目标: 掌握主从复制原理,搭建读写分离架构,了解高可用方案
开篇:单机撑不住了,怎么办?
你的系统火了,QPS从500涨到5000,单机MySQL的CPU飙到90%,查询越来越慢。更可怕的是,主库宕机了,业务停摆2小时,损失百万。
这时候你需要主从架构:一个主库负责写,多个从库负责读,既能分担压力,又能保证高可用。
这正是本讲要解决的核心议题。我们将从底层原理出发,一步步构建高可用的主从架构。
一、为什么需要主从复制?
单机MySQL有两个致命问题:
问题1:性能瓶颈
QPS从500涨到5000,单机CPU飙到90%,查询越来越慢。读请求占80%,但只有一台机器扛着。
问题2:单点故障
主库宕机了,业务停摆2小时,损失百万。没有备份,数据可能永久丢失。
解决方案:主从架构
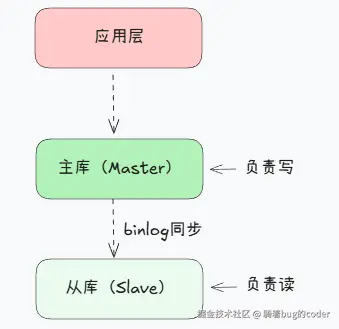
收益:
- 读写分离:主库写,从库读,分担压力
- 高可用:主库挂了,从库顶上
- 数据备份:从库就是实时备份
二、主从复制原理
核心组件:三个线程
主从复制靠三个线程协作完成:
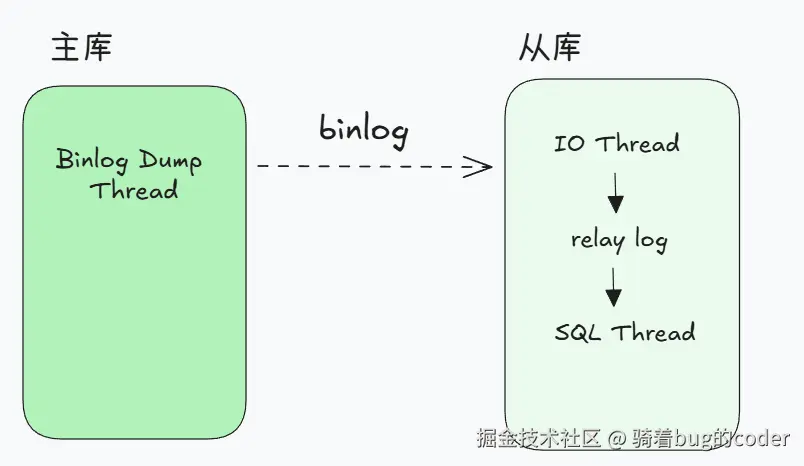
复制流程:
-
主库执行SQL,写入binlog
-
Dump线程读取binlog,发送给从库
-
IO线程接收binlog,写入relay log(中继日志)
-
SQL线程读取relay log,执行SQL
-
从库数据更新
-
从库数据更新
Relay Log:中继日志
- 身份:它是从库独有的日志,长得和 binlog 一模一样,但只在从库存在。
- 作用 :"缓冲与解耦" 。
- 主库发来 binlog,IO线程只管往 Relay Log 里写(速度快)。
- SQL线程慢慢从 Relay Log 里读出来回放(速度慢)。
- 这样,即使从库回放得很慢,甚至从库宕机了,只要 Relay Log 还在,数据就不会丢。
Binlog三种格式对比
binlog是主从复制的核心,我们在第9讲:日志体系已经详细学过它的三种格式。这里我们重点看它在复制中的表现。
| 格式 | 记录内容 | 优点 | 缺点 |
|---|---|---|---|
| STATEMENT | SQL语句原文 | 日志量小 | 非确定性函数复制不一致 |
| ROW | 每行数据的变更 | 复制准确 | 日志量大 |
| MIXED | 自动选择 | 兼顾两者 | 某些场景仍有问题 |
为什么STATEMENT有问题?
sql
-- 主库执行
UPDATE orders SET update_time = NOW() WHERE status = 0;
-- 主库NOW()返回 2025-01-02 10:00:00
-- 从库回放时NOW()返回 2025-01-02 10:00:05
-- 数据不一致!生产环境推荐ROW格式:
sql
SHOW VARIABLES LIKE 'binlog_format';
SET GLOBAL binlog_format = 'ROW';复制模式:性能与数据安全的博弈
默认情况下,MySQL使用异步复制。主库写完binlog就告诉客户端"成功了",不管从库有没有收到。这很快,但如果主库就在这一秒宕机了,binlog还没传给从库,数据就丢了。
为了解决这个问题,MySQL引入了其他模式:
复制模式对比
| 模式 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 异步复制(默认) | 主库写完binlog立即返回 | 性能最好 | 主库宕机可能丢数据 |
| 半同步复制 | 等待至少1个从库确认 | 数据更安全 | 性能略差 |
| GTID复制 | 全局事务ID,自动定位 | 故障切换简单 | 需要MySQL 5.6+ |
GTID复制:彻底告别"手动找位点"
传统复制的痛点:
主库挂了,要切换到从库。但从库需要知道"从哪个binlog位置开始复制"。你需要去手动查找位置,一旦算错,数据就乱了。
GTID是什么?
MySQL 5.6 引入了 GTID(全局事务ID),给每个事务发一个"身份证"。切换时,从库直接告诉主库:"我有这些身份证",主库就把剩下的补给它。
一句话总结: 有了GTID,主从切换全自动,再也不用人工介入算位置了。现在生产环境基本都用这个。
三、主从实战:从搭建到切换
光说不练假把式。我们用Docker快速模拟一套主从环境,演示最核心的搭建 和切换流程。
3.1 Docker极简搭建
第一步:启动两个MySQL容器(主库3307,从库3308)
bash
# 创建网络
docker network create mysql-net
# 启动主库
docker run -d --name mysql-master --network mysql-net -p 3307:3306 -e MYSQL_ROOT_PASSWORD=root mysql:5.7 --server-id=1 --log-bin=mysql-bin --gtid-mode=ON --enforce-gtid-consistency=ON
# 启动从库
docker run -d --name mysql-slave --network mysql-net -p 3308:3306 -e MYSQL_ROOT_PASSWORD=root mysql:5.7 --server-id=2 --relay-log=mysql-relay-bin --gtid-mode=ON --enforce-gtid-consistency=ON
第二步:配置复制关系
我们需要进入从库容器,连接到MySQL命令行:
bash
docker exec -it mysql-slave mysql -uroot -proot然后在MySQL命令行里执行配置命令:
sql
CHANGE MASTER TO
MASTER_HOST='mysql-master',
MASTER_USER='root',
MASTER_PASSWORD='root',
MASTER_AUTO_POSITION=1; -- 开启GTID自动找位点
START SLAVE;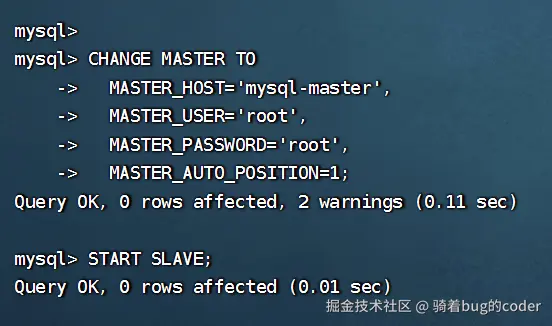
⚠️ 常见报错:ERROR 1777 如果你遇到 ERROR 1777 (HY000): ... because @@GLOBAL.GTID_MODE = OFF,说明启动容器时没开GTID。 解决方法 :先执行 docker rm -f mysql-master mysql-slave 删除旧容器,再加上 --gtid-mode=ON --enforce-gtid-consistency=ON 参数重新启动
3.2 模拟主从切换(手动版)
假设主库(mysql-master)需要停机维护,我们需要把流量切到从库。
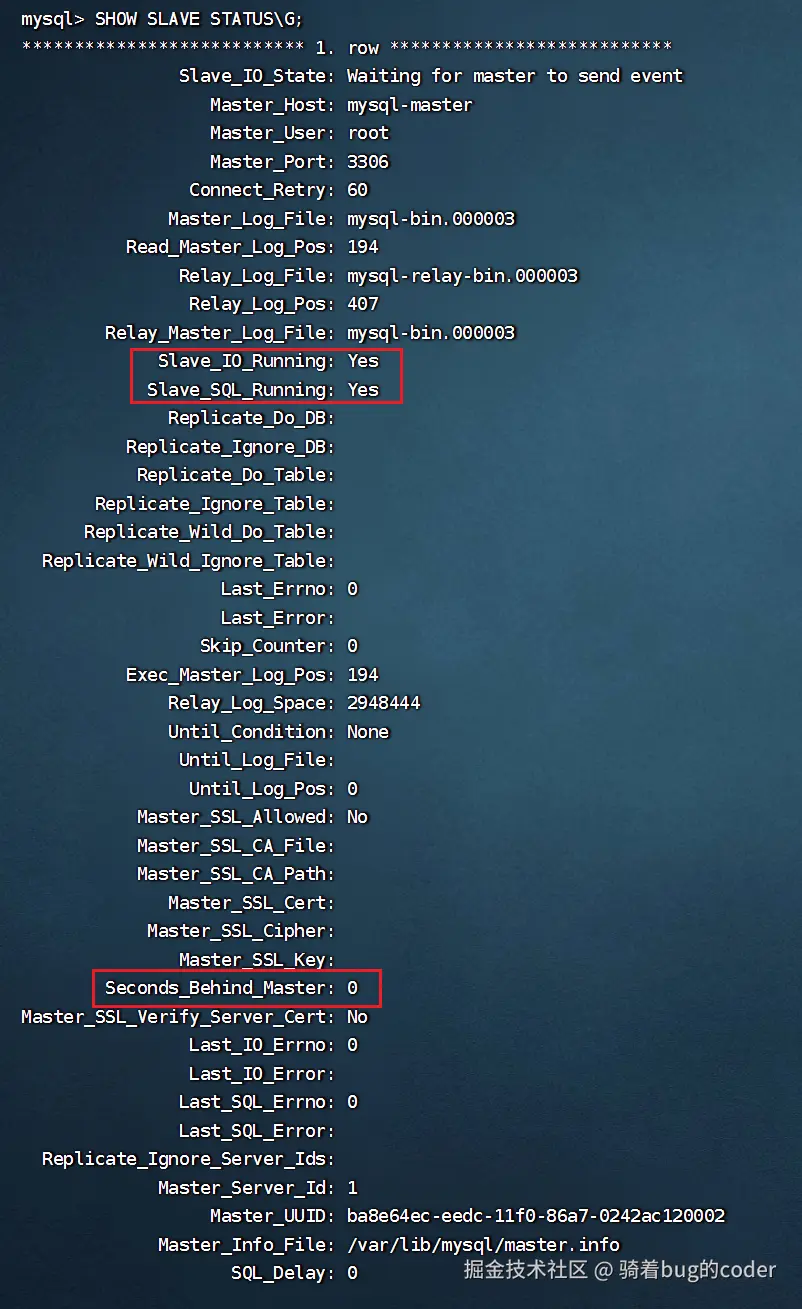
1. 确保从库已追平 在从库执行 SHOW SLAVE STATUS\G,确认 Seconds_Behind_Master 为 0。
2. 主库开启只读 进入主库容器:
bash
docker exec -it mysql-master mysql -uroot -proot
SET GLOBAL read_only = 1;
3. 提升从库为主库 回到从库容器(如果退出了就重新进入 docker exec -it mysql-slave mysql -uroot -proot):
sql
STOP SLAVE;
RESET SLAVE ALL; -- 清除从库配置,让它变身独立的主库
SET GLOBAL read_only = 0;4. 验证新主库可用 在 mysql-slave 里执行写入操作:
sql
CREATE DATABASE IF NOT EXISTS test_switch;
USE test_switch;
CREATE TABLE check_alive (id INT);
INSERT INTO check_alive VALUES (1);
-- 如果这条 INSERT 执行成功,说明它已经成功翻身做主人,可以接受写入了!
3.3 自动化切换(引入MHA)
手动切换太慢了,半夜主库挂了怎么办?这就需要 MHA (Master High Availability)。
它能自动检测主库是否存活,一旦挂了,自动把从库提升为主库,并把IP漂移过去,过程只需10-30秒,业务几乎无感知。
(注:MHA的部署比较偏运维,感兴趣的同学可以去网上查阅资料,或者和你的AI助手深入交流一下,这里就不展开了。)
四、读写分离实现
主从搭好了,怎么让应用自动把读请求发到从库?
方案1:应用层实现
在代码里判断读写,路由到不同数据源。
java
public class DataSourceRouter {
private DataSource master;
private List<DataSource> slaves;
public DataSource route(boolean isWrite) {
if (isWrite) {
return master; // 写操作走主库
}
// 读操作轮询从库
return slaves.get(ThreadLocalRandom.current().nextInt(slaves.size()));
}
}优点: 简单,不依赖中间件,适合小规模项目。 缺点: 侵入业务代码,每个项目都要写一遍。
💡 小Demo怎么做? 如果你只是写个个人项目,不想折腾中间件,用方案1 最快。定义两个DataSource,写个简单的路由注解@ReadDataSource,通过AOP切换数据源。
方案2:中间件实现(生产推荐)
用ShardingSphere等中间件,对应用透明。
yaml
dataSources:
master:
url: jdbc:mysql://192.168.1.100:3306/test
slave1:
url: jdbc:mysql://192.168.1.101:3306/test
rules:
- !READWRITE_SPLITTING
dataSources:
readwrite_ds:
writeDataSourceName: master
readDataSourceNames: [slave1]优点: 对应用透明,配置简单 缺点: 多一层中间件,需要运维
五、主从延迟:读写分离的头号敌人
问题场景
用户下单后立刻查询订单,结果查不到。
java
orderDao.insert(order); // 写主库
Order result = orderDao.selectById(order.getId()); // 读从库,但从库还没同步完
// result = null,用户懵了延迟原因
- 从库性能差:从库配置低,回放速度跟不上
- 大事务回放慢:主库一个大事务,从库要回放很久
- 单线程回放:从库SQL线程是单线程,主库并发写入时跟不上
解决方案
方案1:强制读主库
写操作后短时间内读主库,牺牲一点性能换一致性。
java
orderDao.insert(order);
Order result = masterDao.selectById(order.getId()); // 强制读主库方案2:并行复制 (MTS)
MTS 全称 Multi-Threaded Slave(多线程从库)。
- 原理 :传统从库只有一个SQL线程回放数据,还没干活就累死了。MTS 允许从库开启多个SQL线程并行回放,大大提高了效率。
- 版本:MySQL 5.7 引入了基于"逻辑时钟"的真正并行,之前版本的"多库并行"很鸡肋。
sql
-- 开启并行复制(仅MySQL 5.7+可用)
SET GLOBAL slave_parallel_type = 'LOGICAL_CLOCK';
SET GLOBAL slave_parallel_workers = 4; -- 4个线程并行回放方案3:监控告警
监控 Seconds_Behind_Master 这个核心指标:
0:完美,主从完全同步。> 0:有延迟,数字就是落后的秒数(比如 60 代表从库正在回放主库 1 分钟前的操做)。NULL:出大事了,复制线程报错停止了(比如网络断了或SQL执行错了),需要立刻排查Last_Error。
sql
SHOW SLAVE STATUS\G
-- Seconds_Behind_Master: 0六、高可用与备份
6.1 高可用方案对比
| 方案 | 切换时间 | 数据一致性 | 复杂度 | 适用场景 |
|---|---|---|---|---|
| 主从+手动切换 | 分钟级 | 可能丢失 | 低 | 小型系统 |
| MHA(第三方脚本) | 10-30秒 | 不丢失 | 中 | 生产环境 |
| MGR(官方集群) | 秒级 | 强一致 | 高 | 金融/支付 |
MGR (MySQL Group Replication) ,它是 MySQL 官方推出的集群高可用方案(类似 Redis Cluster),自带强一致性,比 MHA 更高级,但配置也更复杂。
6.2 备份恢复要点
备份策略:
- 全量备份 :每周一次(推荐用
xtrabackup物理备份,速度快) - 增量备份:每天一次
- Binlog:实时归档(这是最后一道防线)
黄金法则(3-2-1原则):
- 3份数据:1份生产数据 + 2份备份数据。
- 2种介质:比如一份存本地磁盘,一份存对象存储(OSS/S3)。
- 1份异地:必须有一份备份在不同的机房或城市(防备火灾、地震)。
误删恢复命令(救命用): 假设你今天(1月11日)上午10:30误删了数据,想恢复到删库前的一瞬间:
bash
# 恢复全量备份 + 重放binlog到误操作前
# --stop-datetime 的时间精确到误操作的前一秒
mysqlbinlog --stop-datetime="2026-01-11 10:29:59" mysql-bin.000001 | mysql -uroot -p七、避坑指南
坑1:从库未设置只读
问题: 应用误写从库导致数据不一致。
正确做法:
sql
SET GLOBAL read_only = 1;
SET GLOBAL super_read_only = 1;坑2:主从延迟未监控
问题: 用户查询不到刚写入的数据。
正确做法: 监控Seconds_Behind_Master,告警阈值>5秒。
坑3:binlog格式选择不当
问题: STATEMENT格式导致主从数据不一致。
正确做法: 使用ROW格式,确保复制准确性。
坑4:切换时未确认同步完成
问题: 主从切换时从库还没同步完,数据丢失。
正确做法: 切换前确认Seconds_Behind_Master = 0,GTID一致。
八、作业(可选)
思考题
如果主库突然宕机,切换到从库后,发现丢了几条数据,这时候业务该怎么止损?(提示:人工补单 或 客服安抚)
动手题
参照文中的Docker命令,自己动手搭建一套主从环境,并尝试执行一次"主从切换",看看即使不改代码,数据库层面发生了什么变化。
九、下一讲预告
主从架构搭建完了,但数据量继续增长,单表1亿行,查询还是慢。从库再多也解决不了单表太大的问题。
第12讲:分库分表与生产实战
下一讲会讲:
- 分库分表的判断标准
- 垂直拆分与水平拆分策略
- 全局唯一ID生成(雪花算法)
- 分区表实战与生产最佳实践
下一讲见!