我最近的工作涉及到数据挖掘,需要从海量文档中,进行精确的、结构化的信息提取。
如果用传统的RAG方案,信息检索的精确性很难保障。一个更好的思路,是让大模型直接理解文档,精准抽取出我们想要的信息。
然而,这个方案也带来了许多工程层面的挑战:
- 大模型的上下文窗口有限,怎么把长文切成合适的粒度?
- 如何保证提取的信息,既没有错乱,也没有遗漏?
- 处理长文时,怎样才能更快?
- 提取到的信息,如何精准地溯源到原文出处,确保其可靠性?
关于这些挑战,我们或许能从Google的开源项目LangExtract中找到答案。
LangExtract是怎么做的?
LangExtract是一个Python库。它能根据你的指令,让大模型从非结构化文本中,提取出精确、可靠的结构化信息。
最关键的是,它能保证每一条数据,都能精准追溯到原文的具体出处。
官方用《罗密欧与朱丽叶》(www.gutenberg.org/files/1513/...

可以看到,挖掘出的每个实体,都能在原文中高亮定位。这个效果,可以说比较惊艳了。
接下来,我们深入源码,看看它到底是如何做到的。
1. 智能分块
面对大模型有限的上下文窗口,LangExtract也需要先对文档进行切分。
但它的切分,并不是按固定长度"一刀切"。因为那样会破坏句子的完整性,影响语义理解。
它的方式更聪明:优先尊重语言的自然边界(如句子、段落),再用"贪心"策略,把上下文窗口填满。
为此,LangExtract设计了一个智能分块 模块(chunking.py),它用一套精心设计的"三重策略"来生成文本块。
分块的三重策略
-
策略1(最优情况):贪心填充完整句子
这个策略的的核心理念是尽可能将多个完整的句子打包进一个分块,以最大化利用模型上下文窗口,从而为模型提供丰富的上下文。
ini# 在 __next__ 方法中 # ... 首先处理完一个句子,得到 curr_chunk ... if self.broken_sentence: self.broken_sentence = False else: # 循环获取下一个完整的句子 for sentence in self.sentence_iter: # 尝试将新句子合并到当前块中 test_chunk = create_token_interval( curr_chunk.start_index, sentence.end_index ) # 如果合并后超出缓冲区大小 if self._tokens_exceed_buffer(test_chunk): # 那么上一个状态的 curr_chunk 就是本次的最佳结果 # ... 返回 curr_chunk ... else: # 如果没超,就接受合并,继续尝试下一个句子 curr_chunk = test_chunk这段代码完美体现了"贪心"策略。它会不断尝试包含下一个完整的句子,直到上下文的缓冲区装不下为止。这种方式保证了分块内部的语义连贯性。
"
关于如何判断一个句子的边界,LangExtract并没有使用重量级的NLP来进行语法分析,而是采用了一套简单、高效的启发式规则。它主要依赖两种规则来判断句子的结束:
"1. 基于标点符号的判断
这是比较常见的句子切分方式。
iniif tokens[i].token_type == TokenType.PUNCTUATION: if _is_end_of_sentence_token(text, tokens, i, _KNOWN_ABBREVIATIONS): return TokenInterval(start_index=start_token_index, end_index=i + 1)通过代码可以看出,它首先检查当前词元(
tokens[i])是不是一个标点符号,如果是,它会进一步通过_is_end_of_sentence_token方法来区分真正的句末标点和缩写词中的标点。例如,它需要判断"Mr."中的.不是句子的结尾,而"Hello World."中的.是句子的结尾。
"2. 基于换行符的判断
这种规则主要用于处理格式化的文本,比如段落之间的换行。
scssif _is_sentence_break_after_newline(text, tokens, i): return TokenInterval(start_index=start_token_index, end_index=i + 1)它调用
_is_sentence_break_after_newline来判断是否存在一个换行符,同时换行符的下一个词元以大写字母开头(如果是英文的话)。这通常被认为是一个非常强的句子边界信号。 -
策略2 (次优情况): 智能切分超长句子
如果单个句子就超过了上下文窗口,不能硬塞,也不能随意切。LangExtract会尝试在句子内部寻找最合适的断点,优先选择换行符
\n。ini# 在 __next__ 方法中,遍历一个长句子的 tokens for token_index in range(curr_chunk.start_index, sentence.end_index): # 记录最新的换行符位置 if self.tokenized_text.tokens[token_index].first_token_after_newline: start_of_new_line = token_index test_chunk = create_token_interval(curr_chunk.start_index, token_index + 1) if self._tokens_exceed_buffer(test_chunk): # 如果超限,检查是否存在一个有效的换行符可以作为断点 if start_of_new_line > 0 and start_of_new_line > curr_chunk.start_index: # 在换行符处切断 curr_chunk = create_token_interval( curr_chunk.start_index, start_of_new_line ) # 否则,就在上一个 token 处切断 (代码中通过循环结束前的 curr_chunk 状态隐式实现) # ... 更新 sentence_iter 位置并返回 curr_chunk ... self.broken_sentence = True return TextChunk(...)这个设计非常巧妙。它在填充缓冲区的过程中,始终"记住"最近的换行符。一旦超限,它会优先"退回"到换行符进行切分。这对于处理诗歌、代码等格式化文本,至关重要。
-
策略3 (极端情况): 处理单个超长Token
考虑到某些极端情况,比如一个超长的URL或者一个没有空格的字符串,可能单个token的长度就超过了上下文窗口限制大小。算法也必须能够健壮地处理这种情况。
ini# 在 __next__ 方法的开头 sentence = next(self.sentence_iter) # 构造一个只包含第一个 token 的 chunk curr_chunk = create_token_interval( sentence.start_index, sentence.start_index + 1 ) # 检查这一个 token 是否就已超限 if self._tokens_exceed_buffer(curr_chunk): # 如果是,那么这个 token 自身就构成一个 chunk self.sentence_iter = SentenceIterator( self.tokenized_text, curr_token_pos=sentence.start_index + 1 ) # ... 返回这个单 token 的 chunk ...这是保证算法鲁棒性的关键。即使文本不规范,流程也能继续,不会崩溃。
通过这套策略,智能分块模块为大模型提供了高质量的输入,这是后续精准提取的基础。
2. 多遍提取与智能合并
分块完成后,就要喂给大模型进行挖掘了。
为了提升召回率 ,找出所有相关实体,LangExtract设计了一套多遍提取机制。它的思路是:通过多次、独立地"审视"同一段文本,增加发现被遗漏实体的机会。
ini
for pass_num in range(extraction_passes):
logging.info("Starting extraction pass %d of %d", pass_num + 1, extraction_passes)
# 每一遍都是完全独立的处理
for annotated_doc in self._annotate_documents_single_pass(
document_list, # 相同的文档
resolver, # 相同的解析器
max_char_buffer, # 相同的参数
batch_length,
debug=(debug and pass_num == 0), # 只在第一遍显示进度
**kwargs,
):
# 收集每一遍的结果
document_extractions_by_pass[doc_id].append(annotated_doc.extractions or [])通过源码可以看到,它复用了单次提取的逻辑,同时保障了每一遍提取都是对原文的全新的、独立的分析,而不是在上一遍剩下的文本中进行提取。
当多遍提取完成后,我们得到了多个可能包含重复或者重叠实体的提取列表。如何将它们融合成一个干净、无冲突的最终列表?
LangExtract的核心策略是:首遍优先,后来者补白(代码注释中的描述,我觉得非常形象)
这里依旧贴出相关的源码讲解:
ini
def _merge_non_overlapping_extractions(
all_extractions: list[Iterable[data.Extraction]],
) -> list[data.Extraction]:
...
# 1. 首遍优先:第一遍提取的所有结果被无条件接受
merged_extractions = list(all_extractions[0])
# 2. 遍历后续遍数的结果
for pass_extractions in all_extractions[1:]:
# 3. 考察后续遍数中的每一个"候选"提取实体
for extraction in pass_extractions:
overlaps = False
if extraction.char_interval is not None:
# 4. 检查该候选实体是否与任何"已接受"的实体存在重叠
for existing_extraction in merged_extractions:
if existing_extraction.char_interval is not None:
if _extractions_overlap(extraction, existing_extraction):
overlaps = True
break # 一旦发现重叠,立即停止检查
# 5. 只有完全不重叠的"候选者"才能被接纳
if not overlaps:
merged_extractions.append(extraction)
return merged_extractions首先,第一遍提取的结果具有最高优先级,被全盘接受。
从第二遍开始,每个提取出的实体都必须经过严格审查:它所占据的位置,是否与已合并的列表中的任何实体有重叠?任何位置的重叠都会被过滤掉。只有在"文本空白区"找到的新实体,才会被加入最终列表。
读这里的源码时我有一个疑问,为什么要采取首遍优先的策略?
后来仔细想了一下,如果允许后续提取出的实体覆盖或者修改第一遍的结果,那就需要一套复杂的仲裁逻辑来决定哪个结果更好,这可能导致系统变得复杂且不稳定。
通过多遍提取与智能合并的策略,此时我们就已经从文档中相对全面的提取出了所需的一系列实体。
然而,尽管采用了多遍提取的原则,大模型依然可能臆想出一些不在文档中存在的实体。此时,溯源就非常重要,如何才能在原文中,精准地找到模型提取内容对应的位置?
LangExtract设计了一套精准溯源策略来解决这个问题。
3. 精准溯源
LangExtract的精准来源定位是通过一个复杂的后处理对齐算法来实现,而不是依赖大模型直接提供位置信息。
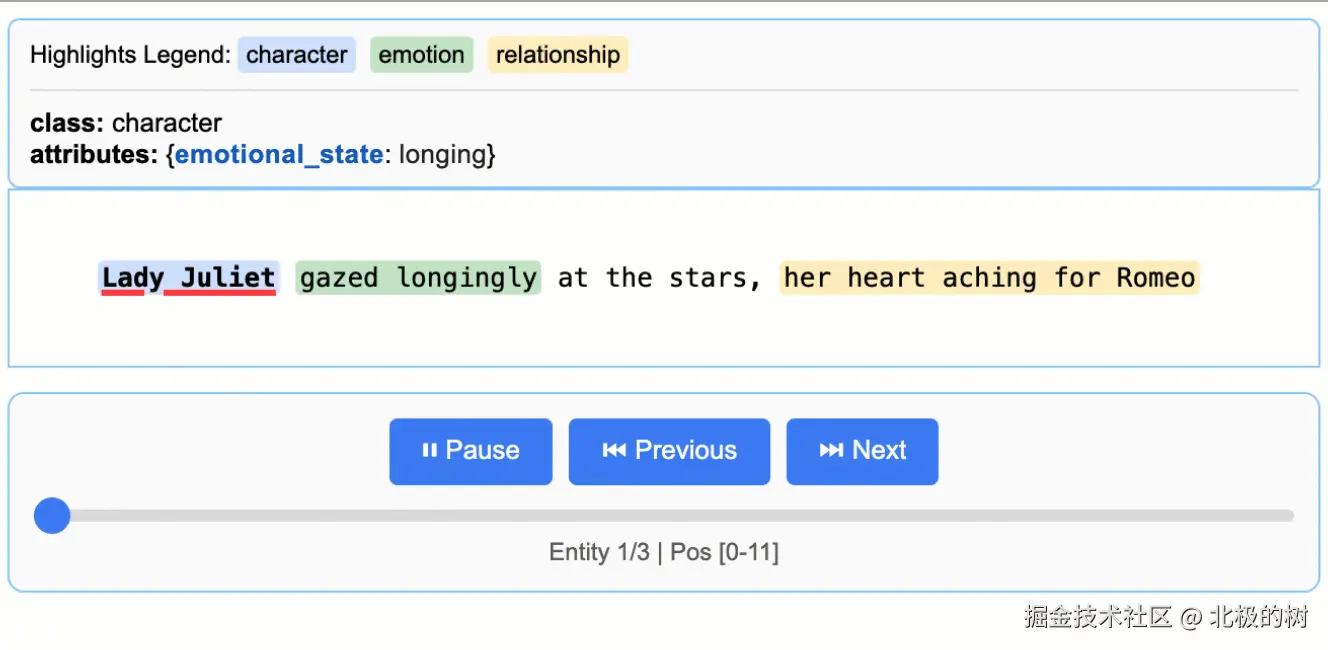
通过走读源码(langextract/resolver.py),发现它采取的是双层对齐策略来实现。
第一层比较简单,就是使用Python的difflib.SequenceMatcher进行词元级别的精确匹配。
ini
self.matcher = difflib.SequenceMatcher(autojunk=False)
# 设置精确匹配的两个对象为源文档和挖掘出的实体
self.source_tokens = source_tokens
self.extraction_tokens = extraction_tokens
self.matcher.set_seqs(a=source_tokens, b=extraction_tokens)
# 开始精确匹配
self.matcher.get_matching_blocks()然而,只依赖精确匹配肯定不行,因为大模型提取出的实体不一定和原文档中的字符串完全保持一致。比如多了一个"的",或者把"Appples"总结成了"Apple"。
因此,当精确匹配失败时,就会进入第二层的模糊匹配 ,也就是提取的文本和源文本中某个片段可能不完全一样(比如多了个词、少了个词、或者单次拼写有细微差别),我们仍然希望能够将它们成功的对应起来。
下面我们来看下LangExtract设计的模糊匹配算法。
第一步:消除噪音
在开始比较之前,首先要解决一个基础的问题:怎么让Apple和apple,以及apples在比较时被视为同一个东西?
这里LangExtract设计了一个简单高效的方案:轻量词干化
"
在解释"轻量词干化"之前,我们首先需要理解什么是"词干化"。
在NLP中,词干化是将单词简化为其基本形式或词干的过程。这样做的主要目的是将一个词的不同变体(如复数、时态变化)归为一类,以便于文本分析和信息检索。例如"running", "runs", "ran" 的词干可能是 "run"。有比较多知名的词干话算法来专门做这件事,例如Porter Stemmer、Snowball Stemmer 等。
LangExtract并没有使用上述的这些重量级词干库,它采取策略如下:
less
@functools.lru_cache(maxsize=10000)
def _normalize_token(token: str) -> str:
token = token.lower()
if len(token) > 3 and token.endswith("s") and not token.endswith("ss"):
token = token[:-1]
return token可以看到,它只是将词元转为小写,并去掉词尾的 "s"(但保留 "ss" 结尾的词,如 "address")。这是一种简单有效的处理单复数问题的方法。同时,使用了一个LRUCache来缓存处理结果,因为在整个文本处理过程中,同一个词元可能会被规范化成千上万次,这个缓存可以极大地提升性能。
第二步:滑动窗口 + 序列匹配
当所有的词元都被词干化后,就开始进行模糊匹配。
ini
# 核心算法逻辑
extraction_tokens = list(_tokenize_with_lowercase(extraction.extraction_text))
extraction_tokens_norm = [_normalize_token(t) for t in extraction_tokens]
# 使用滑动窗口扫描源文本
for start_idx in range(max_window):
for window_size in range(len_e, max_window - start_idx + 1):
window_tokens = source_tokens_norm[start_idx:start_idx + window_size]
# 快速预检查:计算词元交集
window_counts = collections.Counter(window_tokens)
overlap = sum((window_counts & extraction_counts).values())
if overlap < min_overlap:
continue # 跳过不满足最小重叠的窗口
# 使用 SequenceMatcher 计算相似度比率
matcher.set_seq1(window_tokens)
ratio = matcher.ratio()
if ratio > best_ratio:
best_ratio = ratio
best_span = (start_idx, window_size)LangExtract在这里首先使用了一个滑动窗口的机制,这个窗口首先设定为待溯源实体的长度,让这个窗口在原文上从头到尾滑动。然后不断增大窗口大小。
每滑动到一个位置,就计算窗口里的内容和提取结果的相似度,记录下相似度最高的那个窗口位置。
每次循环滑动都进行一次相似度计算非常耗时,于是LangExtract在计算之前加入了一个快速预检查逻辑: 通过collections.Counter能快速统计出当前窗口和提取结果最多有多少个共同的词,如果低于最小的重叠率,则直接跳过。
这个逻辑就像一个高效的过滤器,过滤掉了绝大多数不可能匹配的窗口,让性能成倍数的提升。
结语
看完源码,我的最大体会是,LangExtract并没有用什么花哨的模型,而是用基础的数据结构、经典的算法思想和务实的工程技巧,优雅地解决了模糊文本定位这个棘手的问题。
从尊重语言规律的智能分块,到平衡召回率与稳定性的多遍合并策略,再到结合经典算法实现的双层对齐溯源,LangExtract为我们展示了如何利用基础而强大的工具,去解决大模型在落地应用中最棘手的工程挑战。