- 联系方式:1761430646@qq.com
- 编写时间:2025年8月20日16:09:05
- 博客地址:www.zeroeden.cn
- 菜狗摸索,有误勿喷,烦请联系
1. 概念
1.1 什么是字符集
-
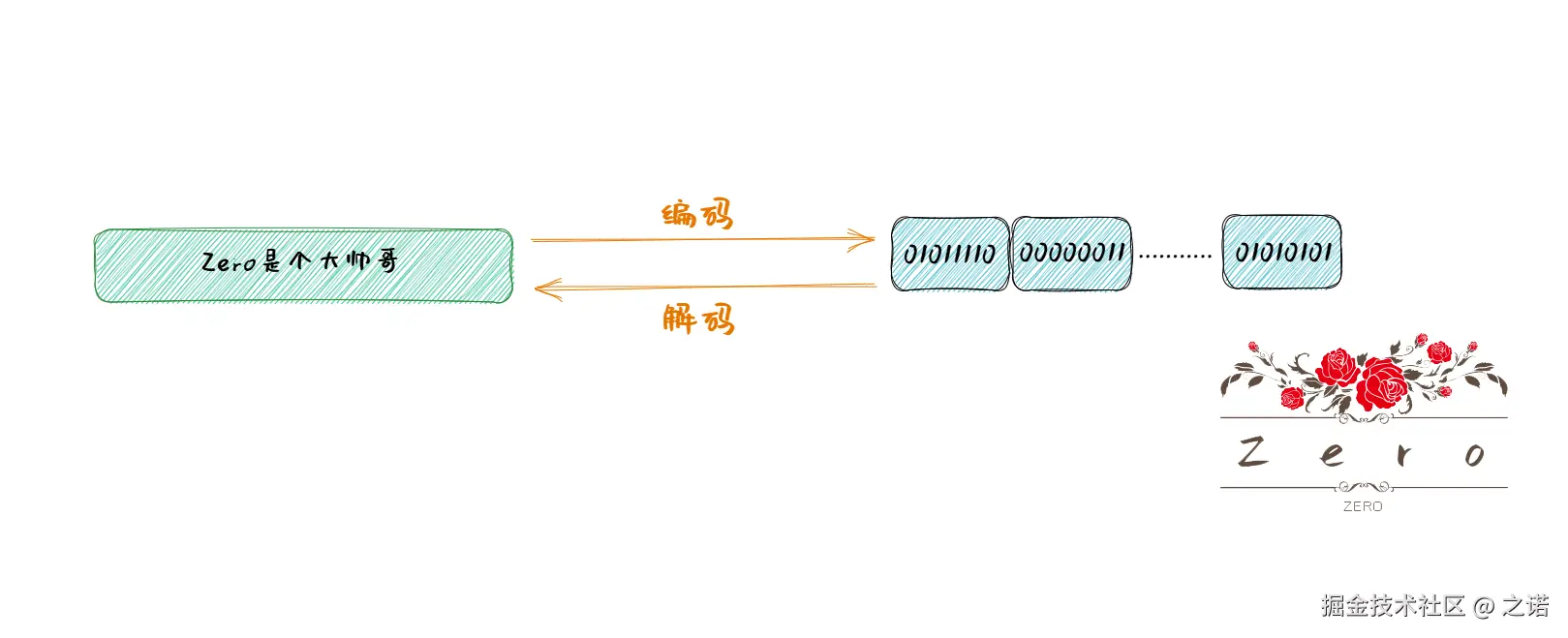
总所周知,计算机是基于二进制存储数据的
-
而我们在电脑上所见到的文字,图片等资源是如何映射到二进制的
-
这就牵扯到本次要谈的字符集
-
字符集本质上可以简单理解为就是
mapping规则 -
有些可以用1
byte就能映射到的,也有些也可能用1~3byte进行映射等等 -
所以
mapping规则是可以有多种,而字符集也是有很多种类的 -
ok,当了解了字符集的概念后,那我们常说的编码,解码则是在指-
编码:将字符映射成二进制数据的过程
-
解码:将二进制数据映射成字符的过程
-
1.2 常见的一些字符集
-
通常来说,后来的字符集默认会兼容以前的字符集,尤其是
ASCII,这种设计理念主要是为了确【向后兼容性】,使得内容或系统能够在新的字符集下正常运行 -
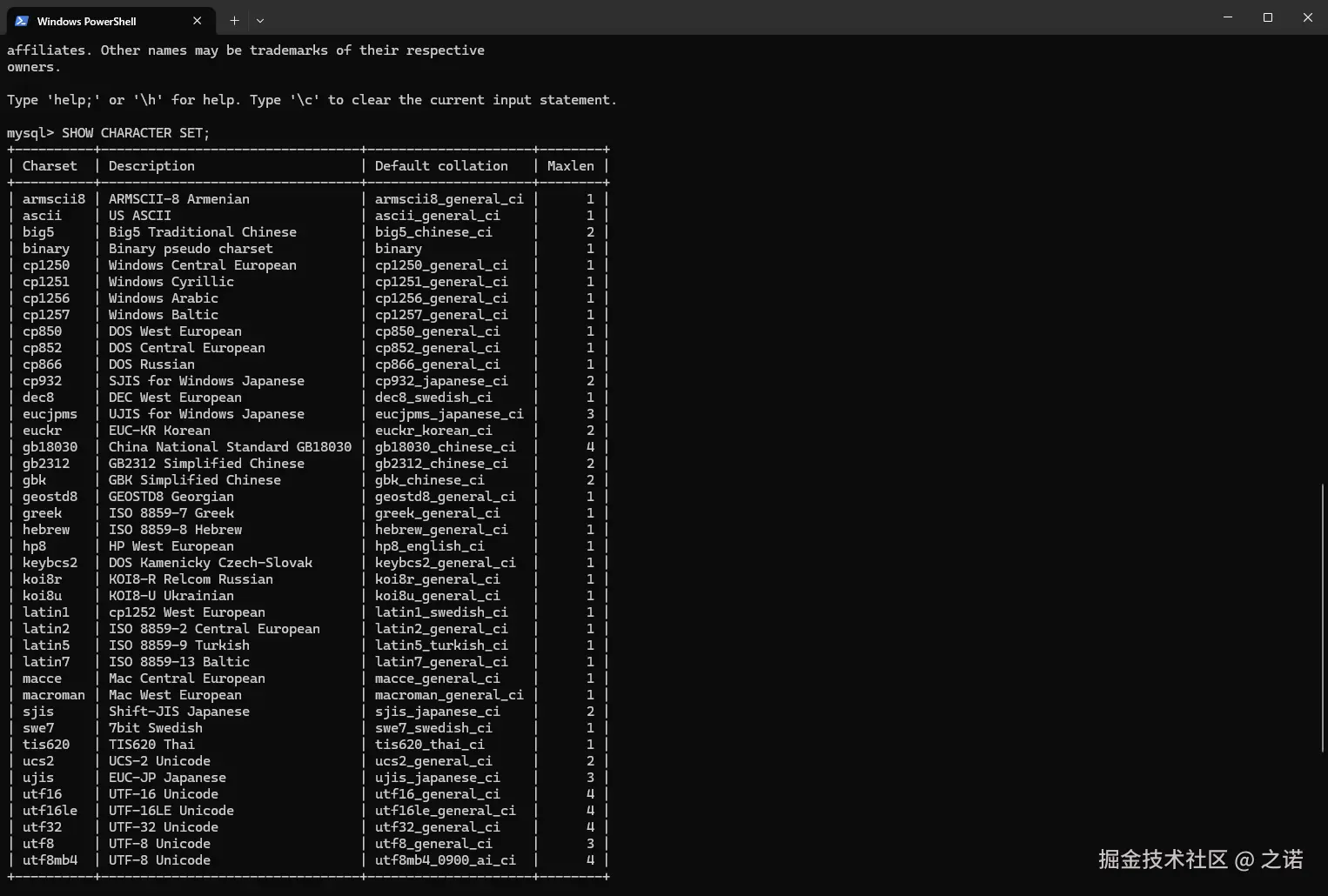
查询语法:
SHOW (CHARACTER SET | CHARSET) [LIKE 匹配的模式];CharsetDescDefault collationMaxlenasciiUS ASCIIascii_general_ci1 gbkGBK Simplified Chinesegbk_chinese_ci2 utf8UTF-8 Unicodeutf8_general_ci3 utf8mb4UTF-8 Unicodeutf8mb4_general_ci4 !!!:表格最后一列的
Maxlen值代表着此字符集的一个字符所占用的最大字节数,并不是固定占用字节数 -
在之前的知识体系中,我们知道标准的
UTF-8字符集采用的是1 ~ 4个byte来表示一个字符 -
但是看到表格中有个
utf8和utf8mb4字符集感觉重复了是不是会很奇怪 -
这其实是
MySQL额外定义了下面的两个概念utf8mb3: "太监"过的UTF-8字符集,使用1~3个byte来表示字符(常见的一些字符用1 ~ 3个就可以表示了),同时在MySQL中,utf8就是utf8mb3的别名(so请注意在讨论MySQL相关知识体系时,谈到utf8要知道它实际上就是代指utf8mb3,是采用1 ~ 3个byte来表示一个字符的)utf8mb4:正宗传统下的UTF-8字符集,使用1-4个byte来表示字符
1.3 字符集的比较规则
- 对于使用同一字符集进行编码解码的两个不同字符
- 如果我们想比较它们二者的大小,其实也可以设定有多种比较方式的
- 比如说通过它们的二进制编码大小比较,也可以比较时忽略了大小写的等等
- 所以这里主要是告诉大家,比较规则有很多,
so比较字符的时候需要明确对应的比较规则
2. Detail
2.1 字符集和比较规则的查看
- 在
MySQL中,每种字符集有对应多种比较规则,且每种字符集都会有设定了默认的一种比较规则
-
查看字符集
-
语法:
SHOW (CHARACTER SET | CHARSET) [LIKE 匹配的模式]; -
Demo:
-
Desc:
Defualt collation表示此字符集默认的比较规则
-
-
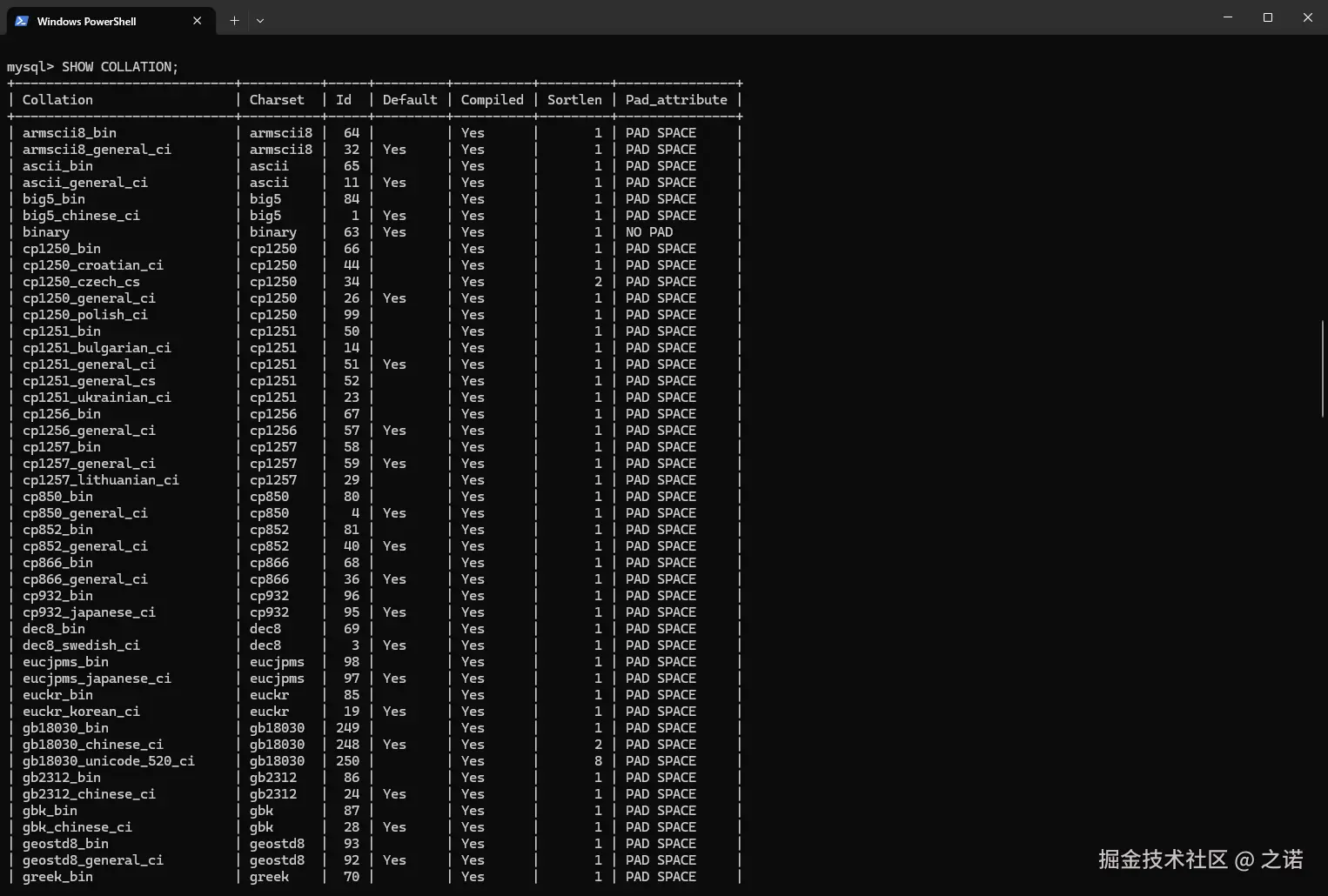
查看比较规则
-
语法:
SHOW COLLATION [LIKE 匹配的模式];(看看会不会忽略大小写这个匹配的模式) -
Demo:
-
Desc:
-
比较规则的名称前缀是以其关联的字符集的名称开头的(Ex:
utf8字符集的比较规则都是以utf8开头的) -
后面紧跟着当前比较规则所应用的语言(Ex:
gneneral表示一种通用的比较规则,roman表示拉丁字母的比较规则) -
后缀代表着当前比较规则是否区分语言中的重音,大小写等
后缀 英文全称 Desc _aiaccent insensitive不区分重音 _asaccent sensitive区分重音 _cicase insensitive不区分大小写 _cscase sensitive区分大小写 _binbinary基于二进制形式进行比较
-
-
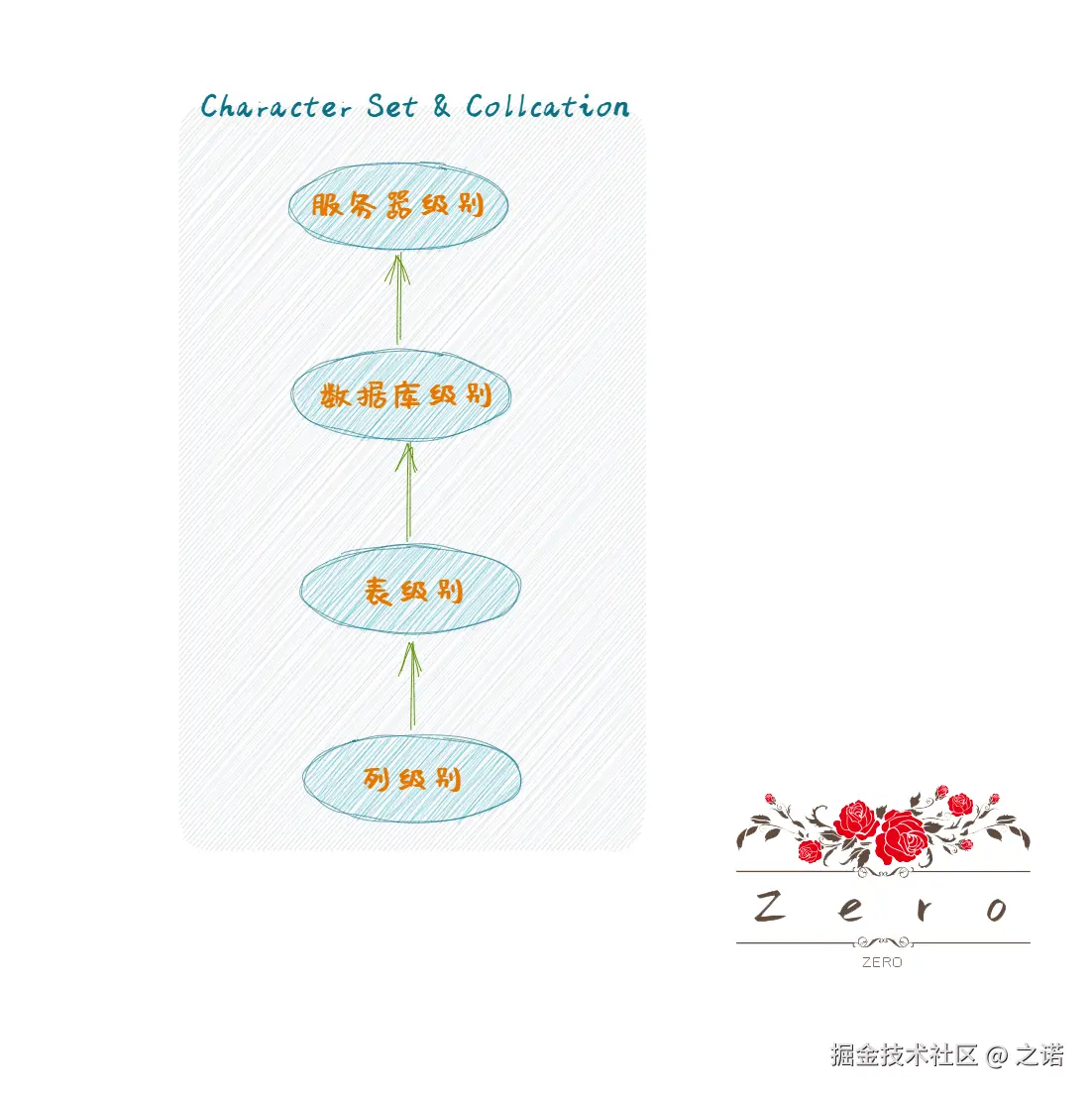
2.2 4个级别的字符集和比较规则
- 在
MySQL服务端中,分成了4种级别的字符集和比较规则,分别是【服务器级别】,【数据库级别】,【表级别】,【列级别】
2.2.1 服务器级别
-
该级别会对整个
MySQL服务生效 -
MySQL提供了两个系统变量用来查看服务器基本的字符集和比较规则character_set_server:服务器级别的字符集collation_server:服务器级别的比较规则
-
若想改变这两个系统变量的值,可以在启动
MySQL服务前,通过更改MySQL配置文件对应配置项值来实现ini[server] character_set_server=utf8 collation_server=utf8_general_ci
2.2.2 数据库级别
-
该级别只会针对对应
database的字符集和比较规则生效,不会影响到其他的database -
可以在创建/更改
database的时候指定database的字符集和比较规则sql-- Create CREATE DATABASE 数据库名 [[DEFAULT] CHARACTER SET 字符集名称] [[DEFAULT] COLLATE 比较规则名称]; -- Alter ALTER DATABASE 数据库名 [[DEFAULT] CHARACTER SET 字符集名称] [[DEFAULT] COLLATE 比较规则名称]; -
MySQL提供了两个系统变量用来查看当前数据库所使用的字符集和比较规则(需要先使用USE语句选中进入当前的数据库)character_set_database:当前数据库的字符集collation_database:当前数据库的比较规则
2.2.3 表级别
-
该级别只会针对当前表的字符集和比较规则生效,不会影响到其他的表
-
可以在创建/更改表时指定对应的字符集和比较规则
sql-- Create CREATE TABLE 表名 (列的信息) [[DEFAULT] CHARACTER SET 字符集名称] [COLLATE 比较规则名称]; -- Alter ALTER TABLE 表名 [[DEFAULT] CHARACTER SET 字符集名称] [COLLATE 比较规则名称];
2.2.4 列级别
-
对于字符串而言,同一个表中不同的列也可以有不同的字符集和比较规则
-
可以在创建/更改列的时候指定对应的字符集和比较规则
sql-- Create CREATE TABLE 表名( 列名 字符串类型 [CHARACTER SET 字符集] [COLLATE 比较规则名称], 其他列... ); -- Alter ALTER TABLE 表名 MODIFY 列名 字符串类型 [CHARACTER SET 字符集名称] [COLLATE 比较规则名称];!!!: 在更改列的字符集时,如果列中存储的数据不能用更改后的字符集进行表示的话,则会发生错误,需要进行兼容(Ex:假设一开始使用
utf8存储了汉字,后续字符集更改为ASCII,由于ASCII不支持存储汉字,则会发生错误) -
在知道了列级别对应的字符集后,其实我们就可以很快计算出某个列存储的实际数据所占用的存储空间大小了
- 假设当前列采用的是
utf32字符集,也就是一个字符固定采用 4个字节来存储 - 对于值为
你好吗,这是实际采用了3 * 4 = 12个字节来存储
- 假设当前列采用的是
-
也有些比较特殊的,比如说像
utf8字符集,因为它是采用可变长编码方式,每个字符的字节数是不固定的,需要取决于字符本身的范围你好吗:对于这个值的每个汉字在Unicode编码下都是采用3个字节来表示的,所以总占用字节数为3 * 3 = 9zero是我:zero中的每个英文在Unicode编码下都是采用1个字节来表示,再加上中文是我,所以总占用字节数为1 * 4 + 3 * 2 = 10
2.2.5 规则
-
可以看到,这四个级别的层级关系是逐渐向下的,它们之间的关系有点类似于面向对象语言中的继承关系-就近优先原则
-
当创建/修改列的时候如果没有显示指定字符集和比较规则,则默认会用当前表所使用的字符集和比较规则
-
当创建/修改表的时候如果没有显示指定字符集和比较规则,则默认会用当前数据库所使用的字符集和比较规则
-
当创建/修改
database的时候如果没有显示指定字符集和比较规则,则默认会用当前服务器的字符集和比较规则
-
-
同时 ,字符集和比较规则之间的关系是相互关联的,不会说
gbk的字符集会出现一个utf8_general_ci的比较规则 -
所以
- 如果只修改了字符集,比较规则也会跟着变化(变更为前文中提到的当前字符集下设定的默认比较规则)
- 如果只修改了比较规则,字符集也会跟着变化(变更为对应前缀的字符集)
2.3 客户端与服务器通信交互过程中字符集的转换
2.3.1 潦草
- 先按照我们的常识构造个草图了解下通信交互过程中需要牵扯到的几个对象
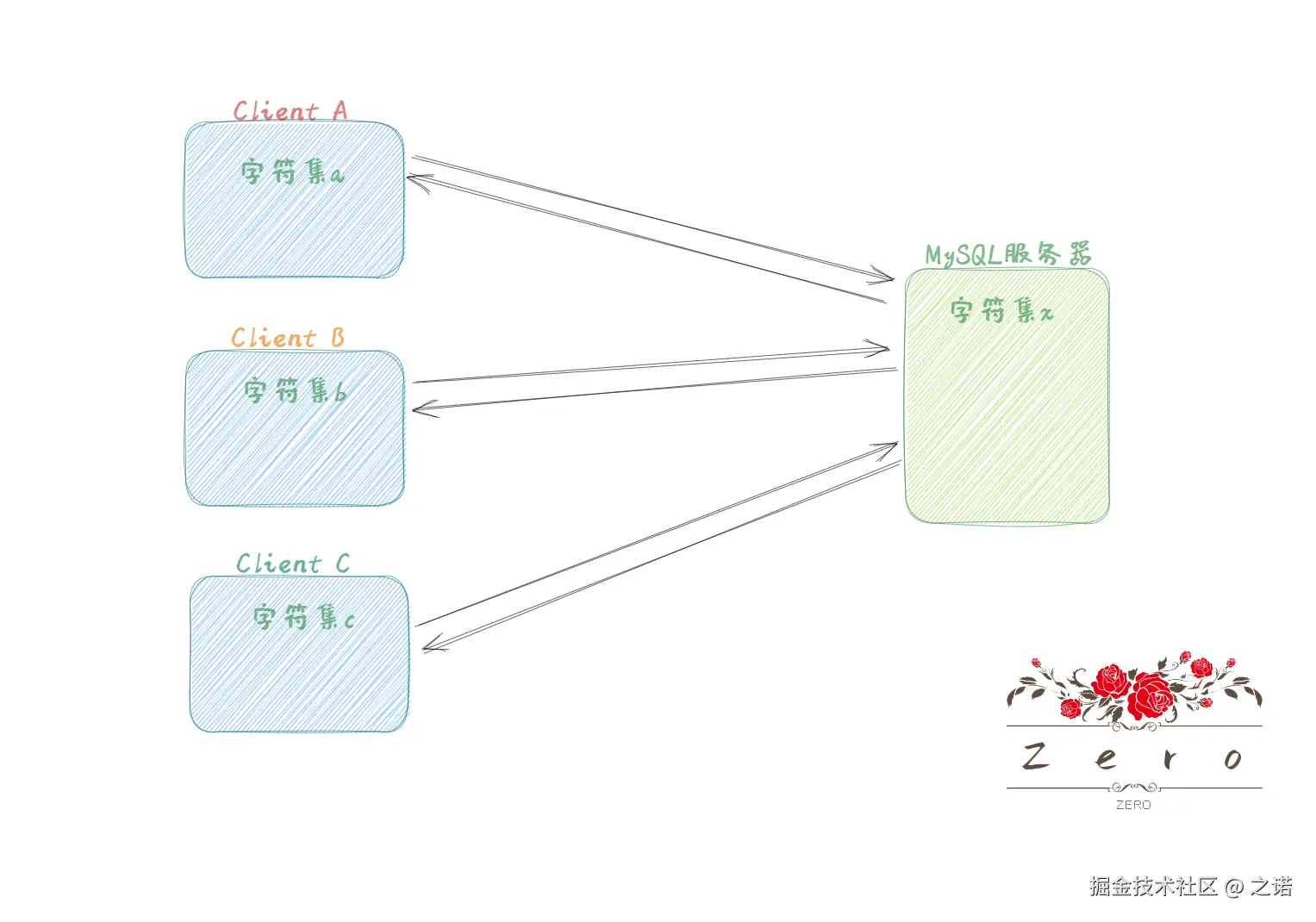
-
可以从上述了解到,客户端在与
MySQL服务器进行通信时 -
不同客户端本身设定的字符集可以是不一致,有多个种类的
-
客户端与
MySQL服务器建立起session后,在每个session中服务器会维护个单独的字符集(上图并未完全表现出来)用来解码(因为不同客户端用来编码的字符集是五花八门的) -
当然,上述描述的其实是一个不完全版的,先手帮助理解的交互过程摆了,让我们基本认识到客户端的命令字符串是经过对应字符集编码后再传给服务器,然后服务器再通过对应字符集进行解码得到原始的命令字符串才进行处理,下面则是完整版的通信交互细节
2.3.2 详细!!!
-
客户端启动时默认的字符集跟当前操作系统有关
windows系统:默认为当前操作系统设定的字符集- 类
unix系统:系统变量LC_ALL-->LC_CTYPE-->LANG设定的字符集 --> 当前操作系统设定的字符集(排在越前面,优先级别越高)
-
windows系统也可以在启动时通过default-character-set选项来设定字符集(就近原则,优先级别最高) -
客户端与服务器建立起连接,也就是建立起
session后 -
假定客户端发送了某个查询字符串的请求,这条查询字符串会通过客户端中设定的字符集A进行编码,形成一条二进制字节序列
-
所以此时服务器在这个
session中最初得到的这个请求也是这条二进制字节序列 -
服务端会在这个
session中通过维持一个单独的叫做character-set-client系统变量,用来 "认为" 客户端编码采用的是字符集B -
所以此时服务端使用这个字符集B进行解析解码得到原本的查询字符串
- 通常来说来说字符集A和字符集B应该是一致的,比如说都是
utf8mb4,那么此时解码就没啥问题 - 但也有可能会出现不一致的情况,比如字符集A是
utf-8,而字符集B是ascii,此时解码服务器就会发出warning
- 通常来说来说字符集A和字符集B应该是一致的,比如说都是
-
那么现在得到了这个查询字符串就开始处理了吗?
-
并不是的
-
此时服务端的这个
session还会通过session级别的系统变量character-set-connection对应的字符集C进行编码成新的字节序列-
是不是很奇怪为什么还会有新的字符集C用来进行新的编码,是不是有点多次一举
-
要知道字符集B的作用其实是用来保证解码二进制字节序列能够完好的得到原始的查询字符串,简单来说就是编码解码的字符集是同一个(所以一般字符集A=字符集B)
-
那为啥还要新的字符集C来进行编码呢
-
前文中提到,每个字符集会含有多种比较规则,对应一个默认的比较规则
-
所以假定查询语句为:
select 'a' = 'A'- 如果字符集C的比较规则为
_ci结尾的,也就是不区分大小写,那么结果是ture - 但如果字符集C的比较规则为
_bin/_cs结尾的,也就是通过二进制比较/区分大小写,那么结果是false
- 如果字符集C的比较规则为
-
可以看到,设定不同的字符集比较规则,会得到完全不一致的结果
- 这个
session级别的character-set-connection系统变量对应的字符集C,有个与之配套的也是session级别的系统变量collation_connection用来设定这个字符集C对应的比较规则
- 这个
-
就有点类似于计算机总喜欢加多一层进行抽象用来解决问题的感觉,这个字符集C相当于
MySQL提供了一种【可扩展】方式用来帮助用户实现更加灵活的自定义比较规则(个人理解,有错勿喷)
-
-
跟列对应设定的字符集相比
- 前文中提到有个【列级别】的字符集D和比较规则表示值实际的存储字符集和比较规则
- 要是这个【列级别】的字符集D跟上述的字符集C不一致或者比较规则不一致怎么办?
- 其实这时候
MySQL规定, 【列级别】的字符集D和对应的比较规则其优先级别最高 - 也就是真不一致的话,还会【列级别】的字符集D进行新的编码转化,再用与之对应的比较规则进行比较
-
-
然后服务端进行处理,得到了真正的查询结果字符串
-
在响应给客户端时,此时依旧也会通过一个
session级别的系统变量character_set_results对应的字符集E进行编码得到二进制字节序列再进行返回 -
客户端收到二进制序列后,进行解码从而进行输出
windows系统采用客户端设定的默认字符集解析解码- 类
unix系统一般采用当前操作系统使用的字符集进行解码
-
完结撒花
-
流程描述(
GPT生成):css┌──────────────────────────────────────────────┐ │ Client 客户端(如 mysql 命令) │ │ │ │ ① 根据系统 locale 或启动参数决定字符集 A │ │ • Windows 默认 = 系统代码页 (如 GBK / cp1252) │ │ • Linux 默认 = LANG 中的编码 (如 UTF-8) │ │ • 可用 --default-character-set 覆盖 │ │ │ │ ② 把查询字符串编码为 字节序列 (A 编码) │ └─────────────────┬────────────────────────────┘ │发送字节流(二进制) ▼ ┌──────────────────────────────────────────────┐ │ MySQL Server 服务器 │ │ │ │ ③ 会话建立后有会话变量: │ │ • character_set_client = B (默认 latin1) │ │ │ │ ④ 服务端用字符集 B 解码收到的字节流 → 得到 │ │ 原始 SQL 字符串 │ │ ※ 如果 A ≠ B,会报 warning │ │ │ │ ⑤ 解码得到字符串后,内部可能进行 re-encode: │ │ • 使用 character_set_connection = C │ │ • 对应比较规则 collation_connection │ │ │ │ → 这一层用于比较、排序、WHERE判断 │ │ (如 select 'a'='A' 在 _ci / _bin 不同) │ │ │ │ ⑥ 实际执行 SQL → 读取表中列数据 │ │ • 列的数据已保存为 字符集D(列级字符集) │ │ • 如果 D ≠ C,则再进行一次转码再比较 │ │ • 列级字符集和collation优先级最高 │ │ │ │ ⑦ 得出结果字符串,准备返回 │ │ │ │ ⑧ 用 character_set_results = E 再次编码结果串 │ │ → 变成字节序列发送回客户端 │ └─────────────────┬────────────────────────────┘ │字节流发回客户端 ▼ ┌──────────────────────────────────────────────┐ │ Client 客户端收到字节数据 │ │ │ │ ⑨ 客户端使用字符集 A 解码字节流并显示 │ │ • Windows 用默认代码页 或指定解码方式 │ │ • Linux 通常依赖系统 locale │ └──────────────────────────────────────────────┘ (流程结束 ✅)
-
所以,上面讲的那么多,其实就是为了干下面5件事
- 客户端发送的请求序列是采用哪一种字符集进行编码
- 服务器接收到的请求字节序列后会认为它是采用哪种字符集进行编码的--得到原始数据
- 服务器在运行过程中会把请求的字节序列转化为以哪种字符集编码的字节序列--可扩展新的比较规则
- 服务器在向客户端返回字节序列时,是采用哪一种字符集进行编码的
- 客户端在收到响应字节序列后,是怎么解码进行输出的
-
总结下上面牵扯到的3个
session级别的系统变量System Variable Desc character_set_client服务器认为请求时按照该系统变量指定的字符集进行编码的 character_set_connection服务器在处理请求时,会把请求序列从 character_set_clien转化为character_set_connectioncharacter_set_results服务器采用该系统变量指定的字符集对返回给客户端的字符串进行编码 !!!:这三个
session级别的系统变量对应3个字符集,实际上在客户端与服务器进行连接的时候,客户端会将默认的字符集,用户等信息一起发送给服务器,服务器在收到后会将character_set_client、character_set_connection和character_set_results这3个系统变量的值初始化为客户端的默认字符集(简单来说,就是客户端设定的字符集和这3个字符集都是同一个)
Desc
- 菜鸡摸索,有误勿喷
- 本文主要参考书籍《
MySQL是怎样运行的--从根儿上理解MySQL》,推荐大佬们可以看看书籍原文内容
参考
- 书籍: 《
MySQL是怎样运行的--从根儿上理解MySQL》----小孩子4919 著