反:将二进制码流解码成Protobuf自己定义的Message结构的POJO实例。
Protobuf更加适合于高性能、快速响应的数据传输应用场景。Protobuf数据包是一种二进制格式,相对于文本格式的数据交换(JSON、XML)来说,速度要快很多。Protobuf优异的性能使得它更加适用于分布式应用场景下的数据通信或者异构环境下的数据交换。
在一个需要大量数据传输的应用场景中,数据量很大,选择Protobuf可以明显地减少传输的数据量和提升网络IO的速度。对于打造一款高性能的通信服务器来说,Protobuf传输协议是最高性能的传输协议之一。微信的消息传输就采用了Protobuf协议。
一个简单的proto文件的实战案例
Protobuf使用proto文件来预先定义的消息格式。数据包按照proto文件所定义的消息格式完成二进制码流的编码和解码。proto文件简单地说就是一个消息的协议文件,这个协议文件的后缀文件名为".proto"。
举例如下:
//[开始头部声明]
syntax = "proto3";
packagecom.crazymakercircle.netty.protocol;
//[结束头部声明]
//[开始 Java选项配置]
option java_package = "com.crazymakercircle.netty.protocol";
option java_outer_classname = "MsgProtos";
//[结束 Java选项配置]
//[开始消息定义]
message Msg {
uint32 id = 1; //消息ID
string content = 2; //消息内容
}
//[结束消息定义]在.proto文件的头部声明中,需要声明一下所使用的Protobuf协议版本,示例中使用的是"proto3"版本。默认的协议版本为"proto2"。
Protobuf支持很多语言,所以它为不同的语言提供了一些可选的配置选项,使用option关键字。option java_package选项的作用为:
将生成的Java代码放入该选项所指定的package类路径中。option java_outer_classname选项的作用为:在生成proto文件所对应的Java代码时,生成的Java外部类使用配置的名称。
在proto文件中,使用message关键字来定义消息的结构体。在生成proto对应的Java代码时,每个具体的消息结构体将对应于一个最终的Java POJO类。结构体的字段(Field)对应到POJO类的属性(Attribute)。也就是说,每定义一个message结构体相当于声明一个Java中的类。proto文件的message可以内嵌message,就像Java的内部类一样。
每个消息结构体可以有多个字段。定义一个字段的格式为"类型名称 = 编号"。例如,"string content = 2;"表示该字段是String类型,字段名为content,编号为2。字段编号表示在Protobuf数据包的序列化、反序列化时该字段的具体排序。
在一个proto文件中可以声明多个message,大部分情况下会把存在依赖关系或者包含关系的message结构体写入一个proto文件,将那些没有关系、相互独立的message结构体分别写入不同的文件,这样便于管理。
通过控制台命令生成POJO和Builder
下载Protobuf安装包,使用命令:
bash
protoc.exe --java_out=./src/main/java/ ./Msg.proto通过Maven插件生成POJO和Builder
使用protobuf-maven-plugin插件可以非常方便地生成消息的POJO类和Builder(构造者)类的Java代码。
xml
<plugin>
<groupId>org.xolstice.maven.plugins</groupId>
<artifactId>protobuf-maven-plugin</artifactId>
<version>0.5.0</version>
<extensions>true</extensions>
<configuration>
<!--proto文件路径-->
<protoSourceRoot>${project.basedir}/protobuf</protoSourceRoot>
<!--目标路径-->
<outputDirectory>${project.build.sourceDirectory}</outputDirectory>
<!--设置是否在生成java文件之前清空outputDirectory的文件-->
<clearOutputDirectory>false</clearOutputDirectory>
<!--临时目录-->
<temporaryProtoFileDirectory>${project.build.directory}/protoc-temp</temporaryProtoFileDirectory>
<!--protoc 可执行文件路径-->
<protocExecutable>${project.basedir}/protobuf/protoc3.6.1.exe</protocExecutable>
</configuration>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>test-compile</goal>
</goals>
</execution>
</executions>
</plugin>Protobuf序列化与反序列化的实战案例
1、使用Builder构造POJO消息对象
2、序列化与反序列化的方式一
java
//第1种方式:序列化 serialization & 反序列化 Deserialization
@Test
public void serAndDesr1() throws IOException
{
MsgProtos.Msg message = buildMsg(1,"疯狂创客圈-高并发发烧友圈子");
//将Protobuf对象,序列化成二进制字节数组
byte[] data = message.toByteArray();
//可以用于网络传输,保存到内存或外存
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
outputStream.write(data);
data = outputStream.toByteArray();
//二进制字节数组,反序列化成Protobuf 对象
MsgProtos.Msg inMsg = MsgProtos.Msg.parseFrom(data);
Logger.info("devId:=" + inMsg.getId());
Logger.info("content:=" + inMsg.getContent());
}这种方式类似于普通Java对象的序列化,适用于很多将Protobuf的POJO序列化到内存或者外存(如物理硬盘)的应用场景。
3、序列化与反序列化的方式二
java
//第2种方式:序列化 serialization & 反序列化 Deserialization
@Test
public void serAndDesr2() throws IOException
{
MsgProtos.Msg message = buildMsg();
//序列化到二进制流
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
message.writeTo(outputStream);
ByteArrayInputStream inputStream = new ByteArrayInputStream(outputStream.toByteArray());
//从二进流,反序列化成Protobuf 对象
MsgProtos.Msg inMsg = MsgProtos.Msg.parseFrom(inputStream);
Logger.info("devId:=" + inMsg.getId());
Logger.info("content:=" + inMsg.getContent());
}在阻塞式的二进制码流传输应用场景中,这种序列化和反序列化的方式是没有问题的。例如,可以将二进制码流写入阻塞式的JavaOIO套接字或者输出到文件。但是,这种方式在异步操作的NIO应用场景中存在粘包/半包的问题。
4. 序列化与反序列化的方式三
java
//第3种方式:序列化 serialization & 反序列化 Deserialization
//带字节长度:[字节长度][字节数据],解决粘包问题
@Test
public void serAndDesr3() throws IOException
{
MsgProtos.Msg message = buildMsg();
//序列化到二进制流
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
message.writeDelimitedTo(outputStream);
ByteArrayInputStream inputStream = new ByteArrayInputStream(outputStream.toByteArray());
//从二进流,反序列化成Protobuf 对象
MsgProtos.Msg inMsg = MsgProtos.Msg.parseDelimitedFrom(inputStream);
Logger.info("devId:=" + inMsg.getId());
Logger.info("content:=" + inMsg.getContent());
}这种方式用于异步操作的NIO应用场景中,解决了粘包/半包的问题。
Protobuf编解码的实战案例
Netty默认支持Protobuf的编码与解码,内置了一套基础的Protobuf编码和解码器。
Netty内置的Protobuf基础编码器/解码器
1、ProtobufEncoder编码器
ProtobufEncoder的实现逻辑非常简单,直接调用了Protobuf POJO实例的toByteArray()方法将自身编码成二进制字节,然后放入Netty的ByteBuf缓冲区中,接着会被发送到下一站编码器。
2、ProtobufDecoder解码器
ProtobufDecoder和ProtobufEncoder相互对应,只不过在使用的时候ProtobufDecoder解码器需要指定一个Protobuf POJO实例作为解码的参考原型(prototype)。
3、ProtobufVarint32LengthFieldPrepender长度编码器
这个编码器的作用是在ProtobufEncoder生成的字节数组之前前置一个varint32数字,表示序列化的二进制字节数量或者长度。
4、ProtobufVarint32FrameDecoder长度解码器
rotobufVarint32FrameDecoder和ProtobufVarint32LengthFieldPrepender相互对应,其作用是根据数据包中长度域(varint32类型)中的长度值解码一个足额的字节数组,然后将字节数组交给下一站的解码器ProtobufDecoder。
什么是varint32类型的长度?Protobuf为什么不用int这种固定类型的长度?
varint32是一种紧凑的表示数字的方法,不是一种固定长度(如32位)的数字类型。varint32用一个或多个字节来表示一个数字,值越小,使用的字节数越少,值越大使用的字节数越多。varint32根据值的大小自动进行收缩,能够减少用于保存长度的字节数。也就是说,varint32与int类型的最大区别是:varint32用一个或多个字节来表示一个数字,int是固定长度的数字。varint32不是固定长度,所以
为了更好地减少通信过程中的传输量,消息头中的长度尽量采用varint格式。
Protobuf传输的服务端的实战案例
Protobuf传输的客户端的实战案例
详解Protobuf协议语法
在Protobuf中,通信协议的格式是通过proto文件定义的。一个proto文件有两大组成部分:头部声明、消息结构体的定义。头部声明部分主要包含了协议的版本、包名、特定语言的选项设置等;消息结构体部分可以定义一个或者多个消息结构体。
proto文件的头部声明
- syntax版本号
- package包
- option配置选项
Protobuf的消息结构体与消息字段
定义一个Protobuf消息结构体的关键字为message。一个消息结构体由一个或者多个消息字段组合而成。
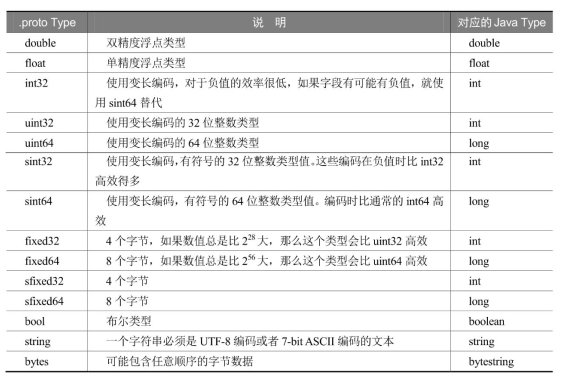
Protobuf字段的数据类型
Protobuf定义了一套基本数据类型,但是这些数据类型几乎都可以对应到C++/Java等语言的基本数据类型。
proto文件的其他语法规范
- 声明
- 嵌套消息
- 枚举