昨晚,字节跳动Seed团队正式宣布开源Seed-OSS系列大语言模型,此次开源的Seed-OSS系列包括三个版本:
-Seed-OSS-36B-Base:含合成数据
-Seed-OSS-36B-Base:不含合成数据
-Seed-OSS-36B-Instruct:指令微调版

所有模型均采用Apache-2.0许可证发布,为研究人员和开发者提供了极大的使用、修改和再分发自由度。
Seed-OSS-36B模型拥有360亿参数,仅使用12万亿token进行训练,却在多个主流开源基准测试中表现出色。模型支持原生512K上下文长度,这是 OpenAI 最新GPT-5模型系列的两倍,意味着用户可以一次性处理大量信息,如长达1600页的文档。
模型采用了流行的因果语言模型架构,结合了RoPE位置编码、分组查询注意力(GQA)机制、RMSNorm和SwiGLU激活函数。其具体架构参数包括64层网络、80/8/8的QKV头配置、128的头维度、5120的隐藏层大小和155K的词汇表大小。
可控思维预算
Seed-OSS-36B引入了一项创新特性------可控思维预算(Controllable Thinking Budget)。这意味着用户根据任务复杂性灵活指定模型的推理长度,动态控制推理过程,显著提高了推理效率。
在实际使用中,用户可以设置512、1K、2K、4K、8K 或 16K的思维预算。模型在推理过程中会定期触发自我反思,估计已消耗和剩余的预算,让用户始终掌控资源使用情况。对于简单任务,模型可以使用较短的思维链快速响应;对于复杂任务,则可以分配更多预算进行深度思考。
性能表现
根据发布的基准测试结果,Seed-OSS-36B在多个领域都达到了开源模型的先进水平。
Base版模型在MMLU-Pro上取得65.1分,在MMLU上取得84.9分,在GSM8K上取得90.8分,在MATH上取得81.7分,在HumanEval上取得76.8分,在BBH上取得87.7分,在MBPP上取得80.6分。
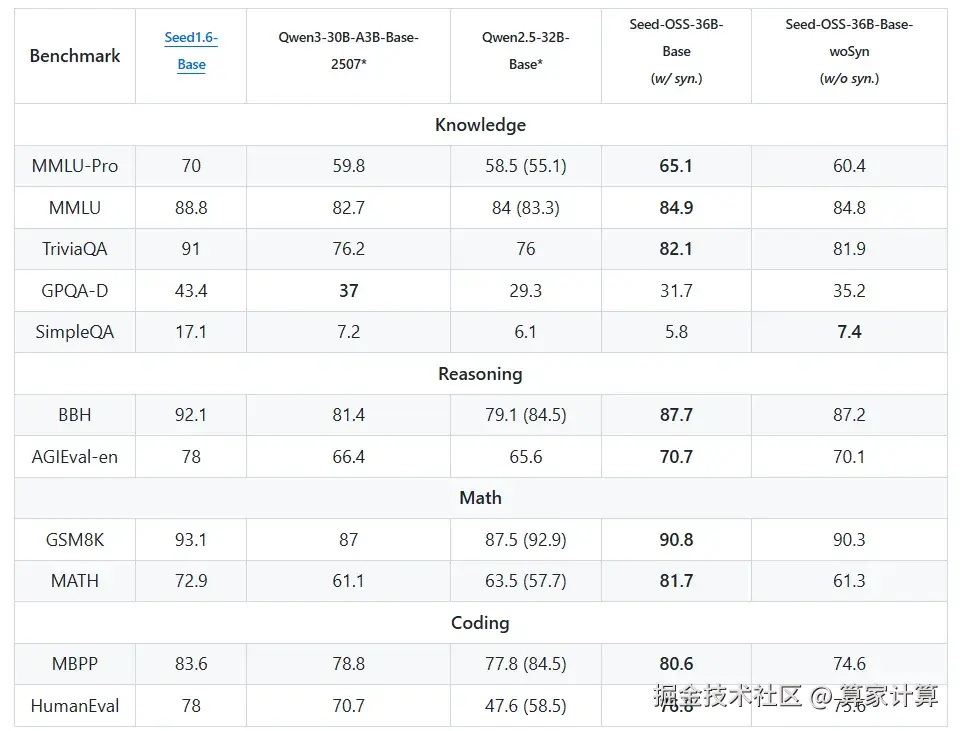
Instruct版本表现更为突出:在AIME24数学基准上达到91.7%,在AIME25上达到84.7%,在LiveCodeBench v6编码基准上达到67.4%,在TAU1-Retail代理任务上达到70.4%,在SWE-Bench Verified上达到56.0%,在RULER(128K)长上下文测试中达到94.6。
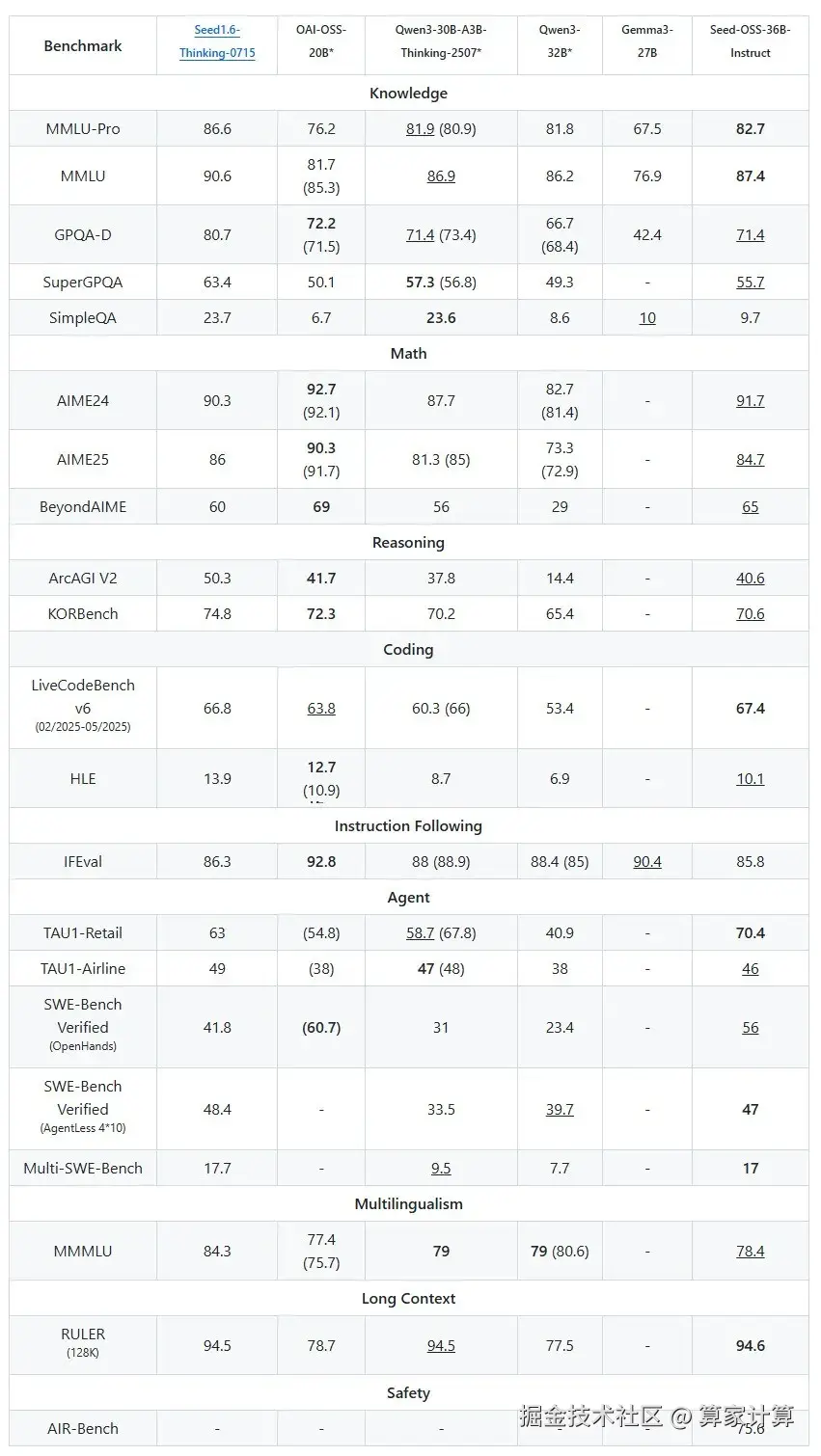
可以看出,Seed-OSS-36B在数学推理、编程能力、代理任务和长上下文处理方面都表现出色,特别是在代理任务和长上下文处理上,该模型创造了开源模型的新纪录。
模型支持通过Hugging Face Transformers和vLLM进行推理,并提供了4-bit和8-bit量化版本。推荐的生成参数为temperature=1.1和top_p=0.95,在这一配置下,模型在多数任务上都能取得最佳性能。
由于36B参数规模较大,即使用Q4量化,也需要大约20GB以上的VRAM。建议使用支持部分卸载的推理框架。
模型已经通过Hugging Face发布,开发者可以立即开始使用和探索这一强大的开源模型。