先交代背景:我自己用着一台 MacBook M3 Max 32G,平时跑跑模型、处理点数据,虽然称不上飞起,但也算是稳如老狗。
最近公司打算添置一台Mac,我一看------去年发布的 M4 Mac mini,外观精致、价格"相对友好",再加上那波"AI电脑""神经网络引擎"的宣传......脑子一热,就给老板和同事们激情推荐了。
结果?我们成了苹果刀法下的那颗韭菜。
初见,这小东西,确实有点东西
刚拿到 M4 Mac mini,我真的被它唬住了。
设计简洁、体积小巧,放在桌面上像个精致的手办。开机速度快,系统流畅,写代码、浏览网页、甚至剪个短视频都没问题。

我当时还跟同事吹:"这玩意儿,性价比之王!颜值生产力两不误!"
情绪价值?直接拉满。
既然买了,总不能只用来写代码吧。
我顺手给它装上了 Ollama,先试了几个 8B、14B 的开源模型。处理点文本总结、格式转换,确实没啥问题,安静、快速、不发烫。
我甚至有点飘了:"看来M4的NPU(神经网络处理器)不是白给的!"
深入了解,问题暴露
好景不长。
随着任务变复杂,8B、14B 的模型开始输出一些"脑干缺失"般的答案------要么逻辑混乱,要么直接摆烂。
没办法,只能上更大参数的模型。
结果这一上,就翻车了。
我常用的 deepseek-r1:32B,在M3 Max上虽然也吃资源,但至少能跑。
换到同样内存的 M4 Mac mini 上?直接卡在加载界面,内存占用飙满,但输出始终为0------像极了你熬夜写方案写到凌晨三点,结果电脑蓝屏了。
我不死心,换了个 Qwen3-30B-A3B。
这回倒是能跑了,但速度呢?每秒30个token。
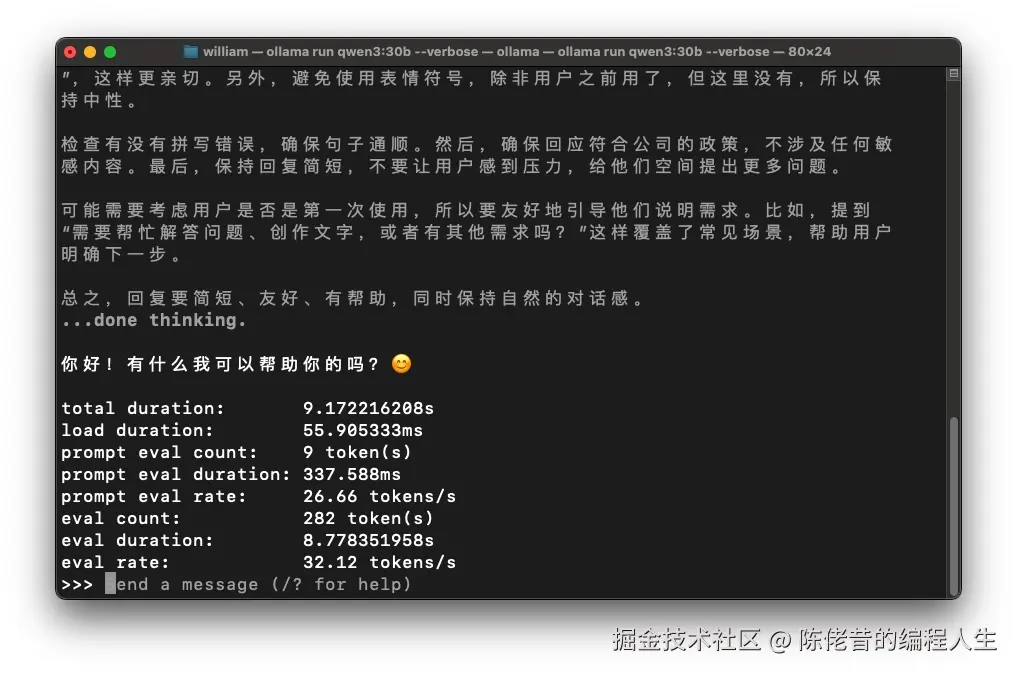
而同样的模型,在M3 Max上能跑到 60 tokens/s,比 M4 快了一倍。
以下是 M3 Max 跑的 Qwen3:30b的截屏
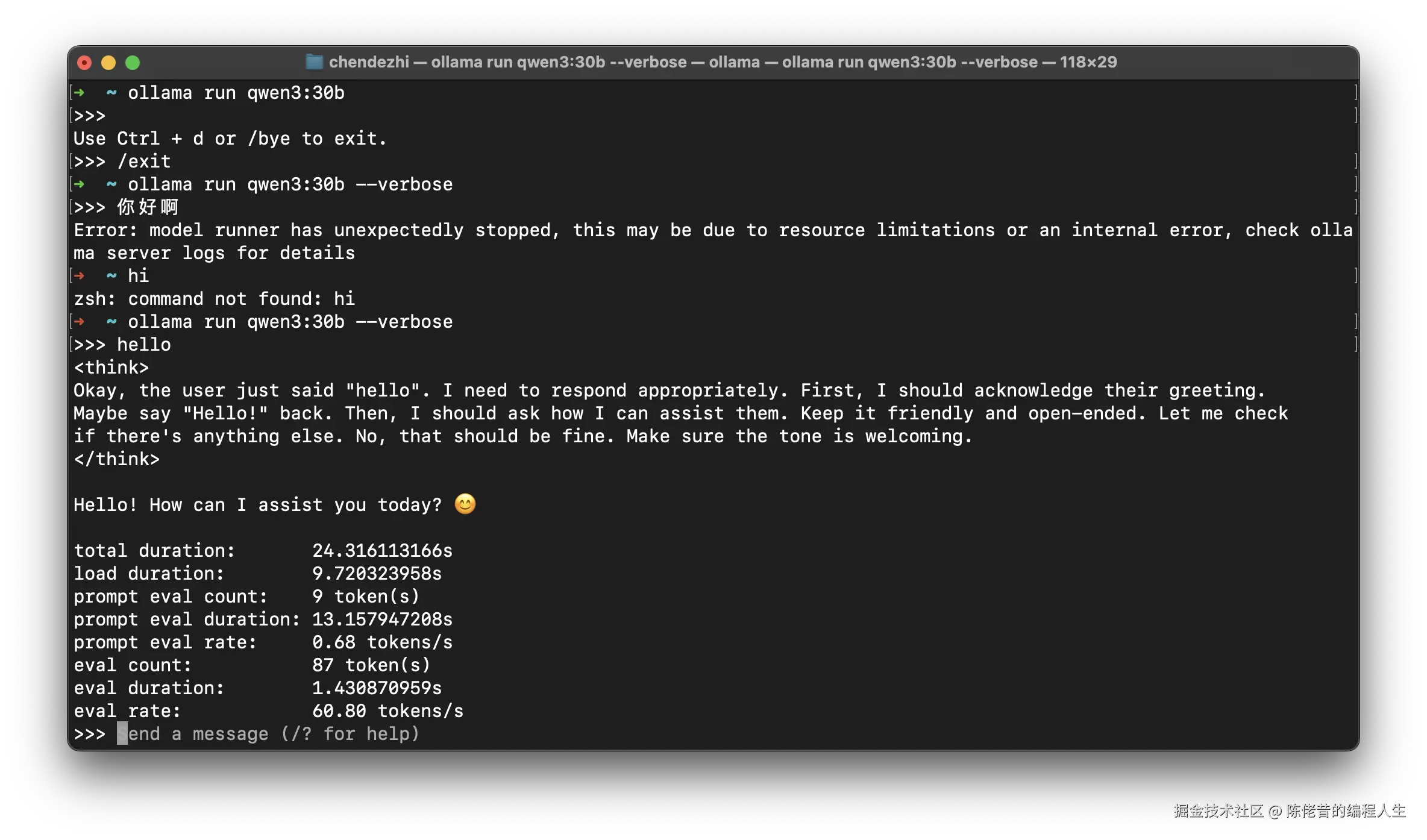
苹果的刀法果然精准!
一查资料,我悟了。
| 芯片 | GPU核心数 | 内存带宽 | 适合场景 |
|---|---|---|---|
| M4 | 10核 | 120GB/s | 日常办公、轻度AI |
| M4 Pro | 16/20核 | 273GB/s | 中度使用 |
| M3 Max | 40核 | 400GB/s | 重度渲染、大模型 |
看出来了吗?
苹果的芯片有明显的等级制度,每个等级之间有一条无法逾越的鸿沟。
M4 的 GPU 性能被阉割得明明白白,而大模型推理恰恰极度依赖GPU并行计算和内存带宽。
苹果根本没打算让标准版M4扛起AI大旗,它只是个"AI体验卡",真要想本地部署大模型,还是得加钱上 Pro / Max。
总结:如果你也想玩大模型......
Mac 系列购买指南:
- ✅ 轻度使用(7B~14B):M4 够用,安静省电颜值高
- ❌ 重度使用(30B+):请直接上 M3/M4 Pro 或 Max,别省那几千块
如果你像我一样,又穷又爱玩的,公司任务又重的,建议还是云服务器+远程调试,别折磨Mac mini了。
最后也给以前听了我的建议,买了残缺版的 Mac Mini 的朋友道个歉~
对不起!是我草率了!
如果您的 M4 Mini 现在正对着大模型"思考人生",我对此深表同情,并建议您:
- 安慰它:告诉它"跑不动不是你的错,是爸爸(库克)没给你吃饱"。
- 安慰自己:至少......它长得好看,省电,还能当个合格的摆件,对吧?
- 来骂我:如果心里实在憋得慌,欢迎在评论区提出批评。
再次鞠躬!这波是我坑了队友,下次推荐前,我一定先把它跑冒烟了再说!