
👨💻程序员三明治 :个人主页
🔥 个人专栏 : 《设计模式精解》 《重学数据结构》
🤞先做到 再看见!
以User对象来举例
我们定义一个User类,并在main方法中创建一个user对象,名字是codesandwich,年龄是18岁:
java
public class User {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
public class Main {
public static void main(String[] args) {
User user = new User();
user.setName("codesandwich");
user.setAge(18);
}
}现在,当我么希望下一次程序重启的时候,我们希望仍然能保存这个对象,那么有几种方式呢?
- 把user对象插入到MySQL对应的user表中,下次我们直接连接数据库就可以查询来获取
- 我们可以创建一个文件,把这个user对象保存到文件中,下次重启,就从那个文件中读取出来
这两种方式的共同点?
- 我们都需要与我们程序之外的东西进行交互,比如和MySQL进行交互,我们都知道,计算机在网络交互的时候都是传输的字节,不可能直接把user对象传给数据库
- 我们把user对象变成一个json文件,文件格式如下
json
{
"name": "codesandwich",
"age": 18
}这两种方式本质都是传输的字节数组,或者说字节流,那么我们读取到name的时候,我们会根据字节流读取到的数据,根据编码转换为我们需要的字符。
序列化本质上就是把一个对象或者把一个结构化的内容转为字节
同理,反序列化就是把字节转为我结构化对象。
如何把对象转为字节数组?
比如说可以用fast JSON把对象转为json
java
public class Main {
public static void main(String[] args) throws IOException {
User user = new User();
user.setName("codesandwich");
user.setAge(18);
// 序列化
String jsonString = JSONObject.toJSONString(user);
File file = new File("user.json");
Files.write(file.toPath(), jsonString.getBytes());
System.out.println(file.length());
}
}我们可以看到文件的长度为32,那就是说,这个json文件有26个字节
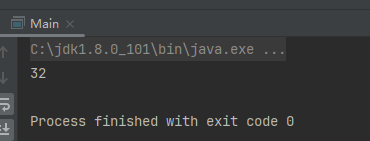
那反序列化怎么做呢?
java
public class Main {
public static void main(String[] args) throws IOException {
User user = new User();
user.setName("codesandwich");
user.setAge(18);
// 序列化
String jsonString = JSONObject.toJSONString(user);
File file = new File("user.json");
Files.write(file.toPath(), jsonString.getBytes());
System.out.println(file.length());
// 反序列化
byte[] bytes = Files.readAllBytes(file.toPath());
User user1 = JSONObject.parseObject(new String(bytes, "UTF-8"), User.class);
System.out.println(user1);
}
}运行结果
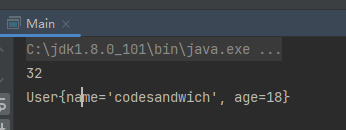
可以看到,用json持久化到我们文件中之后,文件的长度是26,那么我们可不可以更换一个序列化的协议,比如说我们不用json,我们用其他的方式,用更少的空间来达到同样的效果,因为我们的目的就是把我们的对象存储在我们的文件中,同时我们可以通过读取文件,把文件中的内容读取成我们的对象
其次,因为我们的json文件,它存储的并不一定是我们的user对象,此时如果我创建另一个类,比如说我创建一个学生类,他也有名字和年龄,我们可以通过反序列化把它变成另一个类,而不一定把他变成一个User类。那么如果我们需要再JSON里面记录这一条数据最终到底是归属于哪个类的,那我们可能在json里面还需要增加一个属性
java
{
"name": "codesandwich",
"age": 18,
"class" "org.serializer.User"
}现在我们尝试将user对象用另一种序列化方式持久化到我们的磁盘上,让我们可以达到用更少的空间换取相同的效果
java
public class Main {
public static void main(String[] args) throws IOException {
User user = new User();
user.setName("codesandwich");
user.setAge(18);
// 自定义序列化
byte[] userBytes = serializeUser(user);
File file = new File("user.ss");
Files.write(file.toPath(), userBytes);
System.out.println(file.length());
// 自定义反序列化
byte[] readAllBytes = Files.readAllBytes(file.toPath());
User deUser = deserializeUser(readAllBytes);
System.out.println(deUser);
}
private static byte[] serializeUser(User user) {
String name = user.getName();
byte[] nameBytes = name.getBytes();
ByteBuffer byteBuffer = ByteBuffer.allocate(Integer.BYTES + nameBytes.length);
byteBuffer.putInt(user.getAge());
byteBuffer.put(nameBytes);
return byteBuffer.array();
}
private static User deserializeUser(byte[] bytes) {
ByteBuffer byteBuffer = ByteBuffer.wrap(bytes);
int age = byteBuffer.getInt();
byte[] nameBytes = new byte[byteBuffer.remaining()];
byteBuffer.get(nameBytes);
User user = new User();
user.setAge(age);
user.setName(new String(nameBytes, StandardCharsets.UTF_8));
return user;
}
}运行main函数之后,可以看到user.ss文件中的内容如下
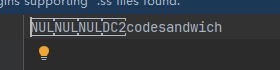
那这个文件和json文件有什么区别?
这个文件的长度是16,比json文件长度小了很多,是紧凑的
假如说我们再存储一个user,那我们读取文件首先读取四个字节,这是我们第一个user的年龄,然后我们再读取剩下的所有字节,然后把它变成一个字符串,这样明显是不对的,所以当我们遇到变长的属性的时候,比如说字符串就是一个变长的属性,那么我们可以在这个字符串前面增加一个数字,表示这个字符串它应该有多长,比如说我们更新一下我们的序列化
java
private static byte[] serializeUser(User user) {
String name = user.getName();
byte[] nameBytes = name.getBytes();
ByteBuffer byteBuffer = ByteBuffer.allocate(Integer.BYTES * 2 + nameBytes.length);
byteBuffer.putInt(user.getAge());
// 添加字符串长度
byteBuffer.putInt(nameBytes.length);
byteBuffer.put(nameBytes);
return byteBuffer.array();
}
private static User deserializeUser(byte[] bytes) {
ByteBuffer byteBuffer = ByteBuffer.wrap(bytes);
int age = byteBuffer.getInt();
int nameLength = byteBuffer.getInt();
byte[] nameBytes = new byte[nameLength];
byteBuffer.get(nameLength);
User user = new User();
user.setAge(age);
user.setName(new String(nameBytes, StandardCharsets.UTF_8));
return user;
}再次执行main函数,可以看到user.ss的长度变为了20,多了4个字节(来存储变长字符串的长度),这样可以让每一个user对象区分开。
Java自带的序列化
修改序列化和反序列化方法
java
public static byte[] serializeUser2(User user) throws IOException {
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream);
objectOutputStream.writeObject(user);
return byteArrayOutputStream.toByteArray();
}
public static User deserializeUser2(byte[] bytes) throws IOException, ClassNotFoundException {
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(bytes);
ObjectInputStream objectInputStream = new ObjectInputStream(byteArrayInputStream);
return (User) objectInputStream.readObject();
}再次运行main函数,发现文件长度达到了93,它比json还要长出非常多

也可以看到,我们的类名也被序列化进去了,所以是因为这样,所以反序列化可以强转为User而不是其他类型。
总结
序列化与反序列化的基本概念
首先,什么是序列化?
序列化,就是将对象的状态转换成字节流的过程,这样以后可以通过这些字节流重新构建具有相同状态的对象。换句话说,序列化是将Java对象转换为便于存储和传输的格式。
我们平时操作的对象大多是在内存中运行的,意味着只要程序终止或断电,内存中的数据就会丢失。而序列化为我们提供了一个"把对象变成字节流"的功能,能把内存中的对象保存到硬盘、数据库或者网络中,也就实现了数据的持久化。
反序列化,则是序列化的逆过程,即将字节流转换回原Java对象,恢复出原来对象的状态和数据。通过反序列化,存储的数据可以再次用于程序的运行。
我们再通过一个例子更好地理解这个过程:
假设你创建了一个Person类的对象:

通过序列化 ,我们把person对象转换成一连串的字节,并将这些字节存储在文件中;当我们想再次使用这个person对象时,通过反序列化的方式,将文件中的字节读取并重建出原始的Person对象。是不是很神奇!
序列化与反序列化的应用场景
1. 数据的持久化
序列化可以将数据以字节流的形式永久存储到硬盘中。比如将对象保存到文件中,或用于缓存(如Redis的RDB备份)。
比如,我们可以将应用中的数据持久化存储到数据库或文件中,下次启动程序时将数据恢复到内存中,就不需要重新初始化数据了。这在数据较大或初始化过程复杂时尤为方便。
2. 对象的网络传输
序列化是远程通信的重要手段。将对象序列化后,可以在网络上传输字节流,接收端再反序列化成原始对象。这是RMI、Web服务等实现网络通信的基础。
例如,微服务架构中,多个系统间的数据传递就可以利用序列化传递对象。序列化的对象字节流不依赖于进程环境,能保证Java对象跨网络传输的完整性。
如何实现序列化与反序列化
在Java中,序列化和反序列化是通过实现 Serializable 接口来完成的。
1. 实现 Serializable 接口
对于一个需要序列化的Java类,必须实现 Serializable 接口:
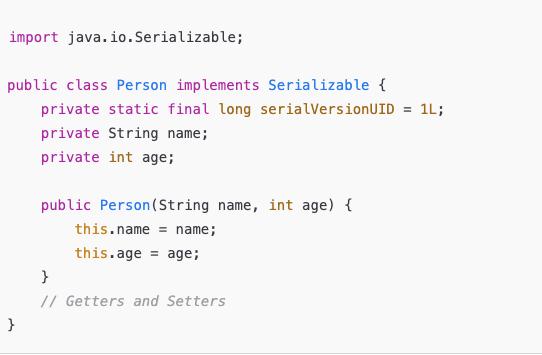
这个接口本身没有任何方法,它只是一个标记接口,用于告诉Java虚拟机这个类可以被序列化。我们也通常会为每个类指定 serialVersionUID,以便在序列化和反序列化过程中保持一致。
2. 使用 ObjectOutputStream 序列化对象
将对象写入文件(序列化)时,可以使用 ObjectOutputStream 类:
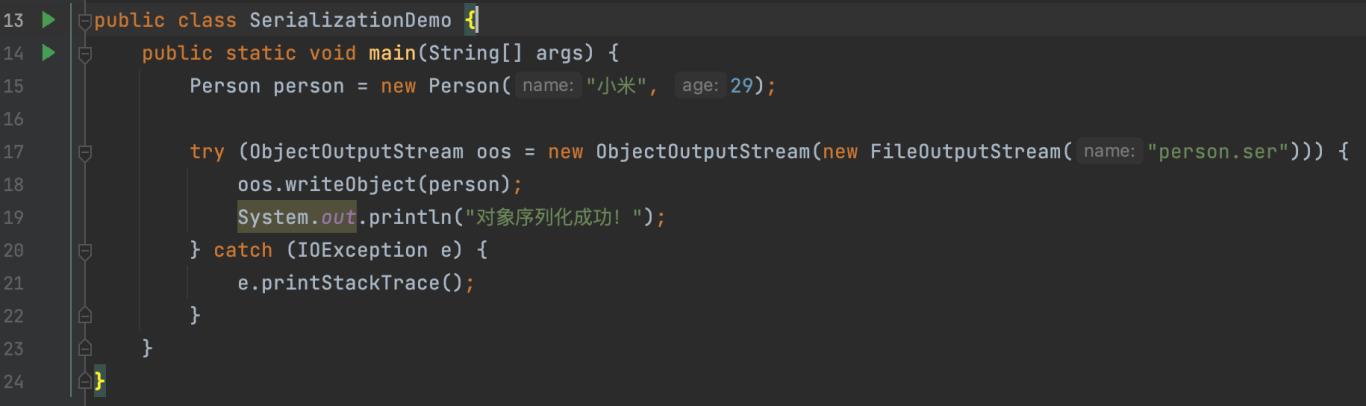
在这个例子中,我们将 person 对象序列化并存储在本地文件 person.ser 中。
3. 使用 ObjectInputStream 反序列化对象
将序列化的文件转换回对象(反序列化)时,可以使用 ObjectInputStream 类:
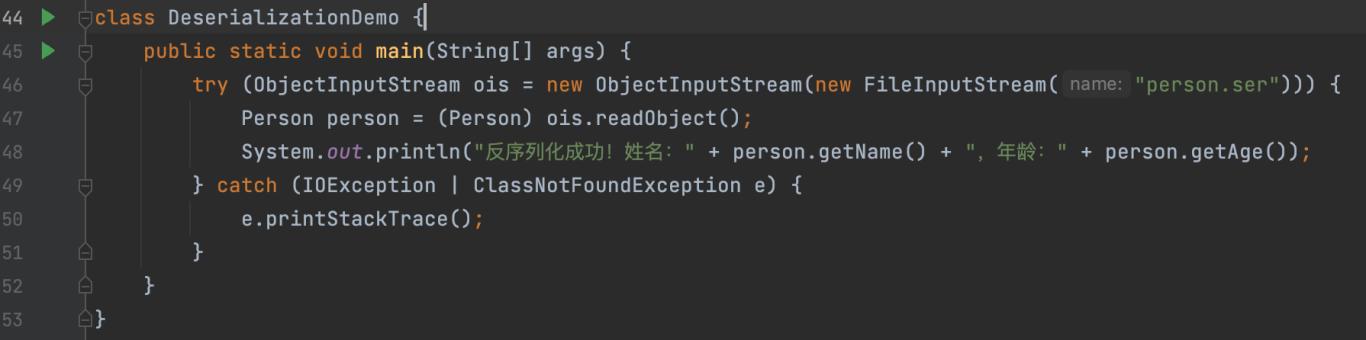
运行这个代码可以将 person.ser 文件反序列化为Person对象,并重新获得其属性值。
序列化与反序列化的优点
- 数据持久化:实现数据的持久化保存,程序重启后可以恢复之前的对象状态。
- 远程通信:使得对象可以在不同的进程间或网络上传输,保证数据在跨平台、跨进程之间的兼容性。
- 缓存:通过序列化将对象缓存到本地文件或内存数据库(如Redis、Memcached)中,读取速度更快。
反序列化失败的原因
在反序列化过程中,有时会遇到反序列化失败的情况,常见的原因之一是:
serialVersionUID 不一致
每个序列化的类都会包含一个 serialVersionUID,它是唯一标识类版本的"身份证"。在反序列化时,Java虚拟机会检查对象的 serialVersionUID 与本地类的 serialVersionUID 是否匹配。如果不一致,Java会抛出 InvalidClassException 异常,表示反序列化失败。
所以,为了保证反序列化的顺利进行,建议在类定义时显式定义 serialVersionUID,例如:

总结:如果你修改了类的结构(比如添加或删除字段),要么重新序列化对象,要么手动设置 serialVersionUID 保持不变。
序列化的最佳实践
- 显式声明 serialVersionUID:避免在类结构改变时导致反序列化失败。
- 避免对敏感数据进行序列化:对于一些敏感信息(如密码),可以使用 transient 关键字声明,防止这些字段被序列化。
- 使用可靠的序列化工具 :在一些高并发场景下,传统的Java序列化效率可能不高,可以考虑使用 Google Protocol Buffers、Kryo、Apache Avro 等更高效的序列化工具。
如果我的内容对你有帮助,请辛苦动动您的手指为我点赞,评论,收藏。感谢大家!!

我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=h70g0sv71wz