AI Compass前沿速览:DINOv3-Meta视觉基础模型、DeepSeek-V3.1、Qwen-Image、Seed-OSS、CombatVLA-3D动作游戏模型、VeOmni训练框架
AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供从完整学习路径。
- github地址:AI-Compass👈:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass👈:https://gitee.com/tingaicompass/ai-compass
🌟 如果本项目对您有所帮助,请为我们点亮一颗星!🌟
1.每周大新闻
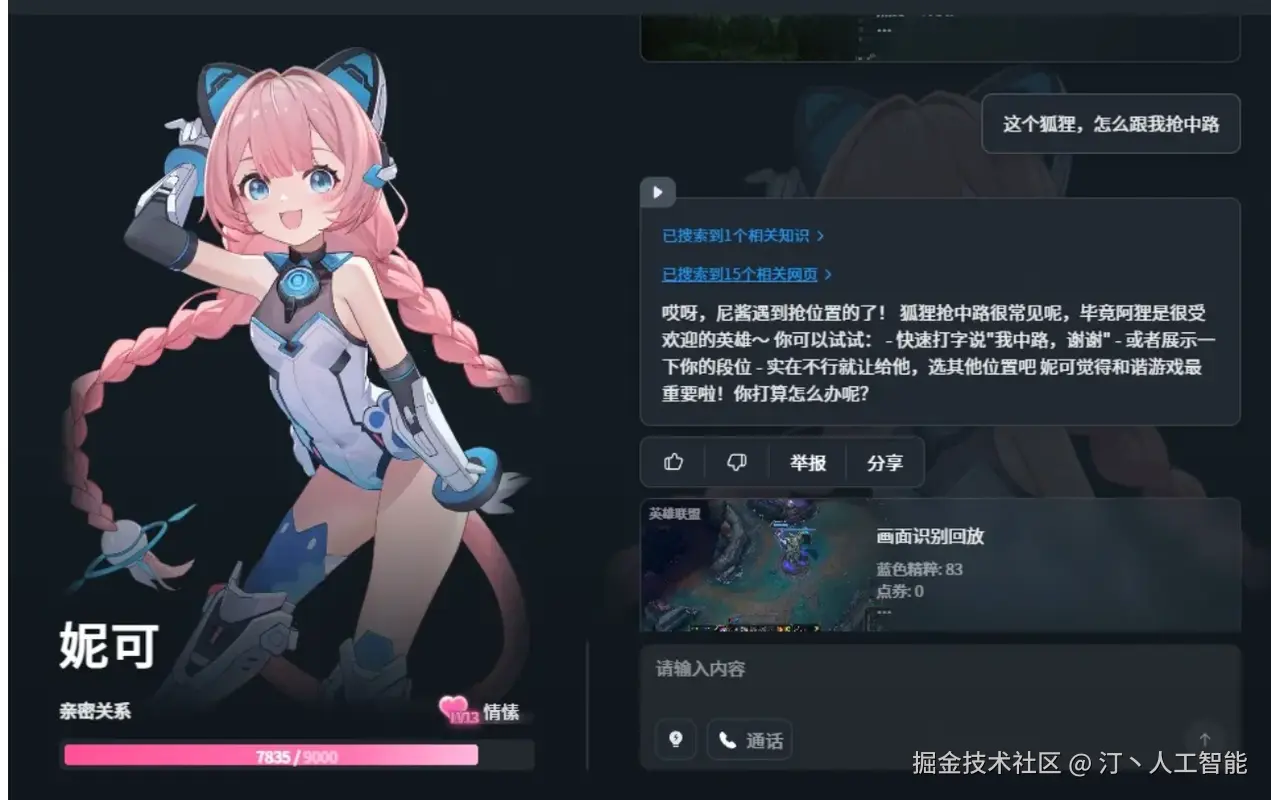
逗逗AI 1.0 --AI游戏伙伴
逗逗AI 1.0 是一款智能AI伙伴,旨在为用户提供情感价值和实时互动支持。该AI能够实时理解用户所处的环境,特别是游戏画面,并基于此提供个性化的互动和策略建议,同时支持多模态长期记忆功能。
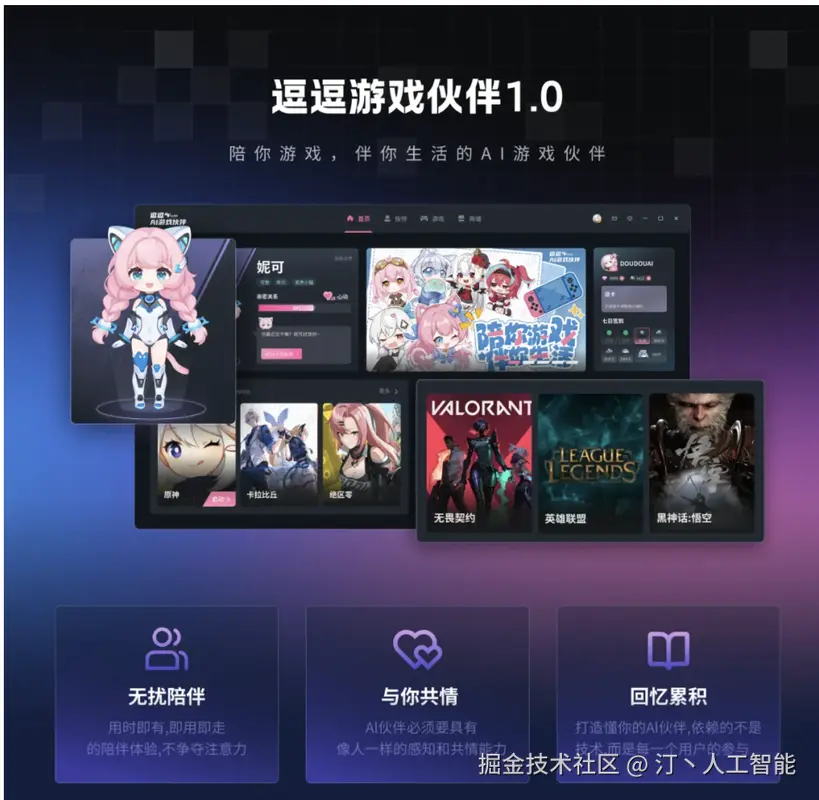
核心功能
- 实时画面理解: 能够即时分析并理解用户屏幕上的内容,如游戏界面。
- 实时互动响应: 基于对画面的理解和情境分析,与用户进行即时对话和交流。
- 情绪价值提供: 通过智能互动,为用户带来情感上的陪伴与支持。
- 策略建议: 在特定场景(如游戏)中,根据实时情况提供专业的分析和战术指导。
- 多模态长期记忆: 具备处理和存储多种类型信息(如视觉、文本)并进行长期记忆的能力,以实现更深度的个性化服务。
技术原理
逗逗AI 1.0 的实现依赖于多项前沿AI技术:
- 计算机视觉 (CV): 用于实时识别、分析和理解游戏或屏幕画面中的元素、状态和上下文。
- 自然语言处理 (NLP): 支撑AI与用户的实时互动,包括理解用户指令、生成自然流畅的对话回应。
- 情感计算 (Affective Computing): 通过分析用户行为或对话内容,识别用户情绪并提供相应的情感反馈或支持。
- 多模态学习 (Multimodal Learning): 整合来自视觉和文本等不同模态的数据进行统一处理和理解。
- 记忆网络/知识图谱: 构建和维护长期记忆系统,使AI能够记住历史交互、用户偏好和特定领域知识,从而提供更精准的个性化服务和策略。
- 决策支持系统/强化学习: 特别是在游戏策略建议方面,可能运用这些技术分析当前局势,预测结果并给出最优决策。
应用场景
-
游戏辅助: 作为玩家的智能游戏伴侣,提供实时的战术分析、角色推荐和策略建议(如英雄联盟的BP环节)。
-
个性化互动陪伴: 在日常使用中提供情感支持,进行智能聊天,成为用户的虚拟伙伴。
-
智能教育/学习辅助: 根据学习内容实时提供解释、答疑或学习策略指导。
-
智能家居/办公助手: 通过理解屏幕内容(如文档、报表),提供实时数据分析或操作建议,提升工作效率。
-
官网: www.doudou.fun/
DeepSeek V3.1
DeepSeek V3.1 是由 DeepSeek 公司推出的最新一代大型人工智能模型,作为 DeepSeek V3 的升级版本。它旨在提供更强大的智能对话和理解能力,通过扩展上下文窗口和优化模型架构,提升了处理长文本和复杂任务的效率和准确性。DeepSeek V3 系列模型是 DeepSeek 在大语言模型领域的最新研究成果,提供了多种规模版本以适应不同应用需求。
核心功能
DeepSeek V3.1 的核心功能主要体现在其强大的文本生成和理解能力。它支持生成高质量、连贯且富有逻辑的文本内容,包括但不限于问答、创作、总结、翻译等。通过扩展至 128k 的上下文窗口,模型能够处理更长的输入,从而更好地理解复杂语境和进行深度推理,提供更精准的响应。此外,它支持多平台API接入和应用部署,方便开发者集成使用。
技术原理
DeepSeek V3.1 在技术上采用了 Transformer 架构,并在 DeepSeek V3 的基础上进行了多项优化。其核心技术亮点包括:
- 大上下文窗口: 将上下文窗口从 64k 扩展至 128k,显著提升了模型处理长文本的能力,减少了信息丢失。
- 模型规模: DeepSeek V3 模型总大小达到 685B,包含 671B 的主模型权重和 14B 的多令牌预测(MTP)模块权重,表明其庞大的参数量和强大的学习能力。
- 高效推理支持: 支持 BF16 和 FP8 等多种精度推理模式,并获得 SGLang、vLLM 和 LMDeploy 等高性能推理框架的优化支持,实现了张量并行和流水线并行,确保在大规模部署时的效率。
- 多令牌预测(MTP): 引入 MTP 模块,可能用于提高生成效率或预测准确性。
花生AI -- B站推出AI视频创作工具
花生AI是B站推出的AI视频创作工具,帮助用户快速生成视频内容。用户只需提供文案或录制好的音频,最快3分钟即可生成完整视频。工具提供两种创作模式:智能匹配素材,根据文案自动匹配画面素材;模板化制作,可快速生成标准化视频。生成的视频内容质量可媲美普通UP主作品,适用于历史、娱乐、商业财经等领域。
- 极速生成视频:用户输入文案或音频后,最快3分钟即可生成完整视频,大大缩短创作时间。
- 智能匹配素材:AI能根据文案内容自动匹配合适的画面素材,帮助创作者快速完成视频制作。
- 模板化制作:提供多种预设模板,用户可直接套用,适合快速生成标准化视频,提升创作效率。
- 支持多种语言:基于B站自研的大语言模型Index,支持近10种语言的实时翻译,准确率高达90%。
- 一键发布:生成的视频可以直接上传至B站,方便创作者快速分享作品,提升内容传播效率。
BISHENG灵思 -- 毕昇推出的开源通用AI Agent
BISHENG灵思是毕昇推出的一款开源通用AI Agent,旨在通过结合业务专家的知识与经验,帮助用户高效完成复杂任务。它同时也是一个开源的LLM应用开发平台,专注于办公场景,已被众多行业头部组织及世界500强企业广泛使用。
核心功能
- 通用AI Agent能力: 作为通用型AI Agent,能够辅助用户处理各类复杂任务。
- 业务知识整合与应用: 结合领域专家的知识和经验,提供专业化的任务处理能力。
- 高效任务自动化: 提升任务执行速度和效率,实现自动化流程。
- LLM应用开发支持: 提供平台支持,便于开发和部署基于大型语言模型(LLM)的办公应用。
技术原理
BISHENG灵思的核心技术创新在于提出了AGL(Agent指导语言)框架。该框架可能通过标准化指令集和协议,指导AI Agent理解和执行复杂的业务逻辑与任务流程。作为LLM应用开发平台,其技术原理涉及大型语言模型的集成与微调、自然语言处理(NLP)技术、知识图谱构建、以及通过API接口与各类企业系统进行数据交互和功能调用的能力,从而实现智能化决策与自动化操作。
应用场景
- 企业办公自动化: 广泛应用于各类办公场景,如智能文档处理、数据分析报告生成、会议纪要整理、邮件自动回复与分类等。
- 业务流程优化: 协助企业梳理、优化并自动化复杂的业务流程,提升运营效率和响应速度。
- 智能知识管理: 构建企业内部知识库,提供智能问答、知识检索和学习支持,加速信息流转。
- 垂直行业解决方案: 可作为基础平台,针对金融、法律、人力资源等特定垂直行业开发定制化的AI Agent解决方案。
MuleRun -- 全球首个AI Agent市场
MuleRun 是全球首个AI Agent市场,其模式类似于eBay,旨在提供一个平台,集合并分发各种即插即用的AI工具,即Mule Agents。
核心功能
MuleRun 的核心功能是提供多样化的AI Agent,这些Agent能够执行多领域任务,包括但不限于游戏辅助、内容创作以及自动化任务处理等。用户可以方便地选择并使用这些预封装的AI工具。
技术原理
MuleRun 的运作基于AI Agent技术和大模型技术,通过模块化和标准化的方式集成各类AI能力,实现AI工具的"即插即用"。这通常涉及API接口、自动化工作流编排以及可能的多模态AI模型支持,以实现Agent的自主决策和任务执行。
应用场景
MuleRun 的AI Agent可广泛应用于多个场景,包括:
- 游戏辅助: 提供游戏内的智能协助或自动化功能。
- 内容创作: 辅助文本、图像、视频等各种形式的内容生成与编辑。
- 自动化任务: 实现日常办公、数据处理、流程管理等领域的自动化操作。
2.每周项目推荐
Qwen-Image-Edit
Qwen-Image-Edit 是由阿里通义(Qwen)团队推出的全能图像编辑模型,其核心构建于200亿参数的Qwen-Image架构之上。该模型融合了语义与外观层面的双重编辑能力,旨在提供精确、高效的图像内容修改。


核心功能
- 语义级图像编辑: 能够理解并修改图像中的概念、对象或场景,实现高层次的内容调整。
- 外观级图像编辑: 支持对图像的低层次视觉细节进行编辑,如添加、删除元素或调整视觉风格。
- 双语文本精准编辑: 具备对图片内中英文文本进行精确修改的能力,同时保持原图风格一致性。
技术原理
Qwen-Image-Edit 基于大型预训练的视觉-语言模型(VLMs)------Qwen-Image,该模型拥有200亿参数,使其具备强大的图像理解与生成能力。其实现双重编辑能力可能采用了多模态融合技术,结合扩散模型(Diffusion Models)进行高质量图像生成与编辑,并通过条件控制机制(如文本提示、掩码)来引导编辑过程。针对文本编辑,模型可能利用了其多语言理解能力,结合图像内容上下文进行文本嵌入、渲染及融合,以确保编辑的自然性和风格保持。
应用场景
-
专业内容创作: 辅助设计师、营销人员快速修改图像素材,满足广告、社交媒体等需求。
-
个性化图像处理: 用户可以利用其进行高级的个人照片编辑,实现定制化效果。
-
电子商务与产品展示: 快速调整商品图片,如修改产品标签、文字说明或细节展示。
-
智能图像辅助: 在办公、教育等场景中,实现对图片信息的快速修改与更新。
-
学术研究与开发: 作为图像编辑领域的基础模型,可用于进一步的算法研究与应用探索。
-
GitHub仓库:github.com/QwenLM/Qwen...
-
HuggingFace模型库:huggingface.co/Qwen/Qwen-I...
-
在线体验Demo:huggingface.co/spaces/Qwen...
Seed-OSS -- 字节开源大模型
Seed-OSS 是由字节跳动 Seed 团队开发的一系列开源大型语言模型。该模型系列旨在提供强大的长上下文处理、推理、智能体和通用能力,并具备友好的开发者特性。尽管仅使用 12T tokens 进行训练,Seed-OSS 在多项流行公开基准测试中展现出卓越性能,并以 Apache-2.0 许可证向开源社区发布,主要针对国际化(i18n)用例进行了优化。
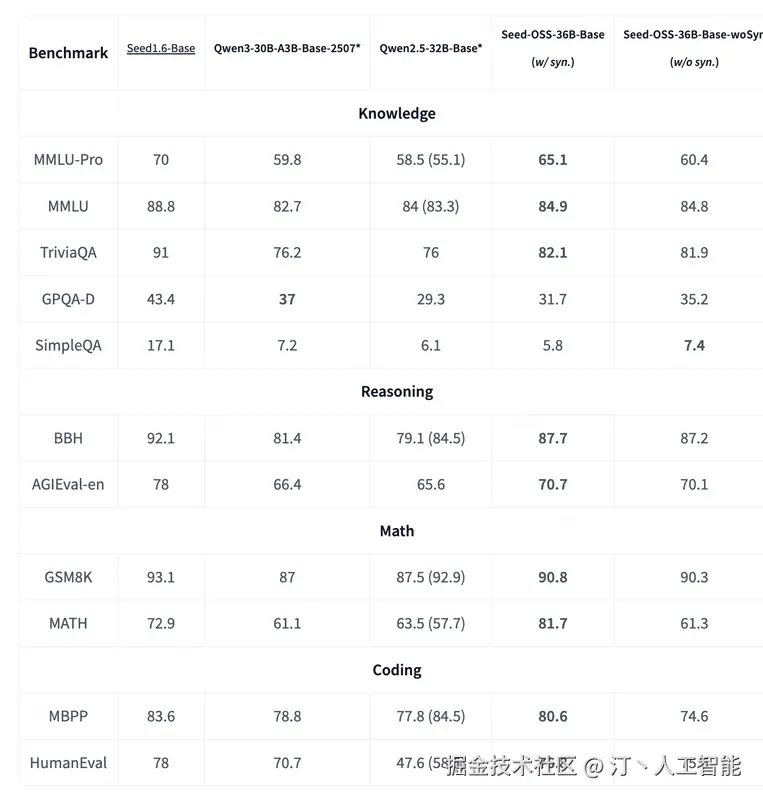
核心功能
- 原生长上下文支持: 模型能够处理高达 512K 的长上下文输入,显著提升对长文本的理解和生成能力。
- 增强推理能力: 经过专门优化,在推理任务中表现出色,同时保持了均衡且卓越的通用能力。
- 智能体能力: 在工具使用和问题解决等智能体任务中表现非凡。
- 灵活的思维预算控制: 允许用户根据需求动态调整推理长度,从而提高实际应用场景中的推理效率。
- 研究友好性: 发布了包含和不包含指令数据的预训练模型,为研究社区提供更多样化的选择。
技术原理
Seed-OSS 采用流行的因果语言模型架构,并集成了多项先进技术以优化性能和效率:
- RoPE (Rotary Position Embeddings): 用于处理序列中的位置信息,增强模型对长距离依赖的理解。
- GQA (Grouped-Query Attention): 一种注意力机制优化,旨在减少内存占用和提高推理速度。
- RMSNorm (Root Mean Square Normalization): 一种归一化技术,有助于稳定训练过程。
- SwiGLU 激活函数: 提供更好的非线性转换能力,提升模型表达力。
应用场景
-
长文本内容处理: 适用于需要理解和生成超长文本的应用,例如文档摘要、长篇写作辅助等。
-
复杂问题推理: 可应用于需要多步逻辑推理的场景,如智能问答、知识图谱构建与查询等。
-
智能体开发: 作为底层模型,支持开发具备工具调用、自主规划和问题解决能力的AI智能体。
-
国际化多语言应用: 针对国际用例进行优化,可服务于跨语言交流、多语言内容创作等全球化场景。
-
前沿AI研究: 为学术界和研究机构提供高质量的开源模型,促进在长上下文、推理和Agent领域的研究与探索。
-
GitHub仓库:github.com/ByteDance-S...
-
HuggingFace模型库:huggingface.co/collections...
ToonComposer -- 腾讯联合港中文、北大推出的AI动画制作工具
ToonComposer是由腾讯ARC实验室开发的一款生成式AI工具,旨在彻底改变和简化传统的卡通及动漫制作流程。它主要通过自动化关键帧之间的中间帧生成(inbetweening)工作,极大地提高了动画制作效率,减少了人工工作量。


核心功能
- 自动化中间帧生成: 能够根据用户输入的草图关键帧,智能地生成完整的动画帧序列,填补关键帧之间的空隙。
- 高效率与成本节约: 显著节省约70%的人工工作量,加速动画制作周期。
- 精确控制: 提供对草图关键帧的精确控制能力,允许用户精细调整动画效果。
- 智能填充与区域控制: 支持智能图像填充和特定区域的精细化控制,确保生成内容的质量和一致性。
技术原理
ToonComposer采用先进的生成式人工智能(Generative AI)技术,特别是通过"生成式关键帧后处理"(Generative Post-Keyframing)方法来驱动动画帧的生成。其核心在于利用深度学习模型理解关键帧间的运动和形态变化,并自主合成中间帧,从而实现动画的平滑过渡。这一技术统一了传统的动画插帧过程,摆脱了对每一帧手动绘制的依赖。
应用场景
- 卡通动画制作: 广泛应用于卡通片、动漫剧集的制作,特别是在需要大量中间帧的场景。
- 电影与游戏动画: 可用于影视特效和游戏动画的预制作或辅助制作,提高生产效率。
- 个人创作者与小型工作室: 赋能独立动画师和小型团队,降低动画制作的技术门槛和成本。
- 教育与研究: 作为AI在内容创作领域应用的案例,可用于相关领域的教学和研究。
ToonComposer的项目地址
- 项目官网:lg-li.github.io/project/too...
- GitHub仓库:github.com/TencentARC/...
- HuggingFace模型库:huggingface.co/TencentARC/...
- arXiv技术论文:arxiv.org/pdf/2508.10...
- 在线体验Demo:huggingface.co/spaces/Tenc...
混元3D世界模型1.0推出Lite版本
腾讯混元世界模型1.0(Hunyuan World Model 1.0)是腾讯发布的一款基于AI的开源3D场景生成模型。它能够将文本描述或单张图片快速转化为高质量、可探索、360度的沉浸式3D虚拟世界,极大地简化了传统3D内容创作的复杂流程,实现分钟级生成。

核心功能
- 文本/图像到3D场景生成: 能够根据文字指令或图片输入,自动生成完整的3D场景。
- 360度可探索环境: 生成的场景支持360度全景视图,并具有可探索性。
- 标准格式输出: 生成的3D内容可导出为标准网格文件(如Mesh),兼容主流游戏引擎和CG软件。
- 高生成质量: 在纹理细节、真实感、美学质量和指令遵循方面表现出色。
- 内容编辑能力: 支持对前景物体进行调整以及替换天空背景,满足个性化创作需求。
技术原理
腾讯混元世界模型1.0的生成架构核心在于结合了多项先进技术:
- 全景代理生成: 实现全景图像的合成。
- 语义分层: 对场景中的元素进行语义理解和分层处理。
- 分层3D重建: 通过分层结构对场景进行高精度3D重建,确保场景的深度和结构准确性。
- AIGC技术: 综合运用人工智能生成内容技术,自动化复杂的3D建模过程。
应用场景
-
游戏开发: 快速生成游戏原型、关卡设计所需的3D场景、建筑、地形和植被等元素。
-
虚拟现实(VR)/元宇宙内容创作: 为VR体验和虚拟世界构建提供沉浸式3D环境。
-
影视动画制作: 作为辅助工具,加速场景的搭建和概念验证。
-
数字艺术与设计: 帮助设计师和艺术家快速实现创意,无需专业的3D建模技能。
-
教育与模拟: 创建逼真的3D环境用于教学、训练和模拟。
-
传统CG工作流集成: 支持与现有计算机图形工作流的无缝衔接,进行编辑和物理仿真。
-
Github 项目地址:github.com/Tencent-Hun...
-
Hugging Face模型地址:huggingface.co/tencent/Hun...
-
技术报告地址:arxiv.org/abs/2507.21...
MemU -- 面向AI情感陪伴的开源AI记忆框架
MemU是一个开源的AI记忆框架,专为AI情感陪伴设计。它作为大型语言模型(LLM)应用的记忆层,旨在帮助AI真正理解用户,并构建具有更高准确性、更快检索速度和更低成本的AI记忆能力。
核心功能
- 对话记忆与关键信息提取: 能够记住用户与AI的每一次对话,并从中提取核心要点。
- 知识图谱构建: 基于对话内容建立知识图谱,实现AI对用户的深度理解。
- 增强记忆性能: 提供高准确性、快速检索和低成本的AI记忆解决方案。
- 持久化记忆能力: 使AI伙伴具备持续的、长期记忆的能力。
技术原理
MemU的核心是一个代理记忆层(agentic memory layer),它通过结构化地存储和管理对话数据,将非结构化的对话内容转化为可供AI理解和检索的知识。其技术原理涉及:
- 自然语言处理 (NLP): 用于解析和理解用户与AI的对话内容。
- 信息提取 (Information Extraction): 从对话中识别并提取关键信息和实体。
- 知识图谱技术 (Knowledge Graph Technology): 将提取的信息组织成结构化的知识网络,形成AI的长期记忆。
- 检索增强生成 (Retrieval-Augmented Generation, RAG) 机制: 通过从记忆层中快速检索相关信息来增强LLM的生成能力,提高回复的准确性和相关性。
- 数据存储与管理: 托管模型、API和云存储,确保记忆数据的有效存储、管理和高效访问。
应用场景
-
AI情感陪伴: 使得AI伴侣能够记住用户的偏好、历史对话和个人信息,提供更加个性化和富有情感的互动。
-
个性化AI助手: 应用于各类AI助手,使其能够根据用户的长期互动历史提供更精准的服务。
-
智能客服: 帮助客服AI记住客户的服务历史和问题细节,提升解决问题的效率和用户满意度。
-
教育辅导AI: 使教育AI能够跟踪学生的学习进度和知识掌握情况,提供定制化的学习体验。
-
项目官网:memu.pro/
-
GitHub仓库:github.com/NevaMind-AI...
VeOmni -- 字节跳动开源的全模态PyTorch原生训练框架
VeOmni 是字节跳动Seed团队开源的一款全模态分布式训练框架,基于PyTorch设计。它旨在以模型为中心,加速多模态大型语言模型(LLMs)的开发与训练,并支持任意模态模型的无缝扩展,提供模块化和高效的训练能力。
核心功能
- 全模态训练支持: 能够高效地进行单模态和多模态模型的预训练与后训练。
- 分布式并行训练: 灵活支持多种分布式并行策略的组合,优化大规模模型训练效率。
- 模型计算与并行解耦: 将分布式并行逻辑与模型计算过程解耦,增强了框架的灵活性和可配置性。
- 高吞吐性能: 能够以高吞吐量进行大规模模型训练,例如可实现每GPU每秒2800+ tokens的MoE模型训练。
- "积木式"配置: 提供直观且易于配置的"积木式"训练方案,简化复杂分布式策略的部署。
技术原理
VeOmni 的核心技术原理是其模型中心化(Model-Centric)的设计理念和引入的分布式配方库(Distributed Recipe Zoo)。该框架将底层分布式并行策略(如数据并行、模型并行、流水线并行、专家并行等)从上层模型计算逻辑中抽象并解耦。这种架构允许用户像组装积木一样,灵活配置和组合不同的并行方案,以适应不同规模和模态(如文本、图像、音频等)的模型训练需求。基于PyTorch生态,VeOmni能够高效利用GPU资源,并通过优化并行策略,显著提升大规模模型,尤其是全模态MoE模型的训练吞吐量和扩展性。
应用场景
-
大规模多模态LLM训练: 用于加速和扩展全模态大型语言模型(LLMs)的预训练和微调。
-
多模态融合模型开发: 为研究人员和开发者提供高效平台,探索和构建涉及图像、文本、语音等多种模态融合的模型。
-
高性能计算集群应用: 适用于需要在大规模计算集群上进行高效分布式训练的企业和研究机构。
-
前沿AI模型研究: 便于AI研究人员实验和验证复杂的分布式训练策略对新型模型架构的性能影响。
-
GitHub仓库:github.com/ByteDance-S...
-
arXiv技术论文:arxiv.org/pdf/2508.02...
Genie Envisioner -- 智元机器人平台
Genie Envisioner(GE)是智元(Zhiyuan Robotics / AgiBotTech)推出的首个面向真实世界机器人操控的统一世界模型开源平台。它旨在通过一个统一的视频生成框架,集成策略学习、评估和仿真功能,打破传统机器人学习系统分阶段开发的模式,从而实现更高效、更智能的机器人操作。
核心功能
- 统一世界模型构建: 通过视频生成技术构建统一的机器人世界模型。
- 策略学习与生成: 支持机器人行为策略的自动化学习与生成。
- 评估与仿真: 提供功能强大的评估工具和仿真环境,用于测试和验证机器人策略。
- 指令驱动操作: 实现可伸缩的、指令驱动的机器人操作。
- 开放平台: 提供开源代码库和相关数据集,促进社区协作和研究。
技术原理
Genie Envisioner 的核心技术原理是构建一个统一的视频生成世界模型 (Unified Video-Generative World Model)。该平台整合了策略学习 (Policy Learning)、评估 (Evaluation)和仿真 (Simulation)机制,形成一个闭环系统 (Closed-loop System)。它利用大规模数据集(如约3000小时的机器人操作数据)进行训练,以学习和预测机器人与环境的交互。通过生成未来的视频帧,该模型能够模拟不同操作指令下的机器人行为和环境变化,从而支持强化学习 (Reinforcement Learning)和模型预测控制 (Model Predictive Control)等高级控制策略,最终实现指令到动作的精确转化,并克服传统感知-规划-执行(Perception-Planning-Execution)范式的局限性。
应用场景
-
通用机器人操作: 适用于各种通用型机器人的精细操作和任务执行。
-
工业自动化: 在工厂、仓库等场景中,提高机器人抓取、组装、分拣等任务的效率和鲁棒性。
-
家庭服务机器人: 为家庭服务机器人提供更强的环境感知和任务执行能力。
-
具身智能研究: 作为具身智能领域的研究平台,推动机器人感知、决策和行动一体化的发展。
-
教育与科研: 为研究人员和学生提供一个开放、统一的实验平台,加速机器人技术创新。
-
GitHub仓库:github.com/AgibotTech/...
-
arXiv技术论文:arxiv.org/pdf/2508.05...
DINOv3 -- Meta开源的通用视觉基础模型
DINOv3是Meta AI推出的一款通用、SOTA(State-of-the-Art)级视觉基础模型,通过大规模自监督学习(SSL)进行训练。它能够从无标注数据中学习并生成高质量的高分辨率视觉特征,旨在提供强大的通用视觉骨干网络,并在各种视觉任务和领域中实现突破性性能。DINOv3在DINOv2的基础上进一步扩展了模型规模和训练数据量,并支持商业许可。
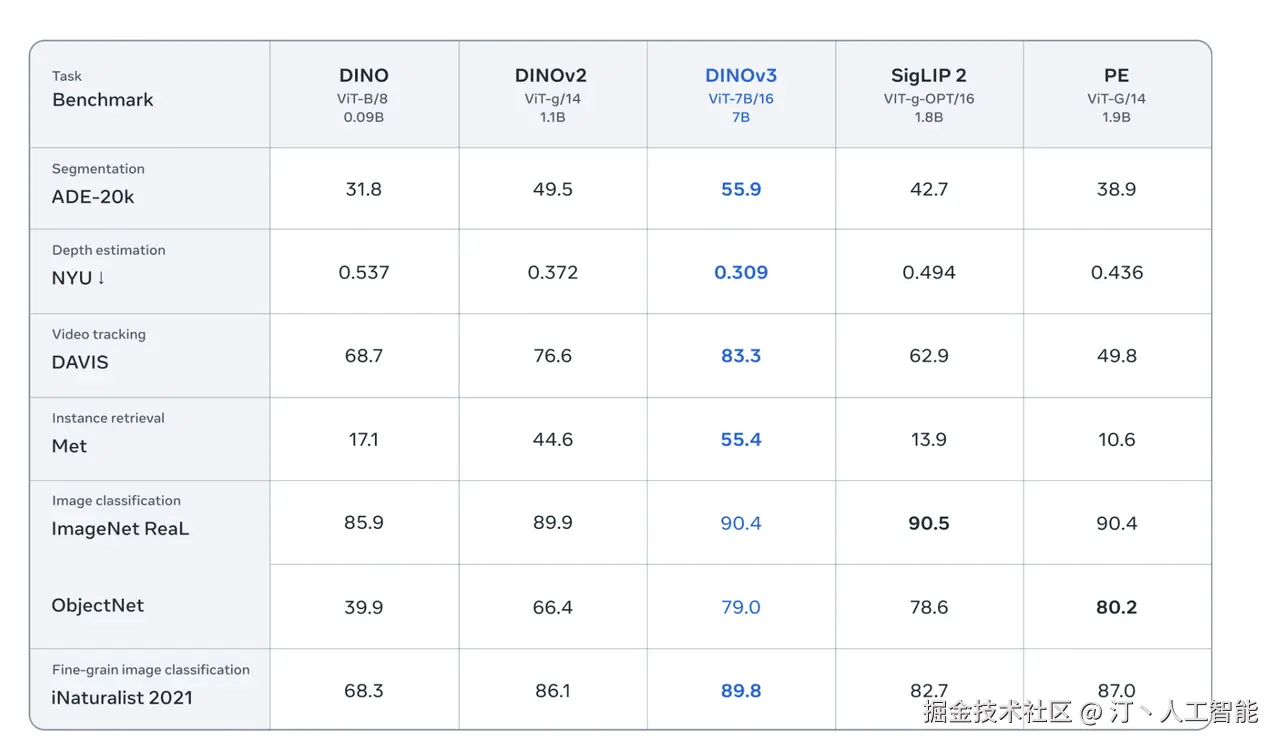
核心功能
- 高分辨率特征生成: 能够产生高质量且分辨率高的图像特征,适用于需要精细视觉信息的任务。
- 通用视觉骨干网络: 提供一个强大的、适用于多种视觉任务的通用视觉骨干模型。
- 自监督学习能力: 利用海量无标注数据进行训练,无需人工标注即可学习强大的视觉表征。
- 跨领域性能优越: 在图像分类、语义分割、目标检测、视频目标跟踪等多种探测任务上超越传统弱监督模型。
- 适应性强: 预训练的DINOv3模型可以通过轻量级适配器在少量标注数据上进行定制,实现更广泛的应用。
- 部署灵活性: 包含蒸馏后的较小模型(如ViT-B、ViT-L)和ConvNeXt变体,便于在不同场景下部署。
技术原理
DINOv3的核心技术原理在于大规模自监督学习(SSL)。它在DINOv2的基础上进行了显著的扩展,模型参数量达到7B,训练数据集规模达到1.7B图像,但相比弱监督方法,所需的计算资源更少。
- 自监督训练: 通过构建无需人工标注的任务来学习图像的内在结构和特征,例如预测图像不同视图之间的关系。
- 视觉Transformer (ViT) 架构: 采用ViT作为其特征提取器,能够有效处理高分辨率图像并捕捉全局依赖关系。
- 模型与数据规模化: 通过将模型尺寸扩大6倍、训练数据量扩大12倍,显著提升了模型性能和泛化能力。
- 冻结骨干网络: 在许多应用中,DINOv3的骨干网络可以保持冻结状态,无需额外微调即可应用于新任务,这得益于其强大的通用特征提取能力。
- 轻量级适配器: 对于特定任务,可以通过训练一个轻量级适配器来微调模型,而非对整个大型模型进行重新训练,从而提高效率。
应用场景
-
图像分类: 对各种图像进行准确的类别识别。
-
语义分割: 精确识别图像中每个像素所属的对象类别。
-
目标检测: 在图像中定位并识别出特定对象。
-
视频目标跟踪: 在视频序列中持续追踪特定目标。
-
医学影像分析: 处理和理解医学图像,辅助诊断。
-
卫星图像分析: 支持对卫星影像进行解析,例如冠层高度估计等。
-
遥感图像处理: 应用于土地利用、环境监测等领域的遥感数据分析。
-
安防监控: 进行智能视频监控中的行为识别与异常检测。
-
自动驾驶: 用于环境感知和目标识别。
-
任何标注数据稀缺的视觉任务: 由于其强大的自监督学习能力,特别适用于缺乏大量标注数据的领域。
-
HuggingFace模型库:huggingface.co/docs/transf...
Shadow -- 开源的AI编程Agent
Shadow 是一个开源的AI编程Agent,旨在帮助开发者理解、推理并贡献现有代码库。它提供了一套全面的工具集,能够集成GitHub仓库,自动化生成拉取请求,管理代码分支,并提供实时的任务状态更新。该项目通过提供高级的代码操作和搜索能力,提升开发效率和协作体验。
核心功能
- 文件操作与管理: 支持文件的读取、编辑、替换、删除和目录探索,能够对代码文件进行细粒度的控制和修改。
- 代码智能搜索: 提供基于正则表达式的模式匹配(grep_search)、模糊文件名搜索(file_search)以及AI驱动的语义代码搜索(semantic_search)。
- GitHub集成与自动化: 能够与GitHub仓库无缝集成,自动生成Pull Request并管理分支,简化开发工作流。
- 实时任务状态更新: 提供任务的实时状态反馈,帮助开发者随时掌握项目进展。
- 代理工具: 为AI Agent提供一套全面的工具,使其能够执行复杂的编程任务。
技术原理
Shadow 的核心技术原理是利用人工智能代理(AI Agent)能力来理解和操作代码库。它结合了:
-
自然语言处理(NLP): 理解开发者意图和代码语义,进行智能化的代码分析和搜索。
-
代码分析与操作引擎: 通过
read_file、edit_file、search_replace等工具实现对代码文件的精确读写和修改。 -
语义搜索技术: 运用先进的AI模型进行代码的语义理解,实现比传统关键词搜索更深层次的代码查找。
-
版本控制系统(VCS)集成: 利用GitHub API等接口,实现与Git仓库的交互,包括分支管理、Pull Request的创建与更新。
-
任务状态管理: 通过后端服务和前端界面,实现任务执行状态的实时监控和反馈机制。
-
项目官网:www.shadowrealm.ai/
-
GitHub仓库:github.com/ishaan1013/...
Klear-Reasoner -- 快手开源的推理模型
Klear-Reasoner 是一个拥有80亿参数的推理模型,旨在通过结合长链式思维监督微调和梯度保留裁剪策略优化(GPPO)来显著提升模型的推理能力。它在数学和编程等复杂基准测试中展现出卓越的性能,能够进行长距离、多步骤的深思熟虑式推理。
核心功能
- 高级推理: 在数学和编程领域执行复杂的长距离推理任务。
- 性能优化: 在AIME和LiveCodeBench等挑战性基准测试中达到行业领先水平 (SOTA)。
- 问题解决: 能够处理需要多步骤逻辑和深层思考的问题。
- 模型训练优化: 引入GPPO机制,解决传统强化学习裁剪机制的局限性,提升训练效率和模型探索能力。
技术原理
Klear-Reasoner的核心技术在于其创新的训练范式:
- 模型架构: 一个80亿参数的推理模型。
- 梯度保留裁剪策略优化 (GPPO): 针对强化学习中的策略优化,GPPO旨在克服传统裁剪机制在探索信号抑制和次优轨迹忽略方面的问题。它通过温和地反向传播来自裁剪区域的梯度,从而在保持策略更新稳定的同时,有效促进模型探索。
- 长链式思维监督微调 (Long Chain-of-Thought Supervised Fine-tuning, SFT): 采用以质量为中心的SFT策略,确保模型能够一致地学习和复制准确的推理模式。
- 强化学习 (RL): 结合SFT与GPPO,进一步提升模型的推理性能。
- 辅助优化技术: 包括软奖励设计(soft reward design)、数据过滤(data filtering)和平衡SFT监督(balanced SFT supervision),共同增强强化学习的效率和推理效果。
应用场景
-
教育科技: 辅助学生解决复杂的数学问题和编程挑战。
-
软件开发: 自动生成、调试和优化代码。
-
科学研究: 在需要复杂逻辑推理的领域(如物理、化学、生物)中进行问题求解和数据分析。
-
人工智能助理: 开发能够进行多步骤决策和复杂任务规划的智能助手。
-
GitHub仓库:github.com/suu990901/K...
-
HuggingFace模型库:huggingface.co/Suu/Klear-R...
-
arXiv技术论文:arxiv.org/pdf/2508.07...
CombatVLA -- 淘天3D动作游戏专用VLA模型
CombatVLA 是由淘天集团未来生活实验室团队开发的一种高效视觉-语言-动作(VLA)模型,专为3D动作角色扮演游戏(ARPG)中的战斗任务设计。该模型旨在通过整合视觉感知、语言理解和动作控制,提升AI在复杂游戏环境中的表现。
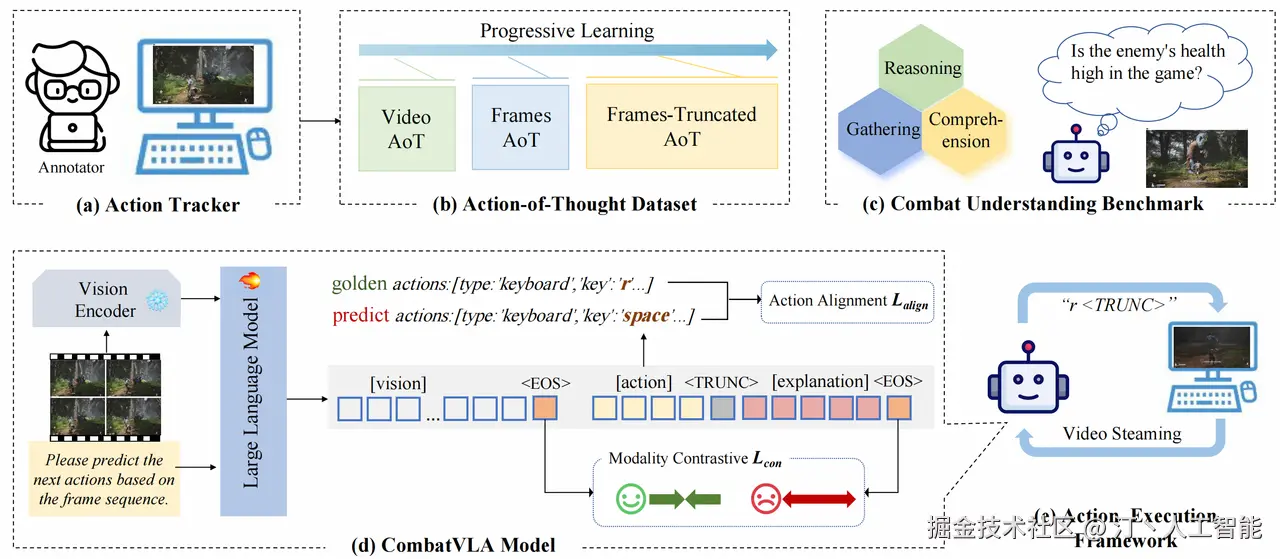
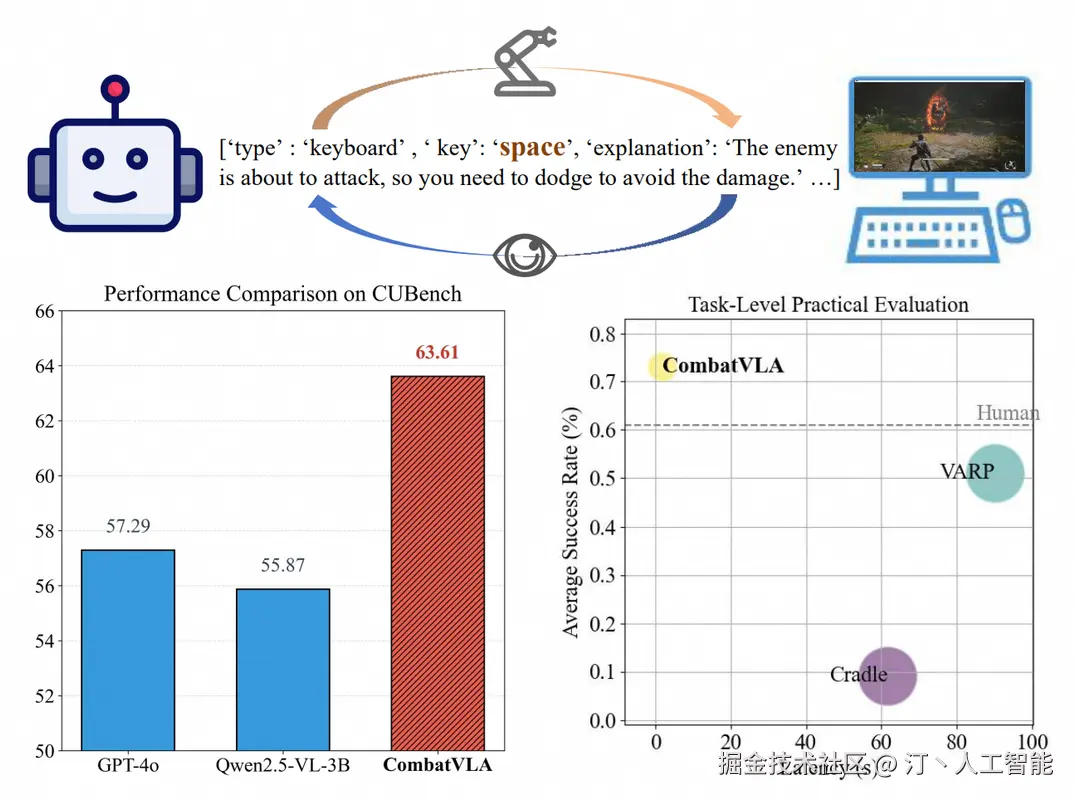
核心功能
CombatVLA 的核心功能在于对3D ARPG中战斗任务的优化。它能够:
- 战斗理解与推理: 识别敌方位置,并进行动作推理。
- 高效执行: 相比现有基于VLM的游戏智能体,显著提升执行速度。
- 多模态控制: 处理视觉输入,并生成一系列操作指令(包括键盘和鼠标操作)来控制游戏。
- 性能超越: 在战斗理解方面超越了GPT-4o和Qwen2.5-VL等现有模型,并在CUBench基准测试中取得了高分。
技术原理
CombatVLA 基于一个3B参数规模的VLA模型,其技术原理涉及:
- 视觉-语言-动作(VLA)集成: 模型将视觉信息、自然语言指令和游戏内的动作输出进行统一学习。
- 高效推理设计: 专门设计以实现高效推理,大幅提升处理速度。
- 基准测试构建: 建立了名为CUBench的战斗理解基准,通过VQA(视觉问答)格式评估模型在识别敌方位置和动作推理任务中的表现。
- 模型架构: 能够处理视觉输入并生成控制游戏动作的序列。
应用场景
CombatVLA 的主要应用场景集中在:
-
3D动作角色扮演游戏(ARPG): 尤其适用于其中复杂的战斗任务,可以作为游戏AI或游戏测试工具。
-
智能体训练: 为在复杂动作游戏环境中训练多模态智能体提供新的见解和方向。
-
游戏开发: 有助于开发更智能、更具响应性的游戏内NPC或AI对手。
-
虚拟环境模拟: 可应用于其他需要视觉感知、语言理解和精准操作的虚拟环境。
-
项目官网:combatvla.github.io/
-
GitHub仓库:github.com/ChenVoid/Co...
-
arXiv技术论文:arxiv.org/pdf/2503.09...
NVIDIA Nemotron Nano 2 -- 英伟达推出的高效推理模型
NVIDIA Nemotron Nano 2 是英伟达推出的一款高效、参数量为9B的推理模型,旨在提供卓越的性能和成本效益。该模型基于创新的混合Mamba-Transformer架构,并在海量数据上进行了预训练,支持长上下文,并强调开放性,同时发布了模型和大部分训练数据集。
核心功能
- 高效推理: 在相似规模下,推理速度比同类模型(如Qwen3-8B)快数倍(最高可达6倍),同时显著降低推理成本(最高可节省60%)。
- 强大推理能力: 在复杂的推理基准测试中表现出色,通过支持"思考"预算控制,可在生成最终答案前先生成推理过程,有效提升复杂任务的准确性。
- 长上下文支持: 具备128k的上下文长度处理能力,使其能够处理更长的输入和输出序列。
- 模型开放性: 英伟达首次开源了用于创建该模型的大部分高质量预训练数据集,包括Nemotron-CC-v2、Nemotron-CC-Math-v1、Nemotron-Pretraining-Code-v1和Nemotron-Pretraining-SFT-v1,促进了研究和应用。
- 统一推理与非推理任务: 设计目标是兼顾推理与非推理任务,提供统一的模型解决方案。
技术原理
NVIDIA Nemotron Nano 2 采用了混合Mamba-Transformer架构,结合了Mamba模型的线性扩展能力和Transformer的强大建模优势。其训练过程包括:
- 预训练阶段: 模型在20万亿个token上进行预训练,并使用FP8精度。通过分阶段持续预训练扩展长上下文能力,使其在保持高性能的同时达到128k上下文支持。
- 后训练阶段: 采用多策略结合进行后训练,包括监督微调(SFT) 、组相对策略优化(GRPO) 、直接偏好优化(DPO)以及人类反馈强化学习(RLHF),以提升模型在指令遵循和推理控制上的表现。其中约5%的数据包含故意截断的推理轨迹,以实现细粒度的"思考"预算控制。
- 模型压缩: 基础模型和对齐模型经过剪枝(Pruning)和蒸馏(Distillation)等压缩技术优化,使其能够在资源受限的设备(如单个NVIDIA A10G GPU)上高效部署和推理。
- 预训练数据集构成: 预训练数据集Nemotron-Pre-Training-Dataset-v1包含66万亿个token,涵盖优质网络爬取、数学、代码、SFT和多语言问答数据,通过Lynx + LLM管线等方法精心处理,确保高质量和多样性。
应用场景
-
边缘设备AI部署: 凭借其紧凑的参数量和高效的推理性能,非常适合在智能手机、智能手表、IoT设备等算力有限的边缘设备上部署生成式AI应用。
-
智能助理与Agentic AI: 可作为智能代理(agentic AI)任务的核心,用于实现复杂的逻辑推理、规划和决策,例如高级问答系统、自动化工作流。
-
内容生成与代码辅助: 利用其强大的生成和推理能力,可用于高质量文本生成、代码自动补全、编程辅助、内容创作等。
-
教育与研究: 开放的训练数据和技术报告使其成为学术研究和教育领域的宝贵资源,促进对高效大模型的理解和开发。
-
低成本推理服务: 对于需要高吞吐量且对成本敏感的企业级AI应用,Nemotron Nano 2 提供了一个经济高效的解决方案。
-
HuggingFace模型库:huggingface.co/collections...
-
在线体验Demo:build.nvidia.com/nvidia/nvid...
谱乐AI -- AI音乐生成
谱乐AI是一款AI驱动的音乐生成平台,旨在通过人工智能技术革新音乐创作过程。它能够接收多种形式的输入,快速生成高质量的匹配音乐作品,为用户提供便捷、个性化的音乐创作体验。
核心功能
- 多模态输入支持: 支持文本、图片、视频等多种输入方式,根据不同输入内容智能生成对应的AI音乐。
- 快速音乐生成: 能够依据用户描述(如"温暖的钢琴曲")在短时间内生成完整的音乐作品。
- 自定义歌曲创作: 协助用户创作定制歌曲和歌词,并生成器乐轨道。
- 创作辅助功能: 提供歌词创作、流派选择、节拍与速度建议以及音乐理论指导等辅助功能,帮助用户进行音乐创作。
- 专属音色模型训练: 提供训练专属音色模型的能力,实现高度个性化的音乐输出。
技术原理
谱乐AI的实现基于先进的深度学习和生成对抗网络(GANs)或变分自编码器(VAEs)等人工智能模型,可能还结合了Transformer架构处理序列数据(如音乐和歌词)。其核心技术包括:
- 多模态融合技术: 将文本、图像、视频等不同模态的数据转化为统一的特征表示,作为音乐生成模型的输入。
- 音乐生成算法: 利用复杂的神经网络模型学习音乐的结构、和声、旋律、节奏等规律,并生成全新的、符合输入描述的音乐序列。
- 音频合成技术: 将生成的音乐序列转换为可听的音频波形,可能涉及数字信号处理和高质量的音色库。
- 个性化模型训练: 通过迁移学习或小样本学习技术,允许用户训练或微调特定音色模型,以适应个性化需求。
应用场景
- 音乐创作与制作: 为专业音乐人、业余爱好者提供创作灵感和快速制作工具,用于歌曲创作、伴奏制作等。
- 内容创作: 为视频博主、游戏开发者、动画制作人等提供快速定制背景音乐的解决方案。
- 教育与学习: 作为音乐理论学习的辅助工具,帮助学生理解和实践音乐概念。
- 个性化娱乐: 满足普通用户对定制化音乐的需求,如为特定情绪或场景生成专属音乐。
- 广告与营销: 快速生成符合品牌调性或产品主题的广告配乐。
AutoCodeBench -- 腾讯混元开源测评大模型代码能力的数据集
AutoCodeBench是由腾讯混元团队推出的一个大规模代码生成基准测试集。它旨在全面评估大语言模型(LLMs)的代码生成能力,包含3920个问题,均匀分布在20种编程语言中。该数据集以其高难度、实用性和多样性为特点,为LLM在代码领域的性能评估提供了一个高质量、可验证的测试平台。
核心功能
- 代码能力测评: 提供一套标准化的测试题目,用于精确衡量大语言模型在不同编程语言下的代码生成和理解能力。
- 多语言支持: 涵盖20种主流编程语言,确保评估的广泛性和全面性。
- 高质量数据集: 采用创新的数据合成策略,确保生成的问题具有高难度和实用性,并且可验证。
- 基准测试: 作为评估不同LLM在代码生成任务上性能的统一基准,支持对基础模型和对话模型的测试。
技术原理
AutoCodeBench的核心技术原理在于其LLM-Sandbox交互自动化工作流。该工作流通过以下步骤实现高质量、可验证的多语言代码数据集的合成:
- 逆向问题合成: 不同于传统的数据合成方法,AutoCodeBench基于已有的代码解决方案和测试函数,逆向提示LLM生成准确的编程问题。
- 多语言沙盒验证: 构建一个多语言的沙盒环境,LLM在此环境中生成测试输入,并通过沙盒获取测试输出,从而确保生成的数据具有高度的可验证性。
- 自动化生成与评估: 整个过程实现了自动化,从问题的生成到测试用例的创建,再到模型的评估,大大提高了基准测试的效率和可靠性。
应用场景
-
大语言模型代码能力评估: 用于研究人员和开发者评估、比较和改进各种大语言模型的代码生成、代码补全、错误修复等能力。
-
AI编程助手研发: 为开发更智能、更准确的AI编程辅助工具提供测试数据和基准,从而提高开发者的编码效率。
-
学术研究: 作为代码生成领域的重要数据集,支持相关算法、模型和理论的深入研究。
-
模型训练与优化: 通过对模型的测试结果进行分析,指导LLM的进一步训练和架构优化,以提升其在编程任务上的表现。
-
GitHub仓库:github.com/Tencent-Hun...
-
HuggingFace模型库:huggingface.co/datasets/te...
-
arXiv技术论文:arxiv.org/pdf/2508.09...
3. AI-Compass
AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供从完整学习路径。
- github地址:AI-Compass👈:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass👈:https://gitee.com/tingaicompass/ai-compass
🌟 如果本项目对您有所帮助,请为我们点亮一颗星!🌟
📋 核心模块架构:
- 🧠 基础知识模块:涵盖AI导航工具、Prompt工程、LLM测评、语言模型、多模态模型等核心理论基础
- ⚙️ 技术框架模块:包含Embedding模型、训练框架、推理部署、评估框架、RLHF等技术栈
- 🚀 应用实践模块:聚焦RAG+workflow、Agent、GraphRAG、MCP+A2A等前沿应用架构
- 🛠️ 产品与工具模块:整合AI应用、AI产品、竞赛资源等实战内容
- 🏢 企业开源模块:汇集华为、腾讯、阿里、百度飞桨、Datawhale等企业级开源资源
- 🌐 社区与平台模块:提供学习平台、技术文章、社区论坛等生态资源
📚 适用人群:
- AI初学者:提供系统化的学习路径和基础知识体系,快速建立AI技术认知框架
- 技术开发者:深度技术资源和工程实践指南,提升AI项目开发和部署能力
- 产品经理:AI产品设计方法论和市场案例分析,掌握AI产品化策略
- 研究人员:前沿技术趋势和学术资源,拓展AI应用研究边界
- 企业团队:完整的AI技术选型和落地方案,加速企业AI转型进程
- 求职者:全面的面试准备资源和项目实战经验,提升AI领域竞争力