多模态学习(Multimodal Learning)作为一项关键技术,通过综合处理文本、图像、音频、视频等多种数据模态,显著增强了模型对复杂信息的解析能力。
其本质在于发挥各模态间的互补优势与冗余特性,克服单一模态的信息边界,复现人类通过多感官协同实现认知的机制。
该技术体系围绕两大核心展开:
多模态融合:通过异构数据的有机整合,系统性提升模型的感知维度与理解深度;
跨模态对齐:建立不同模态数据间的精确映射关系,为后续融合奠定结构化基础。
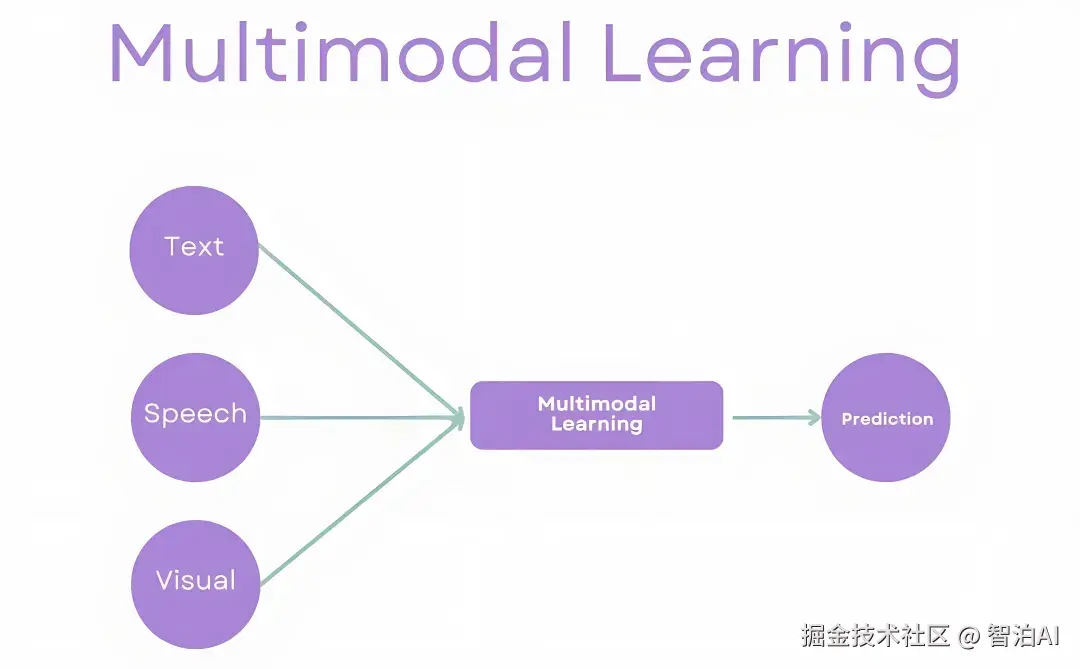
一、多模态融合:整合信息
多模态融合(MultiModal Fusion)的核心在于整合不同模态的互补性优势,通过协同作用构建出兼具稳定性与完整性的多模态表征体系。
表征学习(Representation Learning)通过自动化提取原始数据中各模态的有效特征,实现多模态表征的全面构建。其本质可理解为向量化(Embedding)过程。
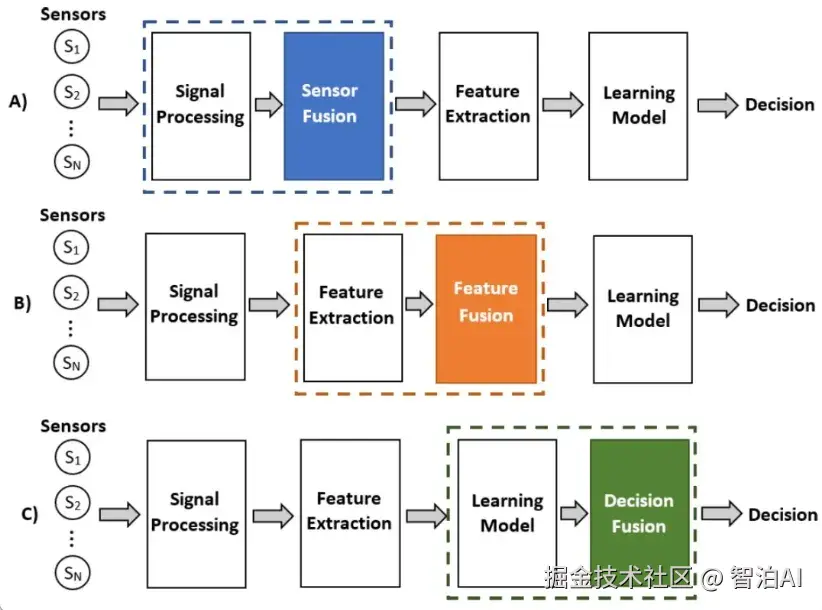
从数据处理的层次角度来划分,多模态融合可分为数据级融合、特征级融合和目标级融合。
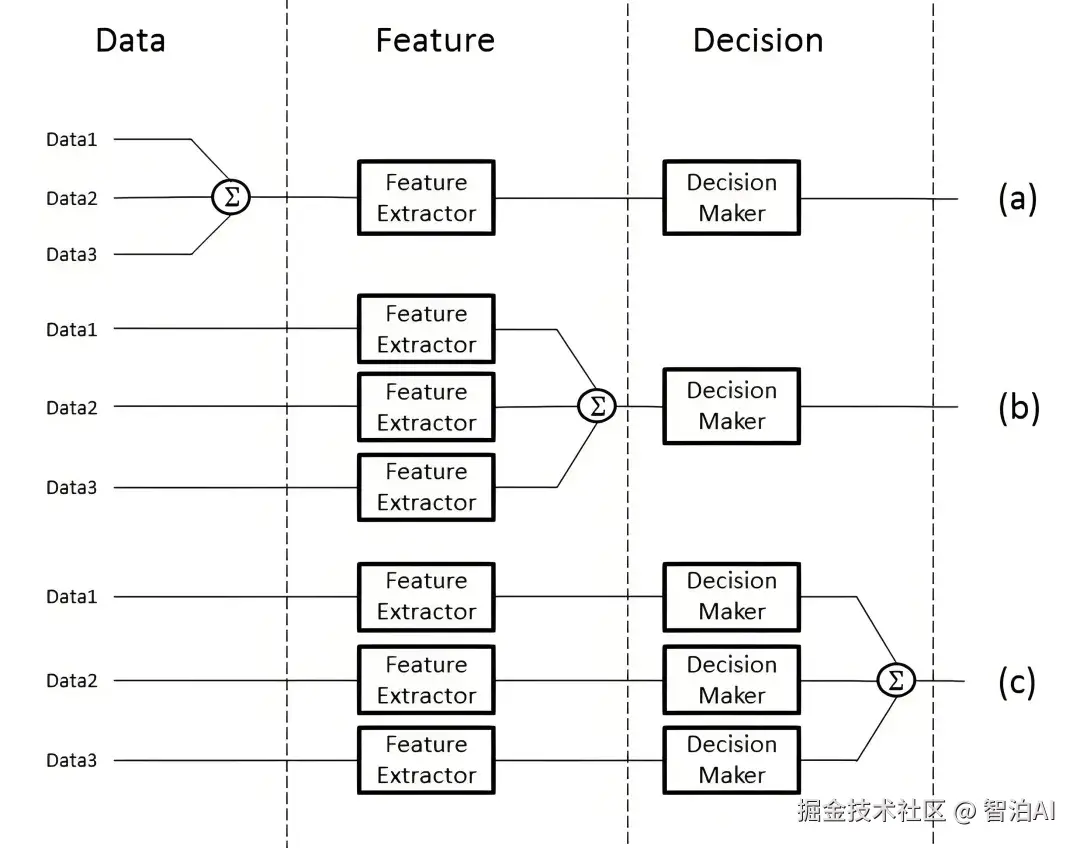
1、数据级融合(Data-Level Fusion)
数据级融合在预处理环节将多模态原始数据进行直接整合,特别适用于数据间存在强相关性且具有互补性的应用场景。
2、特征级融合(Feature-Level Fusion)
特征级融合在完成特征提取后、形成决策前实施。各模态数据经独立处理后生成特征表示,最终在特定特征层面进行融合。该方法在图像分类、语音识别、情感分析等跨模态任务中具有广泛适用性。
3、目标级融合(Decision-Level Fusion)
目标级融合通过整合各单模态模型的输出结果形成最终决策,典型应用于多传感器数据协同分析或多专家系统联合判断等需要综合多源预测结果的场景。
二、跨模态对齐:准确对应
跨模态对齐(MultiModal Alignment)的核心在于通过技术方法实现图像、文本、音频等不同模态数据在特征、语义或表示层面的相互匹配与关联。
跨模态对齐主要分为两大类:显式对齐和隐式对齐。

显示对齐(Explicit Alignment)的核心是通过直接构建不同模态间的映射关系实现,具体分为两类方法:
无监督对齐:依赖数据内在特征自动识别模态关联,典型方法包括CCA(典型相关分析)和自编码器;
监督对齐:借助标签信息引导对齐过程,例如基于多模态嵌入的模型和多任务学习框架。
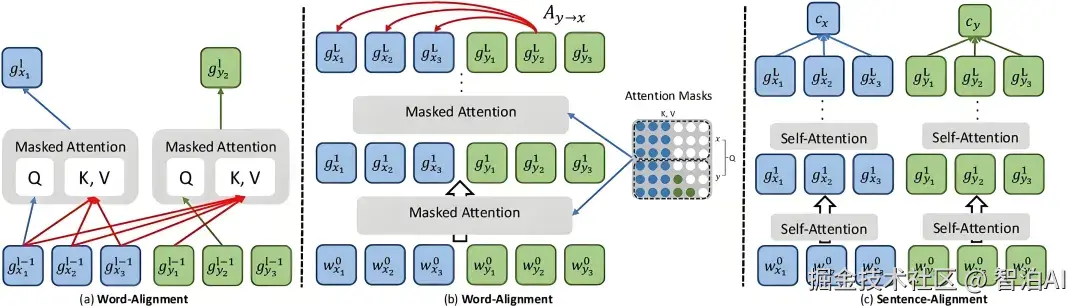
隐式对齐(Implicit Alignment)指无需显式构建映射关系,而是依赖模型自身的内部机制实现跨模态的间接对齐。具体涵盖注意力对齐与语义对齐两种形式。
1、注意力对齐
借助注意力机制动态分配各模态间的权重向量,完成跨模态信息的自适应融合与对齐。
• Transformer模型:应用于图像描述生成等跨模态任务时,通过自注意力机制与编码器-解码器架构,自动捕捉图像与文本间的注意力关联,达成隐式对齐。
• BERT-based模型:在问答或文本-图像检索场景中,融合BERT预训练特征与注意力机制,实现文本查询与视觉内容的隐式对齐。
2、语义对齐
需从语义层面挖掘模态间的潜在关联,建立深层次理解。
• 图神经网络(GNN):通过构建图像-文本语义图,利用GNN建模节点(模态数据)间的语义交互,完成隐式语义对齐。
• 多模态预训练模型:以CLIP(Contrastive Language-Image Pre-training)为例,基于大规模图像-文本对的对比训练,学习图像与文本在语义空间中的映射关系,实现高效隐式对齐。

·更多AI大模型学习视频及资源,都在智泊AI。