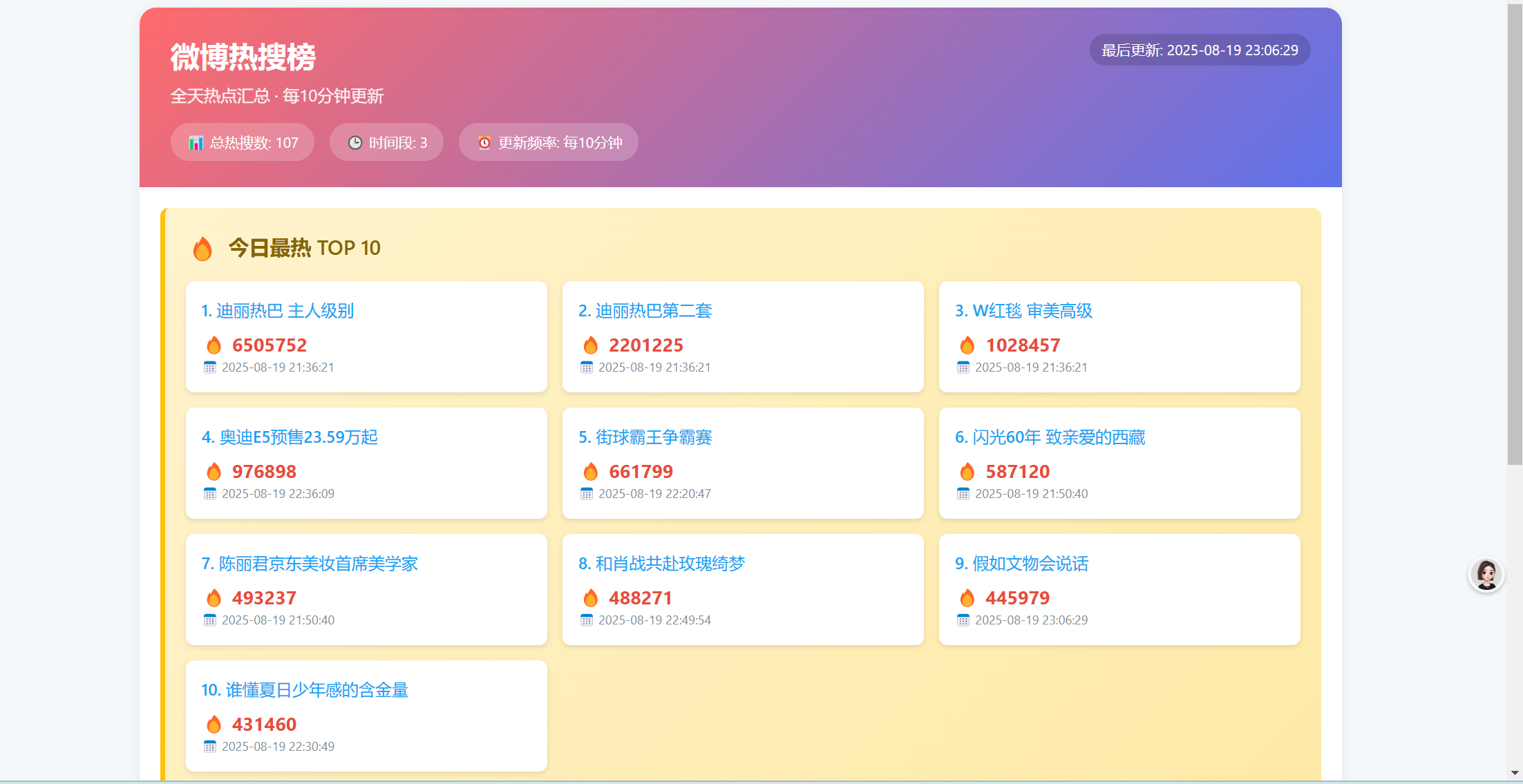
特色功能
• ✅ 避免HTML解析(API更稳定)
• ✅ 数据去重存储
• ✅ 响应式页面设计(支持手机/电脑)
• ✅ 自动折叠历史数据(减少页面冗长)
• ✅ 热度排序TOP 10
• ✅ 时间维度分组展示
• ✅ 页面自动刷新
python
import requests
from bs4 import BeautifulSoup
import time
import os
from datetime import datetime
import schedule
import random
import json
def fetch_weibo_hot():
"""使用API接口获取微博热搜数据(避免HTML结构变化问题)"""
api_url = "https://weibo.com/ajax/side/hotSearch"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36',
'Referer': 'https://weibo.com/',
'Cookie': 'XSRF-TOKEN=RKnNBEaQBdEdmw==' # 替换为你的实际Cookie
}
try:
# 添加随机延迟避免被封
time.sleep(random.uniform(0.5, 1.5))
response = requests.get(api_url, headers=headers, timeout=8)
response.raise_for_status()
# 解析JSON数据
data = response.json()
# 提取热搜数据
hot_items = []
for group in data['data']['realtime']:
# 普通热搜项
if 'word' in group:
item = {
'rank': group.get('rank', ''),
'title': group['word'],
'hot': group.get('num', '0'),
'link': f"https://s.weibo.com/weibo?q={group['word']}",
'timestamp': datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
'source': 'weibo'
}
hot_items.append(item)
# 只保留前50条热搜
return hot_items[:50]
except Exception as e:
print(f"🚨 获取热搜数据失败: {e}")
return []
def load_existing_hot_searches(date_str):
"""加载当天已存在的热搜数据"""
json_file = os.path.join("weibo_hot", date_str, "hot_searches.json")
if os.path.exists(json_file):
try:
with open(json_file, 'r', encoding='utf-8') as f:
return json.load(f)
except Exception as e:
print(f"读取已有热搜数据失败: {e}")
return []
return []
def save_hot_data_json(hot_data, date_str):
"""保存热搜数据到JSON文件"""
daily_dir = os.path.join("weibo_hot", date_str)
if not os.path.exists(daily_dir):
os.makedirs(daily_dir)
json_file = os.path.join(daily_dir, "hot_searches.json")
# 加载已有数据
existing_data = load_existing_hot_searches(date_str)
existing_titles = {item['title'] for item in existing_data}
# 过滤掉已存在的热搜
new_data = [item for item in hot_data if item['title'] not in existing_titles]
# 合并数据
all_data = existing_data + new_data
# 保存到JSON文件
with open(json_file, 'w', encoding='utf-8') as f:
json.dump(all_data, f, ensure_ascii=False, indent=2)
return all_data, len(new_data)
def get_top_hot_searches(hot_data, top_n=10):
"""获取热度最高的前N条热搜"""
# 创建可排序的热搜列表
sortable_items = []
for item in hot_data:
try:
# 尝试将热度值转换为整数
hot_value = int(item['hot'])
sortable_items.append((item, hot_value))
except (TypeError, ValueError):
# 如果转换失败,跳过该条目
continue
# 按热度值排序(从高到低)
sorted_searches = sorted(sortable_items, key=lambda x: x[1], reverse=True)
# 返回前N条原始数据
return [item[0] for item in sorted_searches[:top_n]]
def generate_html(hot_data, date_str):
"""生成HTML文件"""
if not hot_data:
return "<html><body><h1>未获取到热搜数据</h1></body></html>"
# 获取热度最高的前10条热搜
top_hot_searches = get_top_hot_searches(hot_data, 10)
# 按时间分组热搜
time_groups = {}
for item in hot_data:
time_key = item['timestamp'][:13] # 只取到小时
if time_key not in time_groups:
time_groups[time_key] = []
time_groups[time_key].append(item)
# 按时间倒序排列
sorted_times = sorted(time_groups.keys(), reverse=True)
# 统计信息
total_count = len(hot_data)
time_count = len(time_groups)
html_content = f"""
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>微博热搜榜 {date_str}</title>
<link rel="icon" href="data:image/svg+xml,<svg xmlns=%22http://www.w3.org/2000/svg%22 viewBox=%220 0 100 100%22><text y=%22.9em%22 font-size=%2290%22>🔥</text></svg>">
<style>
* {{
box-sizing: border-box;
margin: 0;
padding: 0;
}}
body {{
font-family: -apple-system, BlinkMacSystemFont, "Segoe UI", Roboto, "PingFang SC", "Microsoft YaHei", sans-serif;
background-color: #f5f8fa;
color: #14171a;
line-height: 1.5;
padding: 20px;
max-width: 1200px;
margin: 0 auto;
}}
.container {{
background: white;
border-radius: 16px;
box-shadow: 0 3px 10px rgba(0, 0, 0, 0.08);
overflow: hidden;
margin-bottom: 30px;
}}
.header {{
background: linear-gradient(135deg, #ff6b6b, #5e72eb);
color: white;
padding: 25px 30px;
position: relative;
}}
.title {{
font-size: 28px;
font-weight: 700;
margin-bottom: 5px;
}}
.subtitle {{
font-size: 16px;
opacity: 0.9;
}}
.stats {{
margin-top: 15px;
display: flex;
gap: 15px;
flex-wrap: wrap;
}}
.stat-item {{
background: rgba(255, 255, 255, 0.2);
padding: 8px 15px;
border-radius: 20px;
font-size: 14px;
}}
.update-time {{
position: absolute;
top: 25px;
right: 30px;
background: rgba(0, 0, 0, 0.15);
padding: 5px 12px;
border-radius: 20px;
font-size: 14px;
}}
.top-hot-section {{
background: linear-gradient(135deg, #fff3cd, #ffeaa7);
padding: 20px;
border-radius: 8px;
margin: 20px;
border-left: 5px solid #ffc107;
}}
.section-title {{
font-size: 20px;
font-weight: 600;
margin-bottom: 15px;
color: #856404;
display: flex;
align-items: center;
}}
.section-title::before {{
content: "🔥";
margin-right: 8px;
font-size: 24px;
}}
.top-hot-list {{
display: grid;
grid-template-columns: repeat(auto-fill, minmax(300px, 1fr));
gap: 15px;
}}
.top-hot-item {{
background: white;
padding: 15px;
border-radius: 8px;
box-shadow: 0 2px 5px rgba(0,0,0,0.1);
}}
.top-hot-title {{
font-size: 16px;
font-weight: 500;
margin-bottom: 8px;
}}
.top-hot-value {{
color: #e74c3c;
font-weight: 700;
font-size: 18px;
}}
.hot-time {{
font-size: 12px;
color: #868e96;
}}
.time-section {{
margin: 20px 0;
padding: 15px;
background: #f8f9fa;
border-radius: 8px;
}}
.time-header {{
font-size: 18px;
font-weight: 600;
margin-bottom: 15px;
color: #495057;
display: flex;
align-items: center;
justify-content: space-between;
}}
.time-info {{
display: flex;
align-items: center;
}}
.time-count {{
background: #e9ecef;
padding: 2px 8px;
border-radius: 10px;
font-size: 14px;
margin-left: 10px;
}}
.hot-list {{
padding: 0;
}}
.hot-item {{
display: flex;
align-items: center;
padding: 16px 20px;
border-bottom: 1px solid #e6ecf0;
transition: background 0.2s;
}}
.hot-item:hover {{
background-color: #f7f9fa;
}}
.rank {{
width: 36px;
height: 36px;
line-height: 36px;
text-align: center;
font-weight: bold;
font-size: 16px;
background: #f0f2f5;
border-radius: 8px;
margin-right: 15px;
flex-shrink: 0;
}}
.top1 {{
background: linear-gradient(135deg, #ff9a9e, #fad0c4);
color: #d63031;
}}
.top2 {{
background: linear-gradient(135deg, #a1c4fd, #c2e9fb);
color: #0984e3;
}}
.top3 {{
background: linear-gradient(135deg, #ffecd2, #fcb69f);
color: #e17055;
}}
.hot-content {{
flex: 1;
min-width: 0;
}}
.hot-title {{
font-size: 17px;
font-weight: 500;
margin-bottom: 6px;
white-space: nowrap;
overflow: hidden;
text-overflow: ellipsis;
}}
.hot-stats {{
display: flex;
align-items: center;
color: #657786;
font-size: 14px;
gap: 15px;
flex-wrap: wrap;
}}
.hot-value {{
color: #ff6b6b;
font-weight: 700;
}}
.hot-time {{
font-size: 12px;
color: #868e96;
}}
.link {{
color: #1da1f2;
text-decoration: none;
transition: color 0.2s;
}}
.link:hover {{
color: #0d8bda;
text-decoration: underline;
}}
.footer {{
text-align: center;
padding: 20px;
color: #657786;
font-size: 13px;
border-top: 1px solid #e6ecf0;
}}
.no-data {{
text-align: center;
padding: 40px;
color: #657786;
}}
.collapse-btn {{
background: #6c757d;
color: white;
border: none;
padding: 5px 10px;
border-radius: 4px;
cursor: pointer;
font-size: 12px;
}}
.collapse-btn:hover {{
background: #5a6268;
}}
.collapsed .hot-list {{
display: none;
}}
.auto-refresh {{
text-align: center;
margin: 20px 0;
}}
.refresh-btn {{
background: #28a745;
color: white;
border: none;
padding: 10px 20px;
border-radius: 5px;
cursor: pointer;
font-size: 14px;
}}
.refresh-btn:hover {{
background: #218838;
}}
@media (max-width: 768px) {{
body {{
padding: 10px;
}}
.header {{
padding: 20px 15px;
}}
.title {{
font-size: 22px;
}}
.update-time {{
position: static;
margin-top: 10px;
}}
.top-hot-list {{
grid-template-columns: 1fr;
}}
.hot-item {{
padding: 14px 15px;
}}
.hot-title {{
font-size: 16px;
}}
.hot-stats {{
flex-direction: column;
align-items: flex-start;
gap: 5px;
}}
}}
</style>
</head>
<body>
<div class="container">
<div class="header">
<h1 class="title">微博热搜榜</h1>
<div class="subtitle">全天热点汇总 · 每10分钟更新</div>
<div class="stats">
<div class="stat-item">📊 总热搜数: {total_count}</div>
<div class="stat-item">🕒 时间段: {time_count}</div>
<div class="stat-item">⏰ 更新频率: 每10分钟</div>
</div>
<div class="update-time">最后更新: {datetime.now().strftime("%Y-%m-%d %H:%M:%S")}</div>
</div>
"""
# 添加热度最高的前10条热搜
if top_hot_searches:
html_content += f"""
<div class="top-hot-section">
<div class="section-title">今日最热 TOP 10</div>
<div class="top-hot-list">
"""
for i, item in enumerate(top_hot_searches, 1):
html_content += f"""
<div class="top-hot-item">
<div class="top-hot-title">
<a href="{item['link']}" class="link" target="_blank">{i}. {item['title']}</a>
</div>
<div class="top-hot-value">🔥 {item['hot']}</div>
<div class="hot-time">📅 {item['timestamp']}</div>
</div>
"""
html_content += """
</div>
</div>
"""
# 添加时间分组的热搜内容
for time_key in sorted_times:
time_display = f"{time_key}:00"
time_data = time_groups[time_key]
html_content += f"""
<div class="time-section">
<div class="time-header">
<div class="time-info">
🕒 {time_display}
<span class="time-count">{len(time_data)} 条热搜</span>
</div>
<button class="collapse-btn" onclick="this.parentElement.parentElement.classList.toggle('collapsed')">折叠/展开</button>
</div>
<div class="hot-list">
"""
for item in time_data:
rank_class = ""
if item['rank'] == 1:
rank_class = "top1"
elif item['rank'] == 2:
rank_class = "top2"
elif item['rank'] == 3:
rank_class = "top3"
hot_value = f"<span class='hot-value'>🔥 {item['hot']}</span>" if item['hot'] else ""
html_content += f"""
<div class="hot-item">
<div class="rank {rank_class}">{item['rank']}</div>
<div class="hot-content">
<div class="hot-title">
<a href="{item['link']}" class="link" target="_blank">{item['title']}</a>
</div>
<div class="hot-stats">
{hot_value}
<span class="hot-time">📅 {item['timestamp']}</span>
</div>
</div>
</div>
"""
html_content += """
</div>
</div>
"""
if not hot_data:
html_content += """
<div class="no-data">
<h3>暂无热搜数据</h3>
<p>请检查网络连接或稍后再试</p>
</div>
"""
html_content += f"""
<div class="auto-refresh">
<button class="refresh-btn" onclick="location.reload()">🔄 刷新页面</button>
<p>页面每10分钟自动更新,也可手动刷新</p>
</div>
<div class="footer">
数据来源: 微博热搜 • 每10分钟自动更新 • 最后更新: {datetime.now().strftime("%Y-%m-%d %H:%M:%S")} • 仅供学习参考
</div>
</div>
<script>
// 默认折叠所有时间段的搜索结果
document.addEventListener('DOMContentLoaded', function() {{
var sections = document.querySelectorAll('.time-section');
sections.forEach(function(section, index) {{
if (index > 0) {{ // 保持最新时间段展开
section.classList.add('collapsed');
}}
}});
// 设置自动刷新(每5分钟)
setTimeout(function() {{
location.reload();
}}, 5 * 60 * 1000);
}});
</script>
</body>
</html>
"""
return html_content
def save_hot_data():
"""保存热搜数据"""
try:
# 创建存储目录
if not os.path.exists("weibo_hot"):
os.makedirs("weibo_hot")
# 获取当前日期
now = datetime.now()
date_str = now.strftime("%Y-%m-%d")
print(f"🕒 开始获取 {now.strftime('%Y-%m-%d %H:%M:%S')} 的热搜数据...")
hot_data = fetch_weibo_hot()
if hot_data:
print(f"✅ 成功获取 {len(hot_data)} 条热搜数据")
# 保存到JSON文件并获取所有数据
all_data, new_count = save_hot_data_json(hot_data, date_str)
print(f"📊 已有 {len(all_data)} 条热搜,新增 {new_count} 条")
# 生成HTML内容
html_content = generate_html(all_data, date_str)
# 保存HTML文件
html_file = os.path.join("weibo_hot", date_str, "index.html")
with open(html_file, "w", encoding="utf-8") as f:
f.write(html_content)
print(f"💾 已保存到: {html_file}")
else:
print("⚠️ 未获取到热搜数据,跳过保存")
except Exception as e:
print(f"❌ 保存数据时出错: {e}")
def job():
"""定时任务"""
print("\n" + "="*60)
print(f"⏰ 执行定时任务: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
save_hot_data()
print("="*60 + "\n")
if __name__ == "__main__":
print("🔥 微博热搜爬虫已启动 🔥")
print("⏳ 首次执行将立即运行,之后每10分钟执行一次")
print("💡 提示: 请确保已更新有效的Cookie")
print("="*60)
# 立即执行一次
job()
# 设置定时任务(每10分钟执行一次)
schedule.every(10).minutes.do(job)
print("⏳ 程序运行中,按Ctrl+C退出...")
try:
# 保持程序运行
while True:
schedule.run_pending()
time.sleep(30) # 每30秒检查一次
except KeyboardInterrupt:
print("\n👋 程序已手动停止")