模型组成
经研究表明:对模型中多个层组成的块进行研究,效果好过对单独每一层进行研究
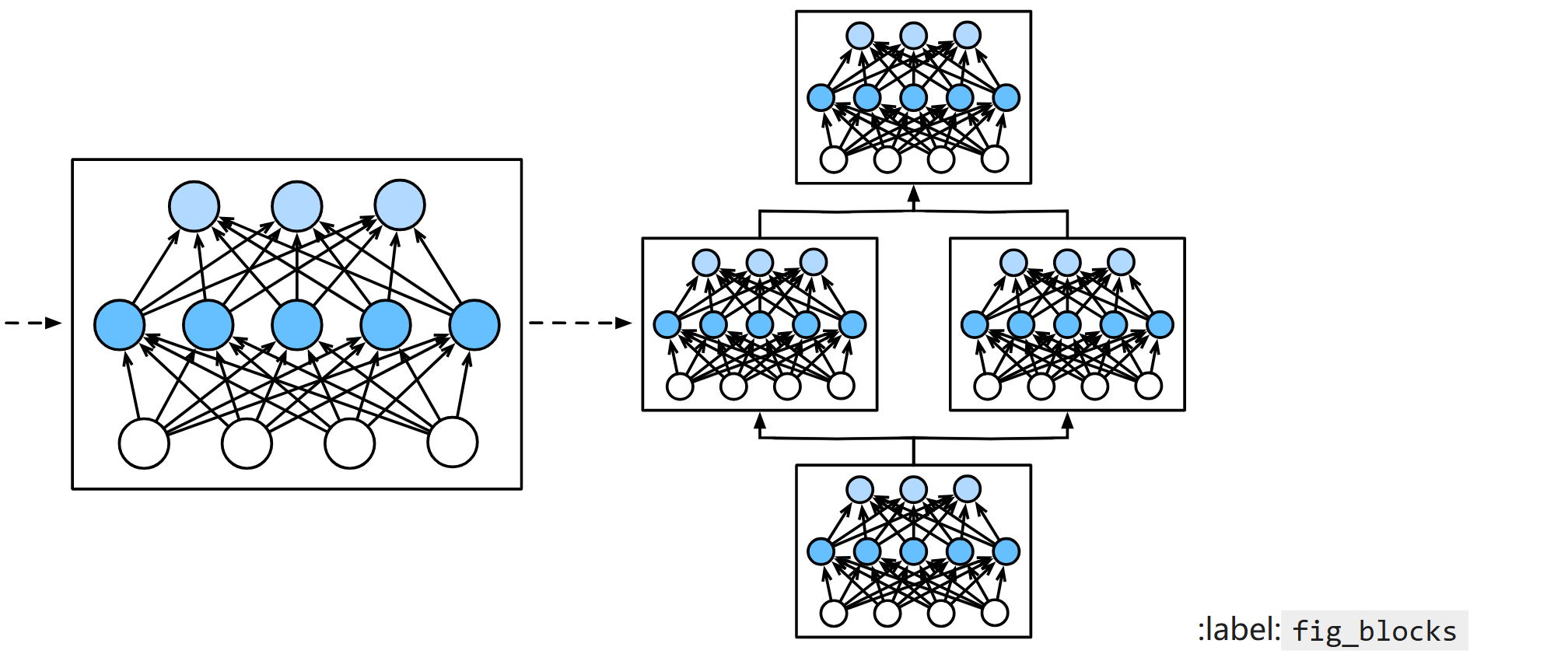
自定义块
一个块就是一个类,其中包含构造函数和前向传播函数。一般我们直接让块继承pytorch里的块类,方便我们定义。
顺序块
我们在pytorch中经常使用的Sequential是一个顺序块,能顺序执行我们提供的层,在书中,我用for循环遍历字典的方式实现了我们自己的一个顺序块
在前向传播中执行代码
我们可以直接将代码写入自定义块中的前向传播方法,将原本的顺序直线改成可知控制的分支和循环。
甚至还能嵌套其他块
参数管理
pytorch提供了接口让我们能我们查看,修改参数。
参数的数据结构
基本的数据结构是有序字典,可以通过参数的名称访问参数的值。
当模块中有嵌套时,模块之前的参数会以树的方式存储
参数的初始化
pytorch内置了参数的初始化方法(一些经典的初始化方法)
pytorch也提供了你进行自定义初始化的接口
参数绑定
这是一个很神奇的功能,他可以将一套参数同时用到模型的多个层中(层的形状要一样),要注意的是,在修改参数时,修改一个地方的参数其他调用了这套参数的层也会改(行为类似指针),而在计算梯度时则会对同一套参数计算多次t梯度
延后参数化
网络每一层的参数大小是在数据在模型中传递时才确定。
自定义层
与自定义块非常类似,可以将自定义层看成自定义只有一层的自定义块。
区别是:将原来定义要用到的层的位置改为参数,将原来组合层的位置改为处理参数的流程。其他基本不变。
读写文件
这里的读写文件是指保存模型中的参数。
存储张量
可以保存模型中的中间和张量
存储参数
pytorch中给出了专门的函数用于保存和读取一个网路的参数。
GPU计算
需要注意的一点是GPU和CPU的存储是分开的,CPU的内存就是内存而GPU的内存是显存。当打印GPU中的张量时(或转成numpy),要进行内存之间的复制。
计算设备
书中给出了两个很方便的函数,可以给出指定GPU或是所有GPU。
张量与GPU
pytorch中可以查看张量在那个设备上,也可以选择将张量方到哪个设备上。
复制
在两个不同设备上的张量是不能直接计算的,要复制到同一个设备上后才能计算。
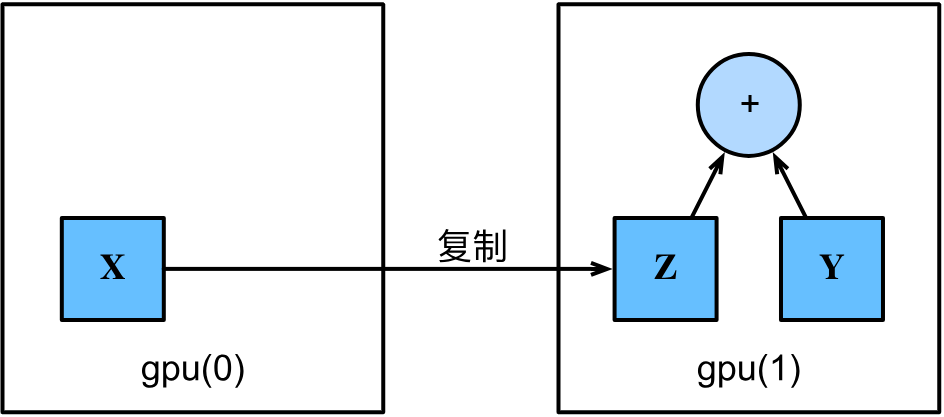
网外与GPU
我们也可以选择将网络放到GPU上