大语言模型(LLM)已经成为通往通用人工智能(AGI)的关键路径。自 ChatGPT 引爆公众关注后,开源社区也不断追赶,推出 LLaMA、Mistral、Yi 等模型,逐步缩小与闭源模型的差距。
DeepSeek LLM 是一项来自 DeepSeek-AI 的开源努力,不仅在架构、训练调度、数据处理等方面延续了高水准的工程实践,更进一步探索了如何在"长期主义"视角下优化大模型的可扩展性与性能。
在正式了解 DeepSeek 的架构前,建议带着以下三个问题阅读这篇文章:
- DeepSeek LLM 在架构上相比 LLaMA 有哪些关键改动?
- 为什么 DeepSeek 使用了 Grouped-Query Attention(GQA),而不是 Multi-Head Attention(MHA)?
- DeepSeek 是如何兼顾训练效率与未来可持续扩展的?
所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:LLMHub,欢迎关注收藏!
一、模型参数配置:从 7B 到 67B 的平滑扩展
DeepSeek LLM 提供两个版本:7B 和 67B,分别拥有 30 层与 95 层 Transformer 层,参数规模上对标 LLaMA,但在细节设计上做出了关键优化:

- 使用 PreNorm 架构 搭配 RMSNorm 正则化
- 激活函数为 SwiGLU
- 位置编码采用 Rotary Embedding(RoPE)
- 67B 模型采用 Grouped-Query Attention(GQA),大幅优化 KV 缓存使用和推理效率
📌 值得注意的是,DeepSeek 并没有简单地加宽 FFN,而是通过增加网络深度来提升模型能力,同时更利于训练阶段的流水线并行。
二、Grouped-Query Attention(GQA):推理成本优化关键
在传统的 Multi-Head Attention 中,每个注意力头都要独立计算 query-key-value 三组向量,随着模型增大,KV 缓存的开销迅速膨胀。
DeepSeek 67B 选择了 GQA 替代 MHA:
- 共享 Key/Value 的方式大幅减少 KV 缓存占用
- 在不显著影响模型性能的前提下,优化推理过程中的计算和显存需求
- 对比使用传统 MHA 的同类模型,在相同硬件资源下推理更快
这一选择使得 DeepSeek 能更好地部署在多种应用场景中,并提高模型在部署阶段的性价比。
三、多步学习率调度器:为长期训练奠定基础
不同于多数 LLM 使用的余弦学习率调度器,DeepSeek LLM 引入了多阶段学习率(multi-step scheduler)策略:
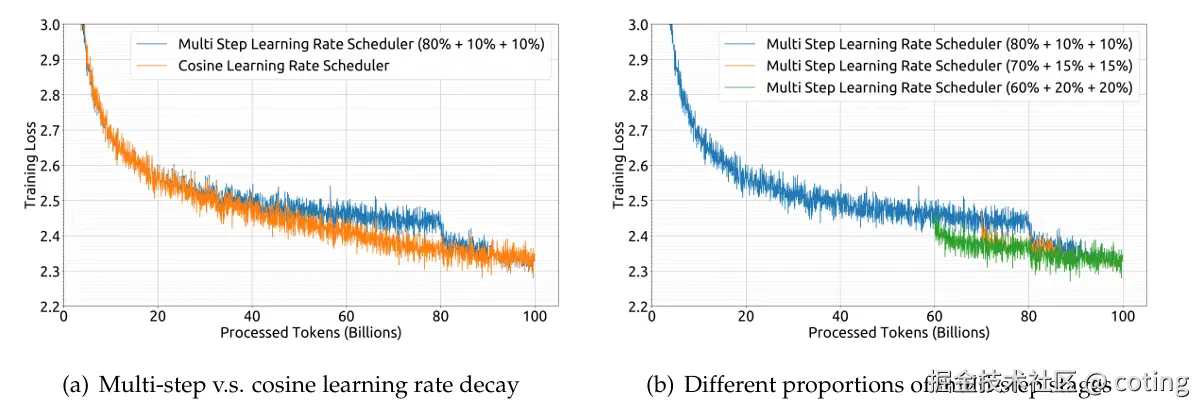
- 初始热身阶段:前 2000 步逐步升高学习率
- 中期阶段:训练 80% token 后将学习率降至 31.6%
- 后期阶段:训练 90% token 后再次降至 10%
这一策略带来两个直接好处:
- 支持阶段性训练/持续训练(continual training),可在未来添加数据、重新微调
- 损失曲线更平稳,避免早期震荡,提升训练稳定性
📌 DeepSeek 明确指出,虽然这种策略与余弦调度相比最终性能差别不大,但在工程上更可控、更有利于长周期训练
四、训练框架与工程优化:支撑大模型运行的幕后工程
DeepSeek 使用自研的高效训练框架 HAI-LLM,集成了 Megatron 的关键并行策略,并加入如下优化:
- 支持 1F1B、张量、数据、序列四种并行方式
- 采用 Flash Attention、ZeRO-1 优化内存利用率
- 模型以 bf16 训练、fp32 累积梯度
- 每 5 分钟异步保存权重与优化器状态,极大减少故障恢复成本
此外还支持在不同并行配置间无缝恢复训练,展示出极高的工程成熟度。
五、三大问题的总结解答
1. DeepSeek LLM 在架构上相比 LLaMA 有哪些关键改动?
主要改动包括:引入 GQA 替代 MHA、使用 RMSNorm 和 SwiGLU、选择多步学习率调度器、在 67B 模型中优先加深网络层数而不是加宽。
| 模型 | 注意力机制 | 学习率调度 | 深度扩展策略 | KV 缓存优化 | 架构细节 |
|---|---|---|---|---|---|
| LLaMA | Multi-Head Attention | Cosine decay | 均衡加宽加深 | 无特别优化 | SwiGLU + RMSNorm |
| DeepSeek LLM | GQA(Grouped Query Attention) | Multi-step 调度器 | 优先加深层数 | 减少 KV 缓存使用 | SwiGLU + RMSNorm + HAI训练框架 |
2. 为什么 DeepSeek 使用 GQA?
为了显著减少推理阶段的 KV 缓存占用,提升推理速度,同时维持较高模型性能。这一策略使得模型更加轻量,适合落地部署。
3. DeepSeek 如何兼顾训练效率与未来可持续扩展?
通过可复用的多步学习率调度器、持续训练友好的设计、以及高性能并行框架 HAI-LLM,DeepSeek 在工程上为长期扩展和迭代预留了空间。
📌 结语
DeepSeek LLM 不只是又一个开源模型,它是对"长期主义"视角下 LLM 架构与训练方式的系统性探索。从架构微调到大规模训练支持,它展示了国产开源 LLM 在工程能力与模型设计上的巨大进步。如果你关心大模型的推理效率、扩展性与部署落地,这份架构设计值得深入研究。
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号算法coting!