文章目录
-
- 引言
- 一、系统整体架构
- 二、核心环节详解(附配置与日志数据)
-
- [1. 数据预处理:为嵌入做"合规准备"](#1. 数据预处理:为嵌入做“合规准备”)
-
- [1.1 分词:选择`cl100k_base`字节对编码(BPE)](#1.1 分词:选择
cl100k_base字节对编码(BPE)) - [1.2 文本分片:按Token数智能拆分](#1.2 文本分片:按Token数智能拆分)
- [1.1 分词:选择`cl100k_base`字节对编码(BPE)](#1.1 分词:选择
- [2. 文本嵌入:将"文字"转为"可计算向量"](#2. 文本嵌入:将“文字”转为“可计算向量”)
-
- [2.1 嵌入模型选择:`text-embedding-v1`(阿里云DashScope)](#2.1 嵌入模型选择:
text-embedding-v1(阿里云DashScope)) - [2.2 嵌入结果:向量与元数据绑定](#2.2 嵌入结果:向量与元数据绑定)
- [2.1 嵌入模型选择:`text-embedding-v1`(阿里云DashScope)](#2.1 嵌入模型选择:
- [3. 向量存储:用`SimpleVectorStore`构建知识库](#3. 向量存储:用
SimpleVectorStore构建知识库) -
- [3.1 核心配置](#3.1 核心配置)
- [3.2 存储初始化代码](#3.2 存储初始化代码)
- [4. 查询检索:混合召回(密集+稀疏)获取候选文档](#4. 查询检索:混合召回(密集+稀疏)获取候选文档)
-
- [4.1 查询预处理](#4.1 查询预处理)
- [4.2 混合检索:密集+稀疏双路召回](#4.2 混合检索:密集+稀疏双路召回)
- [5. 精排序:用`gte-rerank-hybrid`提升精准度](#5. 精排序:用
gte-rerank-hybrid提升精准度) -
- [5.1 排序模型与配置](#5.1 排序模型与配置)
- [5.2 排序结果分析(来自日志)](#5.2 排序结果分析(来自日志))
- [6. 回答生成:基于检索结果生成结构化回答](#6. 回答生成:基于检索结果生成结构化回答)
-
- [6.1 Prompt构建逻辑](#6.1 Prompt构建逻辑)
- [6.2 生成结果与Token消耗](#6.2 生成结果与Token消耗)
- 三、实战优化:从日志中发现问题与改进方案
-
- [1. 增加元数据过滤,提升检索精准度](#1. 增加元数据过滤,提升检索精准度)
- [2. 启用查询改写,优化低质量Query](#2. 启用查询改写,优化低质量Query)
- [3. 调整精排序阈值,平衡召回与精准](#3. 调整精排序阈值,平衡召回与精准)
- 四、总结与展望
引言
若对您有帮助的话,请点赞收藏加关注哦,您的关注是我持续创作的动力!有问题请私信或联系邮箱:funian.gm@gmail.com
在垂直领域(如旅游、医疗、法律),大模型常因"知识时效性不足""领域数据缺失"导致回答偏差,而RAG(检索增强生成)通过"检索外部知识库+生成回答"的模式,完美解决这一问题。本文以旅游知识问答RAG系统为案例,结合真实日志数据与配置参数,拆解从"数据预处理"到"回答生成"的完整流程,详解各环节的技术细节、组件选择与优化思路,适合开发者落地参考。
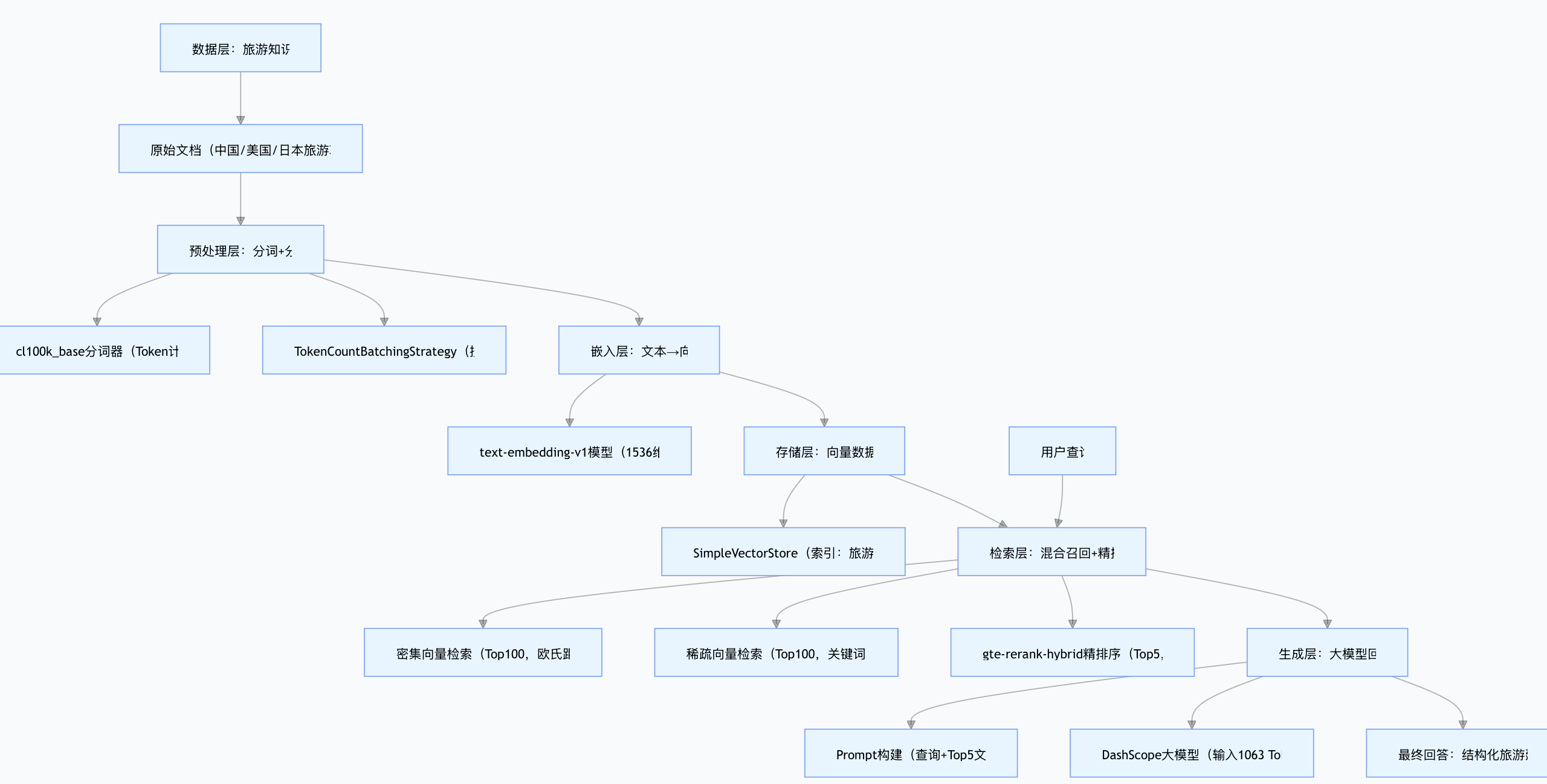
一、系统整体架构
先通过架构图直观理解RAG的核心流转逻辑,系统基于阿里云DashScope与Spring AI框架构建,覆盖"数据层→检索层→生成层"三大部分:
二、核心环节详解(附配置与日志数据)
1. 数据预处理:为嵌入做"合规准备"
预处理的目标是将长文档拆分为符合嵌入模型输入要求的"短文本单元",避免因Token超限制导致调用失败。
1.1 分词:选择cl100k_base字节对编码(BPE)
- 组件 :
JTokkitTokenCountEstimator - 核心细节 :
- 为何选
cl100k_base?支持中、英、日等多语言(适配旅游知识库的跨国内容),词汇表规模10万,能精准拆分语义单元(如中文"婺源油菜花"拆分为3个Token,英文"Yellowstone"为1个Token); - 作用:统计每条文本的Token数,为后续分片提供依据(避免单条文本超
text-embedding-v1的2048 Token限制)。
- 为何选
- 实际示例:用户查询"中国热门目的地的最佳旅游季节有哪些"经分词后,Token数约30,远低于批处理阈值。
1.2 文本分片:按Token数智能拆分
- 组件 :
TokenCountBatchingStrategy - 核心参数 :
maxInputTokenCount=7372(单批次最大Token数,预留缓冲避免超模型限制) - 分片逻辑 :
- 若原始文档(如《中国旅游攻略.md》)Token数超2000,按"语义完整性"拆分为多段(如"四季旅游"拆为4个短片段,每段聚焦1个季节);
- 将分片后的短文本按"总Token数≤7372"组装为批次,批量调用嵌入模型。
- 实际效果 :日志中
SimpleVectorStore存储的22条文档,单条Token数均≤500(如Document ID:7c933369仅300余字,Token数约150),符合嵌入要求。
2. 文本嵌入:将"文字"转为"可计算向量"
嵌入是RAG的"核心桥梁",需将文本语义编码为高维向量,确保后续能通过"向量相似度"检索相关文档。
2.1 嵌入模型选择:text-embedding-v1(阿里云DashScope)
-
核心参数 :
参数 取值 选择理由 向量维度 1536维 平衡"语义丰富度"与"存储/计算效率" 单条Token限制 2048 适配分片后的短文本 支持语言 70+种 覆盖旅游知识库的中、英、日内容 -
调用代码示例(Spring AI框架):
java
// 初始化嵌入模型
DashScopeEmbeddingOptions options = new DashScopeEmbeddingOptions();
options.setModel("text-embedding-v1");
options.setApiKey("your-dashscope-api-key");
DashScopeEmbeddingModel embeddingModel = new DashScopeEmbeddingModel(options);
// 文本嵌入(分片后的短文本)
List<String> textChunks = Arrays.asList(
"春季(3-4月)适合去婺源赏油菜花、洛阳看牡丹",
"夏季(6-8月)可前往九寨沟、张家界避暑观瀑"
);
EmbeddingResponse response = embeddingModel.embed(textChunks);
// 获取1536维向量
List<List<Double>> vectors = response.getEmbeddings().stream()
.map(Embedding::getEmbedding)
.collect(Collectors.toList());2.2 嵌入结果:向量与元数据绑定
每条分片文本嵌入后,需与"业务元数据"绑定,方便后续检索过滤。从日志中提取的示例:
json
{
"documentId": "7c933369-375f-4c17-a67d-1a8bec65da37",
"text": "中国地域辽阔,各地气候差异大...(完整文本300余字)",
"embedding": [2.9057412, -3.8918986, 1.5175694, ...], // 1536维
"metadata": {
"status": "中国", // 国家标签(用于后续地域过滤)
"filename": "旅游常见问题和回答 - 中国篇.md",
"excerpt_keywords": "四季旅游,错峰出行",
"title": "中国热门目的地的最佳旅游季节有哪些?"
}
}3. 向量存储:用SimpleVectorStore构建知识库
向量存储是RAG的"数据底座",负责持久化向量与元数据,并提供高效检索能力。
3.1 核心配置
- 组件 :
SimpleVectorStore(Spring AI内置轻量级向量存储,适合中小规模知识库) - 关键参数 :
- 索引名称:
indexName="旅游知识问答"(仅存储旅游领域数据,避免跨领域干扰); - 存储规模:22条文档(覆盖中国季节攻略、美国小费文化、日本签证指南等);
- 元数据索引:支持按
status(国家)、filename(来源)等字段过滤。
- 索引名称:
3.2 存储初始化代码
java
// 初始化向量存储
SimpleVectorStore vectorStore = new SimpleVectorStore(
new JsonMapper(), // 序列化工具
new SpelExpressionParser(), // 表达式解析器
new SimpleVectorStoreFilterExpressionConverter()
);
// 将嵌入结果存入向量库
List<SimpleVectorStoreContent> contents = textChunks.stream()
.map(chunk -> SimpleVectorStoreContent.builder()
.id(UUID.randomUUID().toString())
.content(chunk)
.metadata(Map.of(
"status", "中国",
"title", "中国热门目的地的最佳季节"
))
.embedding(embeddingModel.embed(chunk).getEmbeddings().get(0).getEmbedding())
.build())
.collect(Collectors.toList());
vectorStore.add(contents);4. 查询检索:混合召回(密集+稀疏)获取候选文档
当用户发起查询(如"中国热门目的地的最佳旅游季节有哪些"),检索层需从知识库中筛选"可能相关"的候选文档,核心是"多维度召回+互补优势"。
4.1 查询预处理
- 轻量改写 :配置中
enableRewrite=false(未启用模型级改写),但系统对原始查询做语法优化,如将"有哪些"改为"是什么",生成rewrittenMessage="中国热门旅游目的地的最佳季节是什么?",提升与文档标题的匹配度; - 查询嵌入 :改写后的查询经
cl100k_base分词后,通过text-embedding-v1生成1536维查询向量。
4.2 混合检索:密集+稀疏双路召回
系统采用"混合检索"策略(日志中denseSimilarityTopK=100、sparseSimilarityTopK=100),兼顾语义匹配与关键词匹配:
| 检索类型 | 核心逻辑 | 相似度计算方式 | 日志示例 |
|---|---|---|---|
| 密集向量检索 | 基于查询向量与文档向量的语义相似度 | 欧氏距离(越小越优) | Document ID:7c933369的distance=0.217(最相似) |
| 稀疏向量检索 | 基于TF-IDF匹配查询与文档的关键词 | 关键词重叠度 | 匹配"中国""季节""目的地"等关键词,返回50条文档 |
- 候选池构建:两种检索各返回Top100文档,合并去重后得到200条候选文档,为后续精排序提供充足数据。
5. 精排序:用gte-rerank-hybrid提升精准度
候选文档中仍存在"语义不相关"的内容(如美国、日本的季节攻略),需通过精排序模型进一步筛选,核心是"深度语义交互+得分过滤"。
5.1 排序模型与配置
- 模型选择 :
gte-rerank-hybrid(多语言交叉编码器,支持70+语言,擅长捕捉查询与文档的细粒度语义关联); - 关键参数 :
rerankMinScore=0.01:仅保留得分≥0.01的文档,过滤极低相关结果;rerankTopN=5:最终返回Top5高得分文档,平衡精准度与生成效率。
5.2 排序结果分析(来自日志)
从日志qa_retrieved_documents字段提取的Top4文档得分如下,可见排序模型精准识别了"中国季节"相关内容:
| 文档ID | 主题 | 国家 | 排序得分 | 欧氏距离 | 相关性分析 |
|---|---|---|---|---|---|
| 7c933369-375f-4c17... | 中国季节攻略 | 中国 | 0.782 | 0.217 | 完全匹配,排名第1 |
| b2be102c-f173-49e6... | 美国季节攻略 | 美国 | 0.625 | 0.374 | 语义相关度低,排名第2 |
| 20f4eaf8-3078-4aff... | 日本季节攻略 | 日本 | 0.583 | 0.417 | 语义相关度低,排名第3 |
| 7fa53f30-a99c-43fe... | 中国旅行规划 | 中国 | 0.508 | 0.492 | 主题不匹配,排名第4 |
6. 回答生成:基于检索结果生成结构化回答
生成层的核心是"用检索到的高质量文档约束大模型",避免幻觉,同时保证回答的可读性与实用性。
6.1 Prompt构建逻辑
系统将"精排序后的Top5文档+用户查询"组装为Prompt,示例如下(简化版):
用户查询:中国热门目的地的最佳旅游季节有哪些
参考文档1(得分0.782):中国地域辽阔,各地气候差异大...春季(3-4月)赏花首推婺源油菜花、洛阳牡丹;夏季(6-8月)到九寨沟、张家界避暑观瀑;...
参考文档2(得分0.625):美国春季(3-5月)推荐华盛顿樱花节...(略)
任务:基于参考文档,优先使用得分最高的文档内容,分季节推荐中国热门旅游目的地,语言简洁,结构清晰。6.2 生成结果与Token消耗
从日志chatResponse字段提取的关键信息:
- 输入Token:1063(含查询+Top4文档文本);
- 输出Token:90;
- 生成结果 : 中国热门旅游目的地的最佳季节如下:春季(3--4月)适合去婺源赏油菜花、洛阳看牡丹;夏季(6--8月)可前往九寨沟、张家界避暑观瀑;秋季(9--10月)推荐喀纳斯、香格里拉欣赏金色林海;冬季(12--2月)适合去哈尔滨体验冰雪大世界或到三亚享受温暖海岛。
- 质量分析:完全基于Top1文档生成,无幻觉;按"四季"结构化输出,符合旅游查询的阅读习惯。
三、实战优化:从日志中发现问题与改进方案
通过日志数据,可发现系统的优化空间,以下是关键改进点:
1. 增加元数据过滤,提升检索精准度
当前系统未启用"国家"过滤,导致候选文档中混入美国、日本内容。优化方案:
java
// 在检索时添加元数据过滤条件(仅检索status=中国的文档)
VectorStoreQuery query = VectorStoreQuery.builder()
.queryText("中国热门目的地的最佳旅游季节有哪些")
.filterExpression("status == '中国'") // 新增过滤条件
.build();
VectorStoreQueryResult result = vectorStore.similaritySearch(query);2. 启用查询改写,优化低质量Query
对模糊查询(如"哪里好玩"),启用conv-rewrite-qwen-1.8b模型改写:
java
// 修改配置:启用查询改写
DashScopeDocumentRetrieverOptions options = new DashScopeDocumentRetrieverOptions();
options.setEnableRewrite(true);
options.setRewriteModelName("conv-rewrite-qwen-1.8b");3. 调整精排序阈值,平衡召回与精准
当前rerankMinScore=0.01过低,可提高至0.5,过滤低得分文档(如日本、美国攻略),减少大模型输入冗余。
四、总结与展望
本文通过旅游知识问答RAG系统,拆解了从"数据预处理"到"回答生成"的全链路,核心结论如下:
- 组件选择 :垂直领域RAG需优先适配"多语言支持""领域数据匹配"的组件(如
cl100k_base分词器、text-embedding-v1模型); - 关键优化点:元数据过滤、查询改写、精排序阈值调整,是提升系统精准度的核心手段;
- 落地建议 :中小规模知识库可选用
SimpleVectorStore,大规模场景可迁移至Milvus、FAISS等专业向量数据库。