作者:来自 Elastic Alessandro Brofferio

学习如何使用 Elasticsearch 构建 RAG 应用,轻松排查你的家电问题。
想要获得 Elastic 认证吗?来看看下一次 Elasticsearch 工程师培训什么时候开始吧!
Elasticsearch 拥有大量新功能,可以帮助你根据使用场景构建最佳搜索解决方案。深入学习我们的示例笔记本,了解更多信息,开启免费的云试用,或者现在就在本地机器上尝试 Elastic。
RAG(Retrieval Augmented Generation)通过使用外部知识库来丰富生成的答案,从而增强了 LLM 的能力。这篇博客详细介绍了一个基于 Elasticsearch 构建的简单 RAG 应用的实现。该应用旨在帮助用户排查家电问题,回答常见问题,比如 "如何将我的洗碗机恢复到出厂设置?"
我们将一步步指导你,涵盖以下内容:
-
创建一个使用 semantic_text 类型来存储 PDF 正文内容的 Elasticsearch 索引
-
设置一个 LLM completion 推理端点,用来与所选的 LLM 交互
-
使用 semantic_text 查询类型,根据用户查询检索相关文档
-
将所有内容结合在一起,构建一个出色的原型
你需要:
-
一个至少更新到 Elastic 8.18.x 的 Elastic Cloud 部署
-
一个 LLM API 服务(我使用的是 OpenAI Azure)
该应用基于一个简单的 Flask 应用构建,可以无缝集成 Elasticsearch API 来执行 RAG。同时配有一个简单的前端,允许用户上传用户手册进行处理。完整代码在这里可以获取。
这个 RAG 应用接收你选择的家电 PDF 手册。上传后,它会智能地逐页解析 PDF 文档,并将每一页提取的文本内容发送到 Elasticsearch。在那里,会依靠导入 Elasticsearch 的推理模型为内容创建文本嵌入,并将其存储为 dense_vectors。一旦手册处理完成,用户就可以输入查询,利用这些知识快速找到家电问题的解决方案。
数据收集
如上所述,我们在 Elastic Cloud 部署上运行了一个 Elasticsearch 实例。Elasticsearch 集群请求受配置设置控制,包括 http:max_content_length。这个网络 HTTP 设置会限制 HTTP 请求体的最大大小,默认值为 100MB,在 Elastic Cloud 中目前不可配置。
为了绕过这一限制来处理更大的文档,我实现了一个简单的 Python 函数,将提供的 PDF 拆分为单独的页面,并存储在一个单独的文件夹中。
下面是该函数的部分代码示例:
python
`
1. def split_pdf(input_pdf_path, output_folder, filename_prefix=''):
2. """
3. Splits a PDF file into individual pages and saves them to an output folder.
5. Args:
6. input_pdf_path (str): The full path to the input PDF file.
7. output_folder (str): The directory where split pages will be saved.
8. filename_prefix (str): A prefix to use for the output filenames (e.g., "manual_").
9. """
10. logging.info(f"[{time.strftime('%H:%M:%S')}] Splitting PDF: {input_pdf_path}")
12. try:
13. # Open the PDF file
14. with open(input_pdf_path, 'rb') as file:
15. pdf_reader = PdfReader(file)
17. # Iterate through each page
18. for page_num in range(len(pdf_reader.pages)):
19. pdf_writer = PdfWriter()
20. pdf_writer.add_page(pdf_reader.pages[page_num])
22. # Generate the output file name
23. # Uses the original filename (without extension) as part of the prefix
24. original_filename_base = os.path.splitext(os.path.basename(input_pdf_path))[0]
25. output_filename = f'{filename_prefix}{original_filename_base}_pg_{page_num + 1}.pdf'
26. output_path = os.path.join(output_folder, output_filename)
28. # Save the page as a new PDF
29. with open(output_path, 'wb') as output_file:
30. pdf_writer.write(output_file)
32. logging.info(f'[{time.strftime("%H:%M:%S")}] Saved split page: {output_filename}')
33. logging.info(f"[{time.strftime('%H:%M:%S')}] Finished splitting PDF: {input_pdf_path}")
34. except Exception as e:
35. logging.error(f"[{time.strftime('%H:%M:%S')}] Error during PDF splitting for {input_pdf_path}: {e}")
`AI写代码为你的 PDF 内容创建嵌入
文本嵌入是指将文本(或其他数据类型)转换为数值向量表示的过程 ------ 具体来说,就是稠密向量。这是现代搜索和机器学习应用中的关键技术,特别适用于语义搜索、相似性搜索和生成式 AI。
Elastic 提供了多种依赖文本嵌入模型的方式:
-
内置模型:这些模型在 Elasticsearch 中即可使用,开箱即用并已预训练,这意味着你不需要在自己的数据上进行微调,使它们能够适应各种使用场景。例如,你可以使用:
-
导入 HuggingFace 模型:用户可以从 HuggingFace 等平台导入预训练模型。这个过程依赖 Eland,它是一个 Python 客户端,提供与 Pandas 兼容的 API,用于在 Elasticsearch 中进行数据探索和分析。
在本项目中,我们将上传一个 HuggingFace 模型。你可以通过以下方式安装 Eland:
go
`python -m pip install eland`AI写代码现在,打开 Bash 编辑器并创建一个 .sh 脚本,正确填写每个参数:
bash
`
1. MODEL_ID="sentence-transformers/all-MiniLM-L6-v2"
2. CLOUD_URL='<<YOUR_CLOUD_URL>>'
3. ELASTIC_API_KEY='<<YOUR_API_KEY>>'
4. eland_import_hub_model \
5. --url "$CLOUD_URL" \
6. --es-api-key "$ELASTIC_API_KEY" \
7. --hub-model-id "$MODEL_ID" \
8. --insecure \
9. --task-type text_embedding\
10. --start
`AI写代码MODEL_ID 指的是从 HuggingFace 获取的模型。我们将使用 all-MiniLM-L6-v2,因为它体积小,可以轻松在 CPU 上运行,并且性能优异,尤其适合本次演示。
运行这个 Bash 脚本后,你的模型会出现在 Elastic 部署中的 Machine Learning -> Model Management -> Trained Models 下。

创建推理端点
从 8.11 版本开始,Elastic 已经普遍提供了推理 API 服务(inference API service)。该功能允许用户创建推理端点,使用 Elastic 服务执行各种推理任务。
在本次演示中,我们将创建一个名为 minilm-l6 的端点,用来使用通过 Eland 上传的模型。这个端点会传递与刚刚上传模型对应的正确 model_id。
bash
`
1. PUT _inference/text_embedding/minilm-l6
2. {
3. "service": "elasticsearch",
4. "service_settings": {
5. "num_allocations": 1,
6. "num_threads": 1,
7. "model_id": "sentence-transformers__all-minilm-l6-v2"
8. }
9. }
`AI写代码创建存储 PDF 内容的索引
接下来,我们将创建一个索引,并使用默认映射,其中包含 semantic_text 字段。此设置需要你指定之前创建的端点 ID。该端点定义了在摄取过程中为 body 字段内容生成嵌入的推理服务。
作为背景说明,semantic_text 是在 Elasticsearch 8.15 中引入的,它简化了语义搜索。若要深入了解我们的方法,建议查看我们的原始博客文章和 Elasticsearch 文档。
markdown
`
1. PUT pdf-documentation-reader
2. {
3. "mappings": {
4. "properties": {
5. "body": {
6. "type": "semantic_text",
7. "inference_id": "minilm-l6"
8. }
9. }
10. }
11. }
`AI写代码设置 completion 端点
在生成主要组件后,一个关键步骤是创建 Elasticsearch 中的推理完成端点(inference completion endpoint)。该端点可以通过生成提示与所选的 Large Language Model (LLM) 进行交互,并提供必要的认证密钥。
具体来说,你将使用名为 completion 的 completion 任务类型(更多细节请参考 Elasticsearch 文档)。
bash
`
1. PUT _inference/completion/openai_chat_completions
2. {
3. "service": "openai",
4. "service_settings": {
5. "api_key": "<<Your API KEY>>",
6. "model_id": "<<Chosen Model>>",
7. "url": "<<Your Service URL>>"
8. }
9. }
`AI写代码创建完成后,你可以通过发送一个简单问题来测试 LLM 集成,如下面的示例所示。
bash
`
1. POST _inference/completion/openai_chat_completions
2. {
3. "input": "When Elasticsearch was created ?"
4. }
`AI写代码输出:
markdown
`
1. {
2. "completion": [
3. {
4. "result": "**Elasticsearch** was first released in **2010**. It was created by Shay Banon, who began working on the project in 2009, and released the first version (0.4) in February **2010**. Elasticsearch is a distributed, open-source search and analytics engine built on top of Apache Lucene."
5. }
6. ]
7. }
`AI写代码搜索你的数据
当用户通过界面提交查询时,它会在现有内容中启动语义搜索,以识别相关的 PDF 段落。与用户输入语义相似的段落随后会被整合到提示中,由 LLM 生成最终答案。语义查询使用之前介绍的 semantic_text 字段来简化处理。
json
`
1. "query": {
2. "semantic": {
3. "field": "body",
4. "query": "How long does the ECO program last ?"
5. }
6. }
`AI写代码虽然我们的示例提供了一个简化的方法,但关于查询 semantic_text 字段的更多细节可以在这里找到。对于需要增强相关性和精确度的高级应用,可以实现一种混合搜索方法,将经典词汇搜索(BM25)与语义搜索结合起来。
整合所有内容:基于 Elasticsearch 的家电手册 RAG 应用
构建故障排查应用的最后一步是将文档检索过程与 LLM 无缝集成,以提供智能、具上下文感知的响应。
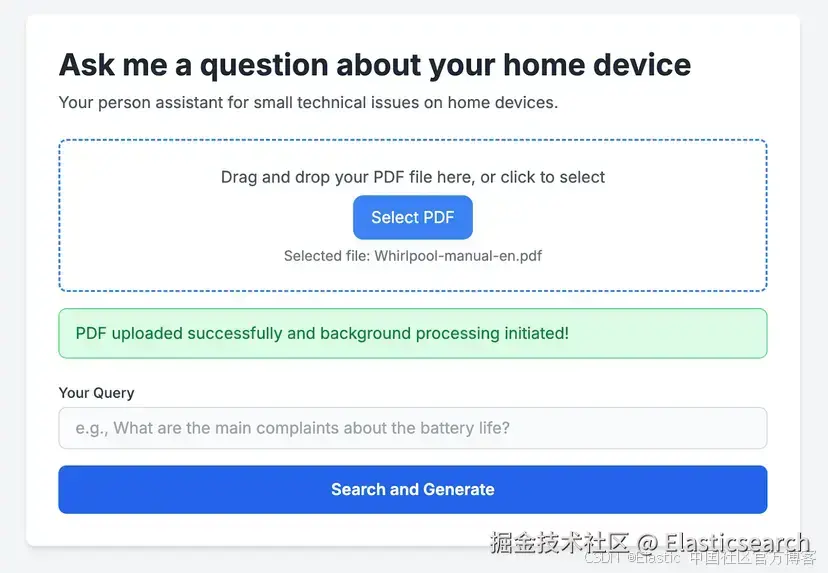
下图的系统概览展示了各个组件的交互,并对所涉及的步骤进行了高层次的回顾。
1)PDF 摄取、嵌入与存储:
- 该过程从原始 PDF 家电手册开始,这些手册包含大量文本、图像和复杂布局。每个 PDF 手册被拆分为单独的页面,然后将每页提取的文本摄取到 Elasticsearch 中。使用解析库提取文本内容和元数据(如型号、制造商和文档类型),并识别关键章节或图表。
- 从每页 PDF 提取的文本被仔细划分为较小的、语义连贯的 "块"。这些块作为 dense_vectors 存储在 Elasticsearch 索引中,利用 semantic_text 字段类型,并依赖为 text_embedding 任务创建的 inference_endpoint。
2)用户查询与上下文检索:
当用户提出故障排查问题(例如,"How long does the ECO Program last?")时,这作为起点。用户的查询使用与摄取的文档块相同的嵌入模型转换为稠密向量嵌入。这确保查询向量与文档块向量处于相同语义空间,从而允许进行有意义的相似性比较。然后使用嵌入的用户查询在 Elasticsearch 文档存储中执行相似性搜索。这些文档块最可能包含回答问题所需的相关信息。
3)提示构建与 LLM 输入:
-
上下文化 :检索到的文档块(原始文本)被动态插入到一个构建好的提示中,该提示将发送给 LLM。提示通常包括:
-
LLM 的指令:关于如何使用提供的信息、期望的输出格式以及任何约束的明确指南。
-
用户的原始查询:用户实际提出的问题。
-
检索到的上下文:最相关块的文本内容,通常明确标注为 "Context" 或 "Relevant Documents"。
-
-
示例提示结构:
markdown
`
1. You are an expert appliance troubleshooter. Using *only* the following context, answer the user's question. If the information is not in the context, state that you cannot answer based on the provided information.
4. **Context:**
5. [Retrieved Chunk 1 Text]
6. [Retrieved Chunk 2 Text]
7. [Retrieved Chunk 3 Text]
8. ...
11. **User Question:** [User's Original Query]
`AI写代码4)LLM 生成:
- 答案综合:完整构建的提示,包括用户查询和相关检索到的上下文,然后发送给 LLM。LLM 处理该输入,并基于提供的信息生成连贯、上下文准确且类人化的响应。它综合检索到的文档块中的信息,为用户的问题提供直接答案。
以下是对我们之前问题 How long does the ECO program last?" 的输出示例:
结论
在本文中,我们演示了如何利用 Elasticsearch 构建 RAG 应用,通过使用 semantic_text 映射等功能。这简化了数据摄取过程,使你可以轻松开始使用语义搜索,同时提供合理的默认设置。它还让你专注于搜索,而不必担心如何索引、生成或查询嵌入。
此外,我们还展示了如何利用最新的 inference_API,它简化了在数据上使用机器学习模型的过程。例如,你可以用它执行推理操作(如为语义搜索生成嵌入),并将其与 LLM 集成进行提示回答。
希望这个应用也能帮助你解决技术问题,而不必额外花钱请技术人员上门。
在本文中,我们可能使用了第三方生成式 AI 工具,这些工具由各自的所有者拥有和运营。Elastic 对这些第三方工具没有控制权,也不对其内容、操作或使用承担任何责任,也不对你使用这些工具可能产生的任何损失或损害负责。在使用 AI 工具处理个人、敏感或机密信息时,请谨慎操作。你提交的任何数据可能会被用于 AI 训练或其他用途。无法保证你提供的信息会被安全或保密地保存。使用前,你应熟悉任何生成式 AI 工具的隐私政策和使用条款。