本文较长建议点赞收藏。更多AI大模型开发 学习视频/籽料/面试题 可参考>>Github<<
RAG (Retrieval - Augmented Generation,检索增强生成 )技术最早可追溯至2020年被正式提出。如今,伴随大模型技术的飞速迭代与应用场景的持续拓展,RAG技术已经深度融入大模型工作流,成为一种被广泛认可且极具影响力的范式。
大厂们也推出了一系列大模型应用融入了知识库,如IMA、飞书这些产品。
腾讯的 ima 个人知识库

字节的飞书知识问答
那么,这些产品都采用的 RAG 技术,背后的原理是什么?假如牛马被老板要求要完成建立公司内部知识库系统(当然最好没有,手动狗头),该如何完成呢?
在这篇文章中,我们会详细介绍RAG的技术原理,并介绍最近流行的结合知识图谱的 RAG 构建。
RAG整体框架
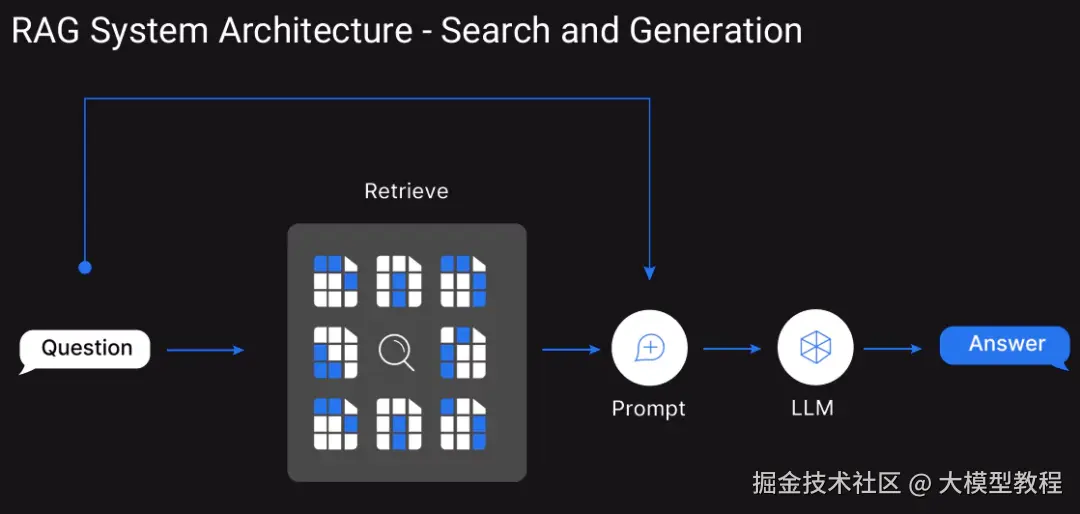
RAG 本质上是一个集成了两个关键组件的混合模型。
- 从各种文件构建知识向量库。
- 理解用户需求,在知识向量库里进行检索,最终生成准确而且上下文丰富的响应。
下面我们分两模块介绍。
RAG知识库构建
构建RAG知识库工作流如图所示:

为构建让大模型可以检索的知识库,首先把各种类型的文件转化为texts格式。
这里 texts 不一定是 txt 格式,也可以是 md 格式、json 格式,主要是为了方便后续进行分块为Chunks
分块后的 Chunks 进一步嵌入文本块 转换为携带语义信息的数值向量 。最终将嵌入储存保存在向量数据库中,以便在用户查询中快速检索。
RAG检索回答
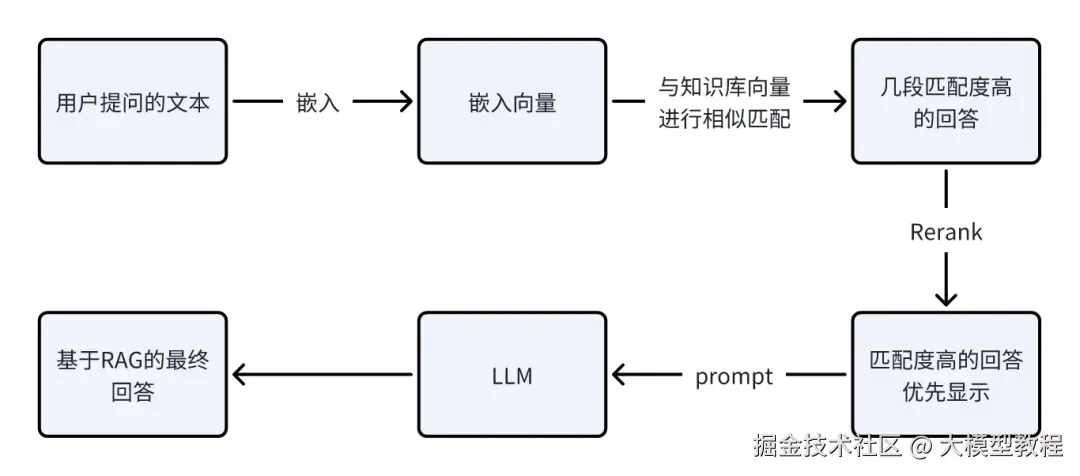 这一模块是为了让大模型理解用户提问,最终生成可信的带有上下文的回复。
这一模块是为了让大模型理解用户提问,最终生成可信的带有上下文的回复。
输入为用户的提问,类似的,大模型把该提问文本转化为嵌入向量,再到上一步构建的知识向量库里进行检索。
最终找到几段匹配度(如余弦相似度)高的回答,再利用Rerank模型,匹配度高的答案优先选择,结合指导大模型回答的提示词(prompt,可以为指导大模型回复的语气),最终,大模型回答给用户基于知识库检索的答案。
知识图谱+RAG(图检索增强生成)
传统 RAG 无法理解复杂实体关系,因此,假如用户查询涉及多个文档和复杂实体,传统 RAG 通常回答单个独立实体,而不是整体响应,无法满足用户需要。
知识图谱是通过节点(实体)和边(关系) 构建的图结构,能够表达复杂的知识和实体间的关系。该结构可以让模型更好地捕获不同实体之间的关系 ,并且,基于图结构进行检索,可以显著地提高检索效率,减少响应时间。
接下来我们简单介绍一下知识图谱相关概念,最后介绍一下如何将知识图谱、RAG 与大模型结合。
知识图谱相关概念
知识图谱使用图论来存储、映射和查询数据关系。它由节点、边(或关系)和属性组成,其中:
- 节点(Nodes)代表实体,如人、企业或任何数据项。
- 边(Edges)或关系(relationships) :连接节点,并说明实体之间的关联。
- 属性(Properties):提供有关节点和关系的额外信息。
以 "电影产业" 领域为例,构建一个简单的知识图谱示例:
diff
- 节点(实体):
- 节点 1:《流浪地球》(实体类型:电影)
- 节点 2:郭帆(实体类型:导演)
- 节点 3:吴京(实体类型:演员)
- 节点 4:科幻片(实体类型:电影类型)
- 边(关系):
- 节点 2 → 节点 1:边标签为 "执导"(表示郭帆执导了《流浪地球》)
- 节点 3 → 节点 1:边标签为 "主演"(表示吴京主演了《流浪地球》)
- 节点 1 → 节点 4:边标签为 "属于"(表示《流浪地球》属于科幻片类型)
- 属性:
- 节点 1 的属性:上映时间 = 2019 年,票房 = 46.86 亿元(提供电影的额外信息)
- 边 "执导" 的属性:合作次数 = 2(表示郭帆与《流浪地球》制作团队的合作次数)最后构建知识图谱如下:
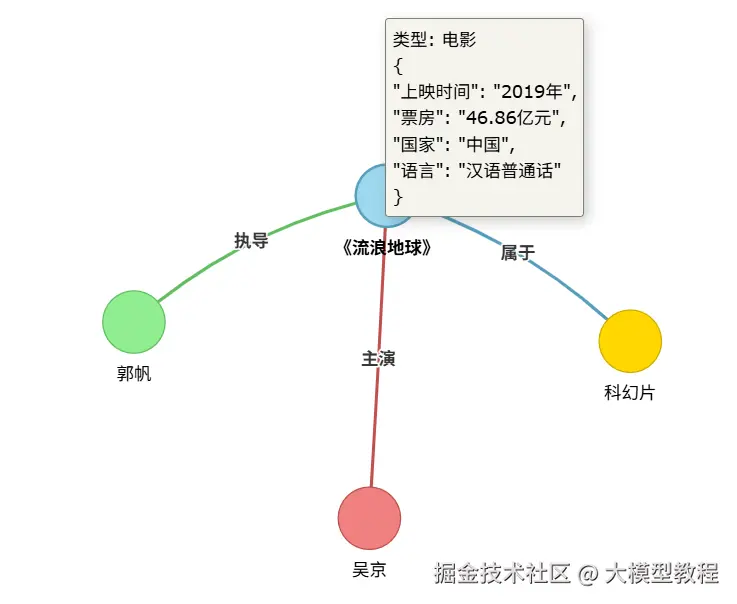
图中清晰展现了该知识图谱里的节点、边、属性。小伙伴们可以试试结合自己的业务场景构建专属的领域知识图谱。
将知识图谱、RAG与大模型结合
一方面,知识图谱可以与RAG结合到大模型,另一方面,大模型也可以促进知识图谱的构建。
如Graphgen团队就尝试了让大模型构建知识图谱。
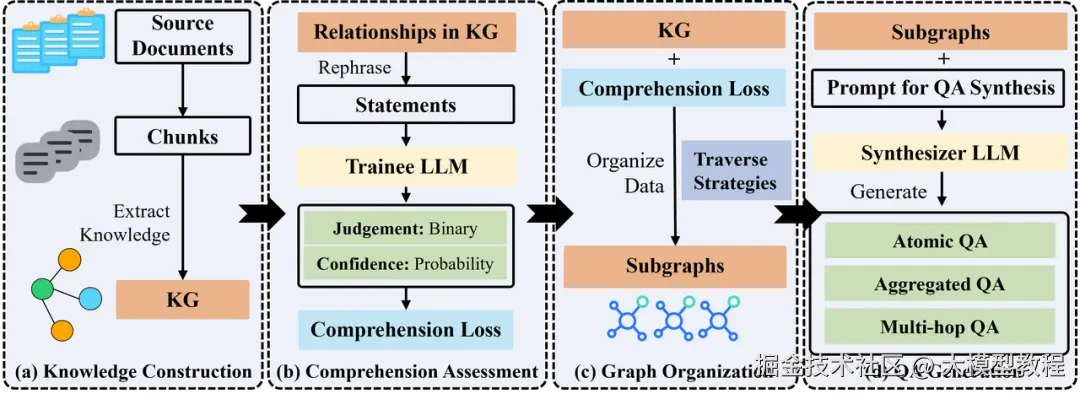
该模型首先将原始文档分割成语义连贯的小片段,接着使用大模型从片段中识别和提取实体及其关系,最后将不同片段中的相同实体或关系的描述自动合并形成知识图谱。
而知识图谱可以与RAG结合到大模型,目前微软提出的GraphRAG1和香港大学提出的LightRAG2是当下非常热门的框架。下面我们以LightRAG框架为例进行介绍。
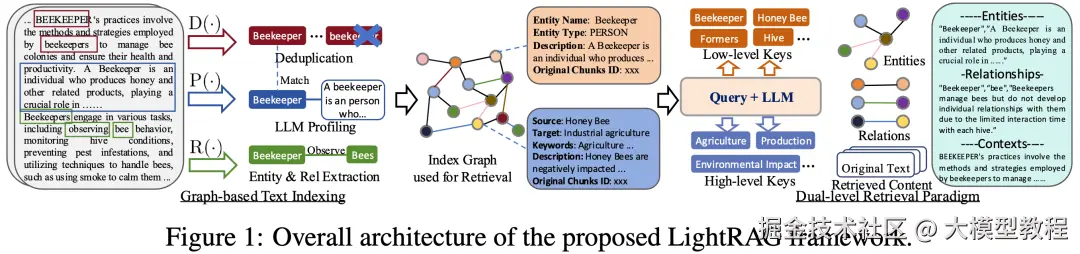
首先运用大模型对文档进行分析,识别并提取其中的实体,这些提取出的实体作为节点,关系作为边,共同构建起知识图谱。为优化图谱,会进行去重操作,去除重复实体。
比如从与 "Beekeeper(养蜂人)" 相关的文本段落里找出 "Beekeeper""Bee(蜜蜂)" 等实体,同时明确它们之间的关系,例如 "管理(Manage)" 关系。
在检索阶段,采用双层检索机制。完成检索后,将获取的实体、关系以及原始文本等信息输入到 LLM 中,系统把用户查询与多源检索结果相整合,生成贴合查询语境的答案。
如 "Beekeeper""Honey Bee(蜜蜂)";高层检索则涵盖更宽泛的主题,像 "农业""生产" 等。
此外,当有新文档加入时,系统会依据之前构建知识图谱的流程处理新文档,再将新生成的图谱数据与现有图谱合并,实现增量更新,让系统能适应动态变化的数据环境,始终基于最新知识进行检索和答案生成 。
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
都在这>>Github<<